2017 年,Google 在论文 Attention is All you need 中提出了 Transformer 模型,其使用 Self-Attention 结构取代了在 NLP 任务中常用的 RNN 网络结构。而且实验也证明Transformer 在效果上已经完败传统的 RNN 网络。Transformer 的整体模型架构如下图所示。尽管它看起来还是很复杂的,但其实我们已经知道了像全连接层(Feed Forward),Softmax层这些基础概念。而在本系列文章的前一篇里(上),我们也解释过了Multi-Head Attention层。 本文将解释搭建Transformer 模型的其它细节。
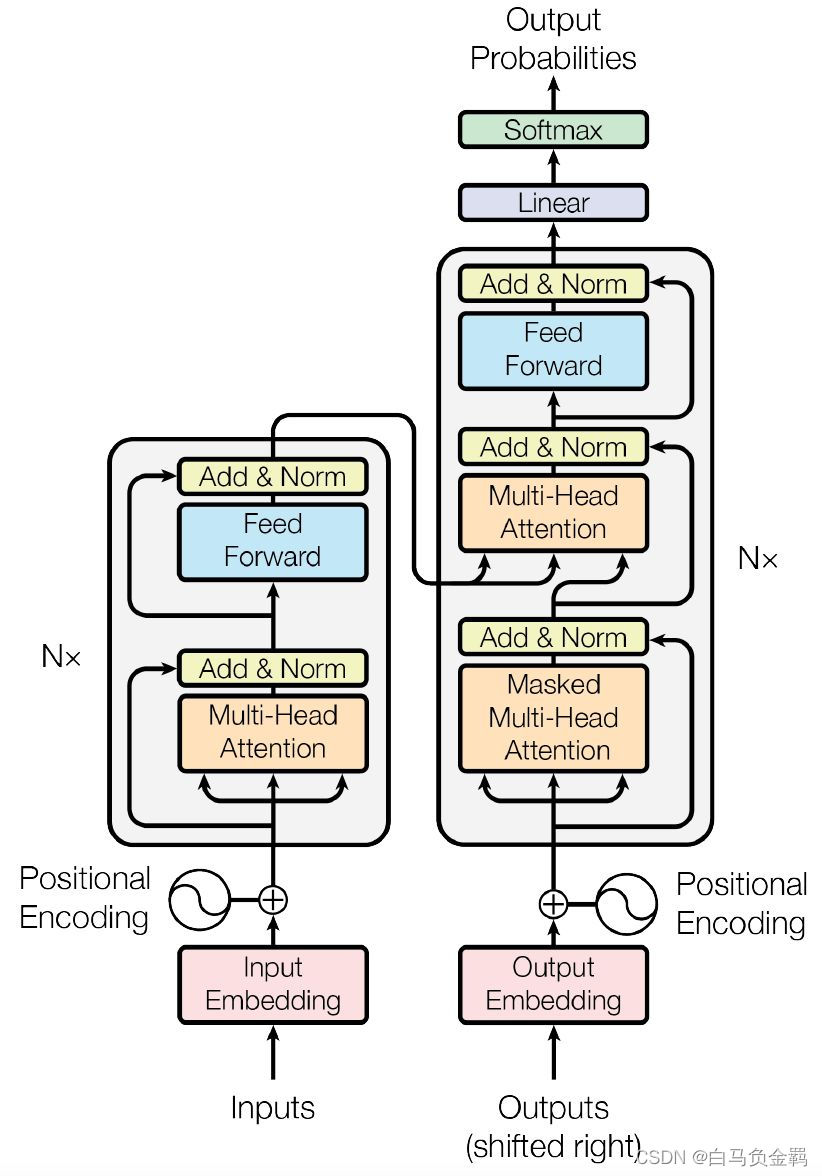
编码组件(上图中作侧部分)由多层编码块(Encoder Block)组成,所以图中使用Nx来表示,在论文中作者使用了 6 层编码器,在实际使用过程中你可以尝试其他层数。
解码组件(上图中右侧部分)也是由相同层数的解码块(Decoder Block)组成(在论文也使用了 6 层),在实际使用过程中你可以尝试其他层数。
本文中部分插图引用自【1】和【2】。
一、编码组件
Transformer 中单词的输入由两部分组成:单词 Embedding 和位置 Embedding (Positional Encoding)。
<