前言 现有的头部姿势估计主要集中在具有预先检测到的正面头部的单个人,这依赖于单独训练的面部检测器,不能很好地泛化到完整的视点。在本文中,作者关注全范围 MPHPE 问题,并提出了一个名为 DirectMHP 的直接端到端简单基线,通过多头的联合回归位置和方向设计了一种新颖的端到端可训练单级网络架构,以解决 MPHPE 问题。
这种灵活的设计可以接受任意姿势表示,同时可以隐含地从更多环境中获益,以提高 HPE 精度,同时保持头部检测性能。
Transformer、目标检测、语义分割交流群
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
计算机视觉入门1v3辅导班

论文:https://arxiv.org/pdf/2301.13817.pdf
代码:https://github.com/hnuzhy/DirectMHP
论文出发点
目前,两个最广泛使用的 HPE 数据集BIWI和300W-LP仅包含窄范围偏航角(-99°,99°)的头部姿势标签。现有 HPE 方法的性能在这些基准上趋于饱和。然而,覆盖全范围偏航角(−180°、180°)的 HPE 方法因此同样具有重要的应用价值。
作者认为目前的两阶段 HPE 方法存在以下两个缺点:(1)人脸/头部检测和方向估计的两阶段模型不能端到端地训练,这使得它不紧凑且效率低下;(2) 单独的阶段无法整合和利用整个人体和周围背景的信息,因此这些模型在野外应用时对挑战性条件不稳健。
创新思路
由于多人头部姿势估计 (MPHPE) 任务没有专门的公共数据集。因此,本文首先分别构建两个 2D 全范围 MPHPE 数据集 AGORA-HPE 和 CMUHPE。然后,本文提出了一种新颖的单级端到端网络结构 DirectMHP,它可以直接预测出现在一张图像中的所有人类头部的全方位姿势。该方法通过共享特征实现联合头部检测和姿势估计。同时,将头部姿势作为相邻属性集成到典型对象预测中,支持任意姿势表示,例如欧拉角。
方法
Benchmarks Construction
(1)AGORA-HPE
首先通过封闭形式的解决方案从具有精确正面视图和预定义相机参数Cref的通用头部模型Href计算相似变换矩阵Mc。在Hreal和Href中精心选择N0对角地标进行对齐。然后,使用Mc松散地围绕每个头部定义一个变换后的3D半球,并通过具有真实相机参数Creal的2D投影生成其边界框,以获得包含背景和整个头部的区域。最后,为了提取头部方向,估计从相机世界Ccam到现实世界Creal的变换矩阵 Mr。Mr计算如下:

然后按照数据集300W-LP和BIWI按照俯仰-偏航-滚动顺序拆分出三个欧拉角。丢弃掉可能没有至少一个有效头部姿势标签的图像,最终生成的 AGORA-HPE 基准分别包含1,070和14,408个图像用于验证和训练集。
(2)CMU-HPE
CMU Panoptic Dataset由一个大规模的多视图系统收集。它的场景主要集中在半球形设备中的一个人或互动的人身上。其标签包括 31 个同步高清视频流中多人的 3D 身体姿势、手部关键点和面部特征。它还提供来自31个视图的校准相机参数Creal。典型的采样时刻快照如下图所示:

类似于构建AGORA-HPE的过程,本文构建了CMU-HPE,它分别有16,216和15,718个图像用于验证和训练集。
如下图,本文构建的两个数据集的俯仰角和横滚角基本上服从正态分布。

提出的两个全范围数据集自然包含比300W-LP&AFLW2000和BIWI更多的人脸隐形头。如下图所示,除了那些奇特的头部后仰外,普通的正面脸往往与自遮挡、隐现遮挡或异常角度等复杂情况并存。

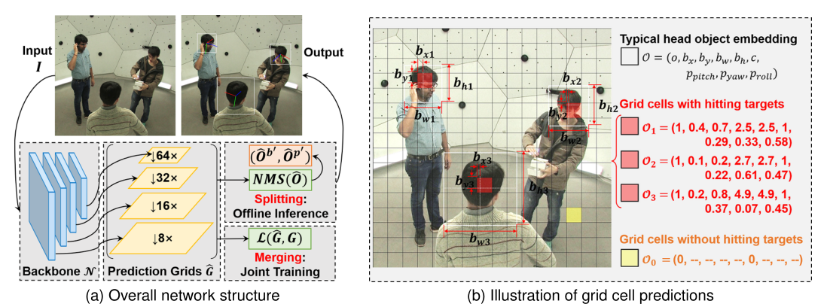
DirectMHP
在MPHPE方法中,训练了一个密集的检测网络来直接预测一组头部对象,其中包含头部边界框集和相应的头部姿势同时设置,并联合头部检测和姿势估计之间的内在相关性。
然后,将头部姿势视为附加的头部属性,并将其与其头部位置连接起来以构建头部对象的联合表示,在统一框架中使用联合预测将这两个任务集成在一起。
一方面,一个合适的头部边界框具有强烈的局部特征(例如,眼睛、耳朵和下巴)和弱的全局特征(例如周围背景和解剖位置),用于其头部方向估计。因此,本文将两者绑定到一个嵌入中,以使网络能够学习它们的内在关系。
Network Architecture Design
网络结构如下图所示。采用目标检测架构(YOLOv5)作为backbone,从一张输入图像I中提取特征并生成预测网格。在训练期间,使用目标网格G来监督损失函数L。在推理中,应用对预测的头部对象进行非最大抑制 (NMS)以获得最终边界框集和相关头部姿势集。
Multi-Loss Optimization
计算总训练损失:

计算三个损失分量如下:
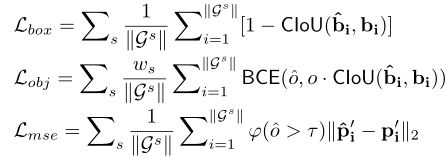
Splitting: Offline Inference
训练结束后,需要对预测对象集进行处理。首先,使用非极大值抑制 (NMS) 来过滤掉误报和冗余边界框。通过计算每个预测对象的置信度,不需要修改获得正头部边界框的常见NMS步骤。
结果
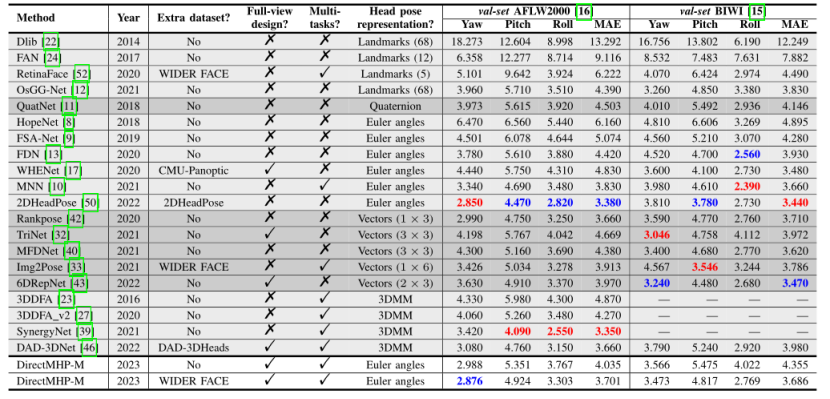
DIRECTMHP-M与在300W-LP 数据集上训练的方法的比较(红色表示最好的结果,蓝色表示第二好的结果):
同理,在AGORA-HPE 基准验证集的性能比较:

类似的,在CMU-HPE 基准验证集的性能比较:

来自 COCO val-set 的一些野外图像的可视化如下图所示。第二行和第三行分别是比较6DRepNet和本文方法的例子。使用6DRepNet估计的头部样本有明显的不准确(黄色圈出)。

欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:444129970。群内有大佬负责解答大家的日常学习、科研、代码问题。
模型部署交流群:732145323。用于计算机视觉方面的模型部署、高性能计算、优化加速、技术学习等方面的交流。
用于超大图像的训练策略:Patch Gradient Descent
新方案:从错误中学习,点云分割中的自我规范化层次语义表示
ECCV2022 | 重新思考单阶段3D目标检测中的IoU优化
目标检测模型的评价标准总结
Vision Transformer和MLP-Mixer联系和对比
Visual Attention Network
TensorRT教程(一)初次介绍TensorRT
TensorRT教程(二)TensorRT进阶介绍
从零搭建Pytorch模型教程(一)数据读取
从零搭建Pytorch模型教程(二)搭建网络
从零搭建Pytorch模型教程(三)搭建Transformer网络
从零搭建Pytorch模型教程(四)编写训练过程--参数解析
从零搭建Pytorch模型教程(五)编写训练过程--一些基本的配置
从零搭建Pytorch模型教程(六)编写训练过程和推理过程
从零搭建Pytorch模型教程(七)单机多卡和多机多卡训练
从零搭建pytorch模型教程(八)实践部分(一)微调、冻结网络
从零搭建pytorch模型教程(八)实践部分(二)目标检测数据集格式转换
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
入门必读系列(十五)神经网络不work的原因总结
入门必读系列(十四)CV论文常见英语单词总结
入门必读系列(十三)高效阅读论文的方法
入门必读系列(十二)池化各要点与各方法总结
入门必读系列(十一)Dropout原理解析
入门必读系列(十)warmup及各主流框架实现差异
入门必读系列(九)彻底理解神经网络
入门必读系列(八)优化器的选择
入门必读系列(七)BatchSize对神经网络训练的影响
入门必读系列(六)神经网络中的归一化方法总结
入门必读系列(五)如何选择合适的初始化方法
入门必读系列(四)Transformer模型
入门必读系列(三)轻量化模型
入门必读系列(二)CNN经典模型
入门必读系列(一)欠拟合与过拟合总结