这一部分是在讲解head.s代码,这个代码与bootsect.s和setup.s在同一目录下,但是head.s程序在被编译生成目标文件后会与内核其他程序一起被链接成system模块,位于system模块的最前面开始部分。system模块将被放置在磁盘上setup模块之后开始的扇区中,即从磁盘上第6个扇区开始放置。其大小为120KB,其中head部分有14KB,head除了做了一些调用main函数的准备工作之外,还做了一件对内核程序在内存中的布局已经对内核程序的正常运行都有重大意义的事情,就是用程序自身代码在程序自身所在的内存空间中创建了内核分页机制,即在 0x00000000处创建了页目录表,页表,缓冲区,GDT,IDT,并将head程序已经执行过的代码所占空间覆盖,这意味着head程序自己将自己废弃,main函数开始执行。我们看看这些是怎么实现的。
同时,CPU的运行模式变了,汇编语法也变了,变成了比较麻烦的AT&T语法,对于AT&T语法不是很熟悉的可以参考别的博客
开始head.s
pg_dir:
.globl startup_32
startup_32:movl $0x10,%eaxmov %ax,%dsmov %ax,%esmov %ax,%fsmov %ax,%gslss stack_start,%espcall setup_idtcall setup_gdtmovl $0x10,%eax # reload all the segment registersmov %ax,%ds # after changing gdt. CS was alreadymov %ax,%es # reloaded in 'setup_gdt'mov %ax,%fsmov %ax,%gslss stack_start,%espxorl %eax,%eax
1: incl %eax # check that A20 really IS enabledmovl %eax,0x000000 # loop forever if it isn'tcmpl %eax,0x100000je 1b
pg_dir标识内核分页机制完成后的内核起始位置,也就是物理内存的起始位置,head程序马上要在这里建立页目录表,为分页机制做准备,这一点非常重要,是内核能够掌握用户进程的基础之一,其占据的内存空间为 0x0000-0x4FFF,在实模式下CS是代码段基址,但是在保护模式下CS是代码段选择符,之后在设置分页机制时,页目录会存放在这里,也会覆盖这里的代码。
jmpi 0,8
这个代码使得CS与GDT的第二项关联,并且使代码段基址指向 0x000000。所以这个指令是一样的
可以看到mov指令来初始化段寄存器ds/es/fs/gs,指向可读可写但不能执行的数据段。(这个是怎么指向数据段的呢,我也是一段时间之后才反应过来,他是类似于上面的指令,我们需要明白的一点是什么呢,现在是保护模式了,所以段寄存器不是直接指向内存了,我们需要通过GDT来访问内存了,通过GDT访问内存,这点非常重要非常重要)
在CPU中,跟段有关的CPU寄存器一共有6个:cs,ss,ds,es,fs,gs,它们保存的是段选择符。而同时这六个寄存器每个都有一个对应的非编程寄存器,它们对应的非编程寄存器中保存的是段描述符。
CS:代码段寄存器
DS:数据段寄存器
SS:栈段寄存器
ES:扩展段寄存器
FS:GS:386处理器之后被引入
这里初始化的目的是为了让着四个寄存器可以变到保护模式,然后加载堆栈段描述符,我们来看看stack_start到底是啥:
long user_stack [ PAGE_SIZE>>2 ] ;struct {long * a;short b;} stack_start = { & user_stack [PAGE_SIZE>>2] , 0x10 };
这个程序在/kernel/sched.c文件当中。lss作用在这里最终的效果是把0x10作为段选择子加载到ss中,并将user_stack的地址放到esp中。可以测算出其起始位置为 0x1E25C。 lss指令相当于让 ss:esp 这个栈顶指针指向了 _stack_start 这个标号的位置。还记得原来的栈顶指针在哪里嘛?0x9FF00,现在要变了。在这个结构体中,高位 8 字节是 0x10,将会赋值给 ss 栈段寄存器,低位 16 字节是 user_stack 这个数组的最后一个元素的地址值,将其赋值给 esp 寄存器。为什么是最后一个元素值呢,因为栈是从后往前生长的。
0x10我们这里也应该当做段选择子来看待,其实就是第四个段选择符,段基址为 0x000000,段限长8MB,内核特权级,后面的压栈动作就在这里执行。
这里我们就能看出来了,实模式和保护模式的寻址方式差异非常大,如果没有我们之前在实模式下创建的GDT表格,现在寻址都无法执行,我们之前设置栈的寄存器是SP,现在是ESP,这是专为保护模式下进行操作作出的调整。
setup_idt和setup_gdt分别对应建立新的IDT表和GDT表
建立新的IDT
/** setup_idt** sets up a idt with 256 entries pointing to* ignore_int, interrupt gates. It then loads* idt. Everything that wants to install itself* in the idt-table may do so themselves. Interrupts* are enabled elsewhere, when we can be relatively* sure everything is ok. This routine will be over-* written by the page tables.*/
setup_idt:lea ignore_int,%edxmovl $0x00080000,%eaxmovw %dx,%ax /* selector = 0x0008 = cs */movw $0x8E00,%dx /* interrupt gate - dpl=0, present */lea idt,%edimov $256,%ecx
rp_sidt:movl %eax,(%edi)movl %edx,4(%edi)addl $8,%edidec %ecxjne rp_sidtlidt idt_descrret
ignore_int是一个函数,作用是打印Unknown interrupt这个字符串,然后结束。想看看的给你瞅一眼:
我们还是先解释清除这段代码写了什么,lea这个指令可以将ignore_int的偏移地址给edx,然后将0x00080000这个值给了eax,
%eax,可存放一般数据,可作为累加器使用;
%ebx,可存放一般数据,可用来存放数据的指针(偏移地址);
%ecx,可存放一般数据,可用来做计数器,常常将循环次数用它来存放;
%edx,可存放一般数据,可用来存放乘法运算产生的部分积,用来存放输入输出的端口地址(指针);
%esi,可存放一般数据,可用于串操作中,存放源地址,对一串数据访问;
%edi,可存放一般数据,可用于串操作中,存放目的地址,对一串数据访问;
%esp,用于寻址一个称为堆栈的存储区,通过它来访问堆栈数据;
%ebp,可存放一般数据,用来存放访问堆栈段的一个数据区,作为基地址;MOVB,MOVW,MOVL三种指令的区别是它们分别是在大小为 1,2和4个字节的数据上进行操作。
MOVW 把 16 位立即数放到寄存器的底16位,高16位清0
MOVT 把 16 位立即数放到寄存器的高16位,低 16位不影响
/* This is the default interrupt "handler" :-) */
int_msg:.asciz "Unknown interrupt\n\r"
.align 2
ignore_int:pushl %eaxpushl %ecxpushl %edxpush %dspush %espush %fsmovl $0x10,%eaxmov %ax,%dsmov %ax,%esmov %ax,%fspushl $int_msgcall printkpopl %eaxpop %fspop %espop %dspopl %edxpopl %ecxpopl %eaxiret
printk是一个函数,被定义在linuxsrc/kernel/printk.c的printk函数。
我们看一下中断描述符的组成
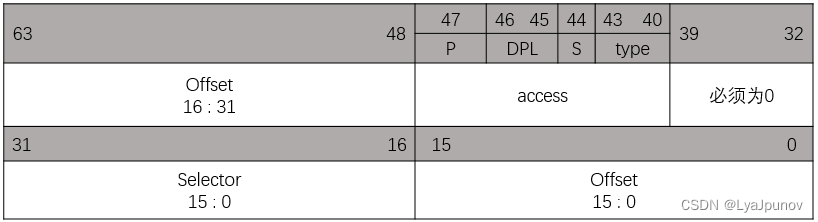
Offset:对应中断服务程序的段内偏移地址
Selector:所在段选择符
DPL:描述符特权级
P:段存在标志
TYPE:段描述符类型
创建IDT表是重建保护模式下中断服务体系的开始,程序先让所有的中断描述符默认指向ignore_int这个位置(将来main函数里面还要让中断描述符对应具体的中断服务程序),之后还要对IDT寄存器的值进行设置,这种初始化操作,可以防止无意中覆盖代码或数据引起的逻辑混乱,以及对开发中的误操作给出及时的提示。IDT有256个表项,实际只使用了几十个,对于误用,未使用的中断描述符,这样的提示信息可以提醒开发人员注意错误。
实际上这段程序的作用就是设置中断描述符表,中断嘛,对应着中断号,你发起中断,给中断号,执行中断程序,此时所有的中断号都指向了一个打印程序,hhhh,这个打印程序就是默认的中断处理程序,之后会被重新设置的中断覆盖。
建立新的GDT
/** setup_gdt** This routines sets up a new gdt and loads it.* Only two entries are currently built, the same* ones that were built in init.s. The routine* is VERY complicated at two whole lines, so this* rather long comment is certainly needed :-).* This routine will beoverwritten by the page tables.*/
setup_gdt:lgdt gdt_descrret
这个是构造好了的
.align 2
.word 0
idt_descr:.word 256*8-1 # idt contains 256 entries.long idt
.align 2
.word 0
gdt_descr:.word 256*8-1 # so does gdt (not that that's any.long gdt # magic number, but it works for me :^).align 8
idt: .fill 256,8,0 # idt is uninitializedgdt: .quad 0x0000000000000000 /* NULL descriptor */.quad 0x00c09a0000000fff /* 16Mb */.quad 0x00c0920000000fff /* 16Mb */.quad 0x0000000000000000 /* TEMPORARY - don't use */.fill 252,8,0 /* space for LDT's and TSS's etc */
最后的gdt:就是gdt表的样子,其实吧和我们之前设置的gdt表一模一样,只是换个位置。第零段位空,第一段指向代码段,第二段指向数据段,第三段为空,剩余的252项留给任务状态段描述符TSS和局部描述符LDT
这里我们搞好了之后
movl $0x10,%eax # reload all the segment registersmov %ax,%ds # after changing gdt. CS was alreadymov %ax,%es # reloaded in 'setup_gdt'mov %ax,%fsmov %ax,%gslss stack_start,%espxorl %eax,%eax
然后又来了一遍加载,每次更新GDT之后,由于段描述符的变化,我们必须重新加载一遍,保证与最新的保持一致。
1: incl %eax # check that A20 really IS enabledmovl %eax,0x000000 # loop forever if it isn'tcmpl %eax,0x100000je 1b
这部分开始检查A20是否真正的开启了,防止出了差错,否则就一直循环。
/** NOTE! 486 should set bit 16, to check for write-protect in supervisor* mode. Then it would be unnecessary with the "verify_area()"-calls.* 486 users probably want to set the NE (#5) bit also, so as to use* int 16 for math errors.*/movl %cr0,%eax # check math chipandl $0x80000011,%eax # Save PG,PE,ET
/* "orl $0x10020,%eax" here for 486 might be good */orl $2,%eax # set MPmovl %eax,%cr0call check_x87jmp after_page_tables
这段代码就是检查数字协处理器芯片是否存在。这个和硬件相关,确认无误后跳转
after_page_tables:pushl $0 # These are the parameters to main :-)pushl $0pushl $0pushl $L6 # return address for main, if it decides to.pushl $mainjmp setup_paging
L6:jmp L6 # main should never return here, but# just in case, we know what happens.
到这里,我们开始压栈,压栈完毕后,然后跳转到setup_paging:
开启分页
/** Setup_paging** This routine sets up paging by setting the page bit* in cr0. The page tables are set up, identity-mapping* the first 16MB. The pager assumes that no illegal* addresses are produced (ie >4Mb on a 4Mb machine).** NOTE! Although all physical memory should be identity* mapped by this routine, only the kernel page functions* use the >1Mb addresses directly. All "normal" functions* use just the lower 1Mb, or the local data space, which* will be mapped to some other place - mm keeps track of* that.** For those with more memory than 16 Mb - tough luck. I've* not got it, why should you :-) The source is here. Change* it. (Seriously - it shouldn't be too difficult. Mostly* change some constants etc. I left it at 16Mb, as my machine* even cannot be extended past that (ok, but it was cheap :-)* I've tried to show which constants to change by having* some kind of marker at them (search for "16Mb"), but I* won't guarantee that's all :-( )*/
.align 2
setup_paging:movl $1024*5,%ecx /* 5 pages - pg_dir+4 page tables */xorl %eax,%eaxxorl %edi,%edi /* pg_dir is at 0x000 */cld;rep;stoslmovl $pg0+7,pg_dir /* set present bit/user r/w */movl $pg1+7,pg_dir+4 /* --------- " " --------- */movl $pg2+7,pg_dir+8 /* --------- " " --------- */movl $pg3+7,pg_dir+12 /* --------- " " --------- */movl $pg3+4092,%edimovl $0xfff007,%eax /* 16Mb - 4096 + 7 (r/w user,p) */std
1: stosl /* fill pages backwards - more efficient :-) */subl $0x1000,%eaxjge 1bxorl %eax,%eax /* pg_dir is at 0x0000 */movl %eax,%cr3 /* cr3 - page directory start */movl %cr0,%eaxorl $0x80000000,%eaxmovl %eax,%cr0 /* set paging (PG) bit */ret /* this also flushes prefetch-queue */
这些代码会让改Linux内核向现代操作系统更近了一步,开启分页保护。分页的情况如下:
/** I put the kernel page tables right after the page directory,* using 4 of them to span 16 Mb of physical memory. People with* more than 16MB will have to expand this.*/
.org 0x1000
pg0:.org 0x2000
pg1:.org 0x3000
pg2:.org 0x4000
pg3:.org 0x5000
我们回顾一下分页的一些知识,开启分页需要将CR0寄存器中的PG位开启,开启这个标志之前必须已经或者同步开启 PE标志位,PG = 0且PE = 0,处理器工作在实地址模式下。PG = 0且PE = 1,处理器工作在没有开启分页机制的保护模式下。PG = 1且PE = 0,在PE没有开启的情况下无法开启PG。PG = 1且PE = 1,处理器工作在开启了分页机制的保护模式下。
我们没开启分页模式之前,我们是怎么找到一个物理地址呢,段寄存器和从全局描述符表中取出段基地址,然后加上偏移地址得到真实的物理地址,但是开启分页机制之后,又会多一步转换,分段机制得到线性地址之后还需要多一步分页机制的转换,要是不开启分页机制的话,这一步就直接是物理地址了。
比如我们的线性地址是 0000000011_0100000000_000000000000 (经过了段机制的转换),那从这个线性地址到实际物理地址的转换是怎么样的呢?
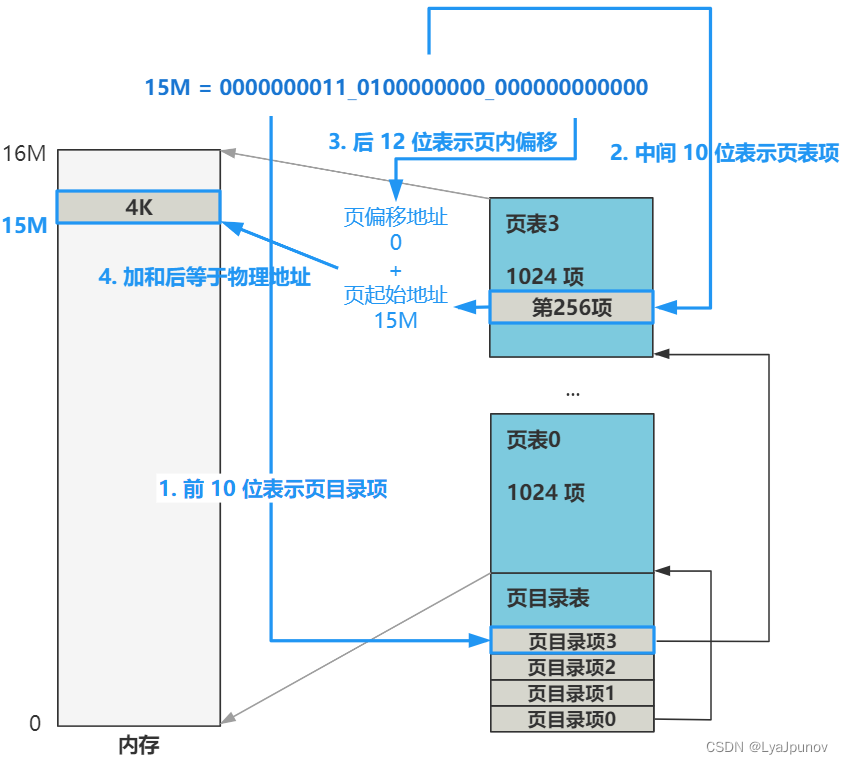
高 10 位负责在页目录表中找到一个页目录项,这个页目录项的值加上中间 10 位拼接后的地址去页表中去寻找一个页表项,这个页表项的值,再加上后 12 位偏移地址,就是最终的物理地址。这一切的操作都由计算机的一个硬件角MMU,也叫内存管理单元,或者分页内存管理单元这个部件来讲虚拟地址转换为物理地址。整个过程我们是不需要关心的,因为这个是硬件层的操作了,操作系统只是在软件层。
我们的这种分配方式为二级页表,一层页目录项PDE,一层叫页表项PTE,之后再开启分页机制的开关。
所以这段代码,就是帮我们把页表和页目录表在内存中写好,之后开启 cr0 寄存器的分页开关,仅此而已。
按照当时的Linux的任务,总可使用的内存不超过16MB,也就是最大地址空间为 0xFFFFF 。而按照当前的页目录表和页表这种机制,1 个页目录表最多包含 1024 个页目录项(也就是 1024 个页表),1 个页表最多包含 1024 个页表项(也就是 1024 个页),1 页为 4KB(因为有 12 位偏移地址),因此,16M 的地址空间可以用 1 个页目录表 + 4 个页表搞定。
这一段代码还包括将页目录表放在内存地址的最开头,记得pg_dir这个标签嘛,现在就是将页目录表放在了这个位置,也就是内存的一开头的位置,然后紧接着他放四个页表,在页目录表和页表中填写好数值来覆盖16MB的内存,随后开启分页机制。
同时,如 idt 和 gdt 一样,我们也需要通过一个寄存器告诉 CPU 我们把这些页表放在了哪里,就是这段代码。
xor eax,eax
mov cr3,eax
具体的页表设置好后,映射内存的情况时怎样呢,那就看页表的具体数据
setup_paging:...cld;rep;stoslmovl $pg0+7,pg_dir /* set present bit/user r/w */movl $pg1+7,pg_dir+4 /* --------- " " --------- */movl $pg2+7,pg_dir+8 /* --------- " " --------- */movl $pg3+7,pg_dir+12 /* --------- " " --------- */movl $pg3+4092,%edimovl $0xfff007,%eax /* 16Mb - 4096 + 7 (r/w user,p) */std
1: stosl /* fill pages backwards - more efficient :-) */subl $0x1000,%eaxjge 1b
前五行表示,页目录表的前 4 个页目录项,分别指向 4 个页表。比如页目录项中的第一项 [eax] 被赋值为 pg0+7,也就是 0x00001007,根据页目录项的格式,表示页表地址为 0x1000,页属性为 0x07 表示改页存在、用户可读写。
后面几行表示,填充 4 个页表的每一项,一共 4*1024=4096 项,依次映射到内存的前 16MB 空间。
现在只有四个页目录项,也就是将前面的16M的线性地址空间与16M的物理地址空间对应上了。
具体的分段与分页的理论我们这里就不在详细的展开了,如果需要详细的理论分析可以看我的另一篇文章,详细解释了分段和分页理论。
为什么要重设GDT
为什么要废除原来的GDT而重新设计一套GDT呢?别以为有啥高深的原因,就是因为原来GDT所在的位置是设计代码时再setup.s里面设置的数据,将来这个setup.s 所在的内存位置会在设计缓冲区时被覆盖掉,如果不改变位置,将来GDT的内容就会被覆盖掉,其实吧,就是管理内存,懂了吧
目前的内存分布
| 内存位置 | 内容 |
|---|---|
| 0x00000 - 0x00FFF | 页目录表 |
| 0x01000 - 0x01FFF | 页表0 |
| 0x02000 - 0x02FFF | 页表1 |
| 0x03000 - 0x03FFF | 页表2 |
| 0x04000 - 0x04FFF | 页表3 |
| 0x05000 - 0x05400 | 软盘缓冲区 |
| 0x05401 - 0x054B7 | 空 |
| 0x054B8 - 0x05CB7 | 中断描述符表IDT |
| 0x05CB8 - 0x064B7 | 全局描述符表GDT |
我们上面做了那么多工作,其实都是为了达到现在的内存状态啊
准备进入main
我们上面讲了分页代码,这里有一个骚操作帮助进入main函数
after_page_tables:pushl $0 # These are the parameters to main :-)pushl $0pushl $0pushl $L6 # return address for main, if it decides to.pushl $mainjmp setup_paging
L6:jmp L6 # main should never return here, but# just in case, we know what happens.
分页之后我们执行了这个代码,这个代码就有意思了,push指令是压榨,五个push指令过去以后,栈会变成这个样子
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XSud4WfK-1676125712644)(C:\Users\LoveSS\AppData\Roaming\Typora\typora-user-images\image-20230211212519126.png)]
然后注意,setup_paging 最后一个指令是 ret,也就是我们上一回讲的设置分页的代码的最后一个指令,形象地说它叫返回指令,但 CPU 可没有那么聪明,它并不知道该返回到哪里执行,只是很机械地把栈顶的元素值当做返回地址,跳转去那里执行。
再具体说是,把 esp 寄存器(栈顶地址)所指向的内存处的值,赋值给 eip 寄存器,而 cs:eip 就是 CPU 要执行的下一条指令的地址。而此时栈顶刚好是 main.c 里写的 main 函数的内存地址,是我们刚刚特意压入栈的,所以 CPU 就理所应当跳过来了。
call指令会自动将EIP的值压栈,保护返回现场,然后执行被调函数程序,等到被调函数程序执行完毕后,也就是被调函数ret指令时,自动出栈给EIP并还原现场,继续执行call的下一条指令,对操作系统而言,这个指令就有点怪异了,如果call调用了操作系统的main函数,那ret返回给谁呢?难道还有一个更底层的程序接受操作系统的返回嘛,操作系统已经是最底层的系统了,那还怎么更底层呢,所以这里使用了这么一个技巧,直接将main压栈,ret返回时直接就执行main函数了,而其他的三个压栈的 0,本意是作为 main 函数的参数,但实际上似乎也没有用到,所以也不必关心。
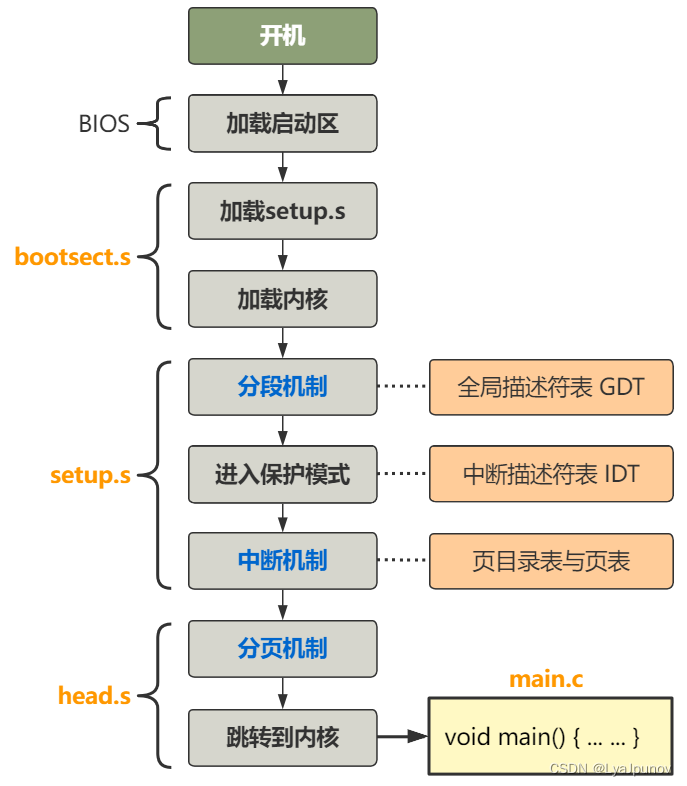
终于终于我们的底层搞完了,进入main函数了,这三章内容讲了我们是怎么从加电到加载完内核并跳到内核程序的,我们梳理一下
加载内核的流程
目前的内存分布
| 内存位置 | 内容 |
|---|---|
| 0x00000 - 0x00FFF | 页目录表 |
| 0x01000 - 0x01FFF | 页表0 |
| 0x02000 - 0x02FFF | 页表1 |
| 0x03000 - 0x03FFF | 页表2 |
| 0x04000 - 0x04FFF | 页表3 |
| 0x05000 - 0x05400 | 软盘缓冲区 |
| 0x05401 - 0x054B7 | 空 |
| 0x054B8 - 0x05CB7 | 中断描述符表IDT |
| 0x05CB8 - 0x064B7 | 全局描述符表GDT |
| 0x064B8 - 0x80000 | system内核 |
| 0x80001 - 0x8FFFF | 空 |
| 0x90000 - 0x901FC | setup在内存中保存的信息 |
| 0x901FD - 0x901FF | 空 |
| 0x90200 - 0x90A00 | setup程序 |
| 0x90A00 - 0x9FF00 | 栈(栈指向0x9FF00),并未占完 |
| 0x9FF01 - 0xFDFFF | 空 |