- teacher forcing
- 训练迭代过程早期的RNN预测能力非常弱,几乎不能给出好的生成结果。如果某一个unit产生了垃圾结果,必然会影响后面一片unit的学习。
- RNN存在着两种训练模式(mode):
- free-running mode:就是常见的那种训练网络的方式: 上一个state的输出作为下一个state的输入。而Teacher Forcing是一种快速有效地训练循环神经网络模型的方法,该模型使用来自先验时间步长的输出作为输入。
- teacher-forcing mode
- Teacher Forcing,是一种网络训练方法,它每次不使用上一个state的输出作为下一个state的输入,而是直接使用训练数据的标准答案(ground truth)的对应上一项作为下一个state的输入。
- Teacher Forcing工作原理: 在训练过程的 t 时刻,使用训练数据集的期望输出或实际输出: y(t), 作为下一时间步骤的输入: x(t+1),而不是使用模型生成的输出h(t)。
- Teacher Forcing同样存在缺点: 一直靠老师带的孩子是走不远的。
- 因为依赖标签数据,在训练过程中,模型会有较好的效果,但是在测试的时候因为不能得到ground truth的支持,所以如果目前生成的序列在训练过程中有很大不同,模型就会变得脆弱。
- 也就是说,这种模型的cross-domain能力会更差,也就是如果测试数据集与训练数据集来自不同的领域,模型的performance就会变差。
- 有计划地学习(Curriculum Learning)
- beam search方法仅适用于具有离散输出值的预测问题,不能用于预测实值(real-valued)输出的问题。
- 有计划地学习的意思就是: 使用一个概率p去选择使用ground truth的输出y(t)还是前一个时间步骤模型生成的输出h(t)作为当前时间步骤的输入x(+1)。这个概率p会随着时间的推移而改变,这就是所谓的计划抽样(scheduled sampling,可参考:https://blog.csdn.net/weixin_45647721/article/details/127352875)
- 训练过程会从force learning开始,慢慢地降低在训练阶段输入ground truth的频率。
- Scheduled Sampling主要应用在序列到序列模型的训练阶段,而生成阶段则不需要使用。
- 在解码器的t时刻Scheduled Sampling以概率ϵ_i使用上一时刻的真实元素y_(t−1)作为解码器输入,以概率1−ϵ_i使用上一时刻生成的元素g_(t−1)作为解码器输入。且由上可得随着i的增大ϵ_i会不断减小,解码器将不断倾向于使用生成的元素作为输入,训练阶段和生成阶段的数据分布将变得越来越一致。
- 不同语言比较:
- C语言是很多语言的底层实现,执行效率高,需要自己做内存管理,对代码的要求比较高,很多功能需要手动实现。
- c#:微软开发的编程语言,部署时需要放在windows server上,最大的问题是windows系统花钱。
- php:一般用于快速搭建网站
- golang: 语法和c比较接近,处理并发时比较有优势
- other:
- ffmpeg将音频转为单通道16k采样率的音频:ffmpeg -i test.wav -ac 1 -ar 16000 -y 1.wav
- 16khz对应256kbps的wav文件
2.11整理(2)(主要关于teacher forcing)
news/2024/11/20 23:26:44/
相关文章
电脑重装系统注册表恢复方法
今天讲关于大家的电脑在遇到一些故障的时候,以及电脑用久了之后会卡顿,那么这时候大家一般都会给电脑重装系统。重装系统之后却发现自己电脑里的注册表不见了,重装系统后怎么恢复注册表?小编就带着大家一起学习重装系统注册表恢复到底是怎…

RocketMQ基础学习
前言: RocketMQ阿里开源的,一款分布式的消息中间件,它经过阿里的生产环境的高并发、高吞吐的考验,同时,还支持分布式事务等场景。RocketMQ使用Java语言进行开发,方便Java开发者学习源码。但是,R…
2.11知识点整理(关于pycharm,python,pytorch,conda)
pycharm 设置anaconda环境: File -> Settings->选择左侧的project xxx再选择打开Project Interpreter页->选择add添加解释器->添加Anaconda中Python解释器(Anaconda安装目录下的python.exe) (选择existing environment ÿ…
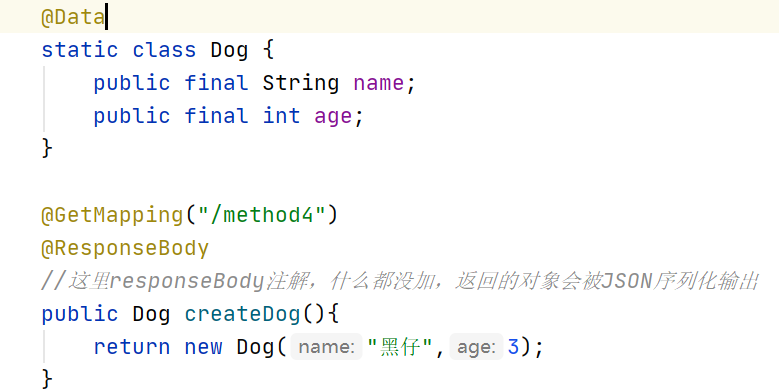
4.SpringWeb
一、创建项目LomBok:辅助开发工具,减少代码编写Spring Web:带上Spring MVC,可以做Web开发了Thymleaf: Web开发末班引擎(不常用)创建好,如下:static/ 放置静态资源的根目录templates/ 放置模板文件的根目录 二、资源配置…
Java学习记录day6
书接上回
类与对象
static关键字
static的作用:
修饰一个属性:声明为static的变量实质上就是一个全局变量,其生命周期为从类被加载开始一直到程序结束;修饰方法:无须本类的对象也可以调用该方法;修饰一个类&#x…
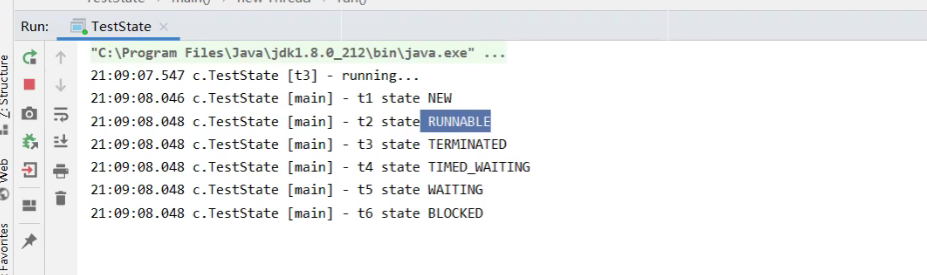
JUC并发编程Ⅰ -- Java中的线程
文章目录线程与进程并行与并发进程与线程应用应用之异步调用应用之提高效率线程的创建方法一:通过继承Thread类创建方法二:使用Runnable配合Thread方法三:使用FutureTask与Thread结合创建查看进程和线程的方法线程运行的原理栈与栈帧线程上下…
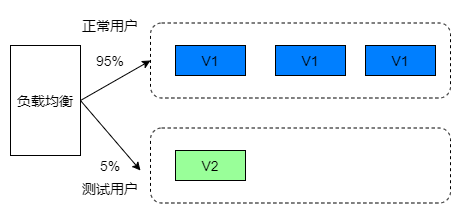
不停服更新应用的方案:蓝绿发布、滚动发布、灰度发布
原文网址:不停服更新应用的方案:蓝绿发布、滚动发布、灰度发布_IT利刃出鞘的博客-CSDN博客
简介
本文介绍不停服更新应用的方案:蓝绿发布、滚动发布、灰度发布。
升级服务器的应用时,要停止掉老版本服务,将程序上传…