- pycharm 设置anaconda环境:
- File -> Settings->选择左侧的project xxx
- 再选择打开Project Interpreter页->选择add添加解释器->添加Anaconda中Python解释器(Anaconda安装目录下的python.exe) (选择existing environment ,然后选择路径(路径可以通过在终端中输入conda info -e查看各个虚拟环境的路径,找到对应虚拟环境的python.exe选择即可))
- python:
- python中对象后加括号调用实际调用的是所属类的__call__方法
- python 中两个*表示打散了
- 装饰器由近及远执行
- python中的构造函数:__new__,析构函数:__del__
- 全局变量的使用:
i=1 def f(): global ii= 2
- conda重置base环境:conda list --revisions(可以看到之前的版本选择回滚到某一版本),如果重置清空,则返回0版本即可:conda install --revision 0
- pytorch :
- model设置不同模式:
- model.eval(),不启用 BatchNormalization 和 Dropout。此时pytorch会自动把BN和DropOut固定住,不会取平均,而是用训练好的值。不然的话,一旦test的batch_size过小,很容易就会因BN层导致模型performance损失较大
- model.train() :启用 BatchNormalization 和 Dropout。 在模型测试阶段使用model.train() 让model变成训练模式,此时 dropout和batch normalization的操作在训练q起到防止网络过拟合的问题。
- model.train(),model.eval(), with torch.no_grad():
- model.train():
- 在train模式下,dropout网络层会按照设定的参数p设置保留激活单元的概率(保留概率=p);
- batchnorm层会继续计算数据的mean和var等参数并更新
- model.eval():
- 在PyTorch中进行validation时,会使用model.eval()切换到测试模式
- model.eval()主要用于通知dropout层和batchnorm层在train和val模式间切换。
- 在val模式下,dropout层会让所有的激活单元都通过,而batchnorm层会停止计算和更新mean和var,直接使用在训练阶段已经学出的mean和var值
- 该模式不会影响各层的gradient计算行为,即gradient计算和存储与training模式一样,只是不进行反传(backprobagation)。
- 使用 with torch.no_grad()
- 主要是用于停止autograd模块的工作,以起到加速和节省显存的作用,具体行为就是停止gradient计算,从而节省了GPU算力和显存,但是并不会影响dropout和batchnorm层的行为。
- 如果不在意显存大小和计算时间的话,仅仅使用model.eval()已足够得到正确的validation的结果;而with torch.no_grad()则是更进一步加速和节省gpu空间(因为不用计算和存储gradient),从而可以更快计算,也可以跑更大的batch来测试。
- model.train():
- 强行改变维度的例子:
if mel_outputs.size()[1]!=tts_seqs.size()[1]:b_size=tts_seqs.size()from torchvision.transforms import Resize torch_resize = Resize([b_size[1],b_size[2]]) # 定义Resize类对象,只能指定修改最后的两个维度,可以借助transpose巧妙使用mel_outputs = torch_resize(mel_outputs)mel_outputs_postnet = torch_resize(mel_outputs_postnet)
- model设置不同模式:
2.11知识点整理(关于pycharm,python,pytorch,conda)
news/2024/11/20 23:18:14/
相关文章
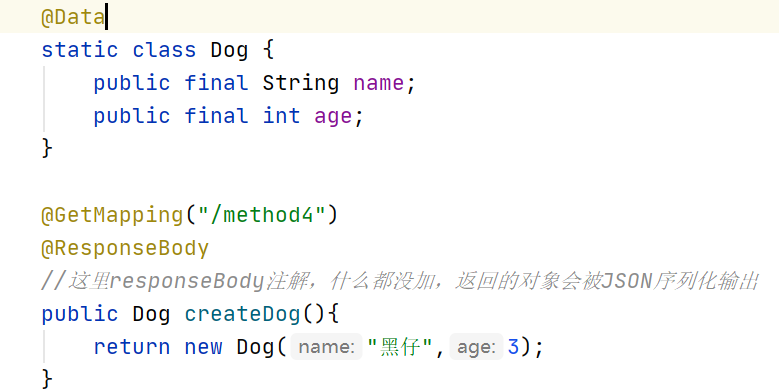
4.SpringWeb
一、创建项目LomBok:辅助开发工具,减少代码编写Spring Web:带上Spring MVC,可以做Web开发了Thymleaf: Web开发末班引擎(不常用)创建好,如下:static/ 放置静态资源的根目录templates/ 放置模板文件的根目录 二、资源配置…
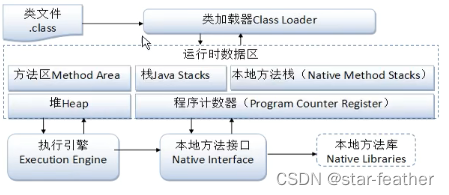
Java学习记录day6
书接上回
类与对象
static关键字
static的作用:
修饰一个属性:声明为static的变量实质上就是一个全局变量,其生命周期为从类被加载开始一直到程序结束;修饰方法:无须本类的对象也可以调用该方法;修饰一个类&#x…
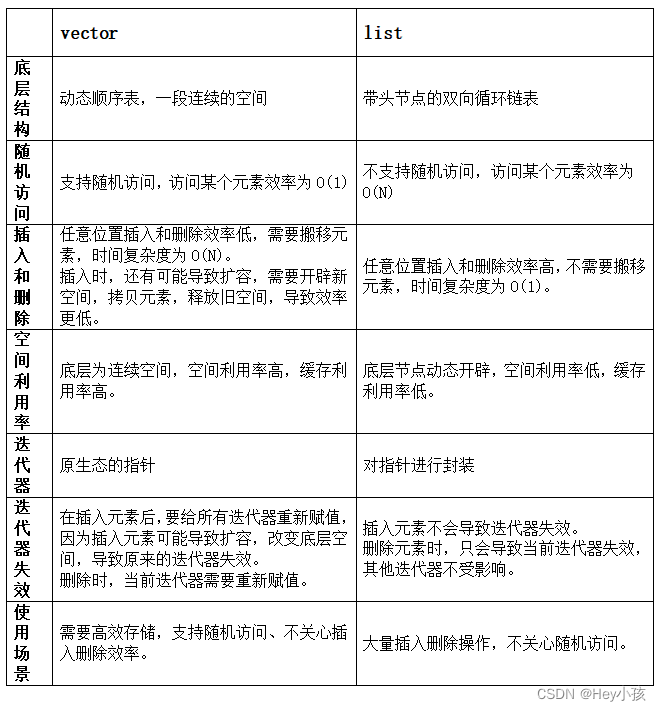
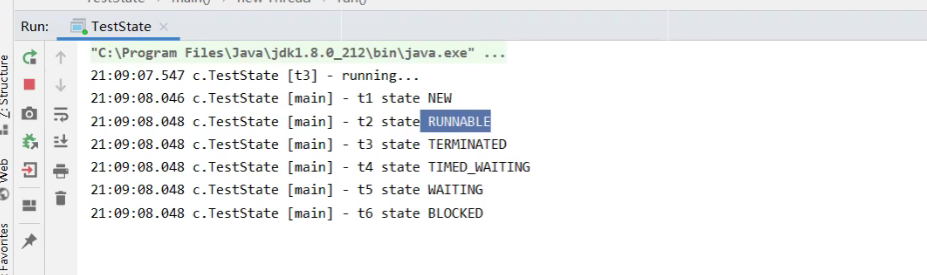
JUC并发编程Ⅰ -- Java中的线程
文章目录线程与进程并行与并发进程与线程应用应用之异步调用应用之提高效率线程的创建方法一:通过继承Thread类创建方法二:使用Runnable配合Thread方法三:使用FutureTask与Thread结合创建查看进程和线程的方法线程运行的原理栈与栈帧线程上下…
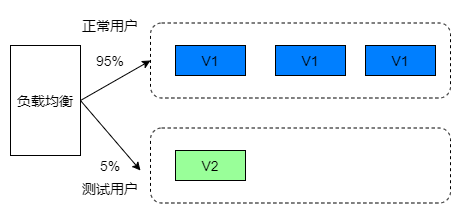
不停服更新应用的方案:蓝绿发布、滚动发布、灰度发布
原文网址:不停服更新应用的方案:蓝绿发布、滚动发布、灰度发布_IT利刃出鞘的博客-CSDN博客
简介
本文介绍不停服更新应用的方案:蓝绿发布、滚动发布、灰度发布。
升级服务器的应用时,要停止掉老版本服务,将程序上传…
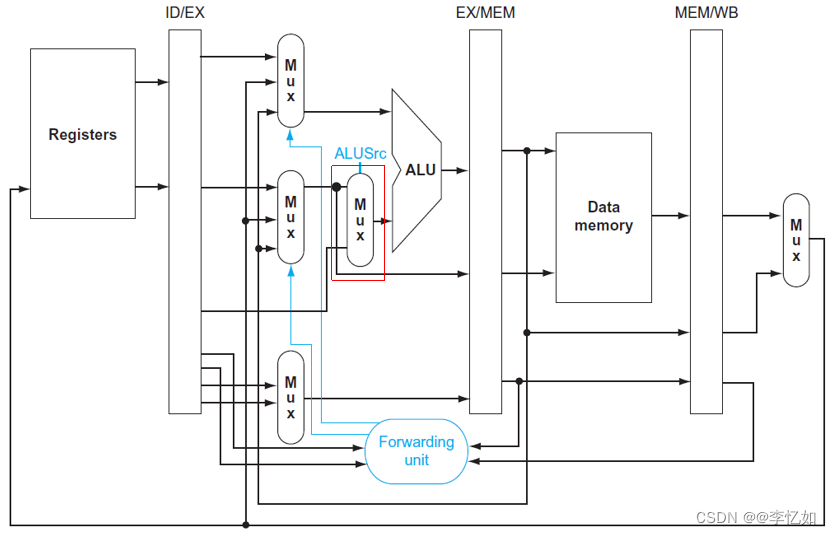
计算机组成与设计04——处理器
系列文章目录
本系列博客重点在深圳大学计算机系统(3)课程的核心内容梳理,参考书目《计算机组成与设计》(有问题欢迎在评论区讨论指出,或直接私信联系我)。
第一章 计算机组成与设计01——计算机概要与技…
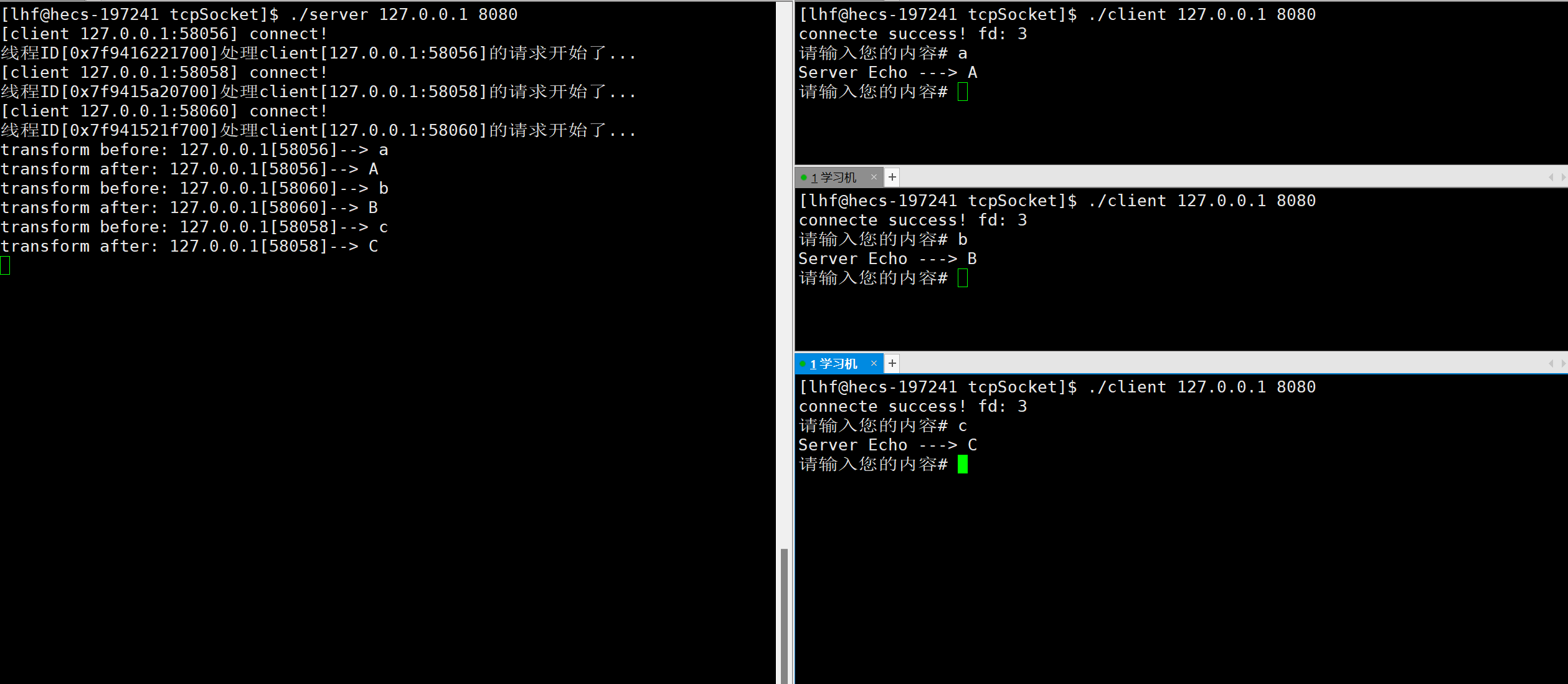
【计算机网络】Linux环境中的TCP网络编程
文章目录前言一、TCP Socket API1. socket2. bind3. listen4. accept5. connect二、封装TCPSocket三、服务端的实现1. 封装TCP通用服务器2. 封装任务对象3. 实现转换功能的服务器四、客户端的实现1. 封装TCP通用客户端2. 实现转换功能的客户端五、结果演示六、多进程版服务器七…
![[数据库]表的增删改查](/images/no-images.jpg)
[数据库]表的增删改查
●🧑个人主页:你帅你先说. ●📃欢迎点赞👍关注💡收藏💖 ●📖既选择了远方,便只顾风雨兼程。 ●🤟欢迎大家有问题随时私信我! ●🧐版权:本文由[你帅…