本期四道题都是在每日一练出现过多次的老题,而且后两道题的思维难度颇大,尤其最后一题-水池注水,如果没有提前准备过,问哥是万万不可能在两个小时内做出来的。所以,拿到这个名次,问哥心里其实很虚。提交之后发现很多人此题没有得分,于是在此将之前解此题的思路与大家分享,共同学习。也希望觉得此题容易的同学一笑而过,或不吝斧正。
第一题:分层遍历二叉树
给定一棵二叉树,节点定义如下: structNode { Node *pLeft; Node *pRight; int data; }; 要求按分层遍历该二叉树,即从上到下按层次访问该二叉树(每一层将单独输出一行),每一层要求访问的顺序为从左到右,并将节点依次编号。
输入描述:输入一行字符串。1(2)表示2是1的子树。(1<=strlen(str)<=1000)
输出描述:输出二叉树的层次。每层占一行。
示例:
示例一 示例二 输入 1(2(4,5(7,8)),3(6)) 1(,) 输出 1
2 3
4 5 6
7 81
分析
此题不难,就是有点麻烦。解题方法也有很多,可以先根据字符串建树,或者使用数组加指针来放置不同层的节点,没有什么特别的技巧。因为字符串里使用嵌套括号来表示“进入下一层”和“返回上一层”,很明显可以使用栈的数据结构来进行模拟。当读到“(”时,说明即将进入下一层,读到“)”时,依次取出栈顶的位置,直到遇到“(”,表示这一层的所有节点。然后再用一个变量 level 表示二叉树中不同的层级。唯一要注意的是因为读入的是字符串,所以节点数字的位数可能大于一,所以需要一个临时变量 num 来保存数字字符,当遇到非数字的字符(“(”、“)”、“,”)时,就将数字字符转化为数字保存在列表里。
参考代码
s = input()
stack = []
level = 1
tree = {}
num = ""
for i in s:if i.isdigit():num += ielse:if num:stack.append(int(num))num = ""if i=="(":level += 1stack.append(i)elif i==")":while stack[-1]!="(":tree.setdefault(level,list()).append(stack.pop())stack.pop()level -= 1
print(1)
for k,v in sorted(tree.items()):print(*sorted(v))第二题:查找整数
给定一个非降序的整数数组,数组中包含重复数字(重复数字很多),给定任意整数,对数组进行二分查找,返回数组正确的位置,给出函数实现: a. 连续相同的数字,返回最后一个匹配的位置;b. 如果数字不存在返回 -1。
输入描述:第一行给定数组长度n,目标值tar。(1<=n,tar<=10000) 第二行给出n个整数a.(1<=a<=10000)
输出描述:按题目描述输出。
示例:
示例一 示例二 输入 7 4
1 2 2 3 4 4 107 4
1 2 2 3 4 10输出 5 4
分析
题目要求二分查找,算法复杂度 ,但实际上直接暴力遍历数组,使用
的复杂度也能pass此题。嗯,怎么说呢,丰俭自由,up to you。
遍历数组的方法就比较简单了,因为数组已经排好序,要求查找目标值的右边界,只要倒序遍历数组即可,一旦发现目标值,即返回坐标,否则遍历完成后返回-1,表示没找到。
参考代码一
n, tar = map(int, input().strip().split())
arr = list(map(int, input().strip().split()))
for i in range(n-1, -1, -1):if arr[i] == tar:print(i)break
else:print(-1)当然,使用二分也并不复杂,直接套模板即可。
参考代码二
n, tar = map(int, input().strip().split())
arr = list(map(int, input().strip().split()))
left, right = 0, n-1
while left < right:mid = (left + right + 1) // 2if arr[mid] <= tar:left = midelse:right = mid - 1
if arr[right] == tar:print(right)
else:print(-1)如果你熟悉python的内置二分模块bisect,自然也可以直接调用模块pass此题。
参考代码三
n, tar = map(int, input().strip().split())
arr = list(map(int, input().strip().split()))
import bisect
res = bisect.bisect(arr, tar)-1
if arr[res] == tar:print(res)
else:print(-1)这就是所谓的“简单题要重拳出击”吧。:D
第三题:小Q整数分割
小Q决定把一个整数n,分割为k个整数。 每个整数必须大于等于1。 小Q有多少方案。
输入描述:输入整数n,k.(1<=n,k<=1e10)
输出描述:输出方案数。答案对1e9+7取模。
示例:
示例一 示例二 输入 3 3 11 45 输出 1 0
分析
印象里本题好像以前考过?按你胃,看到“有多少方案”的字眼,必定会想到动态规划。问题是这题怎么动态?怎么规划?
考虑用数学方程表示题目的要求:假设有 n 个橘子,要放进 k 个筐子里,每个筐子都必须至少有一个橘子,我们用 a 代表筐子, 表示每个筐子里的橘子数量,那么很显然:
对于这每个筐子里橘子数量的分布,可以划分成两种情况:
- 所有筐子里的橘子数量都大于一个,也就是对于
,都存在
;
- 存在至少有一个筐子里的橘子数量为一个,也就是
所以,针对这两种情况,如果用 代表把 n 个橘子放进 k 个筐子的方案数,可以得到状态转移方程如下:
关于第二个转移方程,也就是存在至少有一个筐子里的橘子数量为一时,可以理解为把这个(或其中一个)装有一个橘子的筐子拿走,剩下 个筐子,所以该状态可以从
转移而来。
而第一个方程的理解就有点费脑了:如果所有筐子里的橘子数量都大于一,那么我们把每个筐子里的橘子都拿走一个,总共拿走 k 个,剩下的 k 个筐子里的橘子数量分布依然符合要求(大于等于一)。所以该状态从 转移而来。费脑的地方在于,为什么限定只拿走一个呢?一是题目的要求,所有筐子的橘子数量都必须大于等于一,二是最重要的,为了不重复不遗漏,因为筐子之间无区别,把4分成1+2+1和1+1+2是一样的方案,所以如果拿走两个或以上的橘子,必定会出现重复的方案。上面的数学表达式已经把情况限定在这两种,所以不会出现重复或遗漏的情况。但是在理解上,还需要好好消化。
参考代码
n, k = map(int, input().strip().split())
if n < k: print(0)
else:dp = [[0]*(n+1) for _ in range(k+1)]dp[0][0] = 1for i in range(1, k+1):for j in range(i, n+1):dp[i][j] = dp[i-1][j-1] + dp[i][j-i]print(dp[k][n])思考
由于转移方程只用到了 和
,所以我们可以使用滚动数组优化空间。当然,对本题结果不产生影响,而且以前也介绍过,这里就不赘述了。
但是通过此题,可以发现一个规律,那就是:对于把 n 个物品分成 k 份,每份数量必须大于等于 x 的情况,我们都可以划分成类似的转移方程:
而当 ,也就是允许一些筐子里没有橘子时,上面的转移方程就变成完全背包的模型了,是不是很有意思呢?
第四题:水池注水
给定n*n水池。 向n*n水池中注水。 每行每列只能注水一个方格。 如果一个方格的四周有两个方格已经被水覆盖,则该方格也会被水覆盖。 小Q想知道自己有多少种方案可以使得自己的水池被完全覆盖。
输入描述:给定整数n。(1<=n<=1e5)
输出描述:输出方案数,对1e9+7取模。
示例:
示例 输入 4 输出 22
分析
先说答案:答案是施罗德数列(Schröder number)。
和家喻户晓的斐波那契数列相比,这个数列可谓是默默无闻,谷歌搜到的相关文章也大多是数论专业的论文。但是你依然可以通过搜索前5个数字在OEIS上查到该数列,当然前提是你得先确定当 n 等于 1、2、3、4、5 时的答案是 1、2、6、22、90。
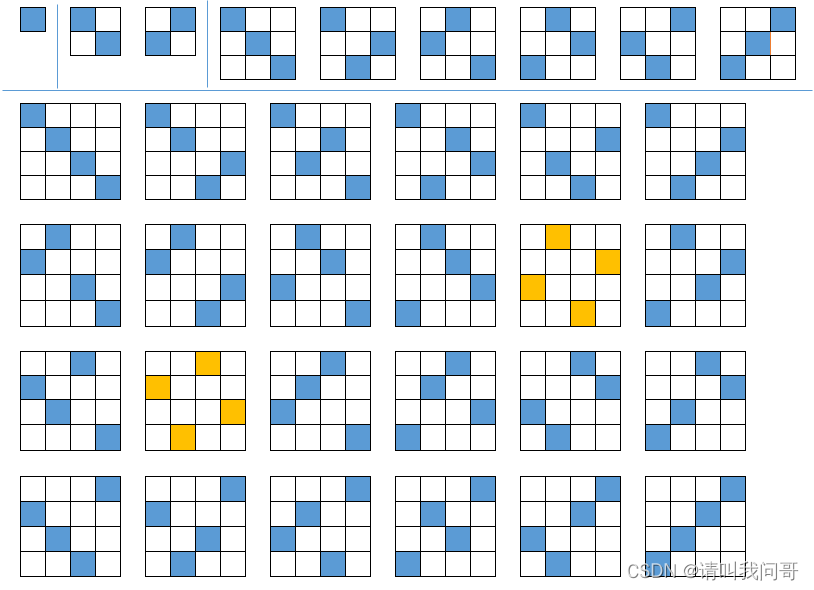
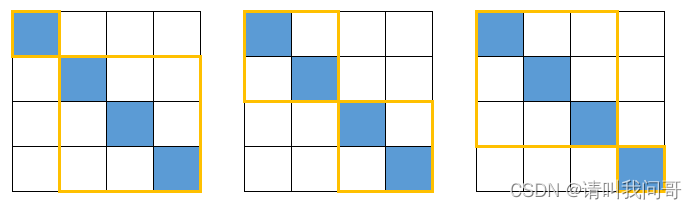
再说回题目,讲讲问哥是怎么找到这个数列的。下图简单列出当 n = 1、2、3、4 时的注水方案,橘色为不可行的方案:
题目给出了两个条件:
- 每行每列只能注水一个方格。
- 如果一个方格的四周有两个方格已经被水覆盖,则该方格也会被水覆盖。
条件 1 听上去很像 N 皇后问题,所以自然可以通过深度搜索算法去找出所有符合条件 2 的注水方法,n 行 n 列,最多 n 个注水口。但是(不考虑剪枝的最坏情况)这种算法的时间复杂度是 ,当 n 很大时,及其不现实,而且这还没有计算检查是否符合条件 2 的时间。
条件 2 很关键,根据这个条件,如下图所示的方格,只有当1、2、3、4四个方格中的两个有水时,方格5才会被水覆盖。但是又由于条件 1,方格1和方格3、方格2和方格4不可能同时注水(处于同一行或同一列),于是,要想水蔓延开来,必须也只需考虑初始注水点在对角线方向相连的情况。
然而——关键的来了——当两个注水点对角线相连的时候,根据条件 2,这两个注水点相邻的另外两个方块也必定会被水覆盖,从而形成一个 2 x 2 的“大”方格,然后又必须和下一行或列的某一个有水的方格在对角线相连,形成一个 (n+1) x (n+1) 的“更大”方格,然后不断重复此过程,直到水池注满水。
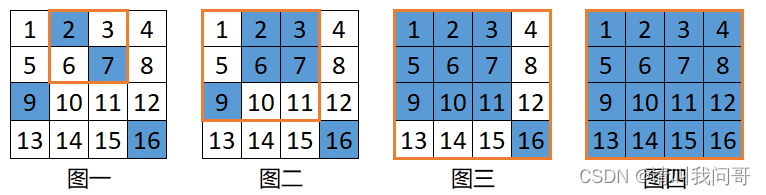
比如上图中,起始注水点 2 和 7 对角线相连(图一),于是方块 3 和 6 也必然被水覆盖,形成一个 2 x 2 的“大”方格(图二);然后该方格又和注水点 9 对角线相连,于是5、10、1、11四个方格也会被水覆盖,形成一个 3 x 3 的“更大”方格(图三);最终,该方格和最后一个注水点 16 对角线相连,于是整个 4 x 4 的水池注满水(图四)。
于是——同样关键——逆向思考,要想整个水池注满水,上面步骤的倒数第二步(图三)就必须要实现两个大方格(或注水点)对角线相连。
如果要实现倒数第二步的那种状态,以 4 x 4 的水池为例,可以分成以下 6 种情况:
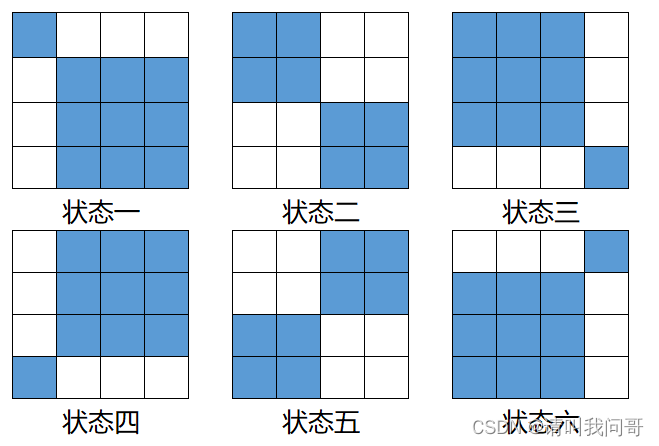
任何能够使 4 x 4 的水池注满水的方案,必定会达到上面6种状态的其中之一。而上面每种状态的方案数都等于对角线两个方块各自的方案数的乘积。
如果用 代表 4 x 4 的水池注满水的方案数的话,似乎马上就可以根据上图得到以下状态转移方程:
但是别急,不难发现,上面6种状态中存在了不少重复的方案。比如下面这种方案同时可以得到状态一和状态二:
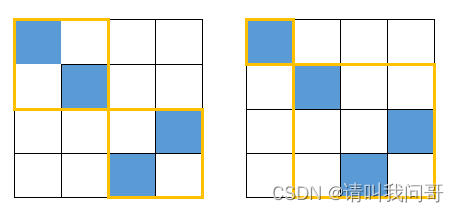
而下面这种方案可以得到状态一、二、三:
原因是由于左上角和右下角的两个方格被重复计算,而重复的次数为该状态中左上角出现的次数加上右下角出现的次数——略去数学推导——结论就是除了第一个状态,其余状态的方案数都要减半(除以2)。
值得一提的是,状态一、二、三和状态四、五、六之间不可能出现重复的情况(前者是左上和右下角,而后者是右上和左下角),但他们之间是严格对称的,包括重复方案数也一样。所以只要计算出上半部分状态的方案数,再乘以 2 即可。于是得到正确的推导式为:
展开得到:
由于 ,带入
即可变为通用推导公式如下:
到这里,本题在算法的层面上就算是解出来了,由该公式可知算法复杂度为 。但是,若非本题的数据范围太过变态,无法pass此题,我是不会发现这个鲜为人知的施罗德数列的,更加不会发现这个数列还有更加简单的复杂度为
的推导公式。
如果你看过在一开始的维基百科页面,就会发现这个数列的数字有多么恐怖。由于是乘积的累加,如果不对结果取模,当 时,也就是该数列第100位的数字为:
5006655111336460402472381082547036154743871773943263346408958078720471894
已经是一个天文数字了,而当 时,第1000位的数字如下:
15645900994341365050828818007549319184903485198422408335608426998340615858178201940169845962789298835120184122681758501303895861272029768948635408022055515900368119470134711688030518076179683439072894424075608681334061201446058674567727821524339681815453636232225887651033061896028703570856322393505559162884589888266707967810838943476409364505917182624994270918964191764601008296203462107497655765483930668162488247286128052040921632241026902310832024980141188859785051453714192473724129414657547472723633186199584993441328231178115250213759177713947013602688048355871066154633693942170981542036773946801154018981724758280714698897476779366860416409302681976324845626500893237511913136855310864971162386771444410826033550970236999427354069883375800404487036334
而本题里 ,是上面的100倍。你敢相信,我用python不取模地计算第100000位数字时把电脑内存搞崩溃了,更不用说耗时了。
但是本题要求的是结果对1e9+7取模,想必是料到了该数列的天文数字,所以我们不需要保存完整的结果,每一步都只要保存取模后的余数即可。根据模运算的结合律和分配律,这和对最终结果取模是等价的。
先给出根据上面的思路写出的代码:
参考代码一
n = int(input().strip())
dp = [0]*(n+1)
dp[1] = 1
for i in range(2, n+1):temp = 0for j in range(1, i):temp += (dp[j])*(dp[i-j])dp[i] = (dp[i-1] + temp)%1000000007
print(dp[n])由于取模也需要时间,所以这里只对每个dp的结果取模,没有对中间的累加值 temp 取模。然而当 n=10000 时,运行时间达到了3秒,而当 n=100000(本题的极值)时,更是需要4分多钟的时间。
10000
907566661
耗时: 3.1507670879364014 秒
100000
57979565
耗时: 247.73565459251404 秒显然这是不可能pass此题的。于是当我意识到超出我的能力范围后,不得不求助于外网,从而找到了一开始介绍的维基百科页面,了解到这么一个数列,并注意到如下的推导方程式:
很显然,这是 的算法啊!
我也搞不懂这些人是怎么从上面 的公式转化过来的(有专门一篇论文,可是我看不懂T_T),但既然有现成的,为什么不拿过来用呢?
参考代码二
n = int(input().strip())
if n <= 2: print(n)
else:MOD = 1000000007dp = [0] * ndp[0] = 1dp[1] = 2for i in range(2, n):dp[i] = dp[i-1]*(6*i-3)//(i+1) - dp[i-2]*(i-2)//(i+1)print(dp[n-1] % MOD)果然,速度得到了很大的提升,然而在测试极值(100000)的时候还是需要5秒,无法在题目要求的1秒内完成计算。
10000
907566661
耗时: 0.06401371955871582 秒
100000
57979565
耗时: 5.330229043960571 秒也许你注意到了,这一次我没有对过程中的dp取模,而只是在最后输出结果的时候取模,这是因为模运算的分配律不支持除法,也就是说
而我们 的推导公式中存在除法,所以无法简单地将模运算应用到每个dp中去(这样做的结果是错误的)。想必是因为过程中的dp数字太大,导致速度变慢的缘故。
那么有没有办法对过程中参与除法计算的dp状态值取模呢?当然有!不然你让C++的同学怎么玩?
这里就不得不引入一个新概念——逆元。原谅问哥自己都还没有完全搞明白-_-|。简单来说,如果存在一个数字,使得
,那么数字
就是数字
的逆元。而逆元与除法模运算的关系如下:
于是,只要得到数字 1 到 n+1 的逆元,就可以对代码二中的递推公式进行模运算的优化了。
感谢这篇文章(虽然也是转载的),我得到了 复杂度的逆元计算公式。将文章里的计算公式无脑带入,然后更新代码如下:
参考代码三
n = int(input().strip())
if n <= 2: print(n)
else:MOD = 1000000007inv = [0] * (n+1)inv[1] = 1for i in range(2, n+1):inv[i] = (MOD - MOD // i) * inv[MOD % i] % MODdp = [0] * ndp[0] = 1dp[1] = 2for i in range(2, n):dp[i] = (dp[i-1]*(6*i-3)*inv[i+1]%MOD - dp[i-2]*(i-2)*inv[i+1]%MOD)%MODprint(dp[n-1] % MOD)用极值测试结果:
10000
907566661
耗时: 0.00800180435180664 秒
100000
57979565
耗时: 0.06801486015319824 秒完美!