文章目录
- 📚概述
- 🐇存储器分类
- 🐇存储器的层次结构
- 🥕原理
- 🥕主存速度慢的原因
- 🥕存储器三个主要特征的关系
- 🥕缓存-主存层次和主存-辅存层次⭐️
- 📚主存储器
- 🐇概述
- 🥕主存的基本组成
- 🥕主存和CPU的联系⭐️
- 🥕存储单元地址的分配(大端小端⭐️)
- 👀按字寻址和按字节寻址⭐️
- 🥕主存的技术指标
- 🍃存储容量
- 🍃存储速度
- 🍃存储器的带宽
- 🐇半导体存储芯片
- 🥕半导体存储芯片的基本结构
- 🥕芯片容量计算及芯片选用⭐️
- 🐇随机存取存储器(RAM)
- 🥕RAM分类
- 🥕动态RAM刷新⭐️
- 🍃集中刷新
- 🍃分散刷新
- 🍃异步刷新
- 🐇存储器的扩展及与CPU连接⭐️⭐️⭐️
- 🥕存储器容量的扩展
- 🍃位扩展(增加存储字长)
- 🍃字扩展(增加存储字的数量)
- 🍃字位扩展(上述二者结合)
- 🥕存储器与CPU的连接
- 🔑【存储器和CPU连接】技巧总结(感悟版)
- 🐇存储器的校验
- 🥕求海明校验码⭐️
- 🥕海明码检验⭐️
- 🔑【海明码检验】技巧程序化
- 🐇提高访存速度的措施
- 🥕细说调整主存结构
- 🍃单体多字系统
- 🍃多体并行系统
- 🔑求【顺序存储】和【交叉存储】的带宽
- 📚高速缓冲存储器
- 🐇概述
- 🥕问题的提出(解答题🔔)
- 🥕Cache的工作原理
- 🔑【Cache命中率】及【Cache-主存系统的效率】
- 🥕Cache的基本结构(了解)
- 🥕Cache的读写操作(了解)
- 🥕Cache的改进(了解)
- 🐇Cache-主存的地址映射
- 🥕直接映射
- 🥕全相联映射
- 🥕组相联映射
- 🥕Cache替换算法(了解)
- 🥕Cache容量计算⭐️⭐️
- 🍃方法
- 🍃例题
- 📚小结
- 🔑本章掌握要点
📚概述
存储器保存内容:程序和数据
🐇存储器分类

🐇存储器的层次结构
🥕原理

🥕主存速度慢的原因
- 主存增速与CPU增速不同步
- 指令执行期间多次访问存储器
🥕存储器三个主要特征的关系
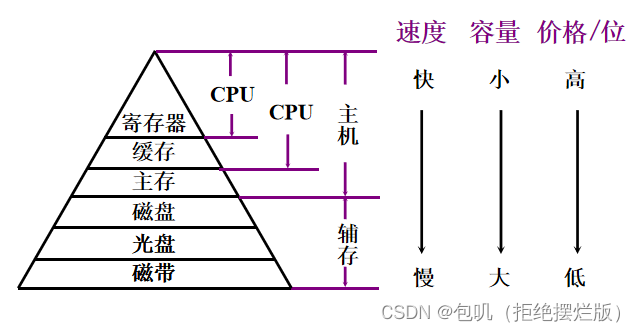
🥕缓存-主存层次和主存-辅存层次⭐️
局部性原理
- 时间局部性:现在被访问的信息在不久的将来还将再次被访问,程序结构体现:循环结构
- 空间局部性:现访问信息,下一次访问其附近的信息,程序结构体现:顺序结构
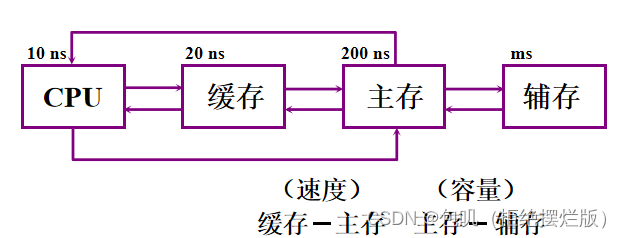
- Cache缓存:解决CPU与主存速度不匹配的矛盾——
缓存-主存层次起加速作用 - 主存:冯诺依曼计算机体系结构
- 辅存:解决主存容量不足与高成本矛盾——
主存-辅存层次起扩容作用
计算机存储系统采用分级方式主要是为了解决容量、速度、价格三者的矛盾
📚主存储器
🐇概述
🥕主存的基本组成
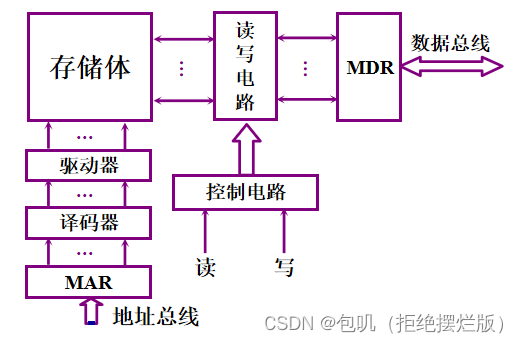
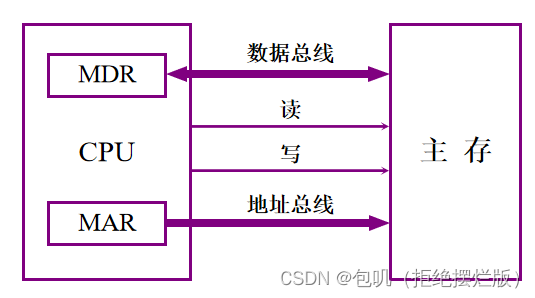
MAR:存储器地址寄存器
MDR:存储器数据寄存器
🥕主存和CPU的联系⭐️
🥕存储单元地址的分配(大端小端⭐️)
数据存储与边界的关系(了解)
- 按边界对齐的数据存储
理解:总体来看,放不下就另开一行,放得下就挤一挤- 未按边界对齐的数据存储
理解:挤着来(虽然节省了空间,但增加了访存次数)C语言变量在内存分配字节数(了解)
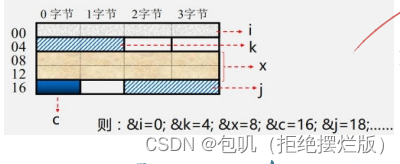
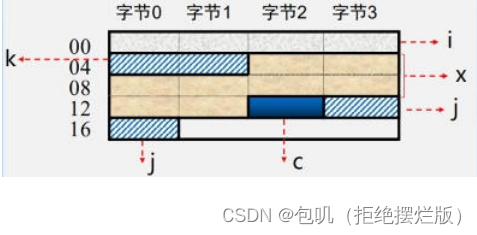

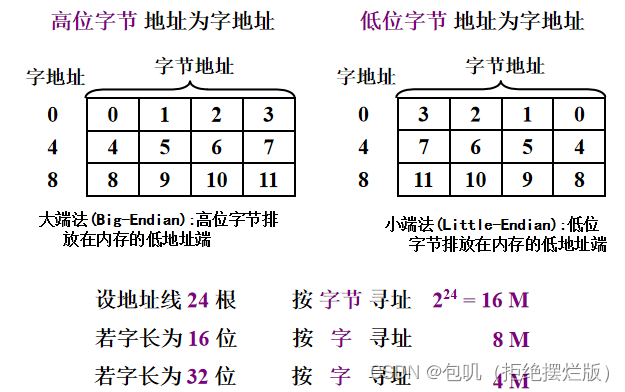
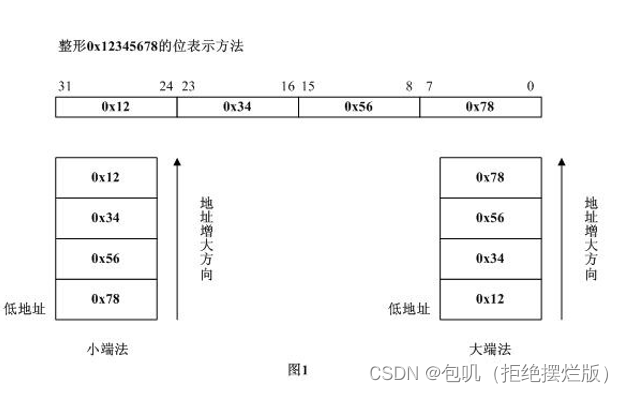
理解:大端就是按顺序来,小端就是倒着来
对于24位地址线的主存而言
- 若字长为32位:
- ①按字节寻址的范围为16M。【2242^{24}224B / 1B=16M】
- ②按字寻址的范围为4M。【2242^{24}224B / 4B = 4M】
- 若字长为16位:
- ①按字节寻址的范围为16M。【2242^{24}224B / 1B=16M】
- ②按字寻址的范围为8M。【2242^{24}224B / 2B = 8M】
- 1MB = 2202^{20}220B
- 👇下边有详解~
👀按字寻址和按字节寻址⭐️
- 基本概念
- 字长:表示机器CPU的处理能力,即CPU在单位时间内能处理的最大二进制数的位数称为字长
- 若字长为32位,表明存储器一次可以处理4个存储单元,指令长度为4个存储单元。
1字节 = 1B= 8b = 8位1字 = 4B= 32b = 32位
- 若字长为32位,表明存储器一次可以处理4个存储单元,指令长度为4个存储单元。
- 位 :数据存储的最小单位,一个位的取值只能是0或1
- 字节(B/Byte):1个字节等于8位,即
1Byte=8bit - 字 :在计算机中,一串数码作为一个整体来处理或运算的,称为一个字。字的位数称为字长;字通常分若干个字节。
- 寻址空间与寻址范围:
- 寻址范围只是一个数字范围,不带有单位
- 而寻址范围的大小指的是寻址空间的大小,寻址空间指能够寻址的最大容量, 单位一般用MB、B来表示。
- 字长:表示机器CPU的处理能力,即CPU在单位时间内能处理的最大二进制数的位数称为字长
- 按字寻址
- 一组地址线的每个不同状态对应一个字的地址,存储空间的最小编址单位是字。
- 一个字由若干个字节构成,所以计算机在寻址过程中会区分字里面的字节,即会给字里面的字节编址,这样就会占用部分地址线
- 例如,有24根地址线,机器字长为16位,若按字寻址的话,16位=2个字节,需要占用一根地址线用来字内寻址,这样就剩下23根地址线,故按字寻址范围是2^23,也就是8M。【真正用于按字寻址的地址线只有24-1=23根】
- 一组地址线的每个不同状态对应一个字的地址,存储空间的最小编址单位是字。
- 按字节寻址
- 一组地址线的每个不同状态对应一个字节的地址,存储空间的最小编址单位是字节。
- 例如,对24位地址线的主存而言(也就是有24根地址线),按字节寻址,每根线有两个状态,那么24根地址线组成的地址信号就有2242^{24}224个不同的状态,每个状态对应一个字节的地址空间的话,那么24根地址线的可寻址空间为2242^{24}224B,即16MB。
- 一组地址线的每个不同状态对应一个字节的地址,存储空间的最小编址单位是字节。
🥕主存的技术指标
🍃存储容量
主存存放二进制代码的总位数
存储容量 = 存储单元个数 × 存储字长(每个存储单元的位数)- 也可用字节总数来表示:
存储容量 = 存储单元个数 × 存储字长/8
🍃存储速度
- 存取时间:存储器的访问时间(读出时间 < 写入时间)
- 存取周期:连续两次独立的存储器操作(读或写)所需的最小间隔时间
- 因为存取周期内,存取操作结束后仍需要一段时间来更改状态,即
存取周期 = 存取时间 +恢复时间,所以存取时间 < 存取周期
🍃存储器的带宽
带宽 = 时钟频率 × 总线宽度带宽 = 存储字长/存储时间- Mbps = Mb/s
- 8Mbps换算成下载速度就是1MB/s
🐇半导体存储芯片
🥕半导体存储芯片的基本结构
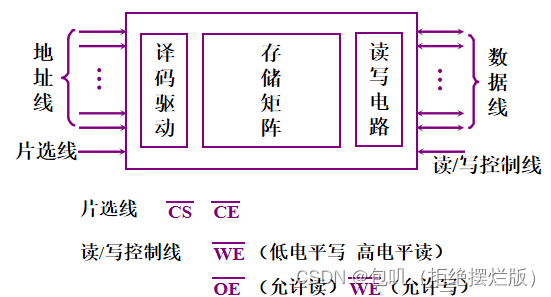
- 地址线是单向输入的,其位数与芯片容量有关
- 数据线是双向的,其位数与芯片可读出或可写入的数据位数有关
🥕芯片容量计算及芯片选用⭐️

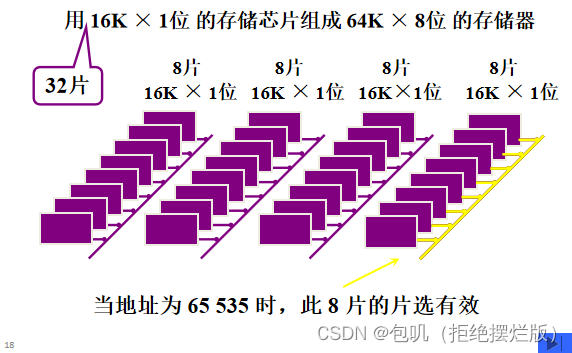
👀在题目中体悟方法,直接上题目——
- 一个16K×32位的存储器,其地址线和数据线的总和是多少❓
- 选用如下规格(A.1K×4位芯片 B.4K×8位芯片)的存储器芯片时,需要多少片❓
- 内存的容量有多少,就是用多少个二进制数表示,地址线的条数就是多少根。
- 16K是其容量大小,16K=2142^{14}214,故地址线14根;
- 1K = 2102^{10}210
- 数据线指一次传输的数据的宽度,32位的宽度需要用32根数据线。
- 故总和为14+32=46根。
- 片数确定
- A.(16K×32)/(1K×4)=16×8=128片
- B.(16K×32)/(4K×8)=4K×4=16片
已知存储器的容量为1MB,那地址线和数据线一共多少根❓
- 只要写成n MB的形式,一律默认为n M × 8
- 1MB可以写成1M×8
- 1M = 2202^{20}220,因此地址线为20根
- 数据线为8根,一共28根
🐇随机存取存储器(RAM)
🥕RAM分类
- 静态存储器:利用双稳态触发器存储信息,速度快,非破坏性读出
- 用途:高速缓存。
- 动态存储器:依靠电容上的存储电荷存储信息,集成度最高,但信息易失,需要定时刷新内容
- 用途:作主存。
| 比较 | 动态RAM(DRAM) | 静态RAM(SRAM) |
|---|---|---|
| 存储原理 | 电容 | 触发器 |
| 集成度 | 高 | 低 |
| 芯片引脚 | 少 | 多 |
| 功耗 | 小 | 大 |
| 价格 | 低 | 高 |
| 速度 | 慢 | 快 |
| 刷新 | 有 | 无 |
🥕动态RAM刷新⭐️
👀因为动态存储器依靠电容上的存储电荷存储信息,集成度最高,但信息易失,所以需要定时刷新内容
👀动态RAM时序——行列地址分开传送
👀刷新与行地址有关。刷新是一行行进行的,必须在刷新周期内,由专用的刷新电路来完成对基本单元电路的逐行刷新,才能保证DRAM内的信息不丢失。

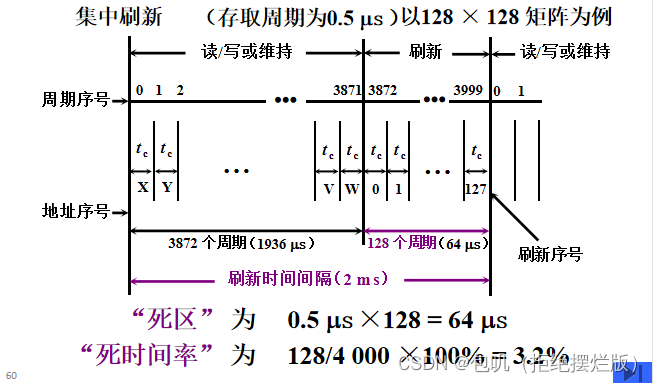
🍃集中刷新
- 集中刷新是在规定的一个刷新周期内,对全部存储单元集中一段时间逐行进行刷新,此刻必须停止读/写操作。
- 速度高,但死时间长,关注死区和死时间率
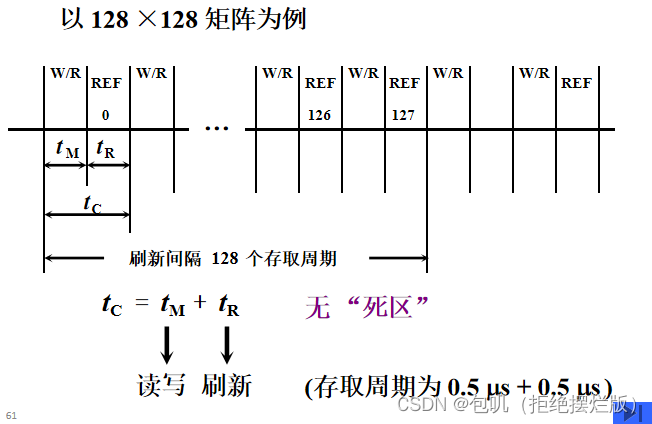
🍃分散刷新
- 分散刷新是指对每行存储单元的刷新分散到每个存取周期内完成。其中,把机器的存取周期tCt_CtC分成两段,前半段tMt_MtM用来读/写或维持信息,后半段tRt_RtR用来刷新。
- 即在每个存取操作后绑定一个刷新操作,延长了存取周期,这样存取周期就成了0.5μs + 0.5μs =1μs,也就不需要专门给出一段时间来刷新了
- 这样,每有128个读取操作,就会把0-127行全部刷新一遍。故每隔128μs 就可将存储芯片全部刷新一遍,即刷新周期是1μs×128=128μs,远短于2ms。
- 不存在停止读/写的死时间,但是存取周期长了,整个系统速度降低了。
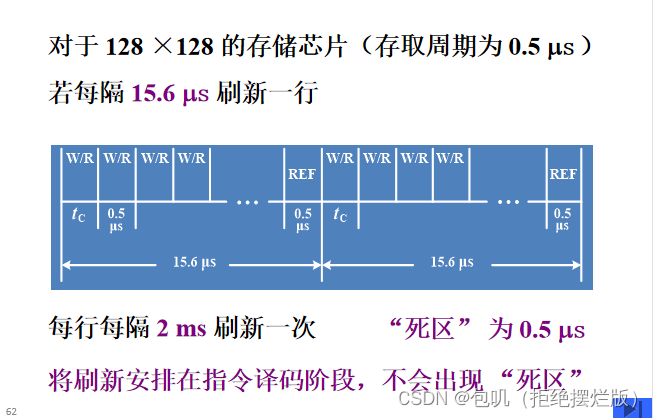
🍃异步刷新
- 分散刷新与集中刷新相结合,既可以缩短“死时间”,又充分利用最大刷新间隔为2ms的特点
- 具体操作为:在2ms内对128行各刷新一遍,即每隔15.6μs刷新一行(2000μs/128≈15.6μs),而每行刷新的时间仍为0.5μs。
- 这样,刷新一行只能停止一个存取周期,对每行来说,刷新间隔时间仍为2ms,而死时间为0.5μs。相对每一段来说,是集中式刷新,相对整体来说,是分散式刷新
- 如果将DRAM的刷新安排在CPU对指令的译码阶段,由于这个阶段CPU不访问存储器,所以不会出现“死区”问题,从根本上上提高了整机的工作效率。
🐇存储器的扩展及与CPU连接⭐️⭐️⭐️
🥕存储器容量的扩展
存储容量 = 存储单元个数 × 存储字长
- 存储单元个数扩展——>字扩展
- 存储字长扩展——>位扩展
🍃位扩展(增加存储字长)
位扩展就是将两个存储芯片当成一个存储芯片来用,让两个存储芯片同时工作,同时被选中,同时做读/写操作。要想保证同时,就是把两个芯片的片选CS,用相同的信号连接
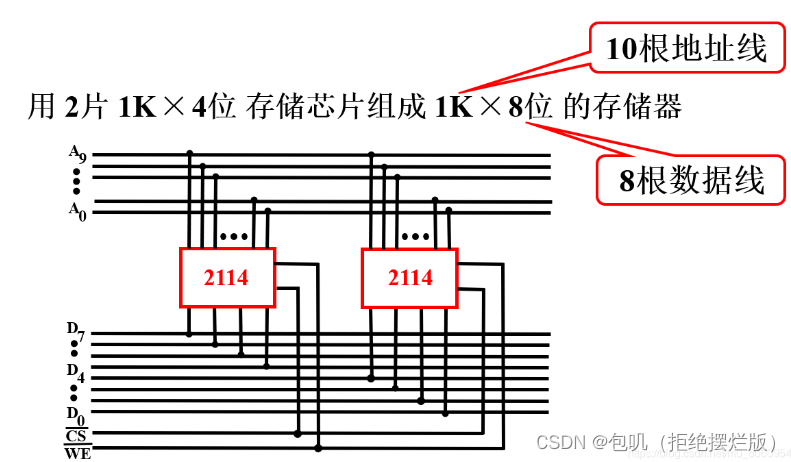
2片1K X 4位的芯片,可以组成1K X 8位的存储器(4位→8位)

🍃字扩展(增加存储字的数量)
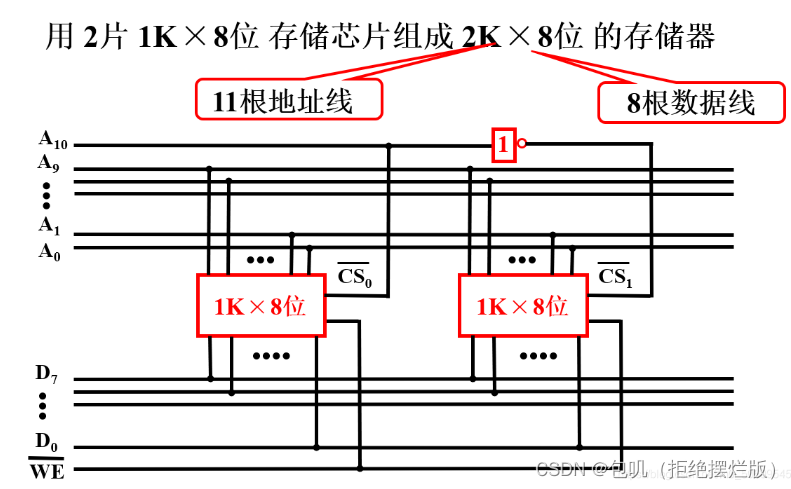
2片1K X 8位的芯片,可以组成2K X 8位的存储器(1K→2K)

🍃字位扩展(上述二者结合)
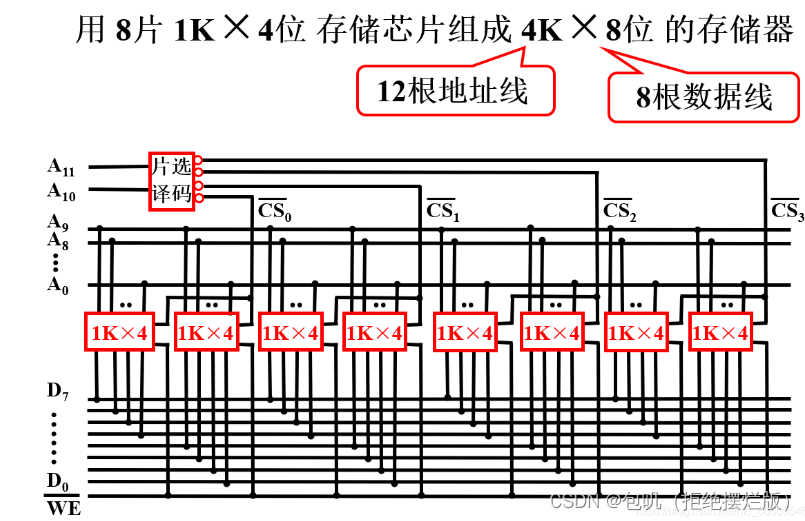
1K X 4位的芯片,组成4K X 8位的存储器(1K→4K,4位→8位)

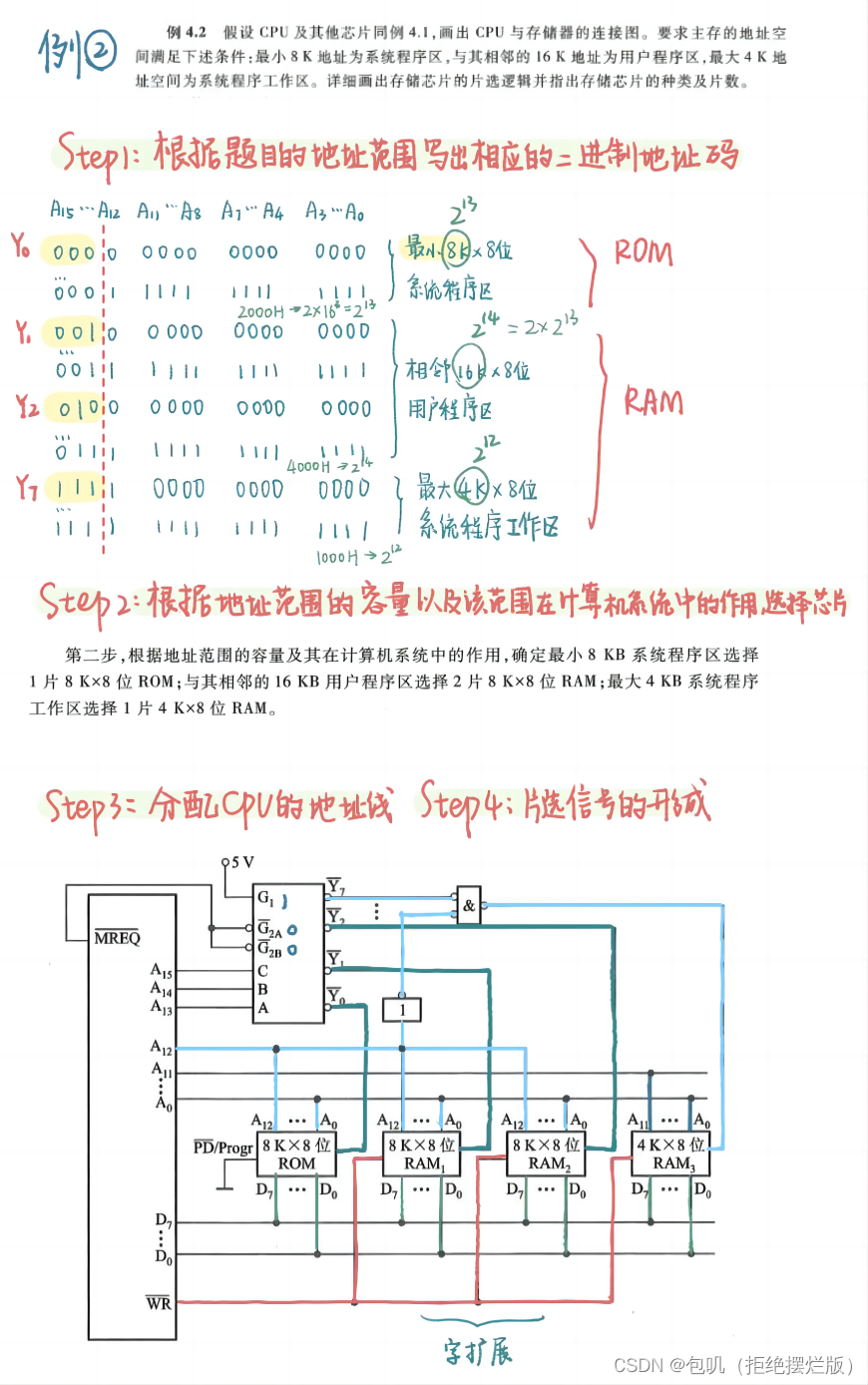
🥕存储器与CPU的连接

上边这张图是理论上的方法,但我个人觉得没啥用 ,这里贴一个讲的很好的小破站视频,用一道例题把细致的点几乎都讲到了,点此直达,看完视频后建议再过一下以下两道例题,应该就能懂啦~
上例题!
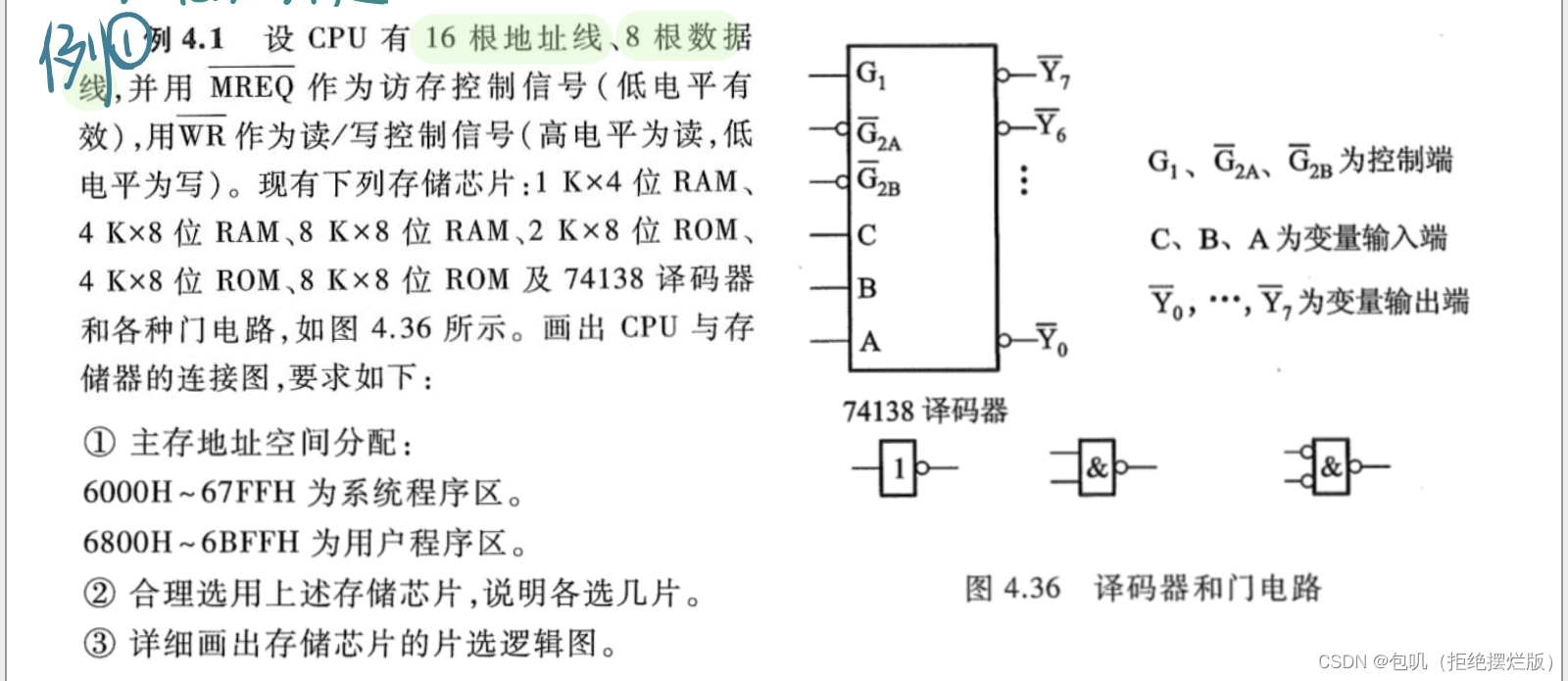
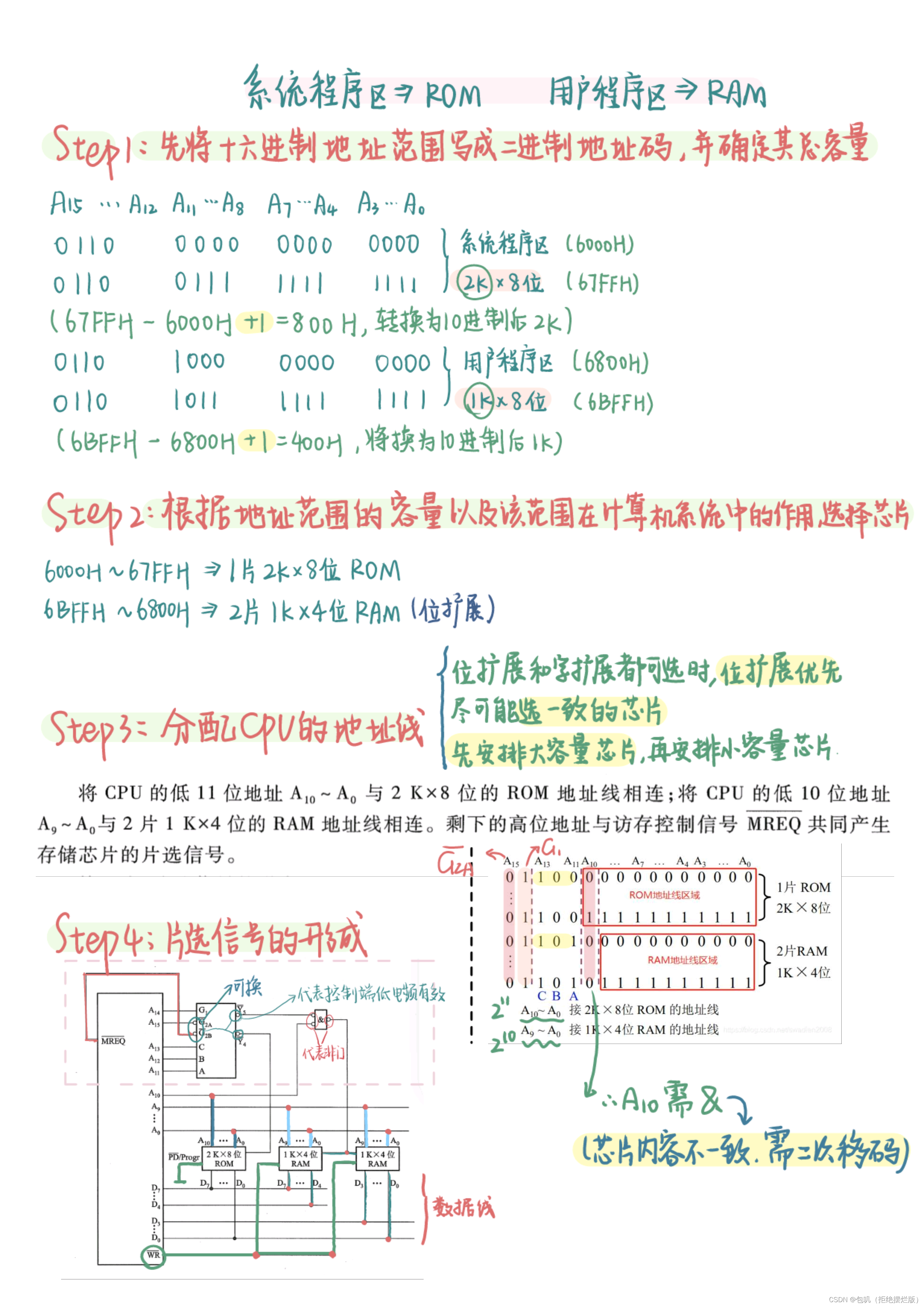
补大图
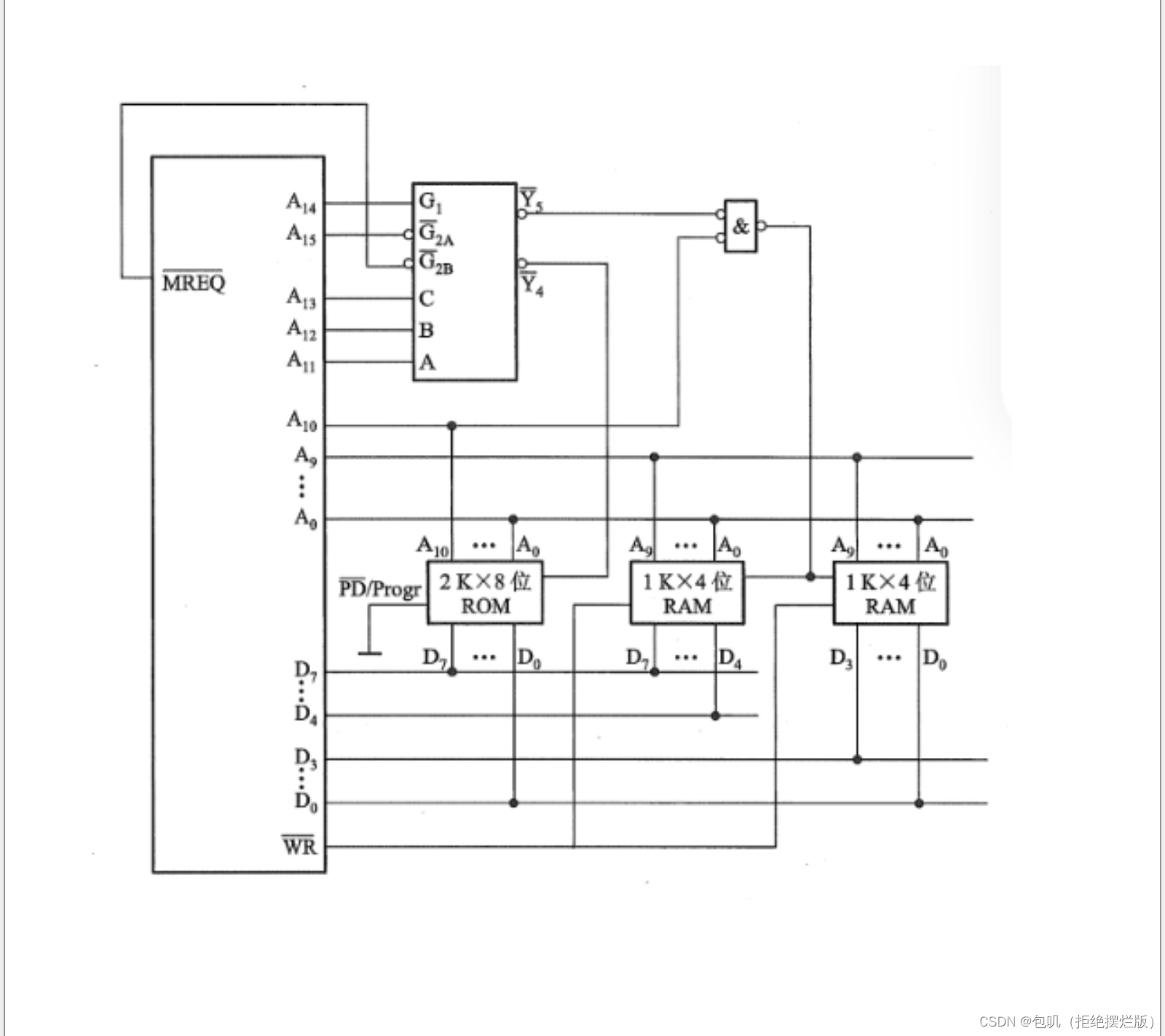
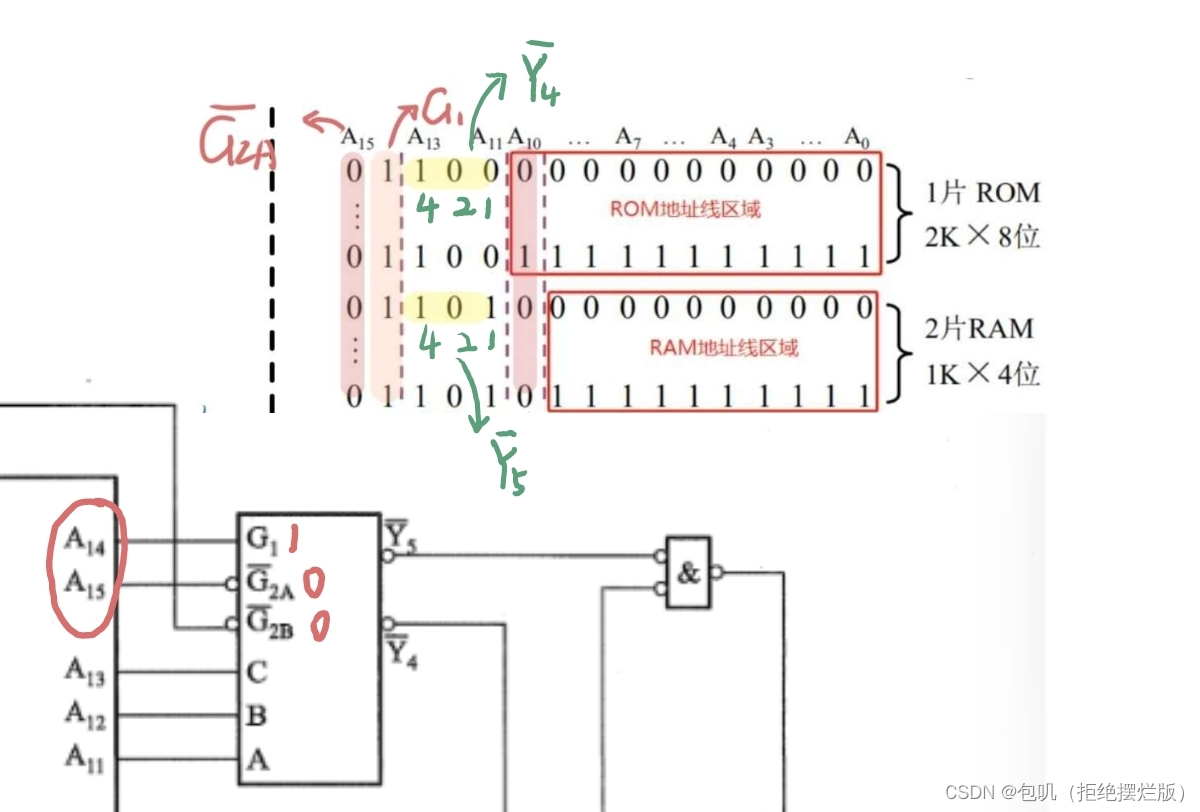
🔑【存储器和CPU连接】技巧总结(感悟版)
-
系统程序区——>ROM,用户地址区——>RAM -
字扩展和位扩展都可选时,首选位扩展(位扩展优于字扩展优于字位扩展)
-
G1G_1G1高电平,G‾2A\overline{G}_{2A}G2A,G‾2B\overline{G}_{2B}G2B低电平,Y‾0到Y‾7\overline{Y}_0到\overline{Y}_7Y0到Y7都是低电平,低电平要画小圈圈
-
G1G_1G1若有空余,外接5V
-
MREQ‾\overline{MREQ}MREQ把它看作是0,如果最后G1G_1G1只能和它连,但是G1G_1G1按道理要连1,那就在它俩之间加一个非门
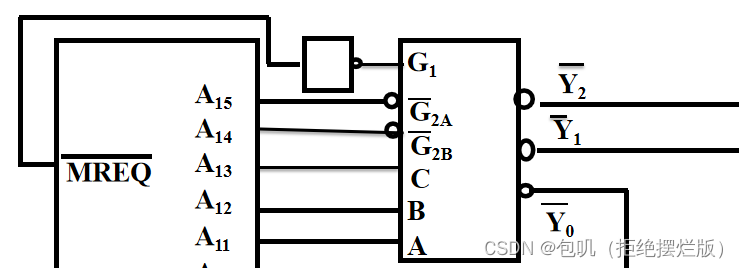
-
RAM连接WR‾\overline{WR}WR,ROM只读外接PD‾/Progr\overline{PD}/ProgrPD/Progr
-
关于二进制地址码
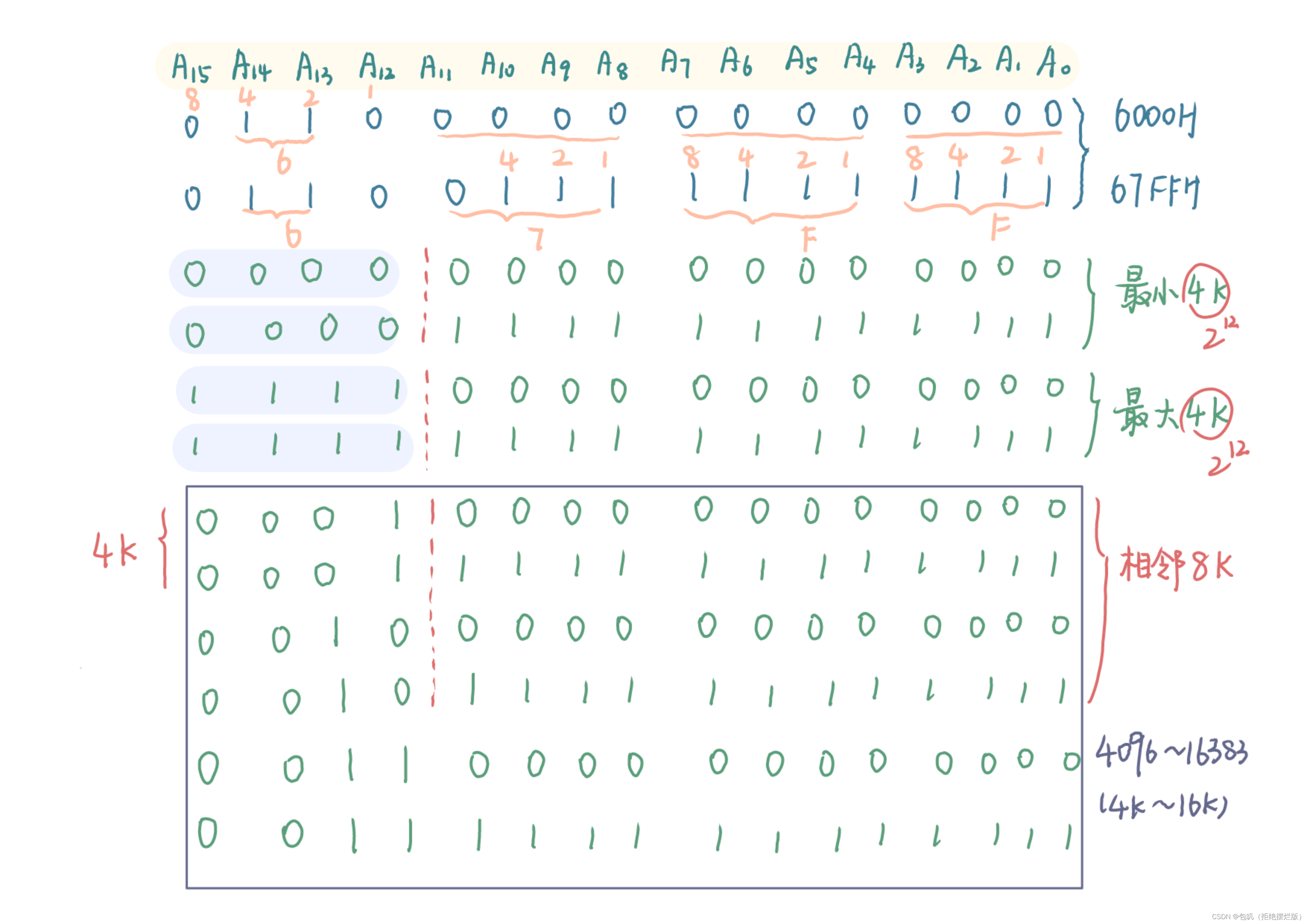
🐇存储器的校验
- 同一编码中,任意两个合法编码之间相应位不同的数目称为码距
- 计算方法:对两个位串进行异或运算,并计算异或运算结果中1的个数
110⊕011=101——>110和011之间码距等于2- 码距越大,抗干扰能力越强,纠错能力越强,编码效率低
🥕求海明校验码⭐️
海明校验:在位序是2的整数次幂的位置放置检验位,其他位置放有效信息
- m个数据 + k个校验位 = m+k个码字
- m+k+1≤2k2^k2k
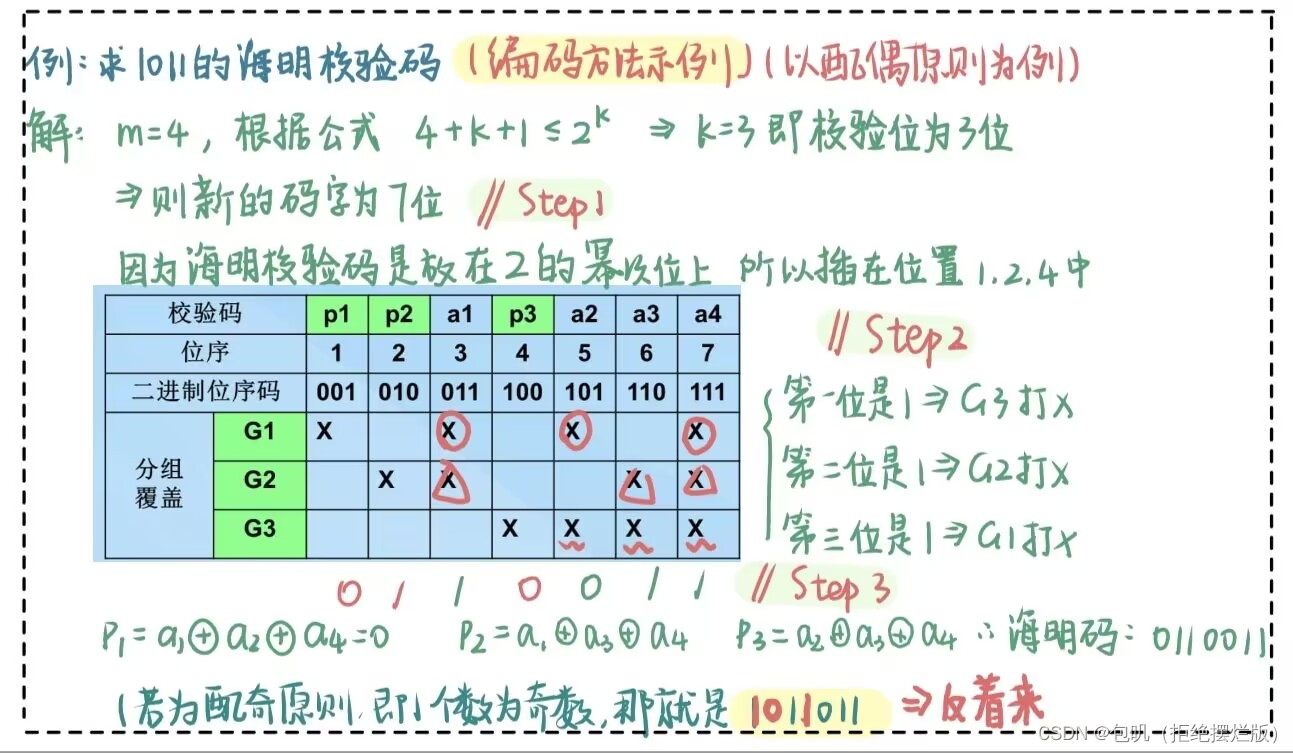
🥕海明码检验⭐️
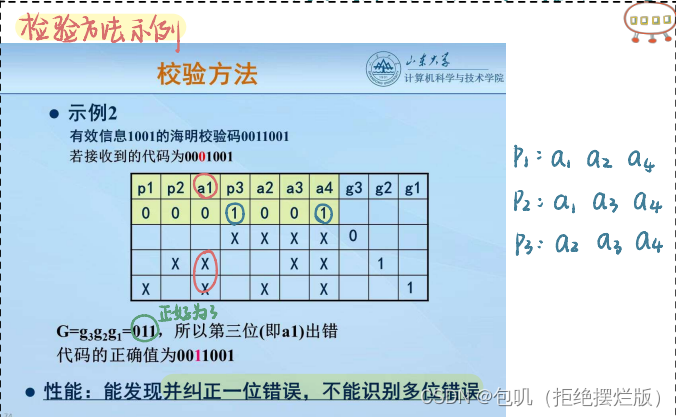
- 错误字G指明
- 当G等于全0时,无错误
- 当G不等于0时,代码错误,G指明位置
- 错误字g4g3g2g1=0000g_4g_3g_2g_1=0000g4g3g2g1=0000 不一定无错,存在同时出错反而显示正确的情况
- 海明校验只能发现并纠正一位错误,不能识别多位错误
🔑【海明码检验】技巧程序化

🐇提高访存速度的措施
- 采用高速器件——高性能存储芯片
- 采用层次结构Cache-主存(详见下文)
- 调整主存结构
🥕细说调整主存结构
🍃单体多字系统
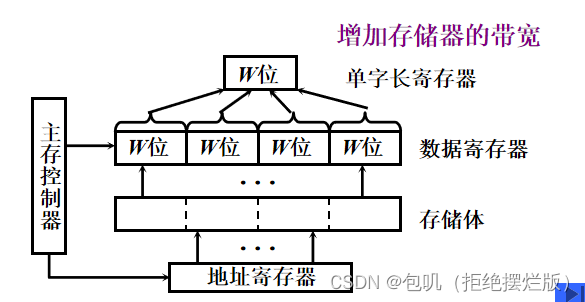
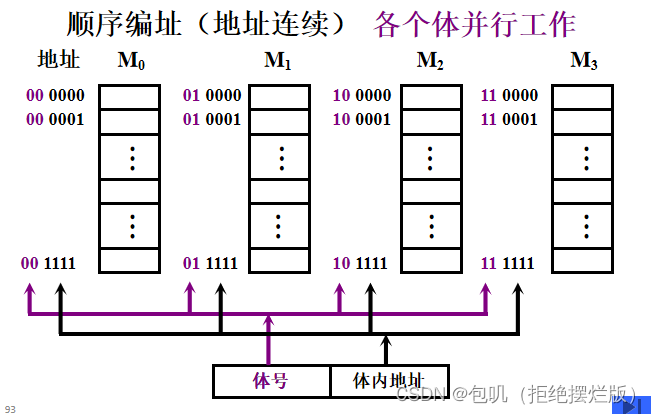
🍃多体并行系统
- 高位交叉(顺序存储)
- 低位交叉(交叉存储)
- 在不改变存取周期的前提下,增加存储器的带宽
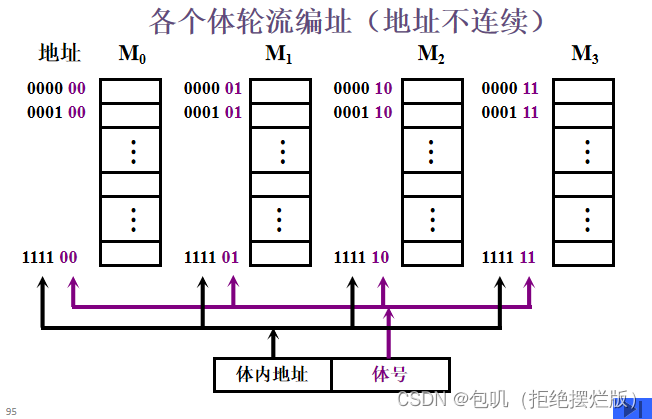
- 在不改变存取周期的前提下,增加存储器的带宽
🔑求【顺序存储】和【交叉存储】的带宽
👀上边提到的系统了解就好,主要知道求【顺序存储】和【交叉存储】的带宽的方法

- b代表bit(位),B代表Byte,注意大小写区分
- 1Byte=8bits
- Mbps=Mb/s=M/s 三个的意思一致。
- 1MB/s=8Mbps=8Mb/s
📚高速缓冲存储器
🐇概述
🥕问题的提出(解答题🔔)
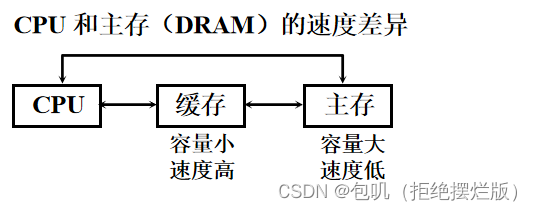
- Cache的作用
- 计算机中设置Cache主要是为了加速CPU访存速度,避免CPU“空等”现象。
- ps:由于主存是按地址访问,Cache是按内容及地址访问,所以不能把Cache的容量扩大到最后取代主存
- 程序访问的局限性
- 在一小段时间内,最近被访问过的程序和数据很可能再次被访问;
- 在空间上,这些被访问的程序和数据往往集中在一小片存储区;
- 在访问顺序上,指令顺序执行比转移执行的可能性大
- 存储系统中Cache-主存层次就是采用了程序访问的局部性原理
🥕Cache的工作原理
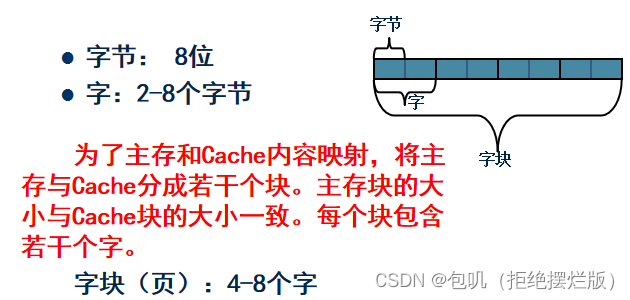
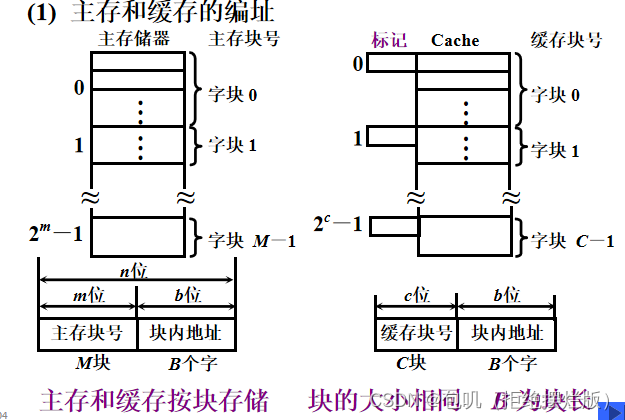
- 命中与未命中
- 缓存共有 C 块,主存共有 M 块,M >> C
- 命中:主存块调入缓存,主存块与缓存块建立了对应关系。用标记记录与某缓存块建立了对应关系的主存块号
- 未命中:主存块未调入缓存,主存块与缓存块未建立了对应关系。
🔑【Cache命中率】及【Cache-主存系统的效率】

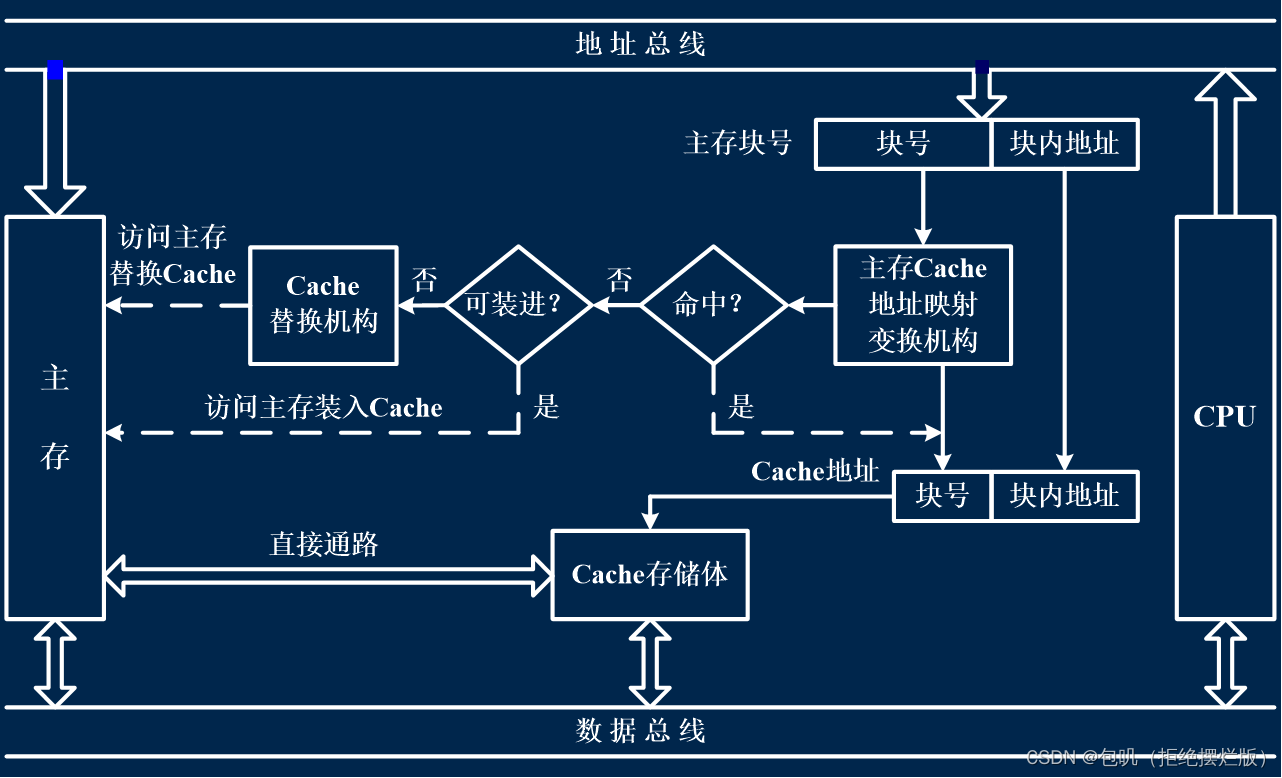
🥕Cache的基本结构(了解)
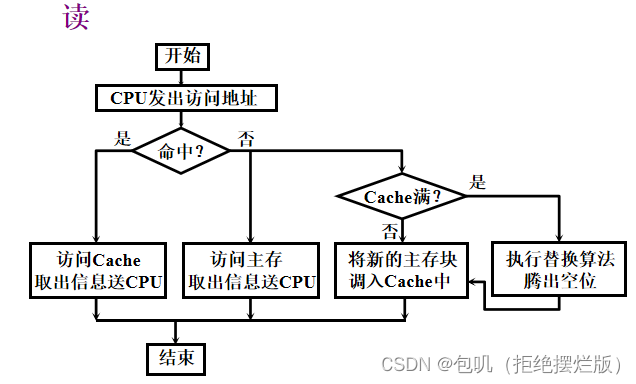
🥕Cache的读写操作(了解)

🥕Cache的改进(了解)
- 增加 Cache 的级数
- 统一缓存和分立缓存
- 统一缓存就是指令数据同一个
- 分立缓存就是指令放指令Cache里,数据放数据Cache里
🐇Cache-主存的地址映射
🥕直接映射
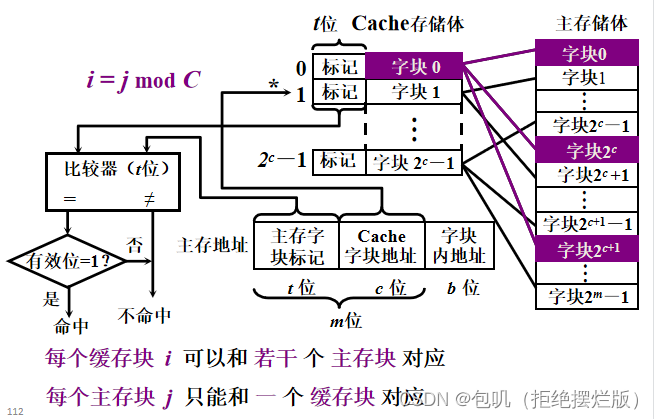
- 助记:一家公司员工(主存块)每天都是不假思索直接去自己所属的公司(Cache字块)
- 优缺点
- 直接映射是最简单的地址映射方式,它的硬件简单,成本低,地址变换速度快,而且不涉及替换算法问题。
- 但是这种方式不够灵活,Cache的存储空间得不到充分利用,每个主存块只有一个固定位置可存放,容易产生冲突,使Cache效率下降,因此只适合大容量Cache采用。
- 例如,如果一个程序需要重复引用主存中第0块与第16块,最好将主存第0块与第16块同时复制到Cache中,但由于它们都只能复制到Cache的第0块中去,即使Cache中别的存储空间空着也不能占用,因此这两个块会不断地交替装入Cache中,导致命中率降低。
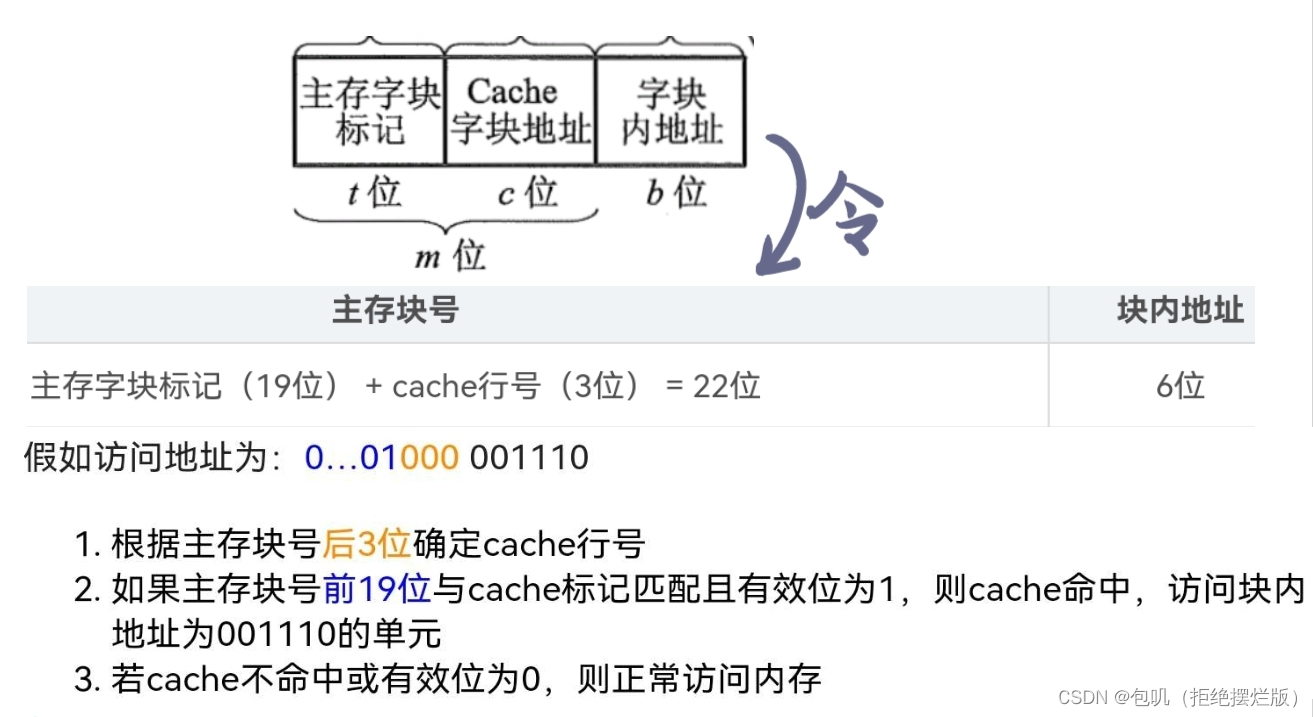
- 查找策略
🥕全相联映射
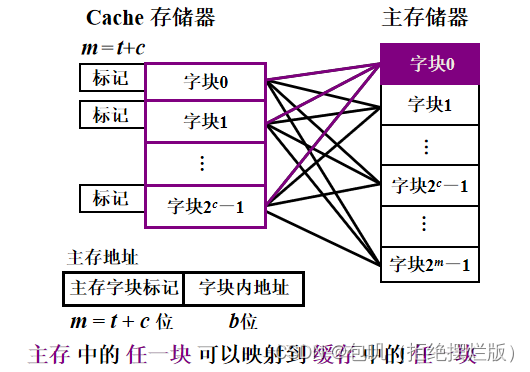
- 助记:有空位全都可以坐
- 特点:方式灵活,结构复杂。查找最慢,当Cache块装满的时候,可能需要遍历所有的Cache行
- 查找策略:

🥕组相联映射
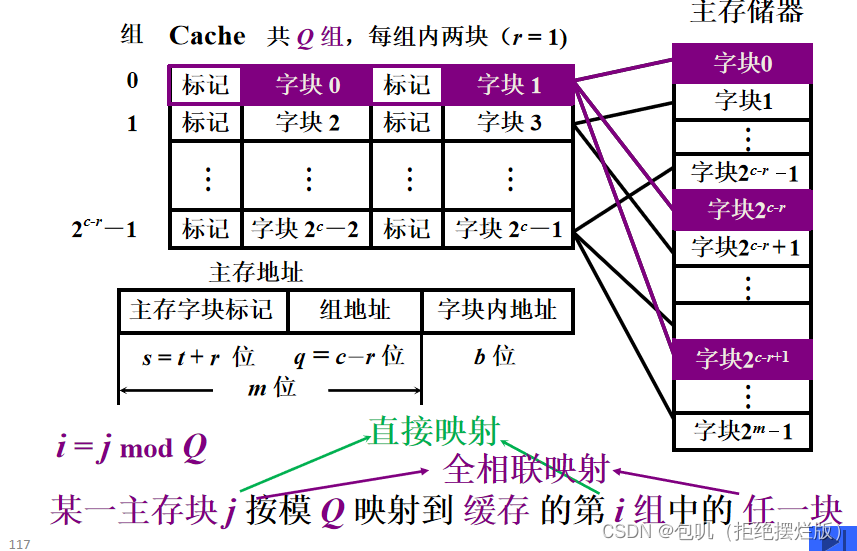
- 优点:如上图,这种方式是上述两种方式的结合,这样既提高了查找效率,又减少了因为冲突导致的换入换出次数
- 查找策略:

| 映射类型 | 映射特点 |
|---|---|
| 直接映射 | 某一主存块只能固定映射到某一缓存块(不灵活) |
| 全相联映射 | 某一主存块能映射到任一缓存块(成本高) |
| 组相联映射 | 某一主存块只能映射到某一缓存组中的任一块 |
🥕Cache替换算法(了解)
- 当Cache内容/行已满,无法接收来自主存块的时候,替换机构将某个块移出Cache。
- 先进先出 ( FIFO )算法
- 近期最少使用( LRU)算法
🥕Cache容量计算⭐️⭐️
🍃方法

🍃例题

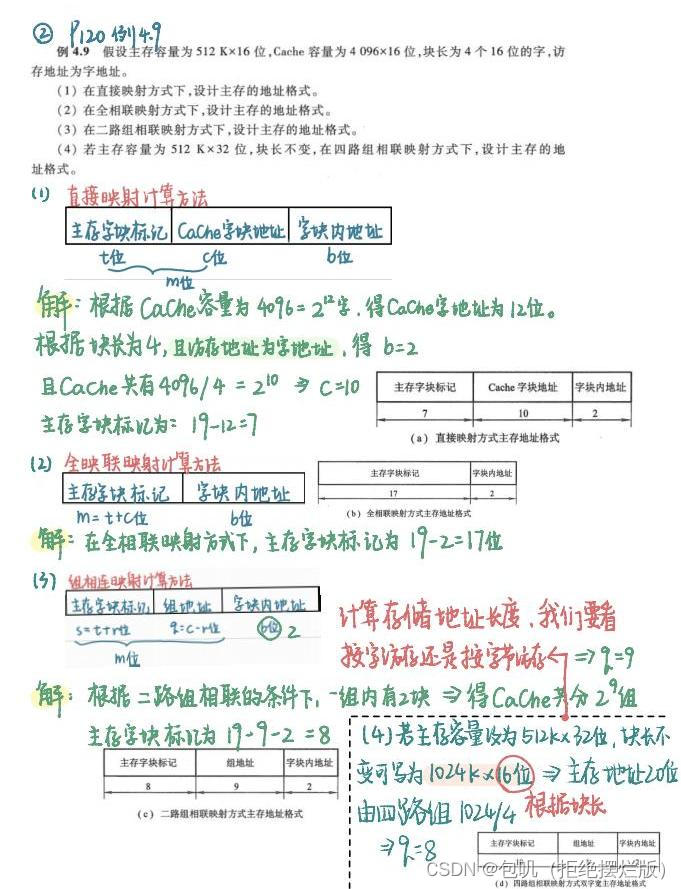
补水印遮挡:10 8 2

📚小结
🔑本章掌握要点


重点关注⭐️
👀参考博客
按字寻址和按字节寻址
DRAM的三种刷新方式的刷新周期问题
字扩展、位扩展、字位扩展