Redis优化——如何优雅的设计key,优化BigKey,Pipeline批处理Key
- 一、Key的设计
- 1. 命名规范
- 2. 长度限制在44字节以内
- 二、BigKey优化
- 1. 查找bigkey
- 2. 删除BigKey
- 3. 优化BigKey
- 三、Pipeline批处理Key
- 1. 单节点的Pipeline
- 2. 集群下的Pipeline
一、Key的设计
1. 命名规范
业务名+数据名+id
例如存储用户登录信息:login:user:id
2. 长度限制在44字节以内
如果使用的时Redis6.0版本以上,Key的编码规则有三个,int, enbstr, raw 44字节内的Key会用int或身体乳mb编码,内存占用小
二、BigKey优化
1. 查找bigkey
- 可以使用scan 0 扫描所有的Key,然后使用strlen查出大Key,这里不要使用keys *命令,会阻塞主线程
- 可以是使用Redis的第三方工具进行检测
2. 删除BigKey
- 使用unlink key 命令删除,不要使用Del key 这也会阻塞
3. 优化BigKey
- 对于大的JSON对象可以使用Hash数据结构存储,因为Hash的底层用到了ZipList,节约内存
- 对于大的Hash呢,比如一个Hash表有100万条数据,key从0-100万,此时我们可以打散Hash,就是让每100个key存储到一个hash表,让key/100,value%100,类似于分片了
三、Pipeline批处理Key
原理:建立一次网络连接,执行多条Redis命令
1. 单节点的Pipeline
@Testvoid testPipleLine(){Jedis jedis = new Jedis("host", 6379);jedis.auth("xxx");Pipeline pipeline = jedis.pipelined();for (int i = 0; i < 1000; i++) {pipeline.set("nb:key" + i, "value" + i);if (i % 100 == 0){ // 每次放入100行命令pipeline.sync();}}}
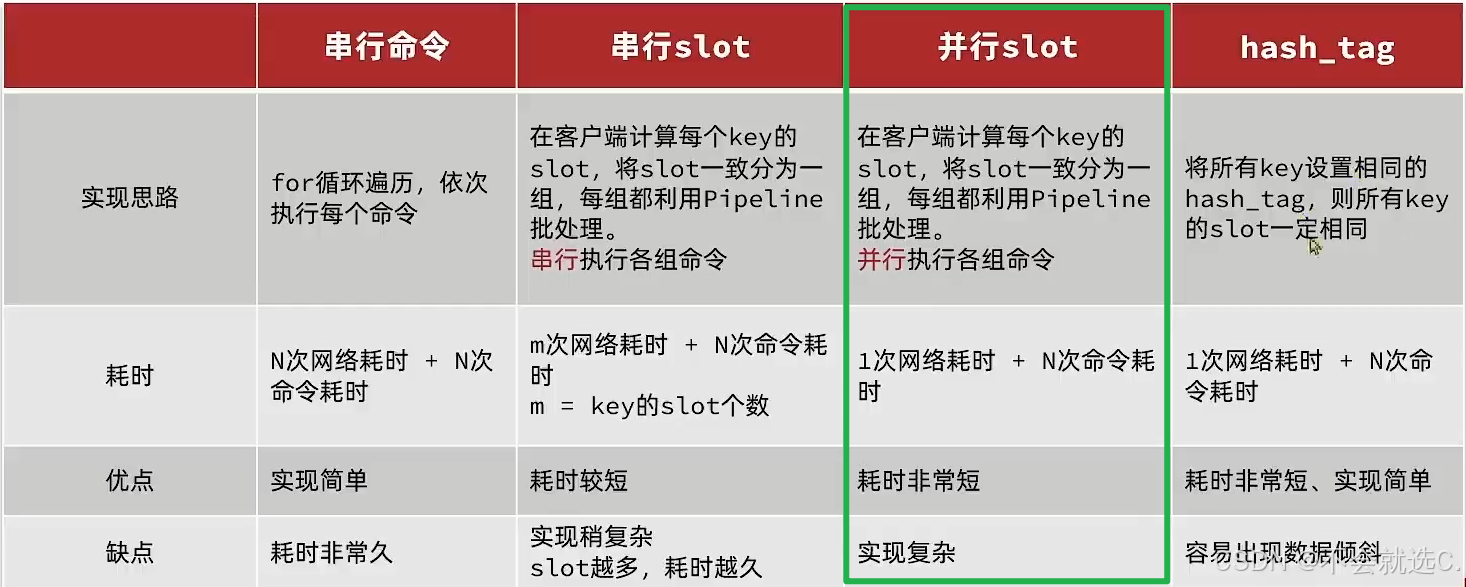
2. 集群下的Pipeline
- 集群部署Redis,插入Key,每一个Key又有一个 slot插槽,这个插槽分布在所有Redis节点中,所以如果批量插入的key的插槽不在同一个节点,那么还是会有多次网络请求,最坏又变成了每次连接执行一条命令
- 解决方案采用并行slot方式
//使用springredistemplate封装好的工具类@Testvoid testslotPipeline(){Map<String, String> map = new HashMap<>();map.put("name", "111");map.put("age", "222");map.put("gemder", "333");redisTemplate.opsForValue().multiSet(map);}