设置主键id自增,name为唯一索引
一、避免重复插入
insert ignore into(有唯一索引)
关键字/句: insert ignore into,如果插入的数据会导致 UNIQUE索引 或 PRIMARY KEY 发生冲突/重复,则忽略此次操作/不插入数据,例:
INSERT IGNORE INTO `student`(`name`,`age`) VALUES(`Jack`,18);-- row(s) affected
这里已经存在 name='Jack”的数据,所以会忽略新插入的数据,受影响行数为 0,表数据不变
需要注意 主键会自增
当使用了insert ignore into 新增数据,即使没有插入,某些版本的mysql会自增主键。
比如原来有数据1(id为1),你又插入了数据1,但是重复了没插入,之后再插入数据2,此时的数据2的主键为3而非2.
mysql5.7.26不会自增,8.0会自增
如何避免自增?
在MySQL5.7中做INSERT IGNORE时发现, 即使INSERT未成功执行, 表的自增主键却自动加1了, 在某些情况下需要避免这种行为. 需要修改的变量是 innodb_autoinc_lock_mode, 将其设为0后, 在INSERT未成功执行时不会自增主键.
innodb_autoinc_lock_mode在MySQL各版本的默认值
根据MySQL官方手册的说明:
There are three possible settings for the innodb_autoinc_lock_mode configuration parameter. The settings are 0, 1, or 2, for “traditional”, “consecutive”, or “interleaved” lock mode, respectively. As of MySQL 8.0, interleaved lock mode (innodb_autoinc_lock_mode=2) is the default setting. Prior to MySQL 8.0, consecutive lock mode is the default (innodb_autoinc_lock_mode=1).
在MySQL8中, 默认值为 2 (interleaved, 交错), 在MySQL8以前, 准确地说在8之前, 5.1之后, 默认值为 1 (consecutive, 连续), 在更早的版本是 0
innodb_autoinc_lock_mode的说明
这个值主要用于平衡性能与安全(主从的数据一致性), insert主要有以下类型
simple insert 如insert into t(name) values(‘test’)
bulk insert 如load data | insert into … select … from …
mixed insert 如insert into t(id,name) values(1,‘a’),(null,‘b’),(5,‘c’);
innodb_autoinc_lock_mode = 0:
与更高版本的MySQL向后兼容
在这一模式下,所有的insert语句都要在语句开始的时候得到一个表级的auto_inc锁,在语句结束的时候才释放这把锁,一个事务可能包涵有一个或多个语句
它能保证值分配的可预见性,与连续性,可重复性,这个也就保证了insert语句在复制到slave的时候还能生成和master那边一样的值(它保证了基于语句复制的安全)
由于在这种模式下auto_inc锁一直要保持到语句的结束,所以这个就影响到了并发的插入
innodb_autoinc_lock_mode = 1:
这一模式对simple insert做了优化,由于simple insert一次性插入值的个数可以立即确定, 所以mysql可以一次生成几个连续的值用于这个insert语句, 总的来说这个对复制也是安全的(保证了基于语句复制的安全)
这一模式也是MySQL8.0之前的默认模式, 这个模式的好处是auto_inc锁不要一直保持到语句的结束, 只要语句得到了相应的值后就可以提前释放锁
innodb_autoinc_lock_mode = 2:
由于这个模式下已经没有了auto_inc锁, 所以这个模式下的性能是最好的, 但是它也有一个问题, 就是对于同一个语句来说它所得到的auto_incremant值可能不是连续的
现在mysql已经推荐把二进制的格式设置成row, 所以在binlog_format不是statement的情况下这个模式可以达到最好的性能
insert if not exists(无唯一索引)
数据字段没有设置主键或唯一索引,当插入数据时,首先判断是否存在这条数据,不存在正常插入,存在则忽略。现在我把主键和唯一索引都去掉了。完整sql为
insert into tacs_staff.user(user_name,address) select '张三','天津' from dual where not exists (select user_name from tacs_staff.user where user_name='张三');
二、不存在则插入,存在则更新
on duplicate key update
如果插入的数据会导致UNIQUE 索引或PRIMARY KEY发生冲突/重复,则执行UPDATE语句,例:
INSERT INTO student(name, age) VALUES(‘Jack’, 19)
ON DUPLICATE KEY
UPDATE age=19; – If will happen conflict, the update statement is executed
– 2 row(s) affected
这里受影响的行数是2,因为数据库中存在name='Jack’的数据,如果不存在此条数据,则受影响的行数为1
可能遇到死锁
bug在5.7.26以及8.0.15版本上已经修复了,当插入数据时,不会在形成间隙锁
但是此方法也有坑,如果表中不止一个唯一索引的话,在特定版本的mysql中容易产生dead lock(死锁)
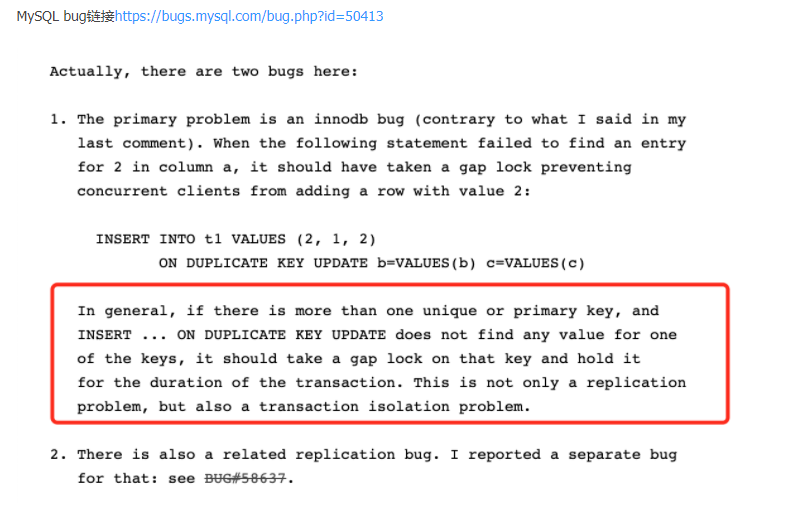
当mysql执行INSERT ON DUPLICATE KEY的 INSERT时,存储引擎会检查插入的行是否会产生重复键错误。如果是的话,它会将现有的
行返回给mysql,mysql会更新它并将其发送回存储引擎。当表具有多个唯一或主键时,此语句对存储引擎检查密钥的顺序非常敏感。根据这个顺序,
存储引擎可以确定不同的行数据给到mysql,因此mysql可以更新不同的行。存储引擎检查key的顺序不是确定性的。例如,InnoDB按照索引添加到
表的顺序检查键。
insert … on duplicate key 在执行时,innodb引擎会先判断插入的行是否产生重复key错误,如果存在,在对该现有的行加上S(共享锁)锁,如果返回该行数据给mysql,然后mysql执行完duplicate后的update操作,然后对该记录加上X(排他锁),最后进行update写入。
如果有两个事务并发的执行同样的语句,那么就会产生death lock
mysql官方描述很简单
An INSERT … ON DUPLICATE KEY UPDATE statement against a table having more than one unique or primary key is also marked as unsafe. (Bug #11765650, Bug #58637)
insert on duplicate key update 如果命中主键或者唯一键索引,加行锁,未命中加gap锁,即会阻塞插入数据
过程分析
insert … on duplicate key 在执行时,innodb引擎会先判断插入的行是否产生重复key错误,如果存在,在对该现有的行加上S(共享锁)锁,如果返回该行数据给mysql,然后mysql执行完duplicate后的update操作,然后对该记录加上X(排他锁),最后进行update写入。
如果有两个事务并发的执行同样的语句,那么就会产生death lock,如:
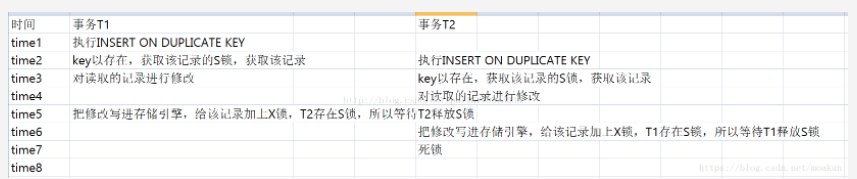
低版本的解决方法
- 尽量不对存在多个唯一键的table使用该语句
- 在有可能有并发事务执行的insert 的内容一样情况下不使用该语句。将批量insert on duplicate key update,拆分成多个语句。保证一次事务中不要插入过多值,将多个数据,变成多个sql,执行插入。可以有效的减少死锁命中的发生。
- 重试:死锁不可怕,当出现死锁发生时,多执行重试操作可以有效保证插入成功,更新不丢失。
- 线程池多线程并发执行改为单线程排队处理。
replace into(先删除再插入)
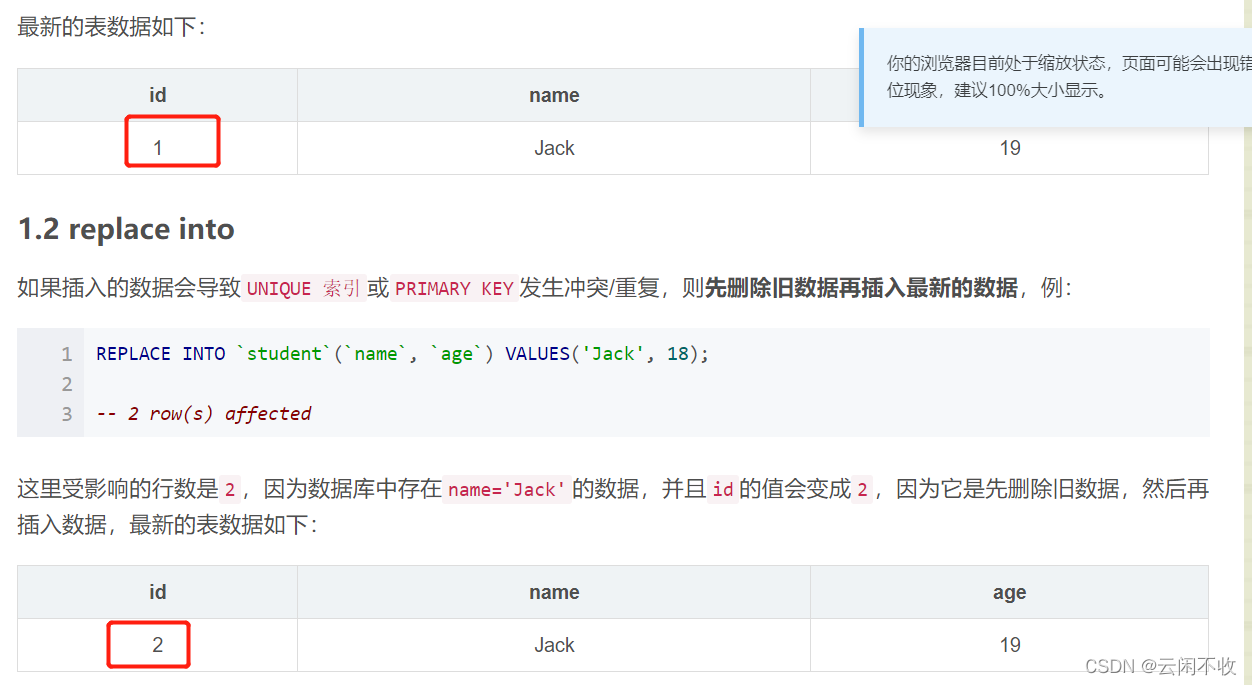
replace into 会根据唯一索引或主键进行判断,如果存在则覆盖写入字段,如果不存在则新增。
此方法有坑,如果主键是自增的,且通过唯一索引来进行操作时,主键会变更,该方法底层是先进性delete,在insert
如果有子表依赖的话不建议使用。