缓存之王 Caffeine 中,涉及到100w级、1000W级、甚至亿级元素的过期问题,如何进行高性能的定时调度,是一个难题。
注: 本文从 对 海量调度任务场景中, 高性能的时间轮算法, 做了一个 系统化、由浅入深的 穿透式介绍, 帮助大家彻底掌握 这个高性能的算法。
另外
本文以 PDF 持续更新,最新尼恩 架构笔记、面试题 的PDF文件,请从下面的链接获取:语雀 或者 码云

海量定时任务管理的问题
下面的问题,来自互联网:
一个大型内容审核平时,在运营设定审核了内容的通过的时间,到了这个时间之后,相关内容自动审核通过,
本是个小的需求,但是考虑到如果需要定时审核的东西很多,这样:
海量的定时任务调度,带来的一系列性能问题。
海量定时任务管理的场景非常多,在实际项目中,存在大量需要定时或是延时触发的任务,
比如电商中,延时需要检查订单是否支付成功,是否配送成功,定时给用户推送提醒等等
方案一 单定时器方案
描述:
把所有需要定时审核的资源放到redis中,例如sorted set中,需要审核通过的时间作为score值。
后台启动一个定时器,定时轮询sortedSet,当score值小于当前时间,则运行任务审核通过。
问题
这个方案在小批量数据的情况下没有问题,
但是在大批量任务的情况下就会出现问题了,因为每次都要轮询全量的数据,逐个判断是否需要执行,
一旦轮询任务执行比较长,就会出现任务无法按照定时的时间执行的问题。
方案二 一个任务一个定时器的方案
描述
每个需要定时完成的任务都启动一个定时任务,然后等待完成之后销毁
问题
这个方案带来的问题很明显,定时任务比较多的情况下,会启动很多的线程,这样服务器会承受不了之后崩溃。
基本上不会采取这个方案。
方案三 redis的过期通知功能
描述
和方案一类似,针对每一个需要定时审核的任务,设定过期时间,
过期时间也就是审核通过的时间,订阅redis的过期事件,当这个事件发生时,执行相应的审核通过任务。
问题
这个方案来说是借用了redis这种中间件来实现我们的功能,这中实际上属于redis的发布订阅功能中的一部分,
针对redis发布订阅功能是不推荐我们在生产环境中做业务操作的,
通常redis内部(例如redis集群节点上下线,选举等等来使用),我们业务系统使用它的这个事件会产生如下两个问题
1、redis发布订阅的不稳定问题
2、redid发布订阅的可靠性问题
具体可以参考 https://my.oschina.net/u/2457218/blog/3065021 (redis的发布订阅缺陷)
方案四 分层时间轮方案
这个东西就是专为大批量定时任务管理而生。
具体论文详见参考文献
http://www.cs.columbia.edu/~nahum/w6998/papers/sosp87-timing-wheels.pdf
缓存之王 Caffeine 中的时间轮
缓存之王 Caffeine 中,涉及到100w级、1000W级、甚至亿级元素的过期问题,
缓存之王 Caffeine 中,涉及到100w级、1000W级、甚至亿级元素的过期问题,如何进行高性能的定时调度,是一个难题。
Caffeine 使用时间轮解决这个问题,
时间轮的大致结构:

Caffeine 对时间轮的实现在TimerWheel,它是一种多层时间轮(hierarchical timing wheels )。
Caffeine 的时间轮,有五级。

看看元素加入到时间轮的schedule方法:
/*** Schedules a timer event for the node.** @param node the entry in the cache*/
public void schedule(@NonNull Node<K, V> node) {Node<K, V> sentinel = findBucket(node.getVariableTime());link(sentinel, node);
}/*** Determines the bucket that the timer event should be added to.** @param time the time when the event fires* @return the sentinel at the head of the bucket*/
Node<K, V> findBucket(long time) {long duration = time - nanos;int length = wheel.length - 1;for (int i = 0; i < length; i++) {if (duration < SPANS[i + 1]) {long ticks = (time >>> SHIFT[i]);int index = (int) (ticks & (wheel[i].length - 1));return wheel[i][index];}}return wheel[length][0];
}/** Adds the entry at the tail of the bucket's list. */
void link(Node<K, V> sentinel, Node<K, V> node) {node.setPreviousInVariableOrder(sentinel.getPreviousInVariableOrder());node.setNextInVariableOrder(sentinel);sentinel.getPreviousInVariableOrder().setNextInVariableOrder(node);sentinel.setPreviousInVariableOrder(node);
}如果看不懂这些源码,没有关系,咱们由浅入深,慢慢道来。
时间轮的基本概念
时间轮这个技术其实出来很久了,在kafka、zookeeper、Netty、Dubbo等高性能组件中都有时间轮使用的方式。
如图,时间轮,从图片上来看,就和手表的表圈是一样,所以称为时间轮.

时间轮其实就是一种环形的数据结构,其设计参考了时钟转动的思维,
可以想象成时钟,分成很多格子,一个格子代表一段时间
时间轮是由多个时间格组成,下图中有8个时间格,每个时间格代表当前时间轮的基本时间跨度(tickDuration),其中时间轮的时间格的个数是固定的。

图中,有8个时间格(槽),假设每个时间格的单位为100ms,那么整个时间轮走完一圈需要800ms。
每100ms指针会沿着顺时针方向移动一个时间单位,
这个单位可以代表时间精度
这个单位可以设置,
比如以秒为单位,也可以以一小时为单位。
通过指针移动,来获得每个时间格中的任务列表,然后遍历这一个时间格中的双向链表来执行任务,以此循环。
时间轮是以时间作为刻度, 组成的一个环形队列,这个环形队列采用数组来实现,
数组的每个元素称为槽 Bucket,

每个槽位可以放一个定时任务列表,叫HashedWheelBucket,
每个槽位可以是一个双向链表,其中可以设置一个 sentinel 哨兵节点, 作为添加任务和删除任务的起始节点。
槽位链表的每一项表示一个定时任务项(HashedWhellTimeout),其中封装了真正的定时任务TimerTask。
简单来说:
时间轮是一种高效利用线程资源进行批量化调度的一种调度模型。
把大批量的调度任务全部绑定到同一个调度器上,使用这一个调度器来进行所有任务的管理、触发、以及运行。

时间轮的模型能够高效管理各种任务:
- 延时任务、
- 周期任务、
- 通知任务。
时间轮算法在很多框架中都有用到,比如 Dubbo、Netty、Kafka 等。
时间轮算法也是一个比较经典的设计。
时间轮和hashmap的类比
更通用的情况, 同一时刻可能需要执行多个任务,比如:
- 每天上午九点除了生成报表之外,
- 执行发送邮件的任务,
- 执行创建文件的任务,
- 执行数据分析的任务
- 等等,
为了存储这些任务,如果有多个任务需要执行呢?
一个槽位可以指向一个数组或者链表,用来存放该刻度需要执行的任务,
所以,本质上,
时间轮的数据结构, 其实类似hashmap,
时间轮每一个时间刻度,可以理解为一个槽位,同一时刻存在多个任务 ,放在双向链表中。
如下图所示:

和hashmap不同的是,时间轮的key,是时间刻度值,并且,时间轮不做hash运算
时间轮在同一时刻存在多个任务时,只要把该刻度对应的链表全部遍历一遍,执行其中的任务即可。
当然, 时钟调度的线程,和 执行任务的线程,一般是需要解耦的。
所以,一般来说,具体的任务,会扔到线程池中异步执行。
时间刻度不够用怎么办?
如果任务不只限定在一天之内呢?
比如我有个任务,需要每周一上午九点执行,我还有另一个任务,需要每周三的上午九点执行。
大概的解决办法是:
- 增大时间轮的刻度
- 列表中的任务中添加round属性
- 分层时间轮
增大时间轮的刻度
一个刻度一小时, 一天24个小时,一周168个小时,为了解决时间刻度不够用的问题,
我可以把时间轮的刻度(槽)从12个增加到168个,
这样的话,一周的所有时间,都可以用一个时间轮来管理。
比如,现在是星期二上午10点,
那么,下周一上午九点,就是时间轮的第9个刻度,
那么,下周三上午九点就是时间轮的第57个刻度,
示意图如下:

单级时间轮的问题
仔细思考一下,会发现单级时间轮方式存在几个缺陷:
-
时间刻度太多会, 导致时间轮走到的多数刻度没有任务执行,
比如一个月就2个任务,我得移动720次,其中718次是无用功。
-
时间刻度太多会导致存储空间变大,利用率变低
比如一个月就2个任务,我得需要大小是720的数组,如果我的执行时间的粒度精确到秒,那就更恐怖了
所以,在实际应用中,一般单时间轮无法满足需求。
例如我们需要秒级的精度,最大延迟可能是10天,那我们时间轮就要至少864000个格子,这就产生了如下几个问题:
- 占用存储过大
- 利用率太低,比如我们只有1秒一个任务,而7天若干任务,那大部分时间,整个轮子都是在空转。
如何解决单级时间轮的问题呢?
方案1:任务中添加round属性
方案2:多级时间轮
任务中添加round属性
这次,不增加时间轮的刻度了,时间轮的刻度还是24个,而是按照任务的时间间隔,给任务增加一个 round属性。
一个round的单位,单表间隔为一轮。
假设:现在有三个任务需要执行:
-
任务一每周二上午九点。
-
任务二每周四上午九点。
-
任务三每个月12号上午九点。
比如现在是9月11号星期二上午10点,时间轮转一圈是24小时,到任务一下次执行(下周二上午九点),
需要时间轮转过6圈后,到第7圈的第9个刻度开始执行。
任务二下次执行第3圈的第9个刻度,任务三是第2圈的第9个刻度。
示意图如下:

时间轮每移动到一个刻度时,遍历任务列表,对每个task 进行分开处理:
- 把round值-1,
- 如果 round=0,则任务执行,从列表中移除。
这样做能解决时间轮刻度范围过大造成的空间浪费,但是却带来了另一个问题:
- 时间轮每次都需要遍历任务列表,耗时增加,当时间轮刻度粒度很小(秒级甚至毫秒级),
- 任务列表又特别长时,这种遍历的办法是不可接受的。
当然,对于大多数场景,这种方法还是适用的。
有没有既节省空间,又节省时间的办法呢?
答案是有的,正如《Hashed and Hierarchical Timing Wheels》标题中提到的,有一种分层时间轮,可以解决做到既节省空间,又节省时间:
分层时间轮
分层时间轮是这样一种思想:
-
针对时间复杂度的问题:
不做遍历计算round,凡是任务列表中的任务,都应该被执行的,直接全部取出来执行。
-
针对空间复杂度的问题:
分层,每个时间粒度对应一个时间轮,多个时间轮之间进行级联协作。
第一点很好理解,第二点有必要举个例子来说明。
比如有三个任务:
- 任务一 :间隔30s。
- 任务二 :间隔1分钟30s。
- 任务三:间隔1小时1分钟30s。
三个任务涉及到三个时间单位:秒、分钟、小时。
按照分层时间轮来设计,我们可以设置三个时间轮:秒轮、分轮、小时轮。
时间刻度先得来到12号这一天,然后才需要关注其更细一级的时间单位:上午9点。
基于这个思想,我们可以设置三个时间轮:月轮、周轮、天轮。
- 秒轮的时间刻度 tick duration 是秒。span 跨度为 一分钟,60秒。
- 分轮的时间刻度 tick duration 是分。span 跨度为 一小时,60分。
- 小时轮的时间刻度是 tick duration 是小时。span 跨度为 一天,24小时。
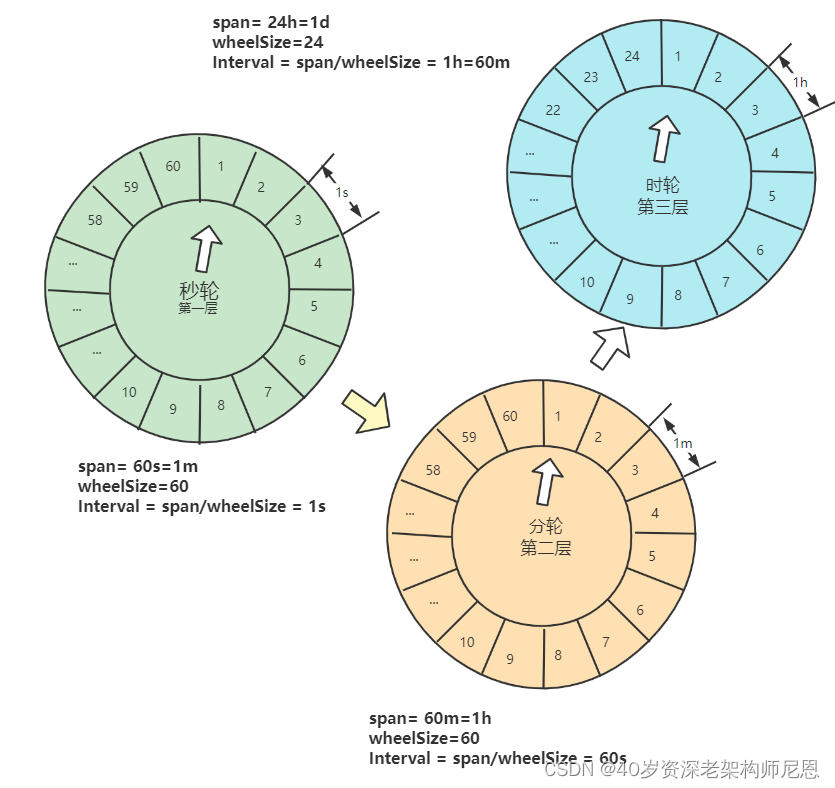
初始添加任务时:
- 任务一添加到秒轮上,
- 任务二添加到分轮上
- 任务三添加到时轮上。
三个时间轮以各自的时间刻度不停流转。
当时轮移动到刻度2(第1小时)时,取出这个刻度下的任务三,丢到分轮上,分轮接管该任务。
当分轮移动到刻度2(第1分钟)时,取出这个刻度下的任务二,丢到秒轮上,秒轮接管该任务。
当秒轮移动到刻度30(第30秒)时,取出这个刻度下的任务一,移除该任务,然后执行该任务。
整体的示意图如下所示:

分层时间轮的时间复杂度分析
分层时间轮算法是为了更高效的实现定时器而设计的一种数据格式,
定时器的核心需求
- 新增(初始化一个定时任务)
- 移除(过期任务)
- 任务到期检测
定时器的实现方式,大概有那些呢?
方式一:基于小顶堆实现的PriorityQueue
内部的结构,按照到期时间,维护了**一个优先队列 PriorityQueue **,
优先队列的插入和删除的时间复杂度是O(logn),
当数据量大的时候,频繁的入堆出堆,总体性能有待考虑。
Timer、DelayQueue 和 ScheduledThreadPool
方式二:带round属性的单级时间轮
由于时间的跨度都比较长,单级时间轮一般会带着round属性。 没有round属性的单级时间轮,生产场景基本不用,这里不做时间复杂度的考虑。
带round属性的单级时间轮的本质就是一个数组,它的时间跨度就是一个时间循环
同时,每一个槽位,会维护一个 任务链表,每一个任务带着 round 数量
时间轮会以时间刻度 tick duration 间隔为单位,开始每一个最小时间间隔步进一个单位,然后检查当前时间轮节点上是否有任务
- 如果有任务,就直接执行
- 没有任务,就等待下一个时间间隔步进1,重复进行检测
时间轮每移动到一个刻度时,遍历任务列表,对每个task 进行分开处理:
- 把round值 减去1,
- 如果 round=0,则任务执行,从列表中移除。
时间复杂度:纯粹的时间轮-新增O(1),移除O(1),检测O(N)
总体而言,时间复杂度O(N)
缺点:时间复杂度高
方式三:分层时间轮实现定时器

本质就是多个时间轮共同一起作用,分时间层级!
以上述图片为样例,当时轮上有任务时,那么就将该任务转移到对应的分钟时间轮上;
当分轮上有任务时,那么就将该任务转移到对应的秒钟的秒轮上;
当秒轮上有任务时,那么就将该任务移除;
时间复杂度:新增O(1),移除O(1),检测O(1)
Caffeine 中的TimerWheel的使用
除了支持expireAfterAccess和expireAfterWrite之外(Guava Cache 也支持这两个特性),Caffeine 还支持expireAfter。
因为expireAfterAccess和expireAfterWrite都只能是固定的过期时间,一般情况而已,这个已经够用了。
但还是有些特殊场景,譬如记录的过期时间,是需要根据某些条件而不一样的,这就需要用户自定义过期时间。
先看看expireAfter的用法
package com.github.benmanes.caffeine.demo;import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.CacheLoader;
import com.github.benmanes.caffeine.cache.Caffeine;
import com.github.benmanes.caffeine.cache.Expiry;
import org.checkerframework.checker.index.qual.NonNegative;
import org.checkerframework.checker.nullness.qual.NonNull;
import org.checkerframework.checker.nullness.qual.Nullable;import java.util.concurrent.TimeUnit;public class ExpireAfterDemo {static System.Logger logger = System.getLogger(ExpireAfterDemo.class.getName());public static void hello(String[] args) {System.out.println("args = " + args);}public static void main(String... args) throws Exception {Cache<String, String> cache = Caffeine.newBuilder()//最大个数限制//最大容量1024个,超过会自动清理空间.maximumSize(1024)//初始化容量.initialCapacity(1)//访问后过期(包括读和写)//5秒没有读写自动删除
// .expireAfterAccess(5, TimeUnit.SECONDS)//写后过期
// .expireAfterWrite(2, TimeUnit.HOURS)//写后自动异步刷新
// .refreshAfterWrite(1, TimeUnit.HOURS)//记录下缓存的一些统计数据,例如命中率等.recordStats().removalListener(((key, value, cause) -> {//清理通知 key,value ==> 键值对 cause ==> 清理原因System.out.println("removed key="+ key);})).expireAfter(new Expiry<String, String>() {//返回创建后的过期时间@Overridepublic long expireAfterCreate(@NonNull String key, @NonNull String value, long currentTime) {System.out.println("1. expireAfterCreate key="+ key);return 0;}//返回更新后的过期时间@Overridepublic long expireAfterUpdate(@NonNull String key, @NonNull String value, long currentTime, @NonNegative long currentDuration) {System.out.println("2. expireAfterUpdate key="+ key);return 0;}//返回读取后的过期时间@Overridepublic long expireAfterRead(@NonNull String key, @NonNull String value, long currentTime, @NonNegative long currentDuration) {System.out.println("3. expireAfterRead key="+ key);return 0;}}).recordStats()//使用CacheLoader创建一个LoadingCache.build(new CacheLoader<String, String>() {//同步加载数据@Nullable@Overridepublic String load(@NonNull String key) throws Exception {System.out.println("loading key="+ key);return "value_" + key;}//异步加载数据@Nullable@Overridepublic String reload(@NonNull String key, @NonNull String oldValue) throws Exception {System.out.println("reloading key="+ key);return "value_" + key;}});//添加值cache.put("name", "疯狂创客圈");cache.put("key", "一个高并发 研究社群");//获取值@Nullable String value = cache.getIfPresent("name");System.out.println("value = " + value);//removecache.invalidate("name");value = cache.getIfPresent("name");System.out.println("value = " + value);}}通过自定义过期时间,使得不同的 key 可以动态的得到不同的过期时间。
需要把expireAfterAccess和expireAfterWrite注释了,因为这两个特性不能跟expireAfter一起使用。只能做二选一,从源码中,也可以看到这点:

当使用了expireAfter特性后,Caffeine 会启用一种叫“时间轮”的算法来实现这个功能。
为什么Caffeine 要用时间轮
好,重点来了,为什么要用时间轮?
对expireAfterAccess和expireAfterWrite的实现是用一个AccessOrderDeque双端队列,它是 FIFO 的
因为它们的过期时间是固定的,从时间维度而言,而最早进入队列的缓存记录Node节点,在头部。
最新的节点、或者最晚进入的缓存记录Node节点,在尾部。

由于每次插入都在尾部,可以理解为这个队列,暗含了一个规律:
元素是按照过期时间有序的
所以, 结论是:
在队列头的数据肯定是最早过期的,在队列尾部的数据肯定是最晚过期的,
要处理过期数据时,只需要首先看看头部是否过期,然后再挨个检查就可以了。
但是,这个队列有个要求:
各个节点的过期时间,要求是一样的
如果过期时间不一样的话,怎么做过期时间检查呢?
这就需要遍历,还有一种方式是,对这个双端队列accessOrderQueue进行排序&插入,这个时间复杂度就不说O(1)了。
于是,Caffeine 用了一种更加高效、优雅的算法-时间轮。
Caffeine 的五级时间轮的源码分析
重要属性与方法
时间轮的具体实现为一个二维数组,其数组的具体位置存放的则为一个待执行节点的链表。
时间轮的二维数组的第一个维度则是具体的时间间隔,分别是秒,分钟,小时,天,4天,但但并没有严格按照时间单位来区分单位,而是根据以上单位最接近的2的整数次幂作为时间间隔,因此在其第一个维度的时间间隔分别是1.07s,1.14m,1.22h,1.63d,6.5d。
static final int[] BUCKETS = { 64, 64, 32, 4, 1 };static final long[] SPANS = {ceilingPowerOfTwo(TimeUnit.SECONDS.toNanos(1)), // 1.07sceilingPowerOfTwo(TimeUnit.MINUTES.toNanos(1)), // 1.14mceilingPowerOfTwo(TimeUnit.HOURS.toNanos(1)), // 1.22hceilingPowerOfTwo(TimeUnit.DAYS.toNanos(1)), // 1.63dBUCKETS[3] * ceilingPowerOfTwo(TimeUnit.DAYS.toNanos(1)), // 6.5dBUCKETS[3] * ceilingPowerOfTwo(TimeUnit.DAYS.toNanos(1)), // 6.5d};当具体的时间事件要加入到时间轮时,将会根据该事件距离当前时间的最接近的单位,首先定位到二维数组的第一个维度,具体后面会解释。
为什么要选择最接近的2的整数而不是选择具体的时间整数,是为了可以通过移位比较快速得到时间滚动在二维数组的第一个维度的变动。
在时间轮中,具体记录了以上时间间隔的偏移量,在时间轮中,将当前时间与上一次时间求差并不断右移SHIFT的位数,便可以快速定位到时间的变动。
//Long.numberOfTrailingZeros(value1) 返回最左侧之后的0位数, 10100010000 》》》 4static final long[] SHIFT = {Long.numberOfTrailingZeros(SPANS[0]),Long.numberOfTrailingZeros(SPANS[1]),Long.numberOfTrailingZeros(SPANS[2]),Long.numberOfTrailingZeros(SPANS[3]),Long.numberOfTrailingZeros(SPANS[4]),};final Node<K, V>[][] wheel;long nanos;
用简单的数字举个例子,第一个维度分别为1s,10s,100s,1000s,
那么具体的第一维存在四个槽位,分别存放10s以内的,10s到100s以内的,100s到1000s以内的,1000s以后的,当一个300s之后发生的时间事件进入后,首先得到差值300,依次比较,显然300大于100小于1000,那么这个300s以后发生的事件在时间轮上的二维数组的第一个维度的第三个位置上。
其中1s则是用来标志过期操作之间的最小的时间刻度,并没有参与到时间事件的定位中,类比时间轮中的1.07s。
请参见视频《第25章:穿透Caffeine 的架构和源码分析》
构造函数
初始化五级时间轮,每个时间轮,都是一个数组。
@SuppressWarnings({"rawtypes", "unchecked"})TimerWheel() {wheel = new Node[BUCKETS.length][];for (int i = 0; i < wheel.length; i++) {wheel[i] = new Node[BUCKETS[i]];for (int j = 0; j < wheel[i].length; j++) {wheel[i][j] = new Sentinel<>();}}System.out.println("BUCKETS = " + Arrays.toString(BUCKETS));System.out.println("SPANS = " +Arrays.toString( SPANS));System.out.println("SHIFT = " + Arrays.toString(SHIFT));System.out.println("Long.toBinaryString(SPANS[0]) = " + Long.toBinaryString(SPANS[0]));System.out.println("wheel = " + wheel);}请参见视频《第25章:穿透Caffeine 的架构和源码分析》
时间步进
/*** Advances the timer and evicts entries that have expired.** @param cache the instance that the entries belong to* @param currentTimeNanos the current time, in nanoseconds*/public void advance(BoundedLocalCache<K, V> cache, long currentTimeNanos) {long previousTimeNanos = nanos;nanos = currentTimeNanos;// If wrapping then temporarily shift the clock for a positive comparison. We assume that the// advancements never exceed a total running time of Long.MAX_VALUE nanoseconds (292 years)// so that an overflow only occurs due to using an arbitrary origin time (System.nanoTime()).if ((previousTimeNanos < 0) && (currentTimeNanos > 0)) {previousTimeNanos += Long.MAX_VALUE;currentTimeNanos += Long.MAX_VALUE;}try {for (int i = 0; i < SHIFT.length; i++) {long previousTicks = (previousTimeNanos >>> SHIFT[i]);long currentTicks = (currentTimeNanos >>> SHIFT[i]);long delta = (currentTicks - previousTicks);if (delta <= 0L) {break;}expire(cache, i, previousTicks, delta);}} catch (Throwable t) {nanos = previousTimeNanos;throw t;}}任务调度
首先找到对应的 时间轮,和时间轮里边的槽位
然后通过哨兵,插入任务
* @param node the entry in the cache*/public void schedule(Node<K, V> node) {Node<K, V> sentinel = findBucket(node.getVariableTime());link(sentinel, node);}找到对应的 时间轮,和时间轮里边的槽位
* @param time the time when the event fires* @return the sentinel at the head of the bucket*/Node<K, V> findBucket(long time) {long duration = time - nanos;int length = wheel.length - 1;for (int i = 0; i < length; i++) {if (duration < SPANS[i + 1]) {long ticks = (time >>> SHIFT[i]);int index = (int) (ticks & (wheel[i].length - 1));return wheel[i][index];}}return wheel[length][0];}
请参见视频《第25章:穿透Caffeine 的架构和源码分析》
Dubbo源码中的时间轮
后面会对照 Caffeine 的时间轮,分析Dubbo源码中的时间轮
未完待续
XXL-Job源码中的时间轮
后面会对照 Caffeine 的时间轮,分析XXL-Job源码中的时间轮
未完待续
参考文献
https://www.likecs.com/show-204434429.html
http://www.cs.columbia.edu/~nahum/w6998/papers/sosp87-timing-wheels.pdf
https://blog.csdn.net/xinzhongtianxia/article/details/86221241
https://blog.csdn.net/m0_37039331/article/details/87401758
https://blog.csdn.net/qq924862077/article/details/112550085
https://baijiahao.baidu.com/s?id=1714290103234167995
https://www.cnblogs.com/smileIce/p/11156412.html
https://blog.csdn.net/bz120413/article/details/122107790
https://blog.csdn.net/Javaesandyou/article/details/123918852
https://blog.csdn.net/Javaesandyou/article/details/123918852
https://blog.csdn.net/FreeeLinux/article/details/54897192
https://blog.csdn.net/weixin_41605937/article/details/121972371
推荐阅读:
-
《尼恩Java面试宝典》
-
《Springcloud gateway 底层原理、核心实战 (史上最全)》
-
《Flux、Mono、Reactor 实战(史上最全)》
-
《sentinel (史上最全)》
-
《Nacos (史上最全)》
-
《分库分表 Sharding-JDBC 底层原理、核心实战(史上最全)》
-
《TCP协议详解 (史上最全)》
-
《clickhouse 超底层原理 + 高可用实操 (史上最全)》
-
《nacos高可用(图解+秒懂+史上最全)》
-
《队列之王: Disruptor 原理、架构、源码 一文穿透》
-
《环形队列、 条带环形队列 Striped-RingBuffer (史上最全)》
-
《一文搞定:SpringBoot、SLF4j、Log4j、Logback、Netty之间混乱关系(史上最全)
-
《单例模式(史上最全)
-
《红黑树( 图解 + 秒懂 + 史上最全)》
-
《分布式事务 (秒懂)》
-
《缓存之王:Caffeine 源码、架构、原理(史上最全,10W字 超级长文)》
-
《缓存之王:Caffeine 的使用(史上最全)》
-
《Java Agent 探针、字节码增强 ByteBuddy(史上最全)》
-
《Docker原理(图解+秒懂+史上最全)》
-
《Redis分布式锁(图解 - 秒懂 - 史上最全)》
-
《Zookeeper 分布式锁 - 图解 - 秒懂》
-
《Zookeeper Curator 事件监听 - 10分钟看懂》
-
《Netty 粘包 拆包 | 史上最全解读》
-
《Netty 100万级高并发服务器配置》
-
《Springcloud 高并发 配置 (一文全懂)》