大数据技术梳理
- 大数据初识
- 大数据基础
- Linux基础
- 高并发技术
- Hadoop体系
- Hadoop技术(一)分布式文件系统HDFS
- Hadoop技术(二)资源管理器YARN和分布式计算框架MapReduce
- Hadoop技术(三)数据仓库工具Hive
- Hadoop技术(四)分布式、面向列的开源数据库HBase
- 高级技术
- CDH集群管理
- Scala——多范式, 可伸缩, 类似Java的编程语言
- Spark——底层操作RDD,基于内存处理数据的计算引擎
- Flink——运行在数据流上的有状态计算框架和处理引擎
- Storm——分布式实时流式计算框架
- 补充技术
- Redis技术
- Elastic Search
- Flume——高可用的、高可靠的、分布式日志收集系统
- Kafka——分布式的消息队列
- 后记
随着企业项目的规模越做越大, 现在很多项目都已经涉及到大数据了.
大数据相关技术的出现解决了传统项目中由于数据量变而引起的质变进而产生的相关问题, 突破传统技术的性能瓶颈, 促进业务更好的发展
2020即将逝去. 在此梳理下这几年自己所掌握的大数据方面的知识, 为今后进行的技术转型做好铺垫.
大数据初识
首先先附上大数据开发主要的职位图
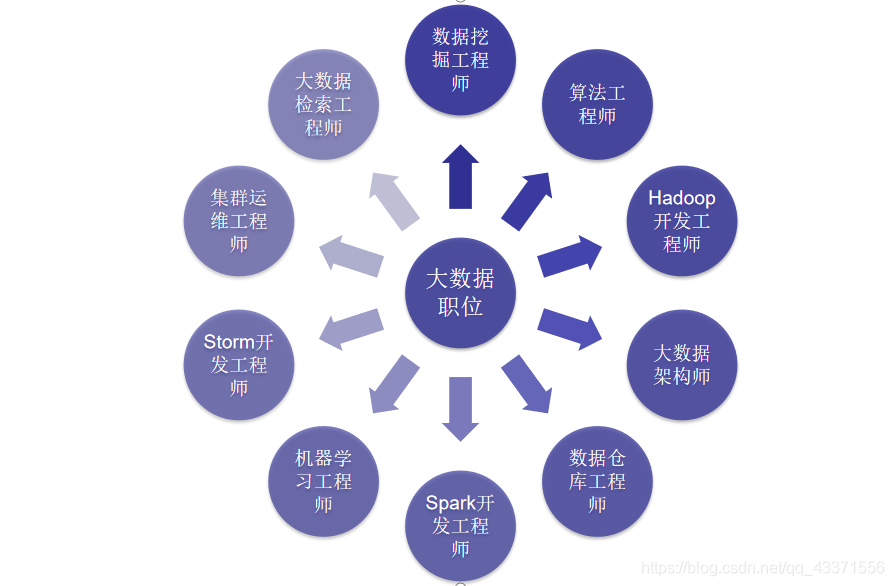
从上图我们可以看到, 从事大数据方向可以有很多具体方向的职位. 相较于Java开发, 选择面更加广泛
而最主要的职位集中在数据挖掘工程师, 算法工程师, hadoop工程师, 数据仓库工程师上. 我们可以通过在各大招聘网站上搜索这些职位去了解这些职位需要哪些技术栈, 以此进行针对性学习和了解
附上各大网招聘站入口(按推荐度排序, 不过都需要注册才能进行职位搜索)
Boos直聘(传送门)
智联招聘(传送门)
拉钩网(传送门)
大数据基础
点击各蓝色标题可以进入对应的博文哦~~~
Linux基础
大数据很多集群操作都是在Linux服务器上面运行的, 因此要想学习大数据的相关知识, 首先需要对Linux有一个系统的了解.
这些了解包括:
-
对自定义版本虚拟机的安装,
-
对多节点(多主机)上的虚拟机进行集群化配置以及备份(以防安装失败后的回滚).
-
Linux常用命令的使用
-
文本编辑命令
vi, vim的使用以及使用该命令后文本产生三种模式的了解
编辑模式:按键具有编辑文本功能:默认打开进入编辑模式
输入模式:按键本身意义
末行模式:接受用户命令输入 -
正则表达式的学习
因为Linux主要使用shell进行操作的特点, 不便我们直接对文本进行查询和修改, 而通过对正则表达式的学习和使用能够方便我们对日志或配置文件进行查询和修改操作 -
行编辑命令(cut, sort, wc)
cut: 文本切分,类似Java中的Spilt函数
sort: 对文本中每行指定位置的字符进行排序
wc: 对文本的行数, 单词数, 以及字节数(包括空格符)进行统计 -
用户与权限操作
因为Linux 中所有内容都是以文件的形式保存和管理的,即一切皆文件. 而文件管理模式带来的弊端就是文件的删除容易导致系统出现问题, 因此需要对登录的用户和权限进行严格限制, 避免出现新闻上常见的"删库跑路" 事件,
这样既对公司的财产安全进行了维护, 同时也避免了一些人因冲动而做出傻事, 这个是非常有必要学习的. -
shell 脚本编写
在大数据的相关工作中, 脚本必不可缺, 它是实现相关软件, 项目管理自动化的重要途径之一. 通过使用脚本, 我们可以对进群中的相关软件和项目进行批量部署, 启动和关闭等操作. 能够为我们节约大量时间, 方便我们将自己的重心转移到业务研发上去.
高并发技术
我国是人口大国同时也是数据大国, 由数据的量(数以亿计)变产生了质变 , 我们步入了大数据时代. 而大数据也带来的高并发的问题. 解决高并发问题是大数据时代的永恒主题.
通过相应技术, 解决高并发问题 ,为企业节省更多资金 ,有益企业良性发展. 这便是大数据技术发展的不竭动力之源.
对高并发相关知识的了解包括
-
网络工程基础知识
OSI七层参考模型, Tcp的三次握手四次分手, 查看虚拟机内核的IP路由表信息命令等. -
LVS技术
LVS是Linux Virtual Server的简称,也就是Linux虚拟服务器,现在LVS已经是Linux标准内核的一部分,可以直接使用LVS提供的各种功能。使用LVS技术要达到的目标是:通过LVS提供的负载均衡技术和Linux操作系统实现一个高性能,高可用的服务器群集,它具有良好的可靠性、可扩展性和可操作性。从而以低廉的成本实现最优的服务性能。
通过对LVS基本概念, 相关调度算法进行介绍. 以及LVS-DR网络拓扑结构的搭建来学习LVS如何使用. -
Keepalived
Keepalived: 基于vrrp协议实现, 是集群管理中保证集群高可用的服务软件. 这里模拟了LVS+Keepalive的实验, 事实上Keepalive还可以和Nginx等软件配合使用实现负载均衡 -
Nginx和 Tengine
Nginx (“engine x”) 是一个高性能的 HTTP和反向代理服务器,也是一个 IMAP/POP3/SMTP 代理服务器; Tengine 是nginx的加强版,封装版 ,性能更加强劲!
这里通过对二者的优缺点进行比较, 并主要使用了Tengine制作Nginx脚本, 配置好Tengine之后又对其进行技术延伸, 实现虚拟Server, 反向代理, 负载均衡等操作, 并对nginx如何识别我们的域名的原理进行了简单的介绍 -
session一致性问题的解决
这里首先模拟了Session不一致产生的情况: 由于Nginx代理多个节点后服务器出现Session不一致的情况, 然后使用其中一种解决方案: 安装memcached进行解决.
另外, 还探讨了服务器时间一致性的解决方案: 安装ntpdate服务
Hadoop体系
Hadoop技术(一)分布式文件系统HDFS
作为Hadoop体系的基石, 分布式存储系统HDFS (Hadoop Distributed File System )提供了高可靠性、高扩展性和高吞吐率的数据存储服务的分布式存储系统
对分布式文件系统的了解包括
-
Hdfs的相关介绍( 优缺点, 相关原理, 架构, 存储模型等的介绍 )
-
Hdfs的读写流程 ( 面试重点 )
-
HDFS中的角色权限与安全模式
与Linux文件权限类似r: read; w:write; x:execute;
所有者(owner)就是Linux的当前用户, 如果Linux系统用户zhangsan使用hadoop命令创建一个文件,那么这个文件在HDFS中owner就是zhangsan。
HDFS的权限目的: 阻止好人错错事,而不是阻止坏人做坏事。HDFS相信,你告诉我你是谁,我就认为你是谁 -
HDFS高可用集群搭建及API
根据在Linux学习搭建好的集群, 安装HDFS: 其中, 操作系统环境需要安装ssh,jdk, 配置免秘钥, 设置时间同步, 配置环境变量, 安装Hadoop相关软件, 并测试是否安装成功. 待成功之后, 搭建伪分布式集群(1台主机)和完全分布式集群(多台主机) -
Hadoop 2.0
因为Hadoop 1.0中HDFS和MapReduce在高可用、扩展性等方面存在问题, 在此学习并安装了Hadoop 2.0, 因为二者区别挺大的, 所以注意区分(面试会问) -
Eclipse 下开发大数据
主要是对Hadoop软件所需运行环境进行配置, 使我们能够在Eclipse上面能够本地运行Hadoop程序
Hadoop技术(二)资源管理器YARN和分布式计算框架MapReduce
Hadoop MapReduce / MR 是一个软件计算框架,可以轻松地编写应用程序,以可靠,容错的方式并行处理大型硬件集群(数千个节点)上的大量数据(多达TB数据集)
Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
对资源管理器YARN和分布式计算框架MapReduce的了解包括
-
对其MapReduce相关知识的了解
基本介绍, MR运行原理. 块 ,切片 , map ,reduce ,组 ,分区 ,输出文件之间的关系等. -
Hadoop MapReduce V2
MapReduce On YARN:MRv2 , 将MapReduce作业直接运行在YARN上,而不是由JobTracker和TaskTracker构建的MRv1系统中. 通过搭建MR V2运行环境, 运行简单案例, 分析相关源码加深对MapReduce的了解 -
Hadoop-MapReduce案例
介绍了MR可以使用的三种案例.天气案例, 好友推荐案例, PageRank ( PageRank是Google提出的算法,用于衡量特定网页相对于搜索引擎索引中的其他网页而言的重要程度。是Google创始人拉里·佩奇和谢尔盖·布林于1997年创造的 PageRank实现了将链接价值概念作为排名因素。 ) -
MapReduce案例-ItemCF
讲述了一个重要的算法, 推荐系统——协同过滤(Collaborative Filtering)算法
通过UserCF来了解这个算法 : 基于用户的协同过滤,通过不同用户对物品的评分来评测用户之间的相似性,基于用户之间的相似性做出推荐。简单来讲就是:给用户推荐和他兴趣相似的其他用户喜欢的物品。
Hadoop技术(三)数据仓库工具Hive
Hadoop生态系统就是为处理大数据集而产生的一个合乎成本效益的解决方案。Hadoop的MapReduce可以将计算任务分割成多个处理单元然后分散到家用的或服务器级别的硬件上,降低成本并提供水平伸缩性。
而Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
对Hive的了解包括以下几点:
-
Hive是什么
对Hive相关概念, 架构原理, 执行流程等进行介绍. -
Hive的搭建
单用户(伪分布式)模式搭建, 多用户(分布式)模式搭建. -
Hive语法
常用命令, 如新增(insert)和修改(update), 内部表和外部表的区别以及创建方式, Hive的分区, Hive的序列化与反序列化, Hive Beeline(beenline 提供了Shell的JDBC的访问方式, 不能用于 DML 操作,只能执行一些查询操作), Hive JDBC( 通过JDBC的方式来链接Hive ) -
Hive的拓展学习
学习Hive的配置参数, 动态分区, Hive分桶, Hive视图, Hive索引. -
Hive运行方式
通过命令行, 脚本, JDBC, Hive Web GUI等方式来使用Hive. -
Hive 权限管理
Hive三种授权模型: 基于存储的授权, 基于SQL标准的Hive授权, Hive默认授权
推荐使用第二种模式进行授权, 并通过搭建该模式授权环境实现相关功能
角色管理: 将一个或多个角色授予其他角色或用户: 如果指定了“ WITH ADMIN OPTION”,则用户将获得将角色授予其他用户/角色的特权。
设置管理对象权限: 对Hive中对象的权限进行授权与撤销 -
Hive优化
从不同角度出发, 来为Hive进行优化, 而优化的最终目的就是提升其计算性能. 从事数仓工程师需要着重了解此方面的内容
Hadoop技术(四)分布式、面向列的开源数据库HBase
HBase 是一个分布式的、面向列的开源数据库。是基于Google 开源的bigtable的实现,面向列的非关系型数据库
对HBase得到了解主要包括:
-
什么是HBase
对HBase的相关概念, 架构原理, 数据模型等进行介绍. -
Hbase的安装
伪分布式安装, 完全分布式安装 -
HBase-API
搭建相关Demo, 使我们可以用Java语言来对HBase进行创建表, 插入数据, 获取指定单元格信息等. 通过Java模拟通话数据并使用HBase的相关API进行处理,
封装了Hbase相关操作, 方便我们通过工具类直接进行Hbase的curd操作, 利用Hbase实现WordCount等等. -
Hbase性能优化
从不同角度出发, 来为HBase进行优化, 而优化的最终目的就是提升其计算性能.
高级技术
CDH集群管理
CDH是大数据分布式集群管理工具。CDH由Cloudera公司开发并提供大数据集群的配置标准化,可以帮助企业安装、配置、运行 hadoop 以达到大规模企业数据的处理和分析。
目前市场中Cloudera公司开发的Cloudera Manager平台(简称CM)与CDH市场占有率很大,掌握 CM+CDH 集群管理是企业开发中必不可少的技能。
对CDH的了解主要包括:
-
CDH是什么
对产生背景, 相关概念, 技术架构等进行了介绍. -
安装
通过 Cloudera Manager 进行部署. -
其他组件安装
通过CM安装Hue( 与Hadoop集群进行交互来分析处理数据 ), Hive, Implal ( 提供对 HDFS 、HBase 数据的高性能、低延迟的交互式 SQL 查询功能 ) , 并将Impala 与 HBase 整合; 安装OOZIE ( 于 Hadoop 平台的开源的工作流调度引擎, 用来管理 Hadoop 作业 ), 并运行Oozie脚本等等
Scala——多范式, 可伸缩, 类似Java的编程语言
Scala——多范式, 可伸缩, 类似Java的编程语言
Scala是一门多范式, 类似java的编程语言 ,设计初衷是实现可伸缩的语言、并集成面向对象编程和函数式编程的各种特性。
Scala以一种简洁、高级的语言将面向对象和函数式编程结合在一起. Scala的静态类型有助于避免复杂应用程序中的bug,它的JVM和JavaScript在运行时允许构建高性能的系统,可以轻松地访问庞大的库生态系统。
对Scala的了解包括:
-
Scala是什么
对Scala的相关概念与六大特性等进行了介绍. -
Scala 安装使用
安装其使用环境, 常用IDE(Eclipse, IDEA)整合Scala插件, 并创建Demo项目. -
Scala 基础
Scala的常用数据类型, 类和变量的声明和使用方式, 条件语句的语法. -
Scala 的方法与函数
Scala常用的五种方法与三种函数介绍与使用. -
集合
Scala中String , 数组, List ,Set, Map, 元组的介绍与使用. -
Scala 高级知识
trait 特性: Scala Trait(特征) 相当于 Java 的接口,实际上它比接口还功能强大。它还可以定义属性和方法的实现。
样例类 CaseClass: 使用了case关键字的类定义就是样例类(case classes),样例类是种特殊的类。实现了类构造参数的getter方法(构造参数默认被声明为val),当构造参数是声明为var类型的,它将帮你实现setter和getter方法
偏函数: 如果一个方法中没有match 只有case,这个函数可以定义成PartialFunction偏函数。偏函数定义时,不能使用括号传参,默认定义PartialFunction中传入一个值,匹配上了对应的case,返回一个值,只能匹配同种类型
Actor Model : Actor通信模型 -
搭建Spark运行环境
Scala语言就是为Spark开发做基础的, 搭建完成后实现一个WordCount的小案例, 初步体会spark语言的极致精简
Spark——底层操作RDD,基于内存处理数据的计算引擎
Apache Spark是一个快速的通用集群计算框架 / 引擎。它提供Java,Scala,Python和R中的高级API,以及支持常规执行图的优化引擎。
它还支持一组丰富的更高级别的工具,包括Spark SQL用于SQL和结构化数据的处理,MLlib机器学习,GraphX用于图形处理和Spark Streaming.
对Spark的了解包括:
-
Spark是什么
对Spark的相关概念以及特点, 与MR的区别, 运行模式, Spark Core相关概念等进行介绍. -
安装
搭建Standalone集群, 介绍Spark四种任务提交方式(Standalone 模式两种提交任务方式和 Yarn模式两种提交任务方式). -
宽窄依赖和资源任务调度
RDD(弹性分布式数据集)之间有一系列的依赖关系,依赖关系又分为窄依赖和宽依赖. -
Spark 源码分析与算法案例
对Spark-Submit提交参数进行介绍, 资源调度, 任务调度源码进行分析, WordCount实现, 统计网站Pv和Uv, 二次排序, 分组取TopN, 广播变量和累加器. -
Spark的深入使用
SparkShell 的使用, SparkUI界面介绍与使用, Spark MasterHA介绍与搭建. -
Spark Shuffle
Spark 两种shuffleManager管理机制, Shuffle文件寻址介绍, Spark 内存管理以及Shuffle调优. -
SparkSQL
Hive是Shark的前身,Shark是SparkSQL的前身, SparkSQL产生的根本原因是其完全脱离了Hive的限制. 这里对SparkSQL的相关概念进行了介绍, 并且通过简单的案例来演示如何去使用. -
SparkStreaming简介
SparkStreaming是流式处理框架,是Spark API的扩展,支持可扩展、高吞吐量、容错的实时数据流处理,实时数据的来源可以是 :Kafka, Flume, Twitter, ZeroMQ或者TCP sockets,并且可以使用高级功能的复杂算子来处理流数据。这里SparkStreaming与Storm的区别, 以及SparkStreaming代码格式, 算子操作, Driver HA(高可用), SparkStreaming整合Kafka等.
Flink——运行在数据流上的有状态计算框架和处理引擎
Apache Flink是一个框架和分布式处理引擎,用于对无限制和有限制的数据流进行有状态的计算。Flink被设计为可以在所有常见的集群环境中运行,以内存速度和任何规模执行计算。
对Flink的了解包括:
-
Flink是什么
对Flink的相关概念, 架构原理, 可以应用的领域, 运行方式, Flink & Storm & SparkStreaming 三者区别等进行了介绍. -
Flink编程
利用Flink实现WordCount, 分区设置和排序, 设置 source和 sink, 计数器的使用, Flink术语重新介绍. -
安装
集群搭建步骤, 利用Flink读取Socket数据, Flink窗口操作, 并与Kafka进行整合使用.
Storm——分布式实时流式计算框架
Storm是Twitter开源的分布式实时大数据处理框架
对Storm的了解包括:
-
Storm是什么
对Storm的相关概念, 拓扑流程, 与MapReduce, Spark Streaming性能对比, 计算模型等进行介绍. -
Storm编程案例
WordSum ( 数据累加 )的实现, WordCount( 数据统计 ) -
Storm Grouping
介绍了Storm的八种分组方式 -
安装
Storm的伪分布式搭建和完全分布式搭建 -
深入理解Storm
深入介绍了Storm的架构, 集群的并发机制, Storm的通信机制和容错机制, Storm Drpc(分布式远程过程调用), Strom 事务机制等. -
Flume-Kafka-Storm整合案例实现
利用所学的三者知识, 进行案例整合和知识复习.
补充技术
Redis技术
Redis是当前比较热门的NOSQL数据库之一,它是一个开源的使用ANSI C语言编写, 数据都是缓存在计算机内存中的的key-value数据库,是大数据处理中必备数据库之一。
使用强大的rendis5.0版本(国内领先),首次引入stream数据类型。Stream 类似于日志的数据结构,允许在单一 Key 上基于自动的有序时间序列存储多个字段,在消息队列,事件通知,统一日志架构等业务场景中有非常大的发挥空间。
它支持的数据类型有五种,分别是String(get/set ket-value)、List(有序 l/r/push/pop key value)、Hash(无序,hget/hset key-field-value)、Set(无序 sadd/rem key-values)、SortSet(有序zadd/zrem key-value)。 他可以与java进行整合,但需导入jedis的jar包 .在存入对象类型数据时, 需要将对象转换成 json格式才能存放到redis数据库中. 在项目中, 通常使用Redis技术进行单点登录时用户信息的存储和购物网站中商品信息及商品分类信息的缓存.
对Redis 的了解包括
-
Redis是什么
认识Redis, 并了解其特点 -
安装Redis
安装单机版, 伪分布式, 完全分布式, 哨兵集群 -
Redis数据类型
认识并使用Redis的五种数据类型的使用以及Redis的其他命令 -
Redis的配置以及持久化方案
Redis配置文件的解读, Redis的两种持久化方式( ADB方式和AOF方式 ) -
用JedisAPI操作redis
Redis支持各种客户端API, 这里使用Java来操作Redis. -
RedisDesktopManager的安装与使用
使用Redis的客户端软件来管理Redis数据库
Elastic Search
Elastic Search
ElasticSearch是一个基于Lucene的搜索引擎 / 服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。
Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到近实时搜索,稳定,可靠,快速,安装使用方便。
对Elastic Search的了解包括
-
什么是Elastic Search
对相关概念, ES功能, ES的使用场景, ES特点等进行介绍. -
ES核心概念
对lucene和ES的关系, 倒排索引等重要概念的梳理. -
ES的安装以及使用
安装ES, Kibana并学会使用简单的Kibana命令(JSON形式).
Flume——高可用的、高可靠的、分布式日志收集系统
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统, Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
对Flume的了解包括:
-
Flume是什么
Flume相关概念的介绍, 架构原理介绍等 -
安装
单节点搭建和集群搭建实现 -
Flume Source
Source是从其他生产数据的应用中接受数据的组件。Source可以监听一个或者多个网络端口,用于接受数据或者从本地文件系统中读取数据,每个Source必须至少连接一个Channel. 这里对Flume的常用的数据源进行介绍 -
Flume Channel
Channel主要是用来缓冲Agent以及接收,但尚未写出到另外一个Agent或者存储系统的数据。Channel的行为比较像队列, 这里对Flume常用的Channel进行介绍 -
Flume Sinks
Sink会连续轮训各自的Channel来读取和删除事件。Sink将事件推送到下一阶段(RPC Sink的情况下),或者到达最终目的地. 这里对Flume常用的Sink进行介绍.
Kafka——分布式的消息队列
kafka是一个高吞吐的分布式消息队列系统
对Kafka的了解包括:
-
Kafka是什么
对Kafka相关概念介绍, 特点, 和其他消息队列的对比, 消息存储和生产消费模型等进行介绍. -
安装
集群安装( 前提: 需要有zookeeper支持 ). -
使用
基本命令, 查看zookeeper中topic相关信息, 删除kafka中的数据, 通过脚本启动Kafka, kafka的leader的均衡机制的介绍, kafka 0.11版本改变介绍. -
Kafka整合flume
flume作为kafka的数据提供方(生产者), kafka的 kafka spout作为消息的消费者. 使Kafka能将数据发送到Flume上.
后记
除了上面的技术, 后续还会更新Kylin, Azkaban等
-
Apche Kylin 是 Hadoop 大数据平台上的一个开源 OLAP 引擎。它采用多维立方体 Cube 预计算技术,可以将特定场景下的大数据 SQL 查询速度提升到亚秒级别。
-
Azkaban是一个批量工作流调度器,底层是使用java语言开发,用于在一个工作流内以一定的顺序运行一组任务和流程,并且提供了非常方便的webui界面来监控任务调度的情况,方便我们来管理流调度任务。在复杂的大数据开发环境中每个任务都不是独立的,之间都会有依赖关系,Azkaban工作流调度器解决的就是此类问题。
成为一个合格的大数据开发者不仅要掌握以上技术, 而且还要时时洞悉新的技术.
人生有限, 技术之路无限. 而身心和技术, 应该同时在路上.