flume
- 第一章 是什么
- 介绍
- 架构
- 第二章 安装
- 简单案例实现(单节点实现)
- 设置多Agent流(集群配置)
- 设置多Agent流的拓展
- 企业常见架构模式
- 流复用模式
- 第三章 Flume Source
- 一 netcat源
- 二 avro源
- 三 exec源
- 利用exec源监控某个文件
- 四 JMS源
- 五 Spooling Directory 源
- 利用Spooling Directory源监控目录
- 六 Kafka源
- 第四章 Flume Channel
- 第五章 Flume Sinks
- HDFS Sink
- flume在项目中的应用
- 资料分享
第一章 是什么
介绍
-
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统, Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
-
当前Flume有两个版本: Flume 0.9X版本的统称Flume-og,Flume1.X版本的统称Flume-ng。由于Flume-ng经过重大重构,与Flume-og有很大不同,使用时请注意区分。
-
flume 官网 http://flume.apache.org/
-
flume用户手册 http://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html
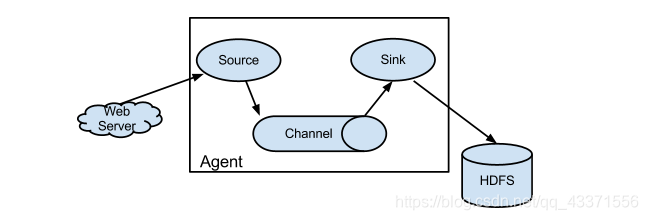
架构
第二章 安装
# 1、上传软件包# 2、解压
tar -zxf apache-flume-1.6.0-bin.tar.gz # 3、修改conf/flume-env.sh ## 将配置jdk环境变量的注释放开,并修改滑稽变量## 删除 docs目录, docs 保存了这个版本的官方文档 , 可以通过浏览器查看, 但是在虚拟机中无法查看,在分布式配置分发时会影响分发效率(图1 )rm -rf docs/注意:JAVA_OPTS 配置 如果我们传输文件过大 报内存溢出时 需要修改这个配置项# 5、配置环境变量并重载 ( . /etc/profile )
export FLUME_HOME=/home/apache-flume-1.6.0-bin
export PATH=$PATH:$FLUME_HOME/bin
----------------------------
:! ls /usr/java
小技巧: 在编辑模式下执行ls命令# 4、验证安装是否成功( 图2 )
./flume-ng version
图1
图2

简单案例实现(单节点实现)
注意: 现在版本已经更新到1.9 ,而本人使用的是1.6的版本, 配置方式早已相差甚远
因此可以通过在Windows下打开该软件包中的docs/ 目录下的index.html查看相应版本的教程
以下配置都是基于官网教程配置
-
创建一个文件, 内容如下
# example.conf: A single-node Flume configuration# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1# Describe/configure the source a1.sources.r1.type = netcat # 监控的节点 a1.sources.r1.bind = node2 a1.sources.r1.port = 44444# Describe the sink a1.sinks.k1.type = logger# Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100# Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 -
运行该文件, 前置运行 (图1,图2,图3)
#运行该案例, -conf-file 文件名, ,生成后的文件名 a1, -Dflume.root.logger日志输出街边, console在控制台输出 flume-ng agent --conf-file option --name a1 -Dflume.root.logger=INFO,console -
在非 flume所在主机(node3)安装一个telnet插件,用于远程通信
yum install -y telnet -
noed3与flume主机建立连接
telnet node2 44444 -
建立连接后 ,输入任意字符 (图4) ,可以看到flume 会收集我们发送的数据 (图5)
图1
从这里可以看出需要我们安装 hdfs, hive, hbase的支持, 只要我们安装了 ,运行时就会自动读取这些应用
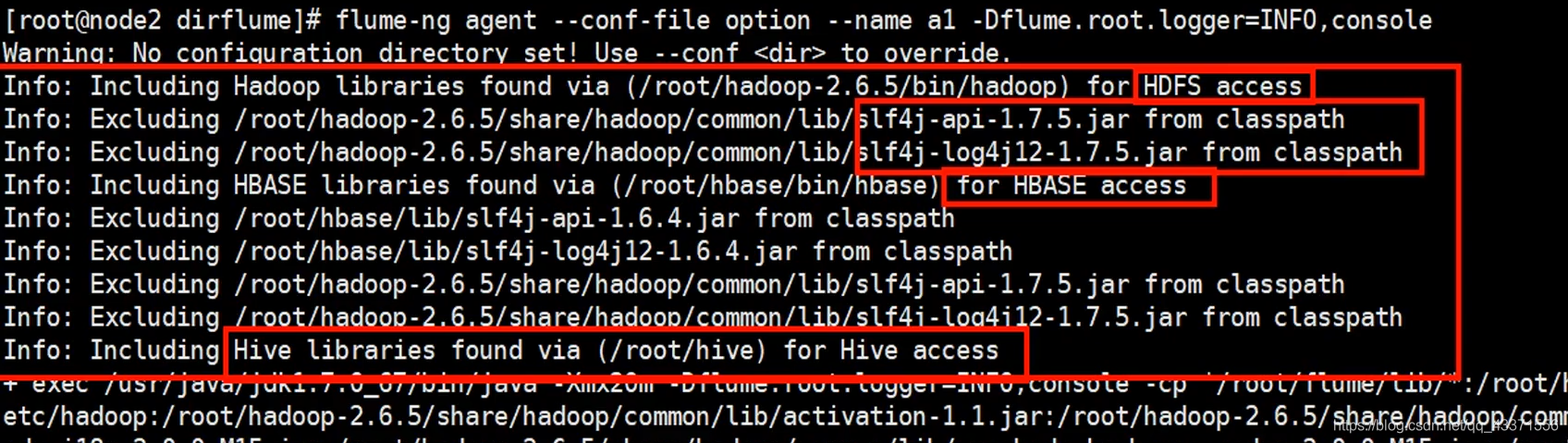
图2
我们可以看到配置文件中配置的东西在启动时生效了…
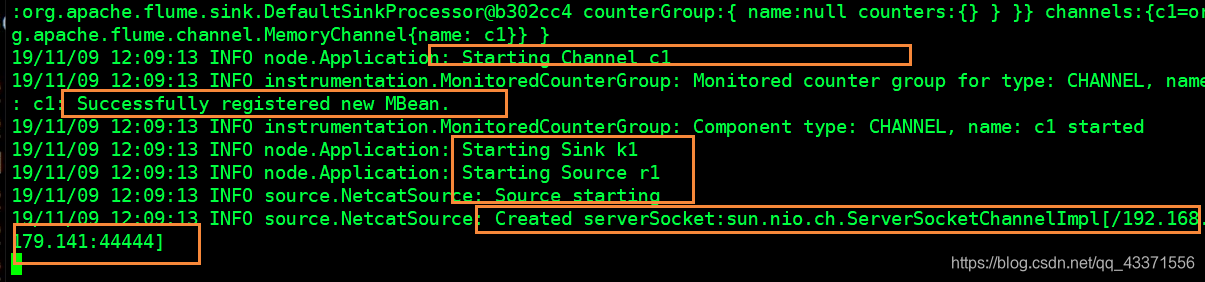
图3
我们可以另起一个命令行 ,通过查看是否有44444这个应用端口号查看是否启动成功

图4
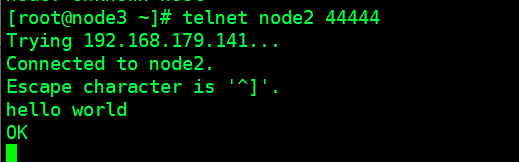
图5
可以看到数据被完整的显示, 以及每个字符的16进制表示

设置多Agent流(集群配置)
需要我们在不同主机安装 flume 并配置
为了跨多个代理或跳流数据,前一个代理的接收器和当前跳的源需要是Avro类型,接收器指向源的主机名(或IP地址)和端口。
架构
为了跨多个代理或跳流数据,前一个代理的接收器和当前跳的源需要是Avro类型,接收器指向源的主机名(或IP地址)和端口。

步骤
-
将单机版配置的flume 从node2发送到node3 ,并配置环境变量,方便以服务的形式启动
# 分发到node3 scp -r flume/ node3:`pwd`# 环境变量配置(vim /etc/profile) export FLUME_HOME=/opt/flume export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_PREFIX/bin:$HADOOP_PREFIX/sbin:$ZOOKEEPER_HOME/bin:$HIVE_HOME/bin:$HBASE_HOME/bin:$FLUME_HOME/bin# 重载配置 . /etc/profile # 测试是否安装成功 [root@node3 opt]# flume-ng version Flume 1.6.0 -
修改node2的自定义配置文件 (vi option-fbs)
# node2 # example.conf: A single-node Flume configuration# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1# Describe/configure the source a1.sources.r1.type = netcat # 修改监控的节点 a1.sources.r1.bind = node2 a1.sources.r1.port = 44444# Describe the sink # 配置分步式 ,这里需要修改 a1.sinks.k1.type = avro a1.sinks.k1.hostname = node3 a1.sinks.k1.port = 4545# Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100# Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 -
修改node3的自定义配置文件avro源( vi option-fbs)
# node3 # example.conf: A single-node Flume configuration# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1# Describe/configure the source 端口需要对应,node3相当于单节点的node2 a1.sources.r1.type = avro a1.sources.r1.bind = node3 a1.sources.r1.port = 4545# Describe the sink a1.sinks.k1.type = logger# Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100# Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 a1.sinks.k1.channel = c1 -
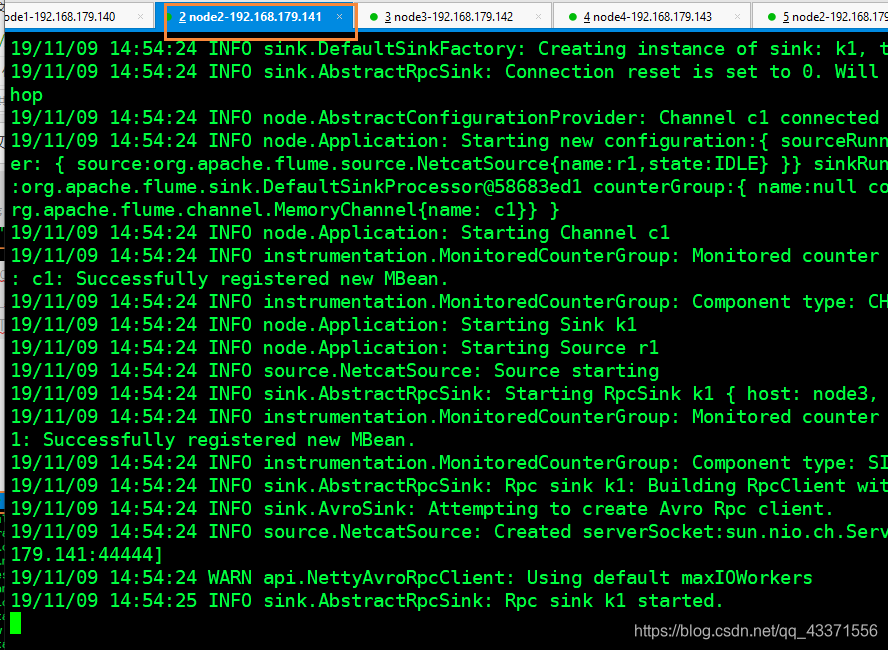
先启动node3的flume, 再启动node2的flume
node2用于发送数据 , node3 用于接收数据# i在两个节点都运行此命令 flume-ng agent --conf-file option-fbs --name a1 -Dflume.root.logger=INFO,console# 观察启动结果 # 首先启动node3 ,效果图1 # 然后启动node2 ,效果图2 # 启动node2后 , 再次查看node3的阻塞式界面, 效果如图3 则启动成功 -
测试效果
依旧使用 telnet测试,在node3发送一条数据 ,查看在哪个节点显示[root@node3 ~]# telnet node2 44444 Trying 192.168.179.141... Connected to node2. Escape character is '^]'. # 在这里输入hello world hello world OK# 观察图4, 图5 ,并结合结构图可知: node3, 中接收到了数据, 而node2没有接收到数据 我们从node3向node2发送数据 ,经过一系列的数据流转 ,node2中的数据就会被发送到node3显示 , 而且一直如此~~~
图1
avro源启动成功

图2
sink 配置成功

图3
node2 连接node3成功

图4
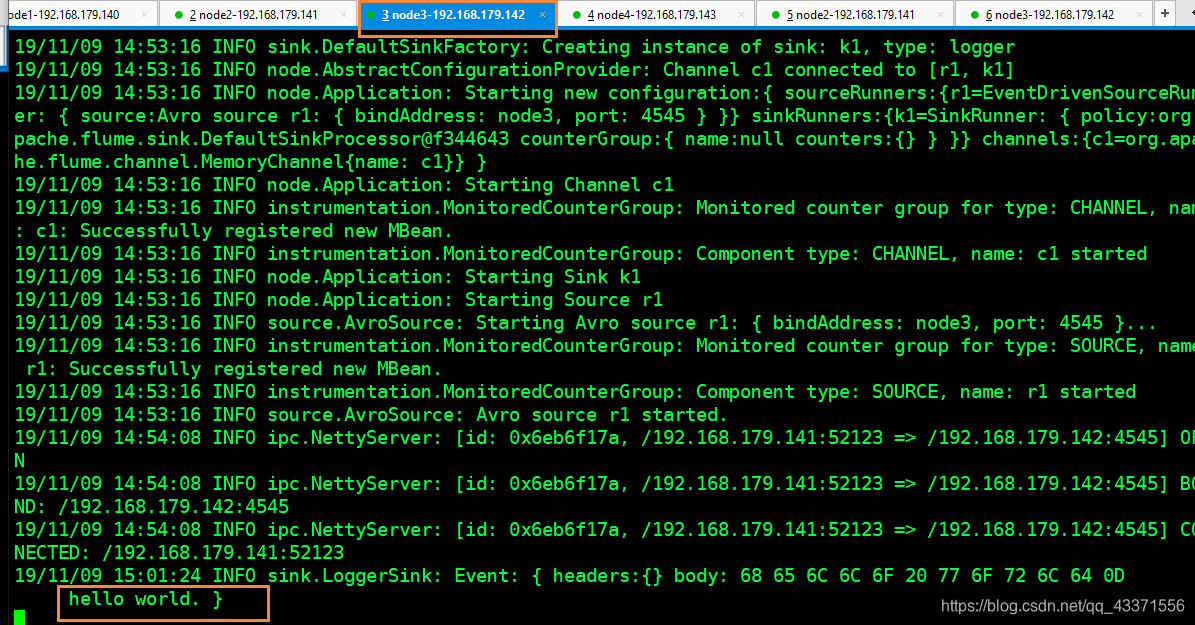
图5
设置多Agent流的拓展
企业常见架构模式
日志收集中一个非常常见的场景是大量日志生成客户端将数据发送给一些附加到存储子系统的使用者代理。例如,从数百个Web服务器收集的日志发送到十几个写入HDFS集群的代理。
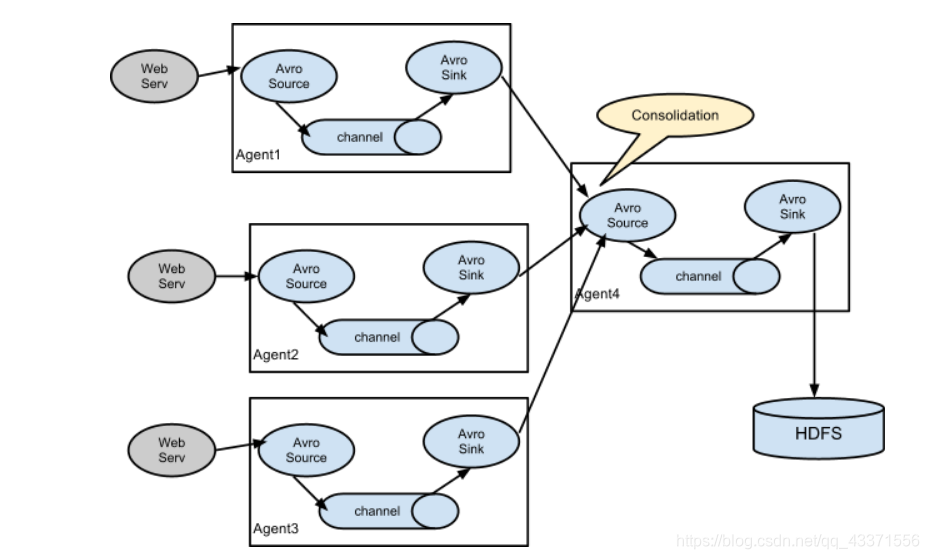
这可以在Flume中通过使用Avro接收器配置多个第一级代理来实现,所有代理都指向单个代理的Avro源(同样,在这种情况下您可以使用节约源/接收器/客户端)。第二层代理上的这个源将接收到的事件合并到单个信道中,该信道由接收器消耗到其最终目的地。
这样配置可能会导致单点故障 , 因此可以配置高可用
流复用模式
Flume支持将事件流复用到一个或多个目的地。这是通过定义流复用器来实现的,该流复用器可以复制或选择性地将事件路由到一个或多个通道。
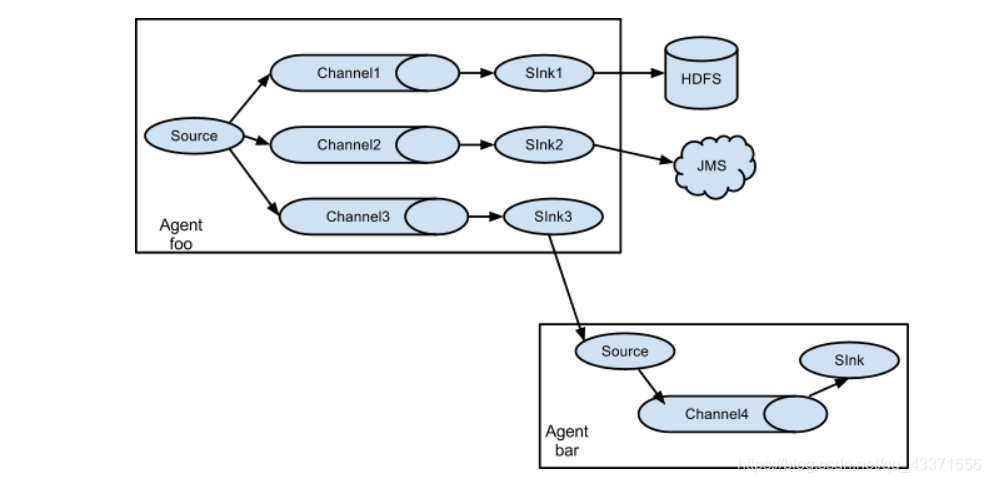
上面的示例显示了一个来自代理“foo”的源,它将流扇出三个不同的通道。这种风扇可以复制或多路复用。在复制流的情况下,每个事件都被发送到所有三个通道。对于多路复用情况,当事件的属性与预先配置的值匹配时,事件被传递到可用通道的子集。例如,如果一个名为“txnType”的事件属性被设置为“Customer”,那么它应该转到Channel 1和Channel 3,如果它是“供应商”,那么它应该转到Channel 2,否则则转到Channel 3。映射可以在代理的配置文件中设置。
第三章 Flume Source
Source是从其他生产数据的应用中接受数据的组件。Source可以监听一个或者多个网络端口,用于接受数据或者从本地文件系统中读取数据,每个Source必须至少连接一个Channel。当然一个Source也可以连接多个Channnel,这取决于系统设计的需要。
所有的Flume Source如下 ,下面将介绍一些主要的源
| Source类型 | 说明 |
|---|---|
| Avro Source | 支持Avro协议(实际上是Avro RPC),内置支持 |
| Thrift Source | 支持Thrift协议,内置支持 |
| Exec Source | 基于Unix的command在标准输出上生产数据 |
| JMS Source | 从JMS系统(消息、主题)中读取数据 |
| Spooling Directory Source | 监控指定目录内数据变更 |
| Twitter 1% firehose Source | 通过API持续下载Twitter数据,试验性质 |
| Netcat Source | 监控某个端口,将流经端口的每一个文本行数据作为Event输入 |
| Sequence Generator Source | 序列生成器数据源,生产序列数据 |
| Syslog Sources | 读取syslog数据,产生Event,支持UDP和TCP两种协议 |
| HTTP Source | 基于HTTP POST或GET方式的数据源,支持JSON、BLOB表示形式 |
| Legacy Sources | 兼容老的Flume OG中Source(0.9.x版本) |
一 netcat源
netcat的源在给定端口上侦听并将每一行文本转换为事件。表现得像数控
nc -k -l [host] [port].…换句话说,它打开指定的端口并侦听数据。期望提供的数据是换行符分隔的文本。每一行文本都被转换成一个sink事件,并通过连接的通道发送。
常用于单节点的配置
二 avro源
侦听Avro端口并从外部Avro客户端流接收事件。当在另一个(前一跳)sink代理上与内置的Avro Sink配对时,它可以创建分层的集合拓扑。
我们搭建多Agent流的环境使用的就是avro源
三 exec源
- exec源在启动时运行给定的unix命令,并期望该进程在标准输出上不断生成数据(stderr被简单丢弃,除非属性logStdErr设置为true)。如果进程因任何原因退出,源也会退出,并且不会产生进一步的数据。
- 这意味着配置例如
cat [named pipe] or tail -F [file]将产生预期的结果日期可能不会-前两个命令生成数据流,后者生成单个事件并退出。
利用exec源监控某个文件
利用node2上的 flume 进行配置
官方介绍如下
-
编写自定义配置文件 option-exec
[root@node2 dirflume]# vim option-exec# 配置文件内容 # 主要是通过 a1.sources.r1.command = tail -F /root/log.txt 这条配置来监控log.txt文件中的内容 # example.conf: A single-node Flume configuration# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1# Describe/configure the sourcea1.sources.r1.type = exec a1.sources.r1.command = tail -F /root/log.txt a1.sources.r1.channels = c1# Describe the sink a1.sinks.k1.type = logger# Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100# Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 -
创建被监控的文件( 文件没有会自动创建, 但是下面演示目录不会)
vim /root/log.txt# 文件内容如下 hello flume -
启动 flume ,查看结果( 图1)
flume-ng agent --conf-file option-exec --name a1 -Dflume.root.logger=INFO,console -
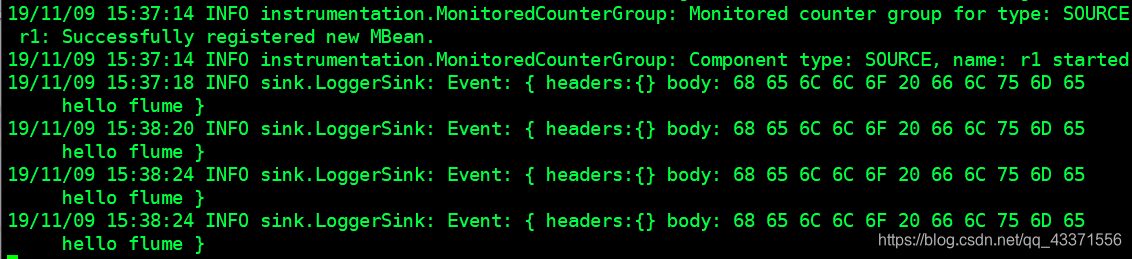
我们可以通过echo 向文件中追加内容 ,查看node2的 flume的阻塞式界面是否显示数据(图2,图3)
echo 'hello flume' >> /root/log.txt echo 'hello flume' >> /root/log.txt echo 'hello flume' >> /root/log.txt ....注意 :
a.我们通常在项目中使用exec源来监控某些日志文件的数据
b.我们可以通过修改配置文件中的a1.sources.r1.command = tail -F /root/log.txt配置来决定是否在一开始读取时读取全部文件,如果我们使用的是tail -f -n 3 /root/log.txt则是从倒数第三行开始输出
图1

图2

图3
四 JMS源
JMS源从JMS目的地(如队列或主题)读取消息。作为JMS应用程序,它应该与任何JMS提供程序一起工作,但只在ActiveMQ中进行了测试。JMS源提供可配置的批处理大小、消息选择器、用户/传递和消息到Flume事件转换器。请注意,供应商提供的JMS JAR应该使用命令行上的plugins.d目录(首选)、-classpath或Flume_CLASSPATH变量(flume-env.sh)包含在Flume类路径中
现在来说用处不大
五 Spooling Directory 源
-
通过此源,您可以通过将要摄取的文件放入磁盘上的“Spooling”目录中来摄取数据。该源将监视指定目录中的新文件,并从出现的新文件中解析事件。事件解析逻辑是可插入的。将给定文件完全读入通道后,将其重命名以指示完成(或选择删除)。
-
与Exec源不同,此源是可靠的,即使Flume重新启动或终止,它也不会丢失数据。为了获得这种可靠性,必须仅将不可变的唯一命名的文件放入Spooling目录中。Flume尝试检测这些问题情况,如果违反这些条件,将返回失败:
-
如果将文件放入Spooling目录后写入文件,Flume将在其日志文件中打印错误并停止处理。
如果以后再使用文件名,Flume将在其日志文件中打印错误并停止处理。
为避免上述问题,将唯一的标识符(例如时间戳)添加到日志文件名称(当它们移到Spooling目录中时)可能会很有用。 -
尽管有此来源的可靠性保证,但是在某些情况下,如果发生某些下游故障,则事件可能会重复。这与Flume其他组件提供的保证是一致的。
-
官方介绍如下
利用Spooling Directory源监控目录
-
修改自定义配置文件( vim .option-spooldir),内容如下
# example.conf: A single-node Flume configuration# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1# Describe/configure the source a1.sources.r1.type = spooldir a1.sources.r1.spoolDir = /root/log a1.sources.r1.fileHeader = false# Describe the sink a1.sinks.k1.type = logger# Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100# Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 -
根据配置文件中
a1.sources.r1.spoolDir = /root/log的配置,创建 .root/log目录 -
启动 flume
flume-ng agent --conf-file option-spooldir --name a1 -Dflume.root.logger=INFO,console -
其他文件的目录下的文件移动到 /root/log文件夹下, 观察flume的阻塞式界面(图1)
可以看到,被读取后文件的后缀名会被修改( 图2 ) -
补充: 我们可以自定义这个后缀名 ,通过图3 设置 ,效果如图4 所示
图1

图2

图3
通过修改自定义文件的下面配置, 可以设置文件被读取后的后缀名 ,默认是 .completed
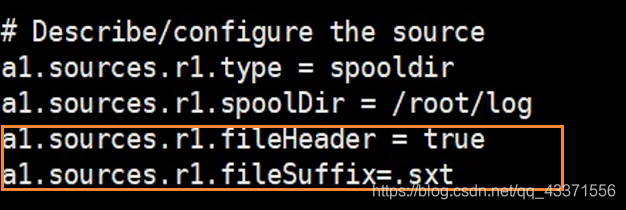
图4
修改后,再次启动 flume,查看被读取目录下的文件,可以看到被读取的文件后缀变成了 .sxt结尾

六 Kafka源
KafkaSource是一个ApacheKafka消费者,负责阅读来自Kafka主题的信息。如果您有多个Kafka源正在运行,您可以使用相同的ConsumerGroup来配置它们,这样每个用户都会为主题读取一组唯一的分区。
注意: Kafka Source覆盖两个Kafka消费者参数:
- auto.committee.Enable被源设置为“false”,我们提交每一批。为了提高性能,可以将其设置为“true”,但是,这可能导致数据使用者的丢失。
- timeout.ms被设置为10 ms,所以当我们检查Kafka是否有新数据时,我们最多要等待10 ms才能到达,将其设置为更高的值可以降低CPU利用率(我们将在较少的紧循环中轮询Kafka),但也意味着写入通道的延迟更高(因为我们将等待更长的数据到达时间)。
部分配置参数参考
ier1.sources.source1.type = org.apache.flume.source.kafka.KafkaSource
tier1.sources.source1.channels = channel1
tier1.sources.source1.zookeeperConnect = localhost:2181
tier1.sources.source1.topic = test1
tier1.sources.source1.groupId = flume
tier1.sources.source1.kafka.consumer.timeout.ms = 100
第四章 Flume Channel
Channel主要是用来缓冲Agent以及接受,但尚未写出到另外一个Agent或者存储系统的数据。Channel的行为比较像队列,Source写入到他们,Sink从他们中读取数据。多个Source可以安全的写入到同一Channel中,并且多个Sink可以从同一个Channel中读取数据。可是一个Sink只能从一个Channel读取数据,如果多个Sink从相同的Channel中读取数据,系统可以保证只有一个Sink会从Channel读取一个特定的事件。
关于channel的配置见 官网channel配置介绍
常见Flume Channel的分类
| Channel类型 | 说明 |
|---|---|
| Memory Channel | Event数据存储在内存中 |
| JDBC Channel | Event数据存储在持久化存储中,当前Flume Channel内置支持Derby |
| File Channel | Event数据存储在磁盘文件中 |
| Spillable Memory Channel | Event数据存储在内存中和磁盘上,当内存队列满了,会持久化到磁盘文件 |
| Pseudo Transaction Channel | 测试用途 |
| Custom Channel | 自定义Channel实现 |
第五章 Flume Sinks
Sink会连续轮训各自的Channel来读取和删除事件。Sink将事件推送到下一阶段(RPC Sink的情况下),或者到达最终目的地。一旦在下一阶段或者其目的地中数据是安全的,Sink通过事务提交通知Channel,可以从Channel中删除这一事件。
所有sink类型如下 ,下面介绍一些主要的sink
| Sink类型 | 说明 |
|---|---|
| HDFS Sink | 数据写入HDFS |
| Logger Sink | 数据写入日志文件 |
| Avro Sink | 数据被转换成Avro Event,然后发送到配置的RPC端口上 |
| Thrift Sink | 数据被转换成Thrift Event,然后发送到配置的RPC端口上 |
| IRC Sink | 数据在IRC上进行回放 |
| File Roll Sink | 存储数据到本地文件系统 |
| Null Sink | 丢弃到所有数据 |
| HBase Sink | 数据写入HBase数据库 |
| Morphline Solr Sink | 数据发送到Solr搜索服务器(集群) |
| ElasticSearch Sink | 数据发送到Elastic Search搜索服务器(集群) |
| Kite Dataset Sink | 写数据到Kite Dataset,试验性质的 |
| Custom Sink | 自定义Sink实现 |
HDFS Sink
这个接收器将事件写入Hadoop分布式文件系统(HDFS)。它目前支持创建文本和序列文件。它支持两种文件类型的压缩。可以根据经过的时间、数据大小或事件数周期性地滚动文件(关闭当前文件并创建新文件)。它还根据事件起源的时间戳或机器等属性对数据进行存储/分区。HDFS目录路径可能包含格式转义序列,这些转义序列将被HDFS接收器替换,以生成目录/文件名来存储事件。使用此接收器需要安装Hadoop,以便Flume可以使用HadoopJAR与HDFS集群通信。注意,支持sync()调用的Hadoop版本是必需的。
配置参数
注意
- 正在使用的文件的名称将经过修饰,以末尾包含“ .tmp”。关闭文件后,将删除此扩展名。这样可以排除目录中的部分完整文件。必需的属性以粗体显示。
- 对于所有与时间相关的转义序列,事件的标头中必须存在带有键“ timestamp”的标头(除非hdfs.useLocalTimeStamp设置为true)。一种自动添加此方法的方法是使用TimestampInterceptor。
配置参数

案例演示
-
创建flume 的自定义配置文件 hdfs-sink
a1.sources = r1 a1.sinks = k1 a1.channels = c1# Describe/configure the source a1.sources.r1.type = spooldir a1.sources.r1.spoolDir = /home/logs a1.sources.r1.fileHeader = true# Describe the sink a1.sinks.k1.type = logger a1.sinks.k1.type=hdfs # 这里注意flume注册时会自动加载hdfs, 因此可以不指定hdfs的路径 a1.sinks.k1.hdfs.path=/flume/events/%Y-%m-%d/%H%M##每隔60s或者文件大小超过10M的时候产生新文件 # hdfs有多少条消息时新建文件,0不基于消息个数 a1.sinks.k1.hdfs.rollCount=0 # hdfs创建多长时间新建文件,0不基于时间 a1.sinks.k1.hdfs.rollInterval=60 # hdfs多大时新建文件,0不基于文件大小 a1.sinks.k1.hdfs.rollSize=10240 # 当目前被打开的临时文件在该参数指定的时间(秒)内,没有任何数据写入,则将该临时文件关闭并重命名成目标文件 a1.sinks.k1.hdfs.idleTimeout=3## 每五分钟生成一个目录: # 是否启用时间上的”舍弃”,这里的”舍弃”,类似于”四舍五入”,后面再介绍。如果启用,则会影响除了%t的其他所有时间表达式 a1.sinks.k1.hdfs.round=true # 时间上进行“舍弃”的值; a1.sinks.k1.hdfs.roundValue=5 # 时间上进行”舍弃”的单位,包含:second,minute,hour a1.sinks.k1.hdfs.roundUnit=second a1.sinks.k1.hdfs.fileType=DataStream a1.sinks.k1.hdfs.useLocalTimeStamp=true # 设置超时时间 a1.sinks.k1.hdfs.callTimeout=60000# Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100# Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 -
根据自定义文件
a1.sources.r1.spoolDir = /home/logs,创建目录 ./home/logs -
运行 flume
flume-ng agent --conf-file hdfs-sink --name a1 -Dflume.root.logger=INFO,console -
移动任意日志文件到 /home/logs 目录下, 效果如图1, 图2所示
图1
flume 阻塞式界面输出相关信息
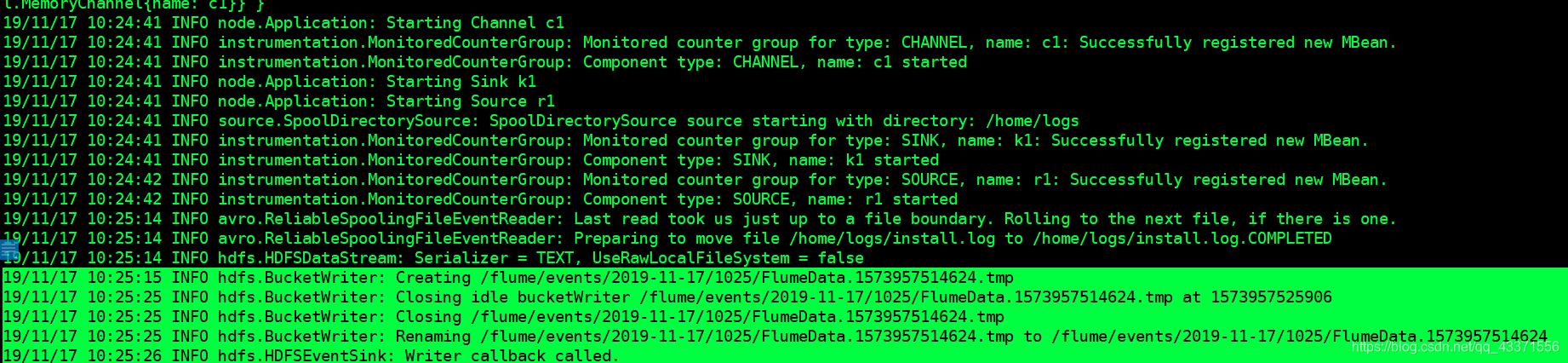
图2
可以看到日志被以时间的顺序读取到hdfs目录下
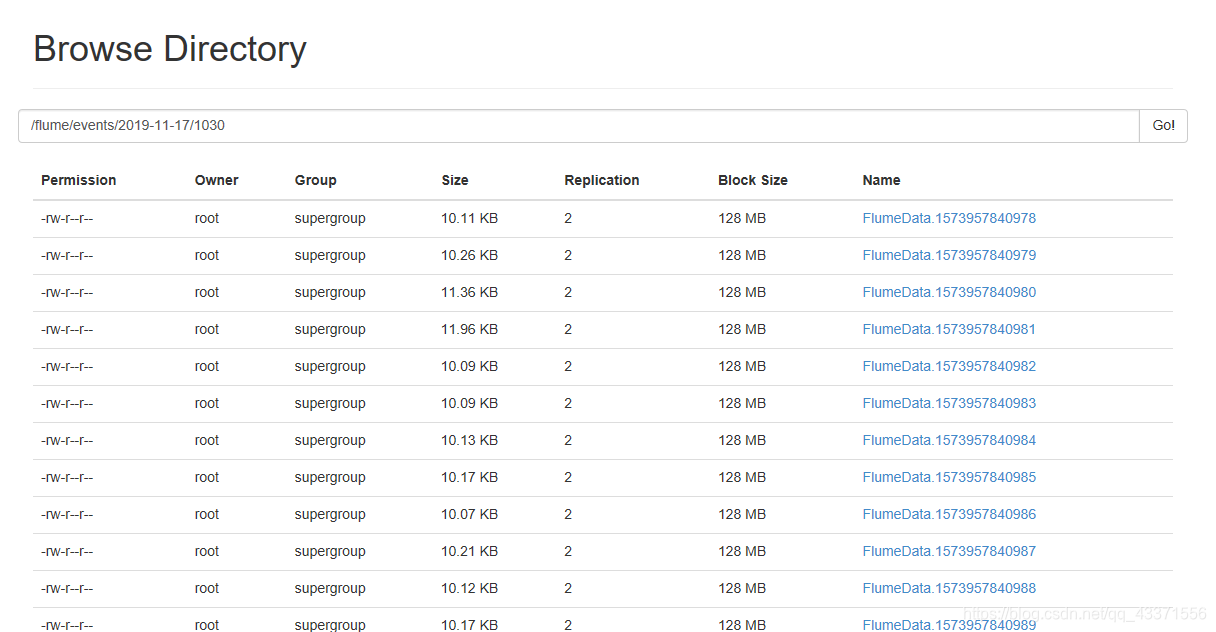
注意: 关于其他sink的配置见官网 官网介绍如下
flume在项目中的应用
flume读取指定目录文件(nginx的指定日志文件 这里是Nginx的配置 )下的数据
并将其收集保存在本地具体实现步骤如下
-
编写 flume的自定义配置文件 ,文件名 project
这里指定了读取nginx 的访问日志文件/opt/data/access.log
以及读取后的文件在hdfs的中的目录/log/%Y%m%d ,%Y%m%d是文件前面的目录名为当前日期
idleTimeout = 10代表10s内如果没有文件传输, 自动关闭文件该文件的写入功能 ,10s再写入会被写入到另一个文件中a1.sources = r1 a1.sinks = k1 a1.channels = c1# Describe/configure the source a1.sources.r1.type = spooldir a1.sources.r1.spoolDir = /home/logs a1.sources.r1.fileHeader = true# Describe the sink ## 指定sink为hdfs, 即从hdfs那里接受channel中的数据, 并指定hdfs的相关目录 a1.sinks.k1.type=hdfs a1.sinks.k1.hdfs.path=hdfs://logs/flume/%Y-%m-%d/%H%M##每隔60s或者文件大小超过10M的时候产生新文件 # hdfs有多少条消息时新建文件,0不基于消息个数 a1.sinks.k1.hdfs.rollCount=0 # hdfs创建多长时间新建文件,0不基于时间,时间单位 s a1.sinks.k1.hdfs.rollInterval=60 # hdfs多大时新建文件,0不基于文件大小 a1.sinks.k1.hdfs.rollSize=10240 # 当目前被打开的临时文件在该参数指定的时间(秒)内,没有任何数据写入,则将该临时文件关闭并重命名成目标文件 a1.sinks.k1.hdfs.idleTimeout=3a1.sinks.k1.hdfs.fileType=DataStream a1.sinks.k1.hdfs.useLocalTimeStamp=true## 每五分钟生成一个目录: # 是否启用时间上的”舍弃”,这里的”舍弃”,类似于”四舍五入”,后面再介绍。如果启用,则会影响除了%t的其他所有时间表达式 a1.sinks.k1.hdfs.round=true # 时间上进行“舍弃”的值; a1.sinks.k1.hdfs.roundValue=5 # 时间上进行”舍弃”的单位,包含:second,minute,hour a1.sinks.k1.hdfs.roundUnit=minute# Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100# Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 -
通过该自定义配置文件运行 flume
flume-ng agent --conf-file project --name a1 -Dflume.root.logger=INFO,console
资料分享
链接:https://pan.baidu.com/s/1uzhq8-aMXYm9qqjpDPeclg
点赞私聊获取配套Flume的软件安装包~~~
提取码:8a3c
复制这段内容后打开百度网盘手机App,操作更方便哦