实现字典树,支持插入和删除,能够打印每一层的数据
示例数据“SJ”, “SHJ”, “SGYY”,"HGL" ,将这些数据插入前缀树,打印树,修改SHZ为SHHZ
解题思路
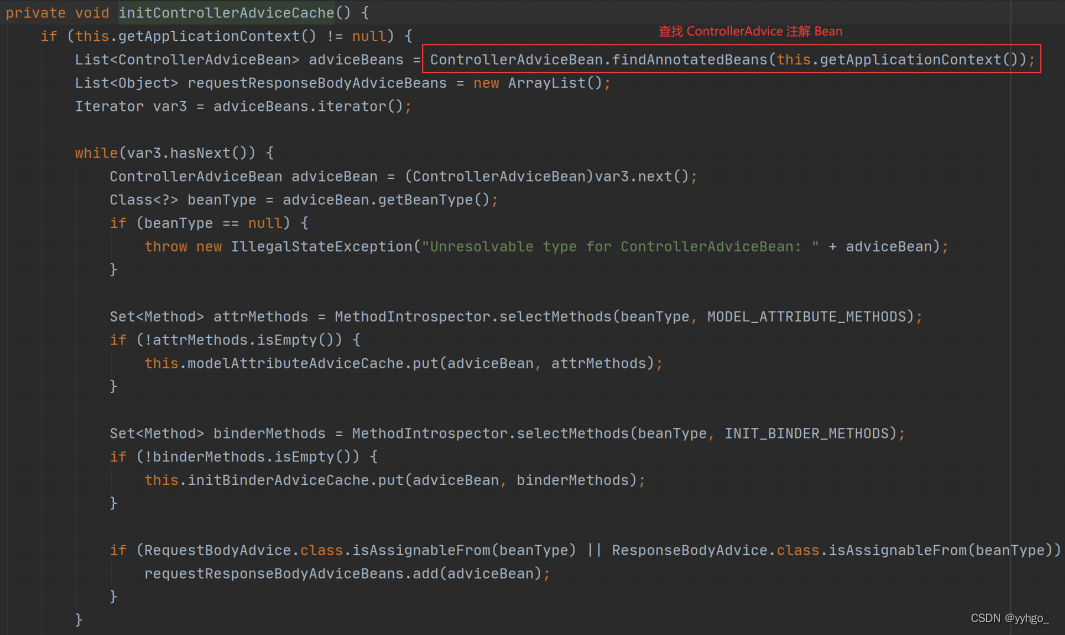
Trie树即字典树,又称单词查找树或键树,是一种树形结构,哈希树的变种。典型应用是用于统计和排序大量的字符串,所以经常被搜索引擎系统用于文本词频统计。它的优点是:最大限度地减少无谓的字符串比较,查询效率比哈希表高。Trie树的核心思想是空间换时间,利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。它有3个基本性质:首先,根节点不包含字符,除根节点外每一个节点都只包含一个字符;其次,从根节点到某一节点路径上经过的字符连接起来,为该节点对应的字符串;最后,每个节点的所有子节点包含的字符都不相同。结点类Node的主要数据结构有:Character类型的name,表示当前结点的字符;TreeMap<Character,Node>类型的子节点列表next;布尔类型的isWordEnd表示当前结点是否为某个单词的结尾;Node类型的双亲结点parent和int类型的prefixCount表示前缀经过这个节点的字符的数量。
如果要插入一个单词word,首先要将该字符串拆分为一个个字符,然后每个字符作为一个节点依次从上往下插入。初始时当前结点cur为根结点,如果cur节点的子节点们不存在该字符,就直接将该子节点插入;否则说明已存在相同前缀,将前缀数量prefixCount自增。所有字符都处理完时cur指针指向这个单词的最后一个字符节点,如果这个节点还不是表示一个单词结尾,则把isWordEnd置为true。如果要删除单词,先向下搜索到此字符串的最后一个子节点,如果字符串不存在则无需删除;如果存在, 则看是不是叶子节点, 如果不是叶子节点则直接把节点的单词标记prefixCount置为false;如果是叶子节点,则一直往上搜索到被使用过的节点就停止搜索,因为从这个结点开始的所有结点都是为了索引要删除的这个单词,所以要把这些仅为了所以该单词的结点全部删除。删除后还需要将该路径上所有结点的prefixCount自减。字典树的层序遍历采用的是广度优先搜索(BFS)的思想,使用一个队列queue,初始时将根节点root进队,如果队列不为空,就输出队头的元素;再判断节点是否有孩子,如果有就将孩子进队,将遍历过的结点出队,循环以上步骤直到队列为空。若要查询单词word是否在Trie中,按照word每个字符顺序向下搜索即可。
import java.util.*;
public class trieTree {class Node {//当前节点表示的字符public Character name;// 子节点列表 Map<子节点字符,子节点>public TreeMap<Character,Node> next;// 是否表示一个单词的结尾public boolean isWordEnd;// 前缀经过这个节点的字符的数量public int prefixCount;// 父节点private Node parent;public Node(boolean isWordEnd) {this(null,isWordEnd,0);}// 构造函数public Node(Character name, boolean isWordEnd, int prefixCount) {this.name = name;this.isWordEnd = isWordEnd;this.prefixCount = prefixCount;this.next = new TreeMap<>();}public Node(Character name, boolean isWordEnd, int prefixCount, Node parent) {this(name,isWordEnd,prefixCount);this.parent = parent;}}// 根节点private Node root;//字典树中单词的个数private int size;public trieTree() {this.root = new Node(false);this.size = 0;}/*** 添加单词word先将字符串拆成每个字符, 然后每个字符作为一个节点依次从上往下插入即可。 生成的树的路径结构刚好就是字符串字符的顺序。*/public void add(String word){Node cur = this.root;for (char key : word.toCharArray()) {//cur节点的子节点们不存在该字符,则直接插入该子节点即可if(!cur.next.containsKey(key)){cur.next.put(key,new Node(key,false,1,cur));}else{//存在相同前缀, 前缀数量+1cur.next.get(key).prefixCount++;}// 更新指针cur = cur.next.get(key);}// 此时 cur指针指向一个单词的最后一个字符节点,如果这个节点还不是表示一个单词结尾,则标记它if (!cur.isWordEnd){cur.isWordEnd = true;this.size++;}}/*** 删除单词先向下搜索到此字符串的最后一个子节点。 如果字符串不存在则无需删除。 如果存在, 则看是不是叶子节点, 如果不是叶子节点直接把节点的单词标记位清除即可。如果是叶子节点, 则一直往上搜索是标记单词的节点 或者 是被使用过的节点就停止搜索(说明从该节点开始是无需删除的),然后从直接删除该节点下的要被删除的子节点即可。*/public void remove(String word){Node node = getPrefixLastNode(word);if (node == null || !node.isWordEnd){System.out.println("单词不存在");return;}// 如果不是叶子节点直接把单词标记去掉即可if (!node.next.isEmpty()){node.isWordEnd = false;}else{// 往上找到是标记单词的 或者 被使用过的节点 就停止Node pre = node; //指向需要被删除的子树的第一个节点node = node.parent; // 当前迭代指针while (node != null && !node.isWordEnd && node.prefixCount <= 1){pre = node;node = node.parent;}// 删除节点node的子节点pre.nameif (node != null){node.next.remove(pre.name);}}// 更新 从 root -> node路径上所有节点的 prefixCount 减1while(node != null){node.prefixCount--;node = node.parent;}}/*** 层次遍历*/public void levelOrder() {Queue<Node> queue = new ArrayDeque<>();queue.offer(this.root);// 上一层的最后一个节点Node preLayerLastNode = this.root;// 本层最后一个节点Node curLayerLastNode = this.root;int curLayer = 0; // 当前层数while(!queue.isEmpty()){Node tmp = queue.remove();if (curLayer != 0){System.out.print(tmp.name +"("+ tmp.prefixCount+"-" + tmp.isWordEnd + ")" + "\t");}TreeMap<Character, Node> treeMap = tmp.next;if (treeMap != null && !treeMap.isEmpty()){List<Node> arrayList = new ArrayList<>(treeMap.values());queue.addAll(arrayList);if (!arrayList.isEmpty()){curLayerLastNode = arrayList.get(arrayList.size()-1);}}//遍历到每一层的末尾就进行换行if (preLayerLastNode.equals(tmp)){curLayer++;preLayerLastNode = curLayerLastNode;System.out.print("\n" + curLayer + "| ");}}}/*** 查询单词word是否在Trie中按照word每个字符顺序向下搜索即可*/public boolean contains(String word) {Node node = getPrefixLastNode(word);return node != null && node.isWordEnd;}/*** 查询是否在Trie中有单词以prefix为前缀按照prefix每个字符顺序向下搜索即可*/public boolean hasPrefix(String prefix){return getPrefixLastNode(prefix) != null;}/*** 词频统计* 获取前缀prefix的数量*/public int getPrefixCount(String prefix){Node node = getPrefixLastNode(prefix);return node != null ? node.prefixCount : 0;}// 获取前缀表示的最后一个节点private Node getPrefixLastNode(String prefix){// 往下搜每个字符节点,能搜到结尾即代表存在并返回Node cur = root;for (char key : prefix.toCharArray()) {if(!cur.next.containsKey(key))return null;cur = cur.next.get(key);}return cur;}public static void main(String []args){trieTree trie = new trieTree();trie.add("SJ");trie.add("SHJ");trie.add("SGYY");trie.add("HGL");System.out.println(trie.contains("SHJ"));trie.levelOrder();trie.remove("SHJ");trie.add("SHHJ");trie.levelOrder();}
}