LBS的瓶颈和方案
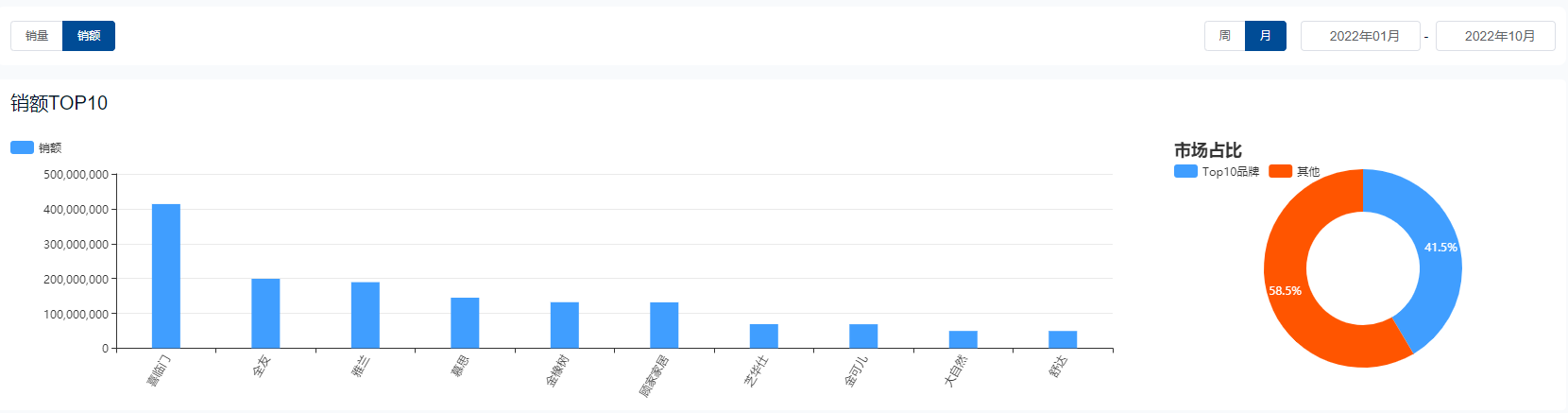
先看看基本的系统模型,如图1所示。
图1 系统模型示意图
- 司机每隔几秒钟上报一次经纬度,存储在MongoDB里;
- 乘客发单时,通过MongoDB圈选出附近司机;
- 将订单通过长连接服务推送给司机;
- 司机接单,开始服务。
MongoDB集群是一主多从的复制集方式,读写都很密集(4w+/s写、1w+/s读)时出现以下问题:
- 从服务器CPU负载急剧上升;
- 查询性能急剧降低(大量查询耗时超过800毫秒);
- 查询吞吐量大幅降低;
- 主从复制出现较大的延迟。
原因是当时的MongoDB版本(2.6.4)是库级别的锁每次写都会锁库,还有每一次LBS查询会分解成许多单独的子查询,增大整个查询的锁等待概率。我们最后将全国分为4个大区,部署多个独立的MongoDB集群,每个大区的用户存储在对应的MongoDB集群里。
长连接服务稳定性
我们的长连接服务通过Socket接收客户端心跳、推送消息给乘客和司机。打车大战期间,长连接服务非常不稳定。
先说说硬件问题,现象是CPU的第一个核经常使用率100%,其他的核却非常空闲,系统吞吐量上不去,对业务的影响很大。经过较长时间排查,最终发现这是因为服务器用了单队列网卡,I/O中断都被分配到了一个CPU核上,大量数据包到来时,单个CPU核无法全部处理,导致LVS不断丢包连接中断。最后解决这个问题其实很简单,换成多队列网卡就行。
再看软件问题,长连接服务当时用Mina实现,Mina本身存在一些问题:内存使用控制粒度不够细、垃圾回收难以有效控制、空闲连接检查效率不高、大量连接时周期性CPU使用率飙高。快的打车的长连接服务特点是:大量的广播、消息推送具有不同的优先级、细粒度的资源监控。最后我们用AIO重写了这个长连接服务框架,彻底解决了这个问题。主要有以下特性:
- 针对快的场景定制开发;
- 资源(主要是ByteBuffer)池化,减少GC造成的影响;
- 广播时,一份ByteBuffer复用到多个通道,减少内存拷贝;
- 使用TimeWheel检测空闲连接,消除空闲连接检测造成的CPU尖峰;
- 支持按优先级发送数据。
其实Netty已经实现了资源池化和TimeWheel方式检测空闲连接,但无法做到消息优先级区分和细粒度监控,这也算是快的自身的定制特性吧,通用的通信框架确实不好满足。选用AIO方式仅仅是因为AIO的编程模型比较简单而已,其实底层的性能并没有多大差别。
系统分布式改造
快的打车最初只有两个系统,一个提供HTTP服务的Web系统,一个提供TCP长连接服务的推送系统,所有业务运行在这个Web系统里,代码量非常庞大,代码下载和编译都需要花较长时间。
业务代码都混在一起,频繁的日常变更导致并行开发的分支非常多,测试和代码合并以及发布验证的效率非常低下,常常一发布就通宵。这种情况下,系统的伸缩性和扩展性非常差,关键业务和非关键业务混在一起,互相影响。
因此我们Web系统做了拆分,将整个系统从上往下分为3个大的层次:业务层、服务层以及数据层。
我们在拆分的同时,也仔细梳理了系统之间的依赖。对于强依赖场景,用Dubbo实现了RPC和服务治理。对于弱依赖场景,通过RocketMQ实现。Dubbo是阿里开源的框架,在阿里内部和国内大型互联网公司有广泛的应用,我们对Dubbo源码比较了解。RocketMQ也是阿里开源的,在内部得到了非常广泛的应用,也有很多外部用户,可简单将RocketMQ理解为Java版的Kafka,我们同样也对RocketMQ源码非常了解,快的打车所有的消息都是通过RocketMQ实现的,这两个中间件在线上运行得非常稳定。
借着分布式改造的机会,我们对系统全局也做了梳理,建立研发流程、代码规范、SQL规范,梳理链路上的单点和性能瓶颈,建立服务降级机制。
无线开放平台
当时客户端与服务端通信面临以下问题。
- 每新增一个业务请求,Web工程就要改动发布。
- 请求和响应格式没有规范,导致服务端很难对请求做统一处理,而且与第三方集成的方式非常多,维护成本高。
- 来多少请求就处理多少,根本不考虑后端服务的承受能力,而某些时候需要对后端做保护。
- 业务逻辑比较分散,有的在Web应用里,有的在Dubbo服务里。提供新功能时,工程师关注的点比较多,增加了系统风险。
- 业务频繁变化和快速发展,文档无法跟上,最后没人能说清到底有哪些协议,协议里的字段含义。
针对这些问题,我们设计了快的无线开放平台KOP,以下是一些大的设计原则。
-
接入权限控制
为接入的客户端分配标示和密钥,密钥由客户端保管,用来对请求做数字签名。服务端对客户端请求做签名校验,校验通过才会执行请求。 -
流量分配和降级
同样的API,不同接入端的访问限制可以不一样。可按城市、客户端平台类型做ABTest。极端情况下,优先保证核心客户端的流量,同时也会优先保证核心API的服务能力,例如登录、下单、接单、支付这些核心的API。被访问被限制时,返回一个限流错误码,客户端根据不同场景酌情处理。 -
流量分析
从客户端、API、IP、用户多个维度,实时分析当前请求是否恶意请求,恶意的IP和用户会被冻结一段时间或永久封禁。 -
实时发布
上线或下线API不需要对KOP进行发布,实时生效。当然,为了安全,会有API的审核机制。 -
实时监控
能统计每个客户端对每个API每分钟的调用总量、成功量、失败量、平均耗时,能以分钟为单位查看指定时间段内的数据曲线,并且能对比历史数据。当响应时间或失败数量超过阈值时,系统会自动发送报警短信。
实时计算与监控
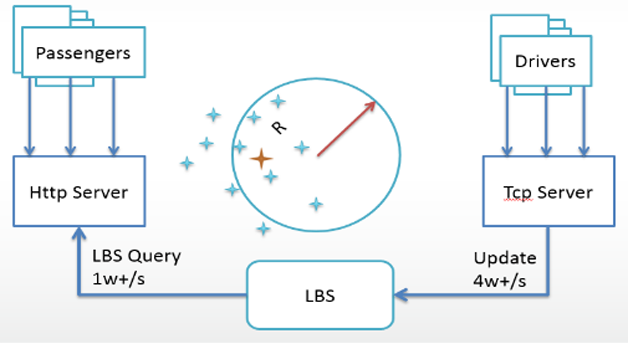
我们基于Storm和HBase设计了自己的实时监控平台,分钟级别实时展现系统运行状况和业务数据(架构如图2所示),包含以下几个主要部分。
图2 监控系统架构图
-
核心计算模型
求和、求平均、分组。 -
基于Storm的实时计算
Storm的逻辑并不复杂,只有两个Bolt,一个将一条日志解析成KV对,另外一个基于KV和设定的规则进行计算。每隔一分钟将数据写入RocketMQ。 -
基于HBase的数据存储
只有插入没有更新,避免了HBase行锁竞争。rowkey是有序的,因为要根据维度和时间段查询,这样会形成HBase Region热点,导致写入比较集中,但是没有性能问题,因为每个维度每隔1分钟定时插入,平均每秒的插入很少。即使前端应用的日志量突然增加很多,HBase的插入频度仍然是稳定的。 -
基于RocketMQ的数据缓冲
收集的日志和Storm计算的结果都先放入MetaQ集群,无论Storm集群还是存储节点,发生故障时系统仍然是稳定的,不会将故障放大;即使有突然的流量高峰,因为有消息队列做缓冲,Storm和HBase仍然能以稳定的TPS处理。这些都极大的保证了系统的稳定性。RocketMQ集群自身的健壮性足够强,都是物理机。SSD存储盘、高配内存和CPU、Broker全部是M/S结构。可以存储足够多的缓冲数据。
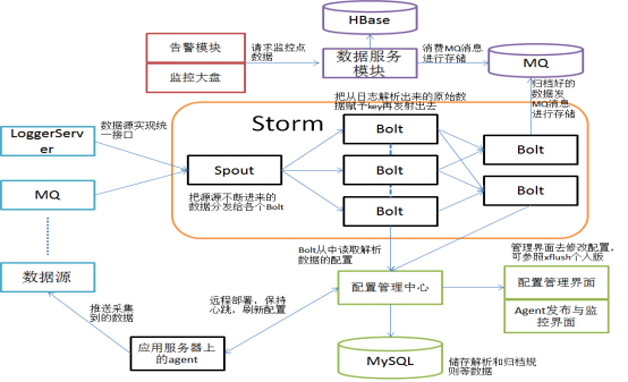
某个系统的实时业务指标(关键数据被隐藏),见图3。
图3 某个业务系统大盘截图
数据层改造
随着业务发展,单数据库单表已经无法满足性能要求,特别是发券和订单,我们选择在客户端分库分表,自己做了一个通用框架解决分库分表的问题。但是还有以下问题:
-
数据同步
快的原来的数据库分为前台库和后台库,前台库给应用系统使用,后台库只供后台使用。不管前台应用有多少库,后台库只有一个,那么前台的多个库多个表如何对应到后台的单库单表?MySQL的复制无法解决这个问题。 -
离线计算抽取
还有大数据的场景,大数据同事经常要dump数据做离线计算,都是通过Sqoop到后台库抽数据,有的复杂SQL经常会使数据库变得不稳定。而且,不同业务场景下的Sqoop会造成数据重复抽取,给数据库添加了更多的负担。
我们最终实现了一个数据同步平台,见图4。
图4 数据同步平台架构图
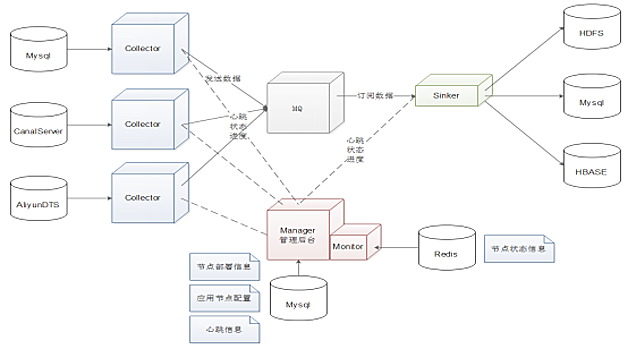
- 数据抽取用开源的canal实现,MySQL binlog改为Row模式,将canal抽取的binlog解析为MQ消息,打包传输给MQ;
- 一份数据,多种消费场景,之前是每种场景都抽取一份数据;
- 各个消费端不需要关心MySQL,只需要关心MQ的Topic;
- 支持全局有序,局部有序,并发乱序;
- 可以指定时间点回放数据;
- 数据链路监控、报警;
- 通过管理平台自动部署节点。
分库分表解决了前台应用的性能问题,数据同步解决了多库多表归一的问题,但是随着时间推移,后台单库的问题越来越严重,迫切需要一种方案解决海量数据存储的问题,同时又要让现有的上层应用不会有太大改动。因此我们基于HBase和数据同步设计了实时数据中心,如图5所示。
图5 实时数据中心架构图
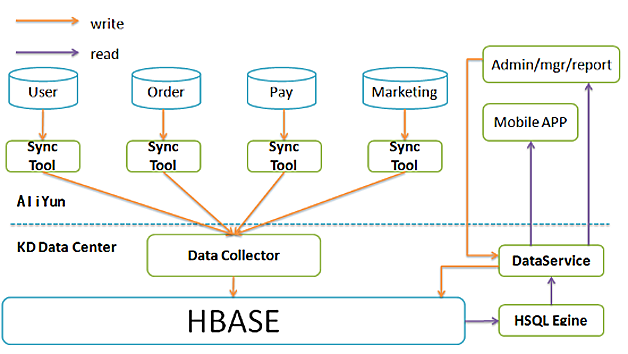
- 将前台MySQL多库多表通过同步平台,都同步到了HBase;
- 为减少后台应用层的改动,设计了一个SQL解析模块,将SQL查询转换为HBase查询;
-
支持二级索引。
说说二级索引,HBase并不支持二级索引,对它而言只有一个索引,那就是Rowkey。如果要按其它字段查询,那就要为这些字段建立与Rowkey的映射关系,这就是所谓的二级索引。HBase二级索引可以通过Coprocessor在数据插入之前执行一段代码,这段代码运行在HBase服务端(Region Server),可以让这段代码负责插入二级索引。实时数据中心的二级索引是在客户端负责插入的,并没有使用Coprocessor,主要原因是Coprocessor不容易实现索引的批量插入,而批量插入,实践证明,是提升HBase插入性能非常有效的手段。二级索引的应用其实还有些条件,如下: -
排序
在HBase中,只有一种排序,就是按Rowkey排序,因此,在建立索引的时候,实际上就定死了将来查询结果的排序。某个索引字段的reverse属性为true,则按这个字段倒序排序,否则正序排序。 - 打散
单调变化的Rowkey读写压力很难均匀分布到多个Region上,而打散将会使读写均匀分布到多个Region,因此提升了读写性能。但打散也有局限性,主要的是,经过打散的字段将无法支持范围查询。而且,hash和reverse这两个属性是互斥的,且hash优先级高,就是说一旦设置了hash=true,则会忽略reverse这个属性。 - 串联
另外需要特别强调的是,索引配置也影响到多表归一,作为“串联”的字段,必须建立唯一索引,如果串联字段上没有建立唯一索引,将无法完成多表归一。
我们还实现了一套将SQL语句转换成HBase API的引擎,可以通过SQL语句直接操作HBase。这里需要指出的是HSQL引擎和Hive是不同的,Hive主要用于将SQL语句转换成Hadoop的Map/Reduce任务,当然也可以转换成HBase的查询。但Hive无法利用二级索引(HBase本来就不存在二级索引这个概念),Hive主要面向的是大批量、低频度、高延迟、顺序读的访问场景,而HSQL可以有效利用二级索引,它面向的是小批量、高频度、低延迟、随机读的访问场景。