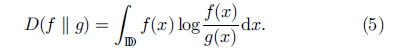在概率论和统计学中,我们经常用一个简单的近似分布来代替观测数据或复杂的分布.KL散度帮助我们衡量当我们选择一个简单近似的分布来代替复杂的数据或复杂的分布的时候有多少信息损失了.
一个例子
假设我们是太空科学家并在参观一个遥远的新星球,我们发现了一些蠕虫,我们想要研究他们.我们发现这些蠕虫都有10个牙齿,但是由于某些原因牙齿会进行脱落,从而导致每个蠕虫最后的牙齿个数各不相同.通过收集一系列数据,我们得到了每个蠕虫牙齿数量的经验概率分布:

现在我们需要将信息发回地球,但是这些信息量是很大,我们的花费也是巨大的.我们希望将这些数据减少到一个简单的模型,这样我们只需要发回1或2个参数即可.(这样我们就不需要发送那么多数值,只需要发回概率分布的参数即可)
均匀分布
我们首先使用均匀分布来表示牙齿的分布.
有11种可能的值,每个的概率都是 1 11 \frac{1}{11} <