一、常见的反爬手段和解决方法
二、splash 介绍与安装
三、验证码识别
图片验证码的处理方案
- 手动输入(input) 这种方法仅限于登录一次就可持续使用的情况
- 图像识别引擎解析 使用光学识别引擎处理图片中的数据,目前常用于图片数据提取,较少用于验证码处理
- 打码平台 爬虫常用的验证码解决方案
- 打码平台:
- 超级鹰
- 斐斐打码
以超级鹰举例:
1、注册用户
2、下载 Python语言Demo
3、打开 项目
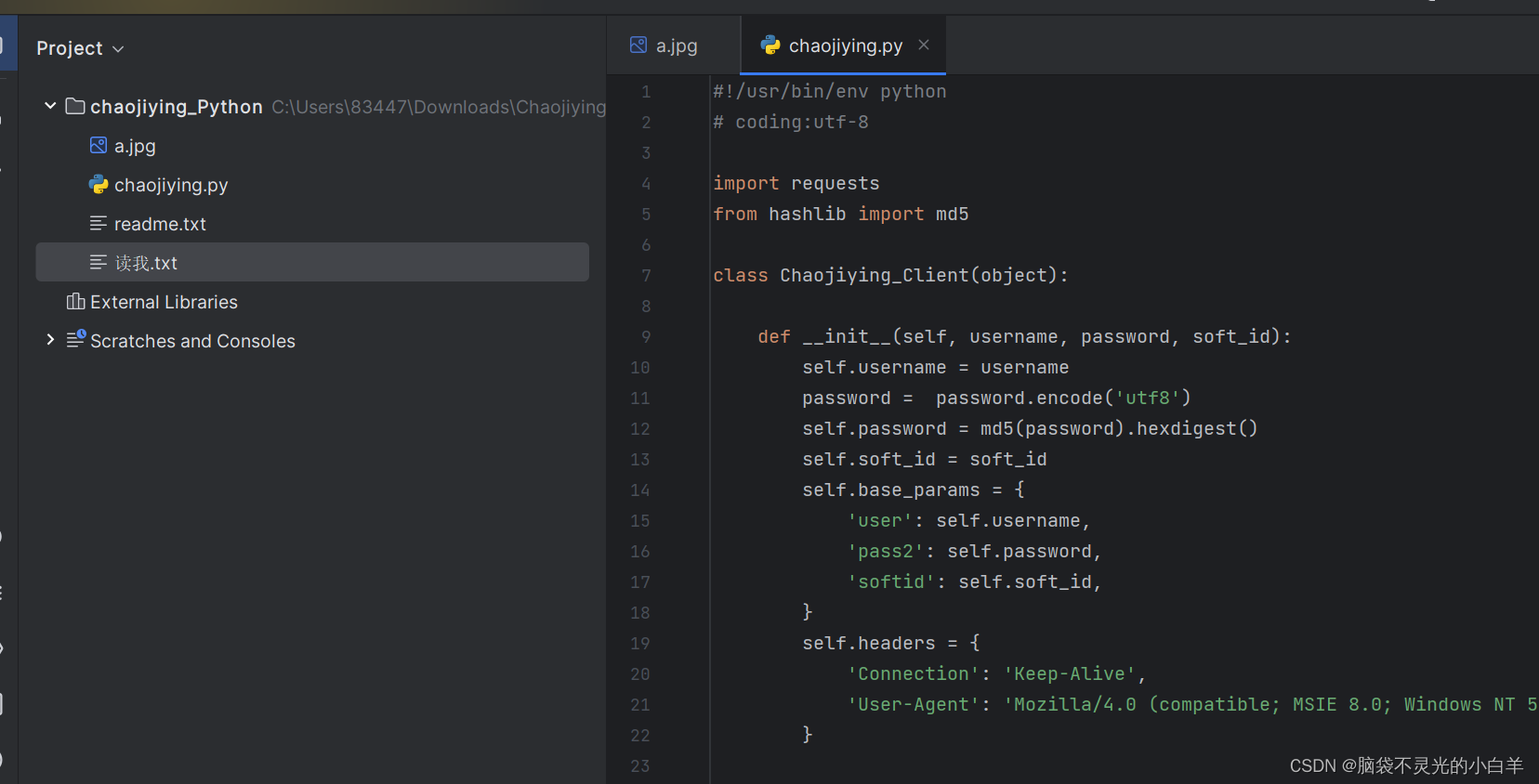
4、修改验证码类型、用户名、登录密码等信息
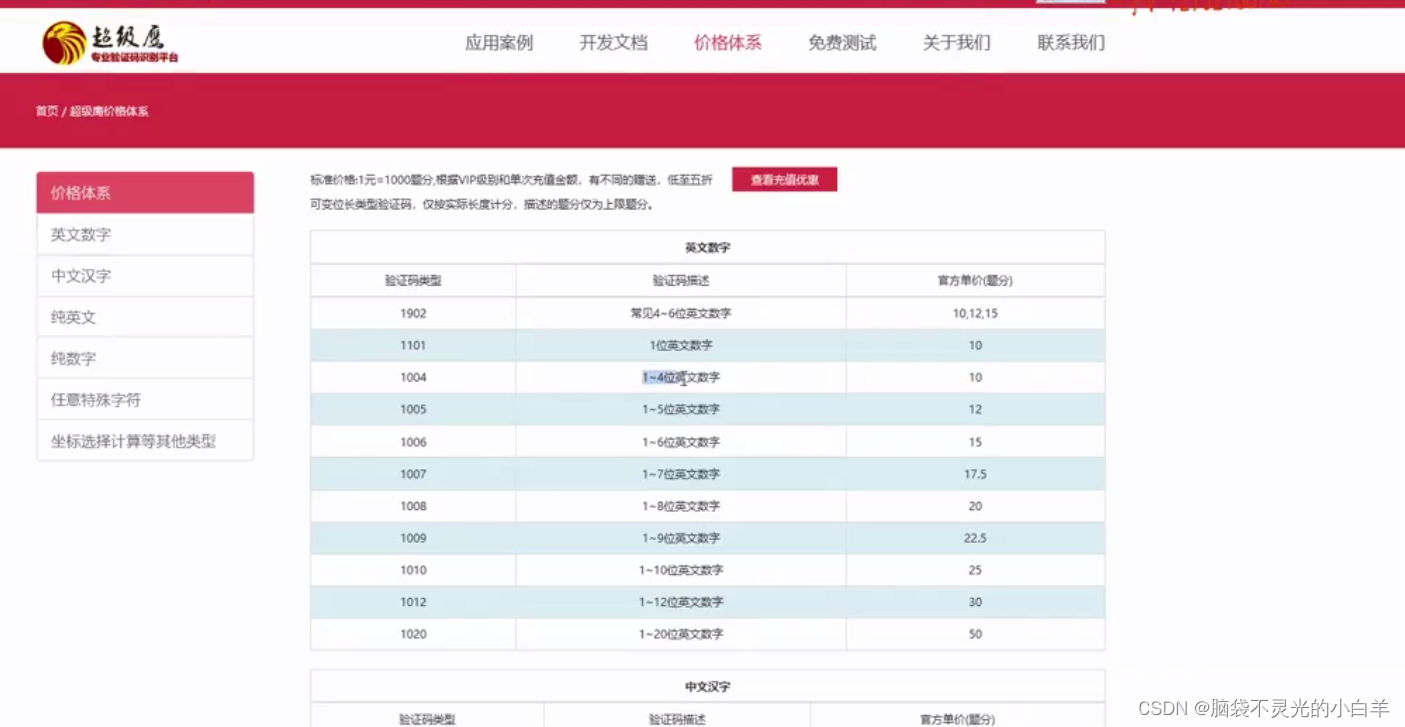
可以修改并封装代码方便以后调用
python">#!/usr/bin/env python
# coding:utf-8import requests
from hashlib import md5class Chaojiying_Client(object):def __init__(self, username, password, soft_id):self.username = usernamepassword = password.encode('utf8')self.password = md5(password).hexdigest()self.soft_id = soft_idself.base_params = {'user': self.username,'pass2': self.password,'softid': self.soft_id,}self.headers = {'Connection': 'Keep-Alive','User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)',}def PostPic(self, im, codetype):"""im: 图片字节codetype: 题目类型 参考 http://www.chaojiying.com/price.html"""params = {'codetype': codetype,}params.update(self.base_params)files = {'userfile': ('ccc.jpg', im)}r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files, headers=self.headers)return r.json()def PostPic_base64(self, base64_str, codetype):"""im: 图片字节codetype: 题目类型 参考 http://www.chaojiying.com/price.html"""params = {'codetype': codetype,'file_base64':base64_str}params.update(self.base_params)r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, headers=self.headers)return r.json()def ReportError(self, im_id):"""im_id:报错题目的图片ID"""params = {'id': im_id,}params.update(self.base_params)r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers)return r.json()def get_code(img_src,cpt_type):chaojiying = Chaojiying_Client('超级鹰用户名', '超级鹰用户名的密码', '96001') # 用户中心>>软件ID 生成一个替换 96001im = open(img_src, 'rb').read() # 本地图片文件路径 来替换 a.jpg 有时WIN系统须要//return chaojiying.Postpic(im.cap_type).get('pic_str')if __name__ == '__main__': #本地图片文件路径 来替换 a.jpg 有时WIN系统须要//print(get_code('chaojiying_Python/a.jpg',1004)) #1902 验证码类型 官方网站>>价格体系 3.4+版 print 后要加()#print chaojiying.PostPic(base64_str, 1902) #此处为传入 base64代码
三、验证码登录
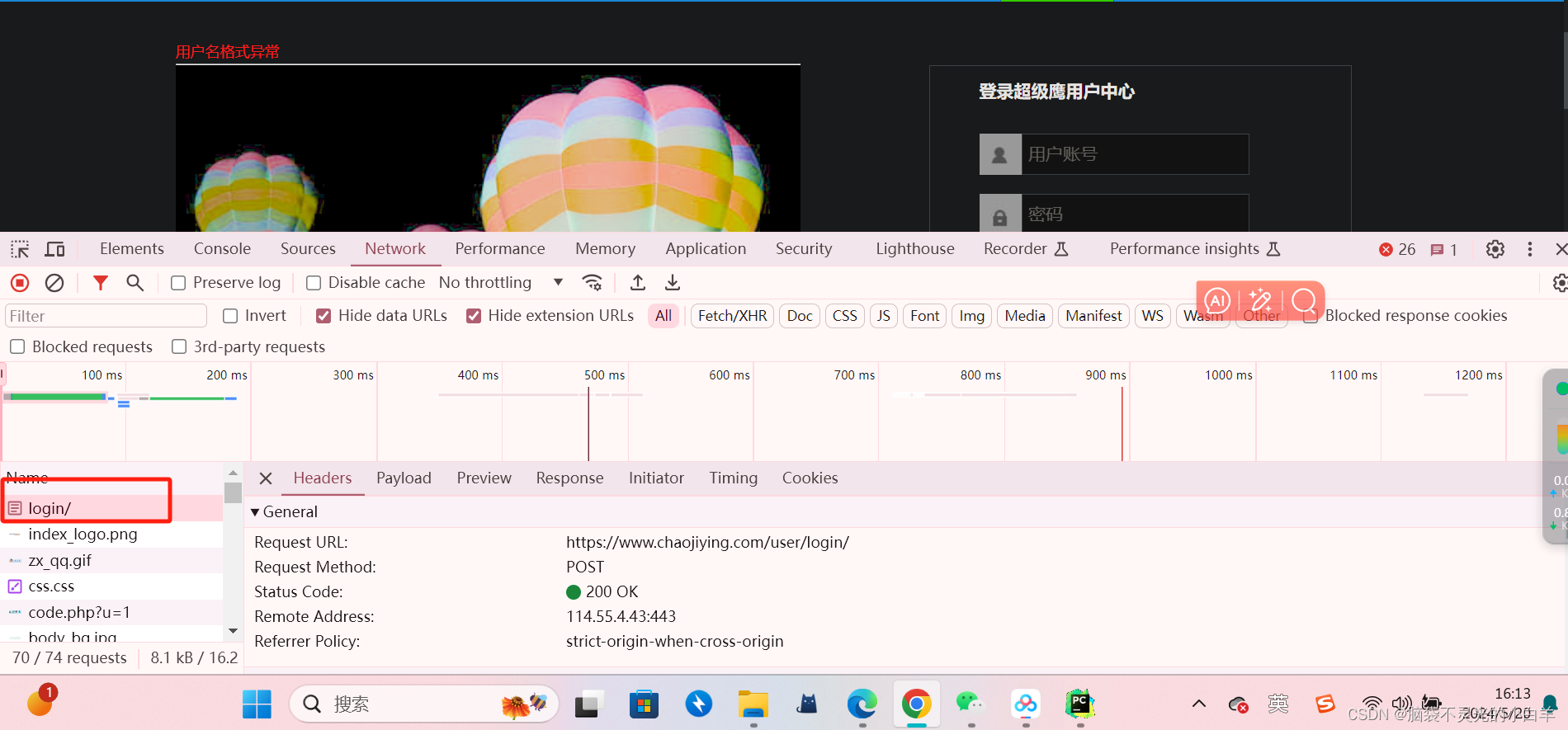
1、可以先输入一个错误的登录账号 找到登录接口
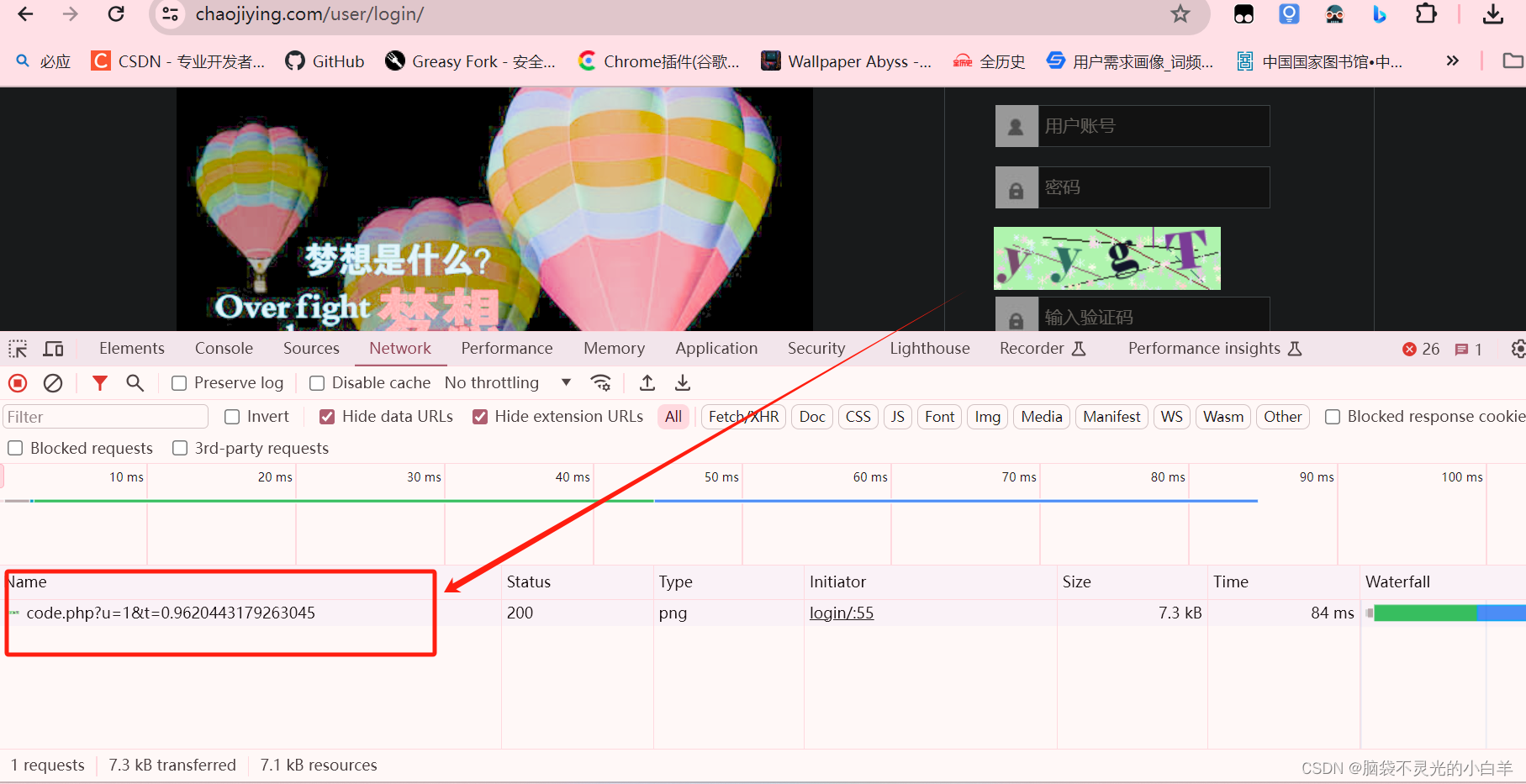
2、点击验证码 找到获取验证码图片的接口
编写代码:
python">import requests
from chaojiying.chaojiying import get_codedef login_input():headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36'}session = requests.Session()login_url = 'https://www.chaojiying.com/user/login/'img_url = 'https://www.chaojiying.com/include/code/code.php?u=1&t=0.5925062343043659'# 获取验证码img_resp = session.get(img_url,headers=headers)with open('tmp.png', 'wb') as f:f.write(img_resp.content)code= input('请输入验证码:')# 构造登录参数params = {"user": "ls1233456","pass": "123456","imgtxt": code,"act": "1"}# 登录resp = session.post(login_url,data=params,headers=headers)print(resp.text)def login_auto():headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36'}session = requests.Session()login_url = 'https://www.chaojiying.com/user/login/'img_url = 'https://www.chaojiying.com/include/code/code.php?u=1&t=0.5925062343043659'img_resp = session.get(img_url,headers=headers)with open('tmp.png', 'wb') as f:f.write(img_resp.content)# 识别验证码code= get_code('tmp.png',1004)# 构造登录参数params = {"user": "ls1233456","pass": "123456","imgtxt": code,"act": "1"}# 登录resp = session.post(login_url,data=params,headers=headers)print(resp.text)if __name__ == "__main__":login_auto()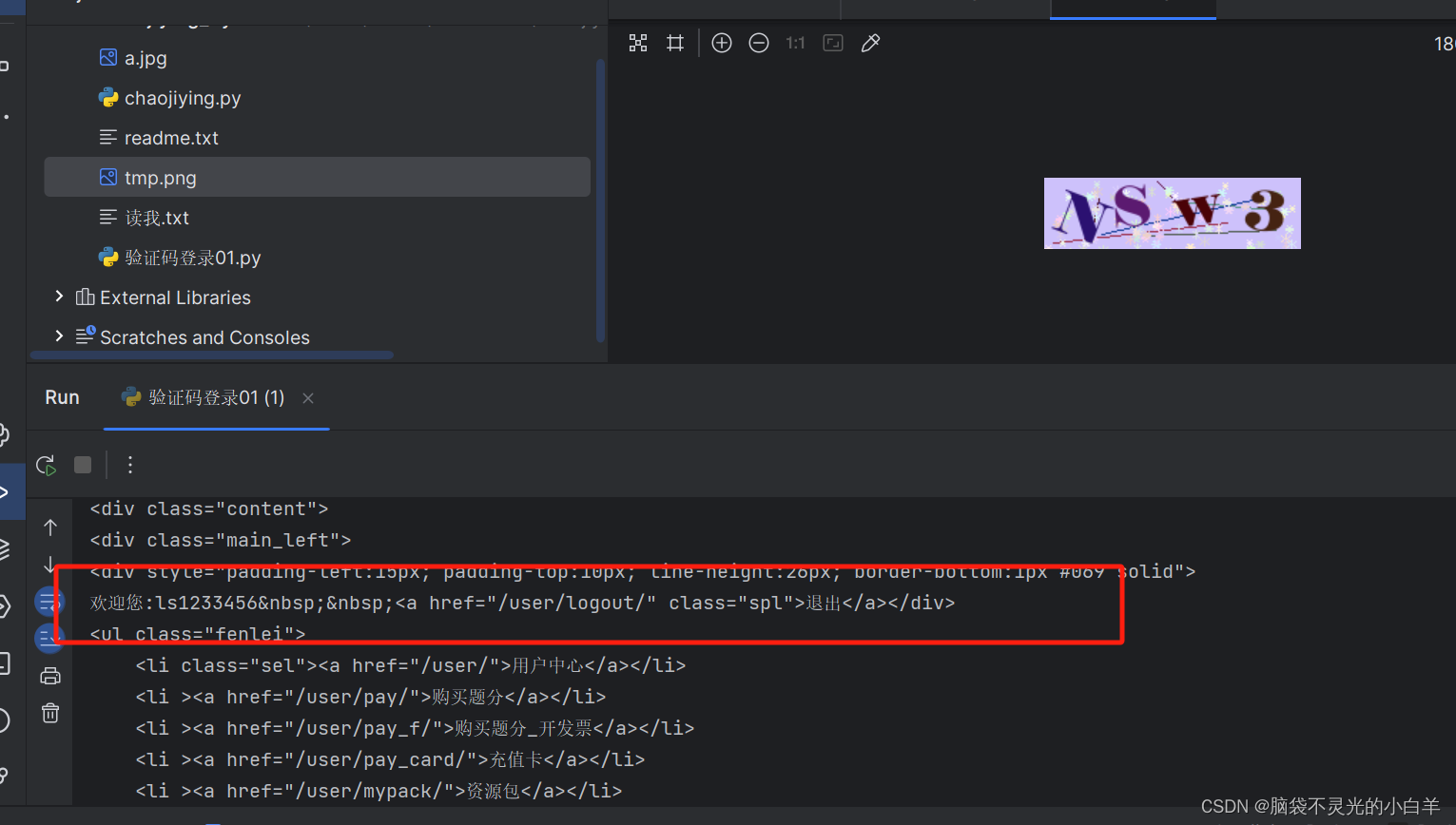
四、Chrome抓包分析JS数据源
目标:获取所有英雄并下载每个英雄的壁纸
找到每位英雄的壁纸接口
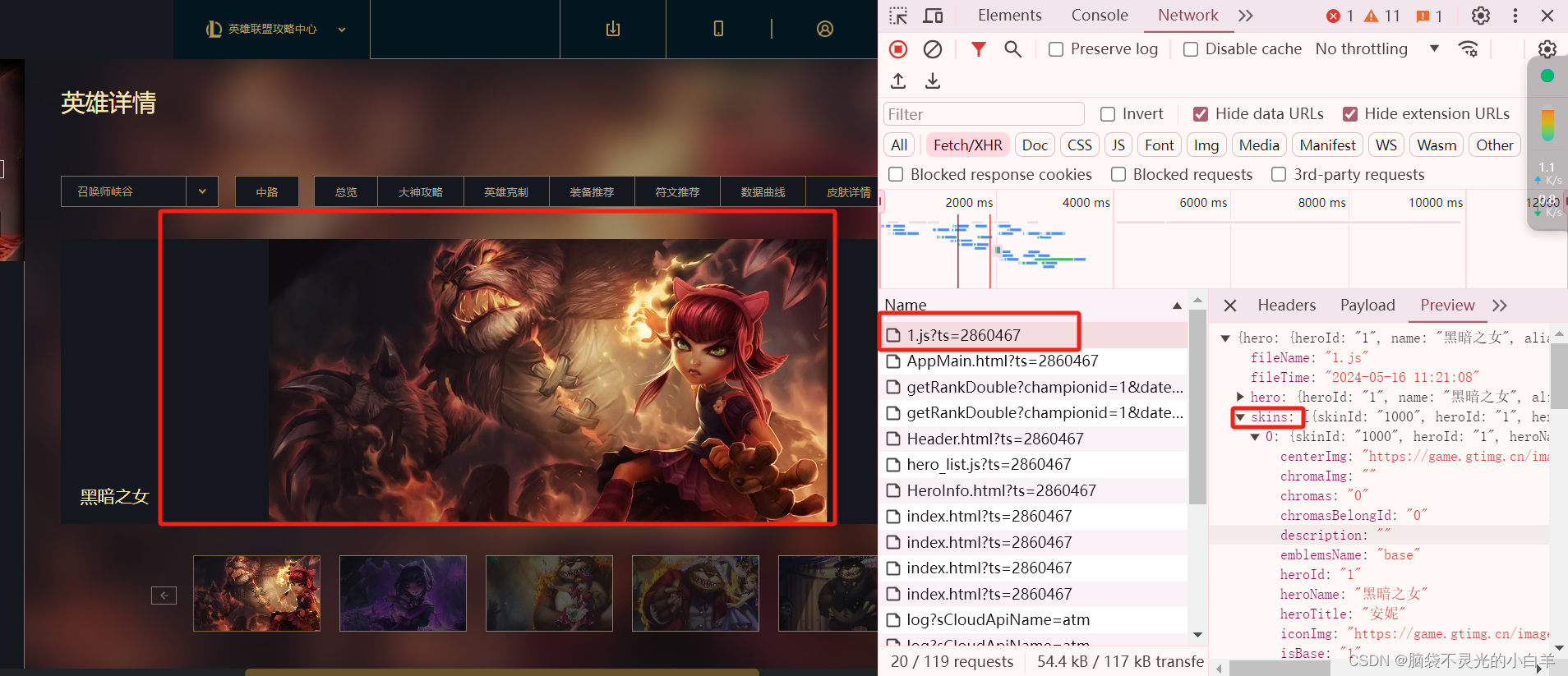
找到外层每位英雄的列表数据
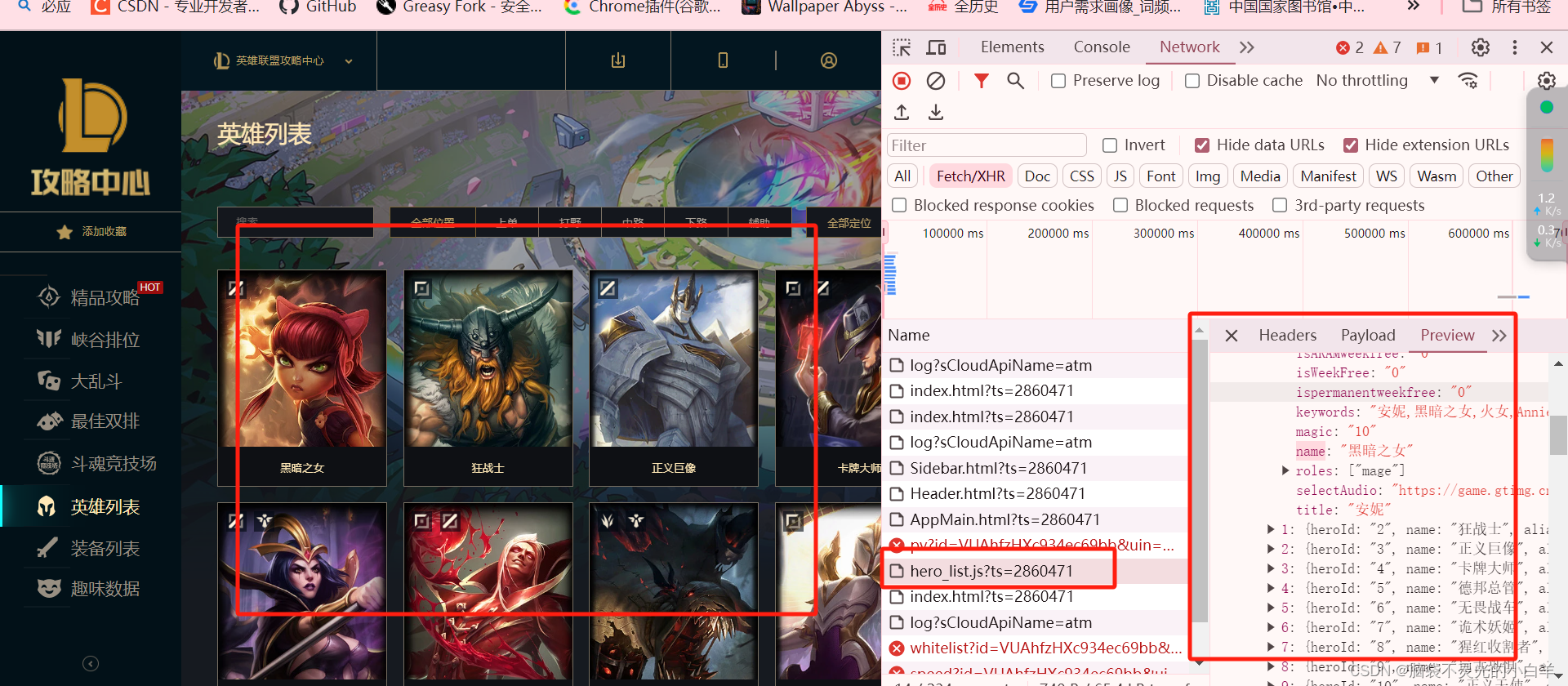
编写代码逻辑
python">import requests
import os
from time import sleepheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36'
}
hero_js = requests.get('https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js', headers=headers)
for hero in hero_js.json().get('hero'):id = hero.get('heroId')hero_name = hero.get('name')url = f'https://game.gtimg.cn/images/lol/act/img/js/hero/{id}.js'js_resp = requests.get(url, headers=headers)for sk in js_resp.json().get('skins'):file_name = sk.get('name').replace(' ','_')img_url = sk.get('mainImg')chromas = sk.get('chromas')if chromas == '0':img_resp = requests.get(img_url, headers=headers)sleep(1)print(f'正在下载:{file_name} 图片')file_dir = f'img/{hero_name}'if not os.path.exists(file_dir):os.mkdir(file_dir)with open(f'img/{hero_name}/{file_name}.png', 'wb') as f:f.write(img_resp.content)
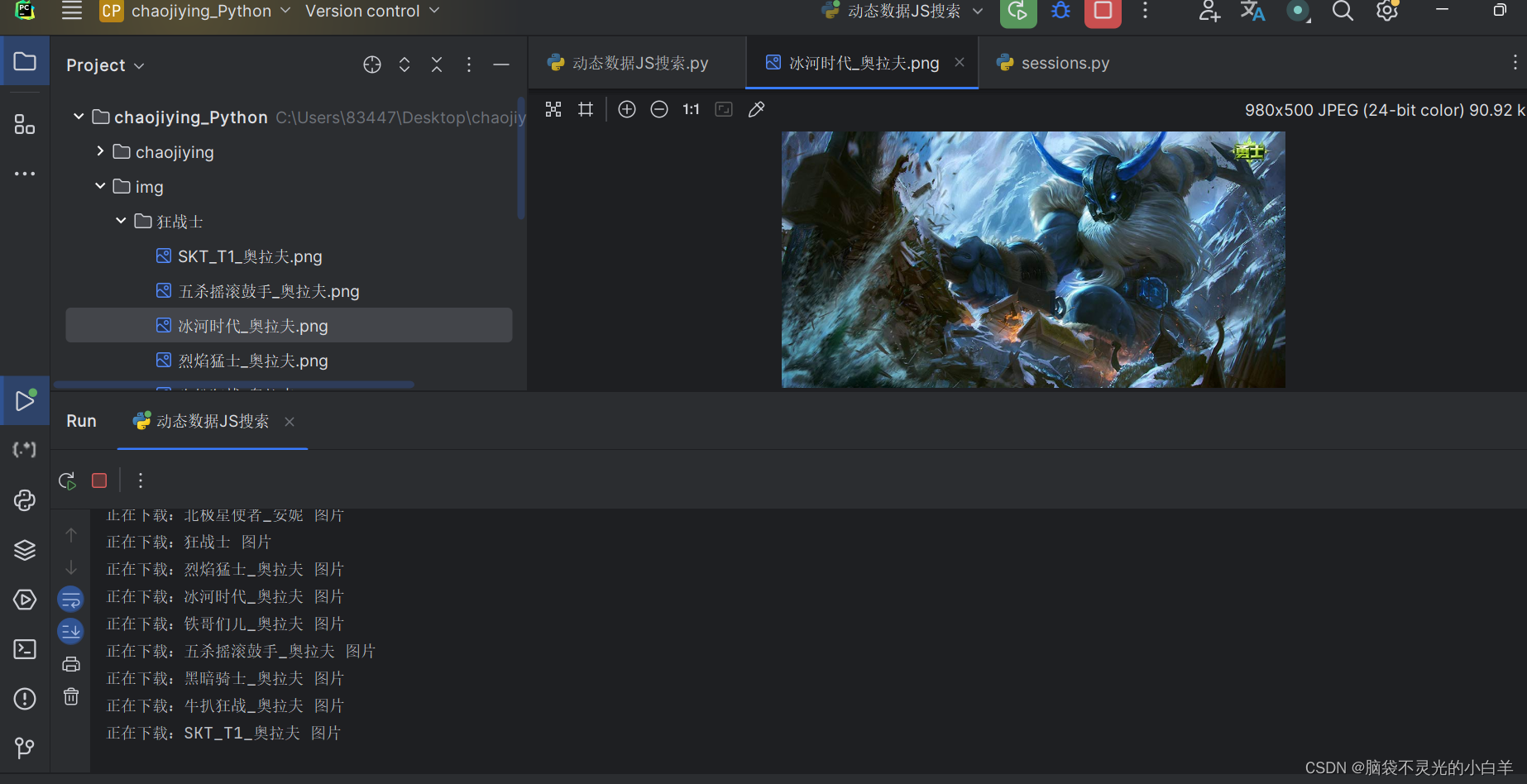
五、JS逆向的操作思路
pythonJS_211">六、python执行JS代码
python"># pip install PyExecJS
import execjs
# pip install js2py
import js2pyjs = '''
function add(num1, num2){return num1+num2;
}
function show(){return "hello python2js";
}
'''
def func1():ctx = execjs.compile(js)rs = ctx.call('add', 1, 2)print(rs)print(ctx.call('show'))def func2():context = js2py.EvalJs(js)context.execute(js)# result = context.add(1,2)result = context.show()print(result)if __name__ == '__main__':func2()
七、JS逆向生成加密数据
解密 微信公众平台 的登录密码 实现登录
下面是解密思路:
假设这里:账号是123,密码是123456,可以发现 密码已经被加密处理了,通过常规的 密码来登录是不好使的
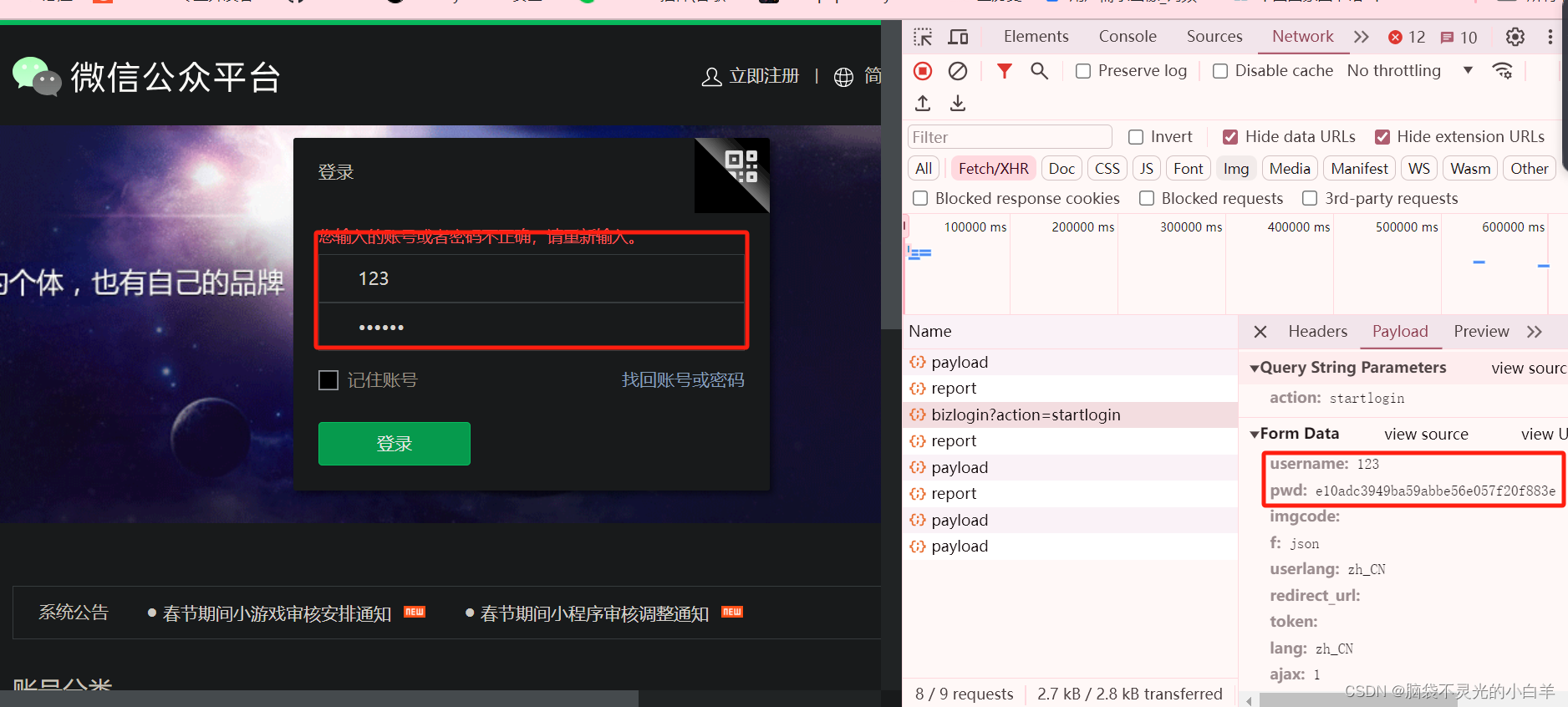
找到这个对密码进行加密的 js 函数,直接拿出来 放到我们的 python 中,这样我们可以通过它提供的加密规则 ,生成需要的密码来实现登录
首先搜索一下 谁调用了这bizlongin
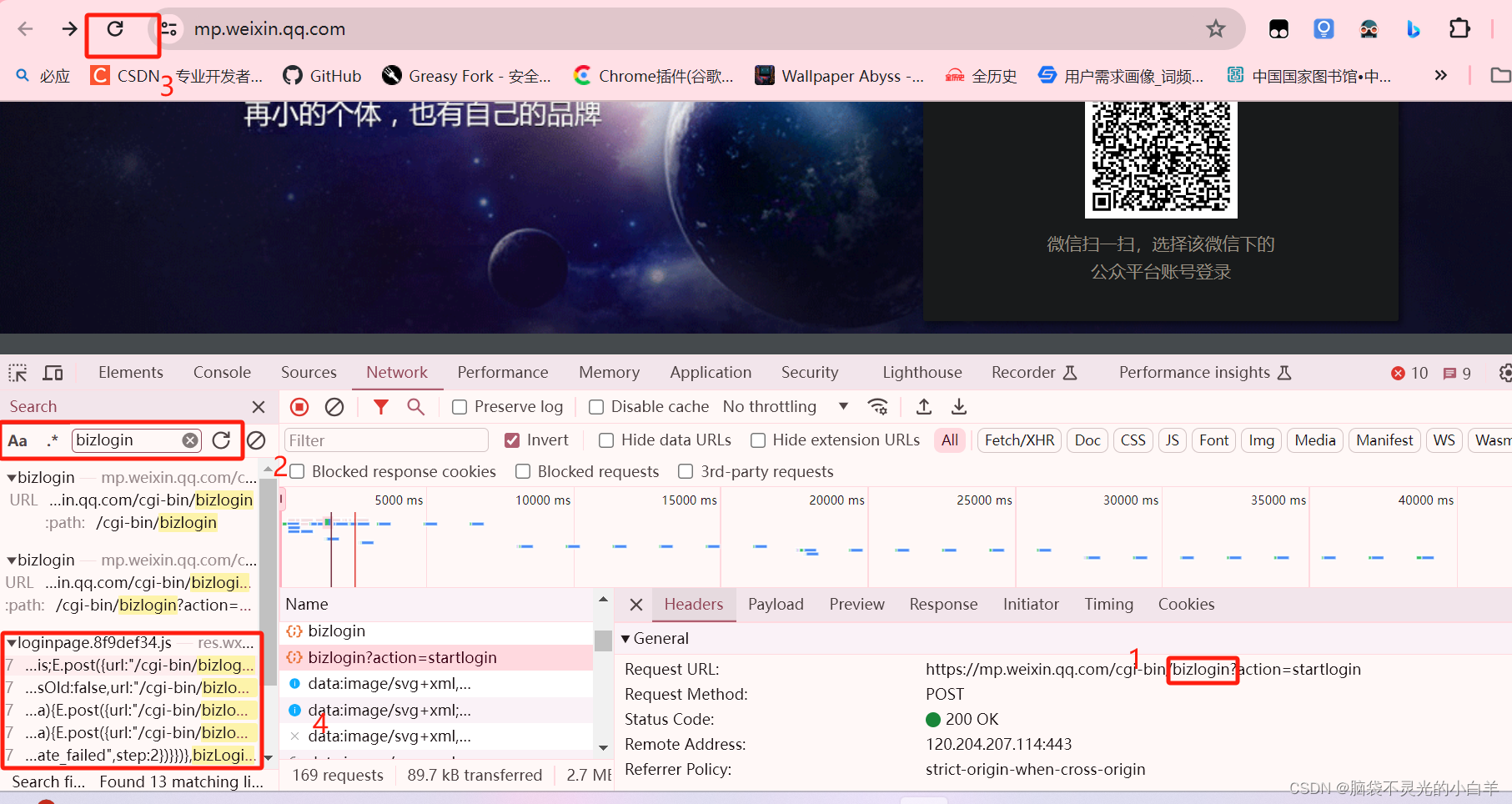
推测可能的 js 函数
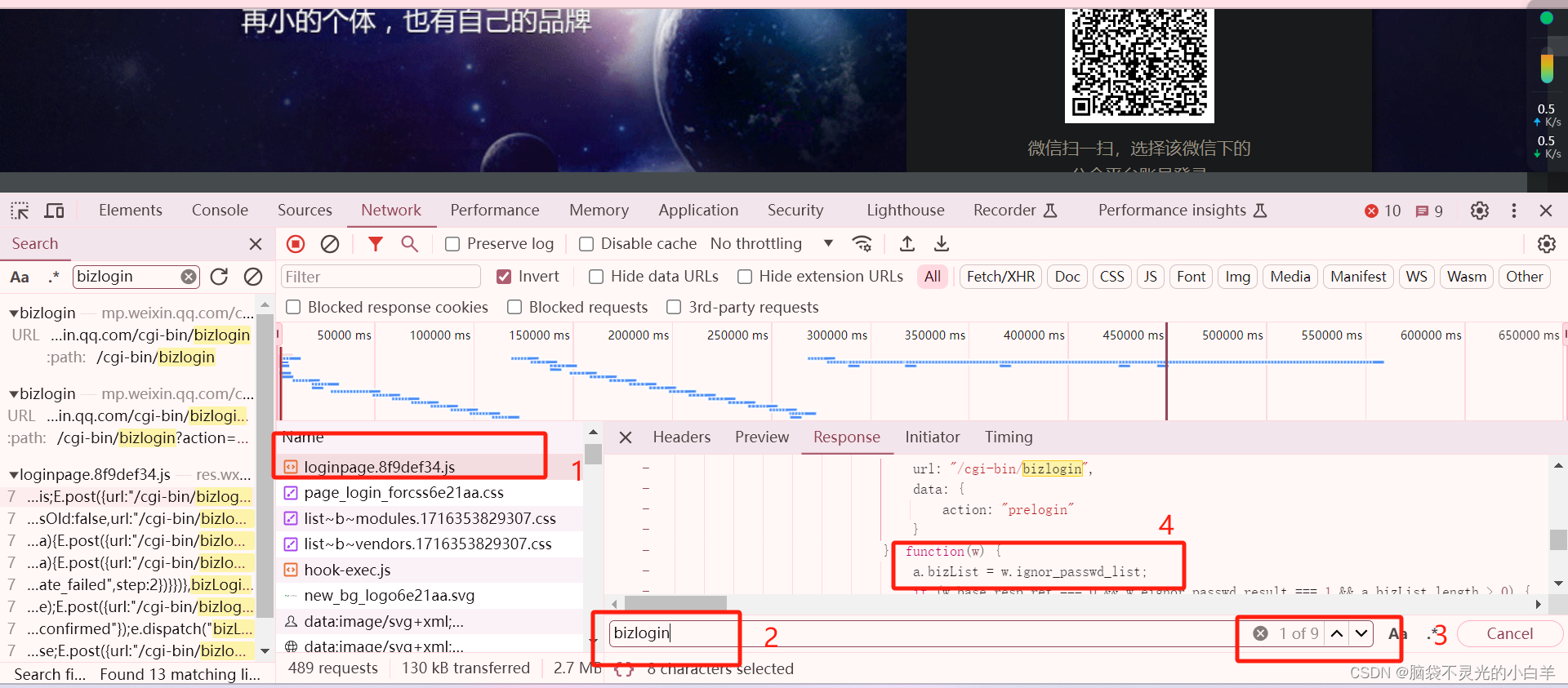
这里查找出9个相关的内容 只有上图这里出现了passwd字样 为了验证 ,可以直接打上断点进行调试 这里试过之后好像不是,直接搜索 pwd 进行断点调试 最终找到函数
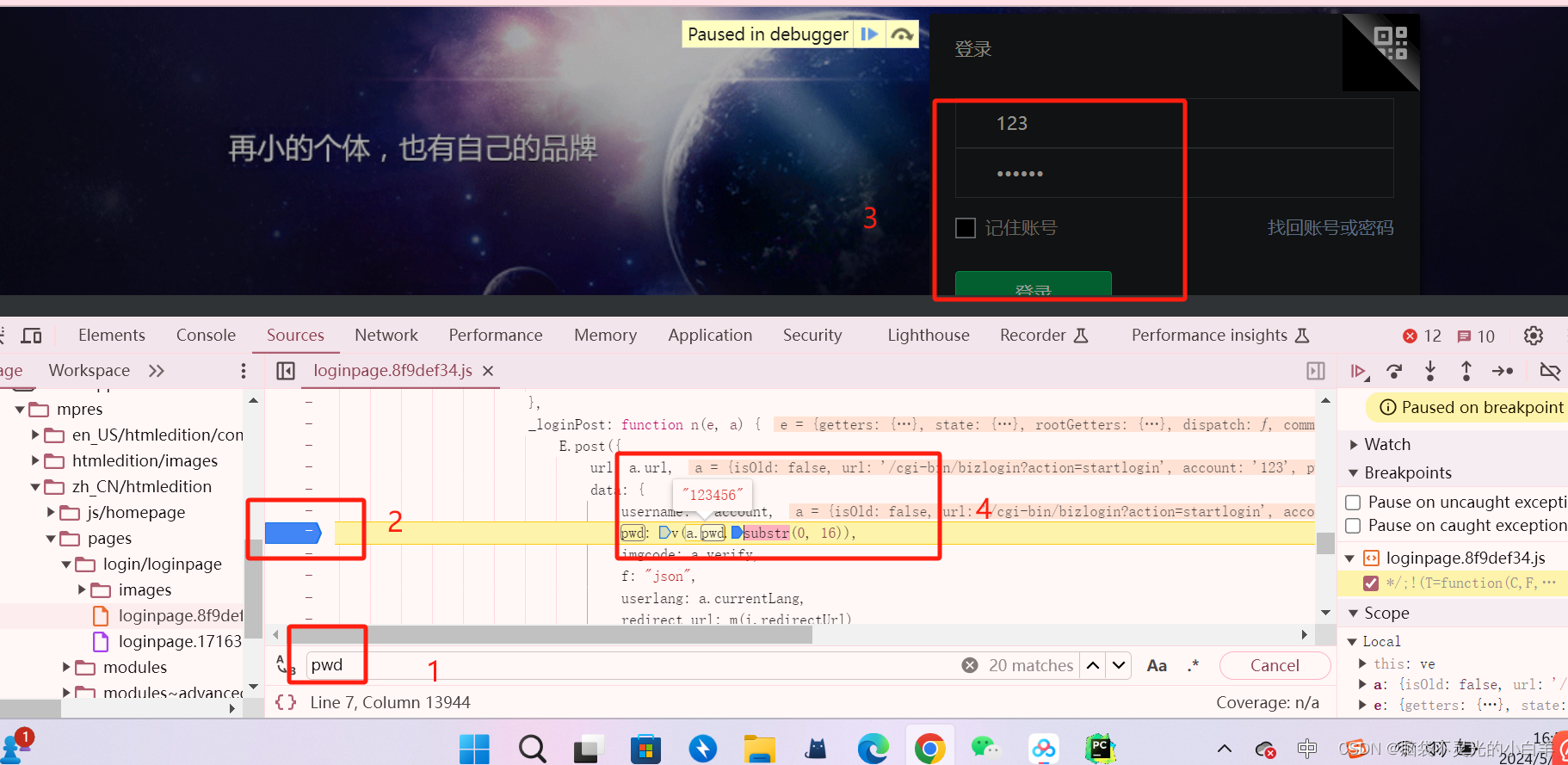
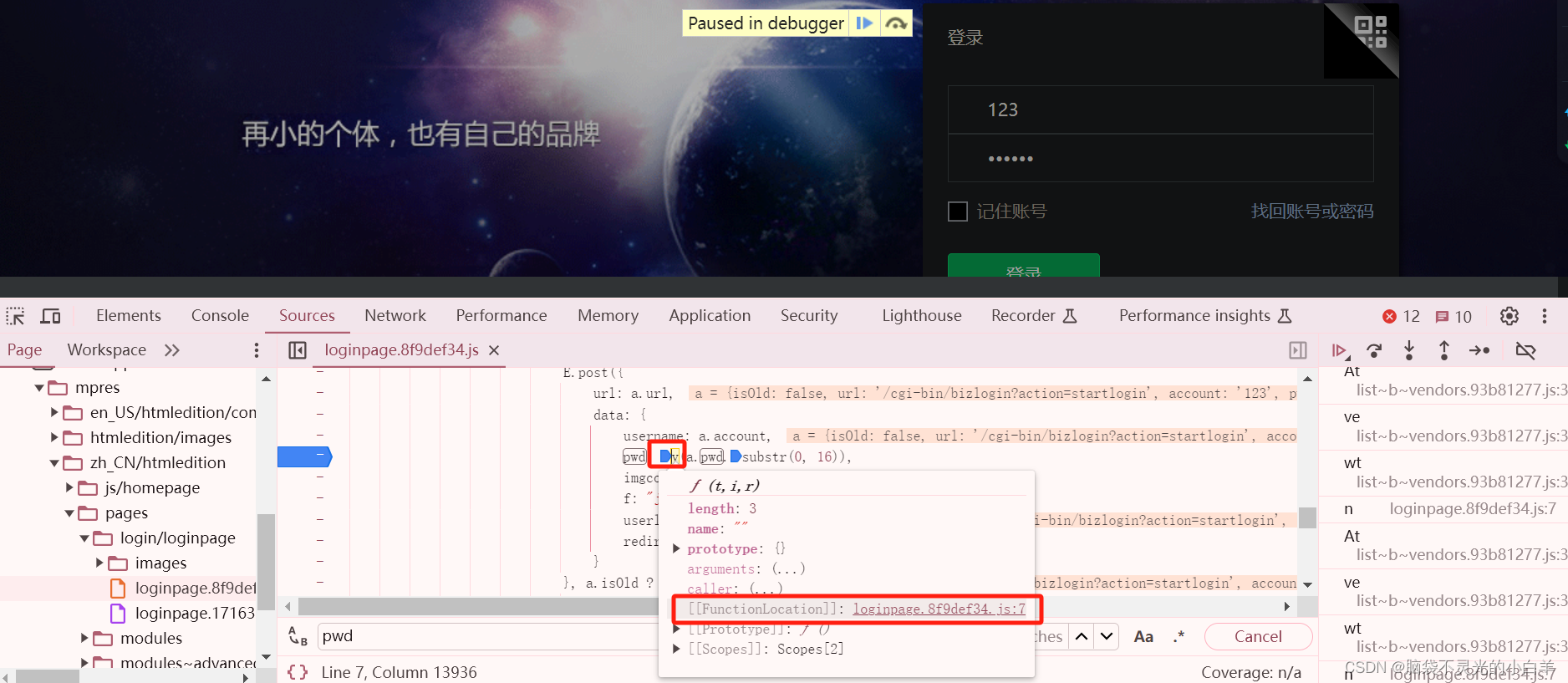
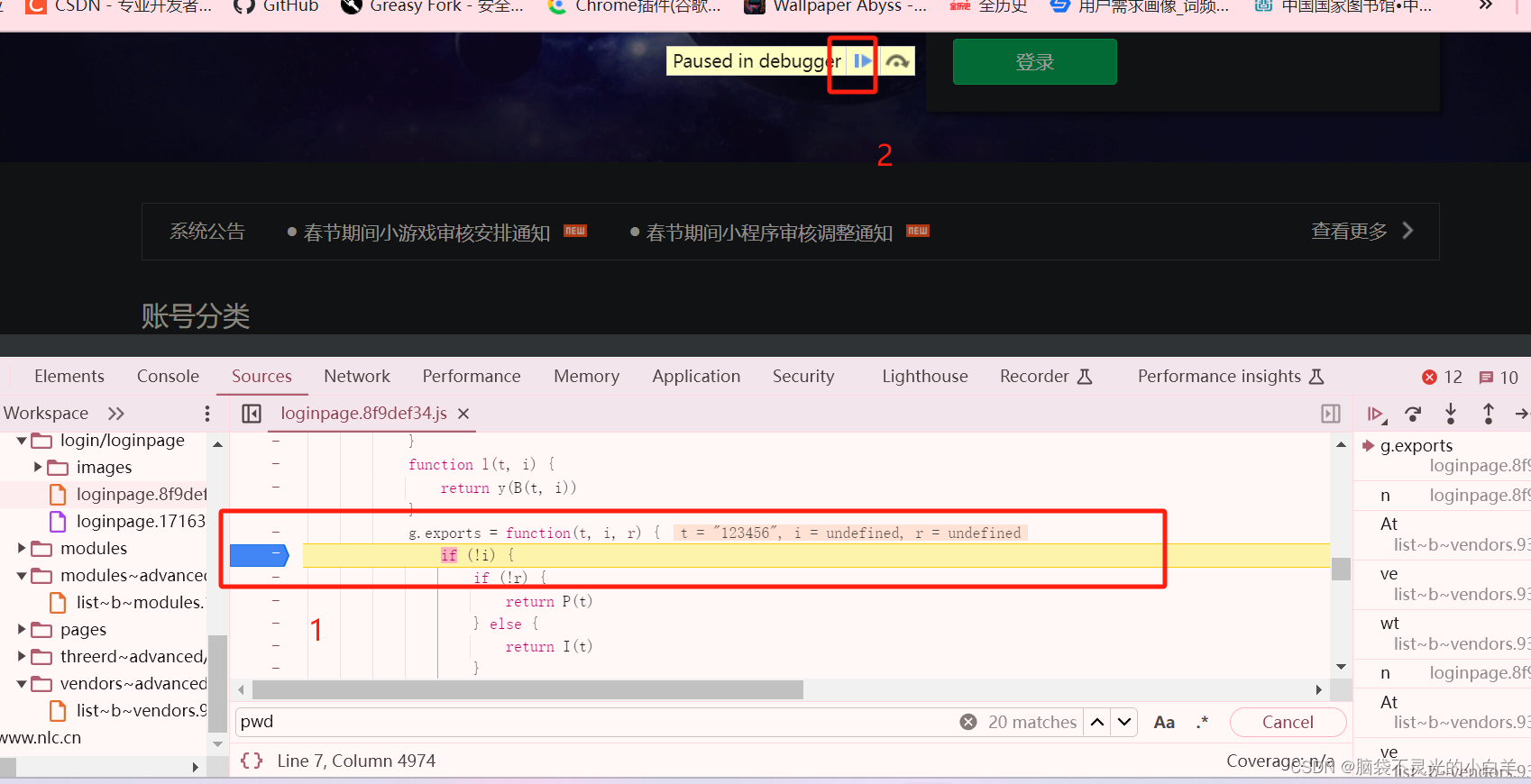
直接把这段js代码拷贝到我们的代码中
python">js = ‘’‘
拷贝的js代码
’‘’import execjsctx = execjs.compile(js)
rs = ctx.call('g.exports', '123456')
print(rs)
实例:某猫小说加密数据生成JS加密逆向分析探索
八、常见的加密使用 base64、md5
python">def test_base64():import base64msg = 'hello'rs = base64.b32encode(msg.encode())print(rs)rs2 = base64.b32encode(rs)print(rs2)def test_md51():import hashlibm = hashlib.md5()m.update('hello'.encode())pwd = m.hexdigest()print(pwd)def test_md52():import hashlibpwd = hashlib.new('md5',b'hello').hexdigest()print(pwd)if __name__ == '__main__':test_base64()# test_md52()
DES/AES
RSA
pythonNode_311">九、python使用Node
下载Node
安装node
创建 js 文件
python">function add(a,b){return a+b
}
tmp_a = parseInt(process.argv[2])
tmp_b = parseInt(process.argv[3])
console.log(add(tmp_a,tmp_b))
node 执行 js
python">def test_node1():import osa = 1b = 2cmd_line = (f'node js02.js {a} {b}')with os.popen(cmd_line) as nodejs:rs = nodejs.read().replace('\n', '')print(rs)
def test_node2():import subprocessa = 1b = 2cmd_line = (f'node js02.js {a} {b}')p = subprocess.Popen(cmd_line.split(),stdout=subprocess.PIPE)rs = p.stdout.read().decode().replace('\n','')print(rs)if __name__ == '__main__':test_node1()test_node2()
十、IP代理池
日志模块
日志模块用于记录程序运行过程中的重要信息,这些信息可以帮助开发者调试程序,监控程序的运行状态,追踪错误和异常等。使用日志的好处包括:
- 记录程序的运行情况:方便查看请求是否成功、代理是否有效等。
- 错误追踪:当程序出错时,能够快速定位问题。
- 性能监控:可以记录每次请求的响应时间,帮助优化爬虫性能。
python">import loggingdef setup_logging(log_file='./proxy_sys/my.log'):logging.basicConfig(filename=log_file,level=logging.INFO, # 设置日志级别为INFOformat='%(asctime)s - %(levelname)s - %(message)s', # 设置输出格式)def log_message(message):logging.info(message)# 使用示例
if __name__ == "__main__":setup_logging()log_message("程序启动成功")log_message("正在获取代理IP")
请求模块
请求模块负责实际的网络请求,它会使用代理池中的代理IP进行请求,并处理响应结果。一个好的请求模块应该:
- 自动选择代理IP:从代理池中随机选择一个可用的代理。
- 处理异常:在请求失败时能够妥善处理,比如重试或切换代理。
- 记录请求日志:在请求过程中记录相关信息,包括请求状态和代理的使用情况。
以下是一个简单的请求模块示例,利用前面定义的日志模块进行记录:
python">import requests
import random
import loggingfrom setup_logging import setup_loggingclass ProxyPool:def __init__(self):self.proxies = ['http://username:password@proxy1.com:port','http://username:password@proxy2.com:port','http://username:password@proxy3.com:port',]def get_random_proxy(self):return random.choice(self.proxies)class RequestModule:def __init__(self, proxy_pool):self.proxy_pool = proxy_pooldef make_request(self, url):proxy = self.proxy_pool.get_random_proxy()logging.info(f"使用代理: {proxy} 进行请求")try:response = requests.get(url, proxies={"http": proxy, "https": proxy}, timeout=5)response.raise_for_status() # 如果响应状态码不是200,抛出异常logging.info(f"成功请求: {url}, 状态码: {response.status_code}")return response.textexcept requests.exceptions.RequestException as e:logging.error(f"请求失败: {e}")return None# 主程序
if __name__ == "__main__":setup_logging()proxy_pool = ProxyPool()request_module = RequestModule(proxy_pool)url = "https://httpbin.org/ip" # 测试获取IP的地址response = request_module.make_request(url)if response:print(response) # 打印响应内容

数据库模块
python">import sqlite3class Database:def __init__(self, db_file='data.db'):"""初始化数据库连接和创建表"""self.connection = sqlite3.connect(db_file)self.cursor = self.connection.cursor()self.create_table()def create_table(self):"""创建存储数据的表"""self.cursor.execute('''CREATE TABLE IF NOT EXISTS scraped_data (id INTEGER PRIMARY KEY AUTOINCREMENT,url TEXT NOT NULL,content TEXT NOT NULL)''')self.connection.commit()def insert_data(self, url, content):"""插入数据"""self.cursor.execute('INSERT INTO scraped_data (url, content) VALUES (?, ?)', (url, content))self.connection.commit()def fetch_all_data(self):"""查询所有数据"""self.cursor.execute('SELECT * FROM scraped_data')return self.cursor.fetchall()def close(self):"""关闭数据库连接"""self.connection.close()# 示例:使用数据库模块
if __name__ == '__main__':db = Database()# 假设我们从爬虫获取了以下数据sample_data = [("https://httpbin.org/ip", "178.128.123.45"),("https://httpbin.org/user-agent", "Mozilla/5.0"),]# 插入数据for url, content in sample_data:db.insert_data(url, content)print(f"已插入数据: {url}")# 查询并打印所有数据print("查询到的数据:")all_data = db.fetch_all_data()for row in all_data:print(row)db.close()
代理IP验证
代理IP验证的目的
- 确保有效性:过滤掉无法连接或响应时间过长的IP,以确保可用代理的质量。
- 提高请求成功率:使用经过验证的代理IP进行请求,提高爬虫的效率和稳定性。
- 避免封禁:使用有效的IP降低被目标网站封禁的风险。
验证的方法
1、简单GET请求:通过向一个稳定且不限制请求频率的URL(如 http://httpbin.org/ip)发起请求来验证代理IP是否可用。
2、响应时间检测:同时,可以记录请求的响应时间,以评估代理的性能。
3、状态码检查:检查返回的HTTP状态码,以判断请求是否成功(状态码200表示成功)。
4、特定内容验证:有些情况下,可以验证返回内容是否符合预期(如获取的IP是否与代理IP一致)。
python">import requests
import timeclass ProxyPool:def __init__(self):# 模拟代理IP列表self.proxies = ['http://username:password@proxy1.com:port','http://username:password@proxy2.com:port','http://username:password@proxy3.com:port',# 更多代理IP]def validate_proxy(self, proxy):"""验证代理IP的有效性"""url = 'http://httpbin.org/ip' # 验证代理的URLtry:start_time = time.time() # 记录请求开始时间response = requests.get(url, proxies={"http": proxy, "https": proxy}, timeout=5)if response.status_code == 200:# 检查返回的IPreturn response.json()['origin'] # 返回获得的IPelse:print(f"代理{proxy}返回状态码: {response.status_code}")return None # IP无效except requests.exceptions.RequestException as e:print(f"代理{proxy}验证失败: {e}")return Nonefinally:elapsed_time = time.time() - start_timeprint(f"请求耗时: 0.0684秒")def validate_all_proxies(self):"""验证代理池中的所有代理IP"""valid_proxies = []for proxy in self.proxies:print(f"正在验证代理: {proxy}")ip = self.validate_proxy(proxy)if ip:print(f"代理{proxy}有效, 获取的IP: {ip}")valid_proxies.append(proxy)else:print(f"代理{proxy}无效")return valid_proxies# 使用实例
if __name__ == '__main__':proxy_pool = ProxyPool()valid_proxies = proxy_pool.validate_all_proxies()print("有效的代理IP列表:", valid_proxies)
下载代理IP
下载代理IP的思路
1、选择代理IP源:选择一些提供免费代理IP的网站,这些网站定期更新其代理IP列表。
2、发送请求:使用爬虫发送HTTP GET请求,获取代理IP页面的HTML内容。
3、解析HTML:提取所需的代理IP信息,包括IP地址、端口、匿名类型等。
4、去重与有效性验证:将提取的IP地址进行去重和有效性验证,确保代理IP池中的IP是可用的。可以在下载时进行简单的有效性检查。
5、存储:将可用的代理IP存储到数据库或内存中,以供后续使用。
python">pip install requests beautifulsoup4
python">import requests
from bs4 import BeautifulSoupclass ProxyDownloader:def __init__(self, url):self.url = urldef download_proxies(self):"""从指定URL下载代理IP"""try:response = requests.get(self.url, timeout=5)response.raise_for_status() # 检查响应状态return self.parse_proxies(response.text)except requests.exceptions.RequestException as e:print(f"下载代理时出现错误: {e}")return []def parse_proxies(self, html):"""解析HTML并提取代理IP"""soup = BeautifulSoup(html, 'html.parser')proxies = set() # 使用集合去重# 根据网站的HTML结构提取IP和端口for row in soup.find_all('tr')[1:]: # 跳过表头columns = row.find_all('td')if len(columns) >= 2: # 确保有足够的列ip = columns[0].text.strip() # 第一列是IP地址port = columns[1].text.strip() # 第二列是端口proxies.add(f"{ip}:{port}") # 添加到集合return list(proxies)# 使用示例
if __name__ == '__main__':url = 'http://www.ip3366.net/free/?stype=3' # 指定代理源网站downloader = ProxyDownloader(url)proxies = downloader.download_proxies()print("下载到的代理IP:")for proxy in proxies:print(proxy)
IP代理池的调度器
调度器的主要功能
- 获取代理IP:从代理池中获取当前可用的代理IP。
- 负载均衡:合理分配请求到不同的代理IP,以避免某个代理过载。
- 监控代理状态:监测代理的使用情况(成功率、响应时间等),根据反馈动态调整代理的有效性。
- 代理更新:在需要时更新代理池,移除失效的代理IP,并添加新的可用IP。
调度器的基本结构
一个简单的IP代理池调度器通常包括以下几个部分:
- 代理池:存储和管理代理IP的集合。
- 请求管理:处理请求并分发给合适的代理IP。
- 状态监控:记录和分析每个代理的使用情况。
python">import random
import requests
import timeclass ProxyPool:def __init__(self):# 初始化代理IP列表self.proxies = []def add_proxy(self, proxy):"""添加代理IP到池中"""self.proxies.append(proxy)def remove_proxy(self, proxy):"""从池中移除代理IP"""self.proxies.remove(proxy)def get_random_proxy(self):"""获取随机代理IP"""if self.proxies:return random.choice(self.proxies)else:return Noneclass Scheduler:def __init__(self, proxy_pool):self.proxy_pool = proxy_poolself.success_count = {} # 用于记录每个代理的成功请求数self.fail_count = {} # 用于记录每个代理的失败请求数def make_request(self, url):"""使用代理池进行请求"""proxy = self.proxy_pool.get_random_proxy()if not proxy:print("没有可用的代理IP!")return Noneprint(f"使用代理: {proxy}")try:response = requests.get(url, proxies={"http": proxy, "https": proxy}, timeout=5)response.raise_for_status() # 检查响应状态self.success_count[proxy] = self.success_count.get(proxy, 0) + 1return response.textexcept requests.exceptions.RequestException as e:print(f"请求失败: {e}")self.fail_count[proxy] = self.fail_count.get(proxy, 0) + 1# 如果失败次数达到阈值,可以将该代理从代理池移除if self.fail_count[proxy] >= 3:print(f"代理{proxy}失效,移除。")self.proxy_pool.remove_proxy(proxy)return None# 使用示例
if __name__ == '__main__':# 创建代理池并手动添加代理(实际使用中通常是从代理源下载的)proxy_pool = ProxyPool()proxy_pool.add_proxy('http://username:password@proxy1.com:port')proxy_pool.add_proxy('http://username:password@proxy2.com:port')proxy_pool.add_proxy('http://username:password@proxy3.com:port')# 创建调度器scheduler = Scheduler(proxy_pool)# 循环发送请求(可根据需求调整循环次数和请求间隔)for _ in range(5):content = scheduler.make_request('http://httpbin.org/ip')if content:print("请求成功,响应内容:", content)# 短暂休息以避免过快请求time.sleep(2)
API接口
API 接口的主要功能
1、获取可用代理IP:提供一种方式让用户获取当前可用的代理IP。
2、添加代理IP:允许外部程序将新代理IP添加到代理池中。
3、删除代理IP:提供接口以便外部程序删除无效或不需要的代理IP。
4、查询代理IP状态:查询特定代理IP的使用情况,如是否有效、请求成功率等。
常见的RESTful API设计(使用HTTP动词)如下:
- GET /proxies:获取可用代理IP列表
- POST /proxies:添加新代理IP
- DELETE /proxies/{ip}:删除特定的代理IP
- GET /proxies/{ip}:查询代理IP的状态
python">pip install Flask
python">from flask import Flask, jsonify, request
import randomapp = Flask(__name__)class ProxyPool:def __init__(self):self.proxies = {} # 用字典存储代理和状态def add_proxy(self, proxy):self.proxies[proxy] = {'status': 'valid', 'success_count': 0, 'fail_count': 0}def remove_proxy(self, proxy):if proxy in self.proxies:del self.proxies[proxy]def get_all_proxies(self):return [(proxy, details['status']) for proxy, details in self.proxies.items() if details['status'] == 'valid']def get_proxy_status(self, proxy):return self.proxies.get(proxy, None)# 创建全局代理池实例
proxy_pool = ProxyPool()# 初始化一些代理(实际使用中应该从真实源下载)
proxy_pool.add_proxy('http://username:password@proxy1.com:port')
proxy_pool.add_proxy('http://username:password@proxy2.com:port')@app.route('/proxies', methods=['GET'])
def get_proxies():"""获取可用代理IP列表"""proxies = proxy_pool.get_all_proxies()return jsonify(proxies)@app.route('/proxies', methods=['POST'])
def add_proxy():"""添加新代理IP"""data = request.jsonproxy = data.get('proxy')if proxy:proxy_pool.add_proxy(proxy)return jsonify({"message": "Proxy added successfully."}), 201return jsonify({"error": "Proxy not provided."}), 400@app.route('/proxies/<string:proxy>', methods=['DELETE'])
def delete_proxy(proxy):"""删除特定的代理IP"""proxy_pool.remove_proxy(proxy)return jsonify({"message": f"Proxy {proxy} removed successfully."}), 200@app.route('/proxies/<string:proxy>', methods=['GET'])
def proxy_status(proxy):"""查询代理IP的状态"""status = proxy_pool.get_proxy_status(proxy)if status:return jsonify({"proxy": proxy, "status": status['status'], "success_count": status['success_count'], "fail_count": status['fail_count']})return jsonify({"error": "Proxy not found."}), 404if __name__ == '__main__':app.run(debug=True)
将上述代码保存为 proxy_pool_api.py,并在终端中运行。
python">python proxy_pool_api.py
使用API测试工具,如Postman或curl,测试API端点。
获取可用的代理IP列表:
python">curl -X GET http://127.0.0.1:5000/proxies

添加一个新的代理IP:
python">curl -X POST http://127.0.0.1:5000/proxies -H "Content-Type: application/json" -d '{"proxy": "http://username:password@proxy3.com:port"}'
删除一个代理IP:
python">curl -X DELETE http://127.0.0.1:5000/proxies/http://username:password@proxy1.com:port
查询特定代理的状态:
python">curl -X GET http://127.0.0.1:5000/proxies/http://username:password@proxy2.com:port






