目录
- 前言
- 一、ABSTRACT
- 二、INTRODUCTION
- 三、KNOWLEDGE-INTENSIVE REASONING TASKS
- 3-1、SETUP
- 3-2、METHODS
- 3-3、RESULTS AND OBSERVATIONS
- 四、DECISION MAKING TASKS
- 4-1、ALFWorld TASK
- 4-2、WebShop TASK
- 五、RELATED WORK
- 六、CONCLUSION
- 总结
前言
文章提出了ReAct方法,将推理(如链式思维提示)和行动(如行动计划生成)集成到大型语言模型(LLMs)中的研究,这在以前的研究中通常是分开探讨的。该方法通过交错生成推理轨迹和特定任务的行动步骤,使模型能够更有效地进行动态推理,并创建、维护及调整行动计划。此外,通过与外部环境(如维基百科)的互动,模型能够将额外的信息融入推理过程中,从而增强推理与行动之间的协同效果。一、ABSTRACT
详细介绍了ReAct(Reasoning and Acting)的研究,这是一种用于语言模型的新方法,专注于将推理和行动融合在一起。主要目的是在各种语言理解和交互式决策任务中,通过生成交织的推理轨迹和行动计划来增强这两者之间的协同作用。
1、主要内容
- 推理与行动的结合:ReAct通过生成推理痕迹和相应行动的方式,允许模型在行动计划的创建、维护和调整中进行动态推理。同时,模型能与外部环境(如知识库或其他环境)交互,从而整合额外信息到推理过程中。
- 应用范围:ReAct被应用于多种语言和决策制定任务上,显示出其相较于现有最先进方法的有效性,同时也提高了人类对模型决策过程的可解释性和信任度。
2、具体成效:
- HotpotQA和Fever数据集:ReAct通过与简单的Wikipedia API交互,解决了传统链式推理中普遍存在的幻觉和错误传播问题,生成的解决任务轨迹比没有推理轨迹的基线更加易于理解。
- ALFWorld和WebShop任务:ReAct在只有一到两个上下文示例的提示下,表现优于通过大量任务实例训练的模仿学习和强化学习方法,成功率分别提高了34%和10%。
这一研究展示了在复杂语言理解和决策任务中,通过合理地引导大型语言模型(LLM)进行推理和行动,可以显著提高任务执行的准确性和效率 。
二、INTRODUCTION
1、大型语言模型的能力
- 随着大型语言模型(LLM)的发展,它们已经被证明在多步骤推理任务中具有显著的表现。文中提到,适当的提示可以使这些模型执行多步骤的推理过程,从而解决复杂的问题。这种能力的展示启发了研究者将这种模型用于更广泛的语言理解和交互式决策任务。
2、ReAct的独特之处
- ReAct模型尝试将这些推理步骤与具体的行动步骤结合起来,形成一种新的交互式模型。这种方法不仅能够提高任务执行的效率和准确性,还能通过生成的推理和行动轨迹增强人类对模型行为的可解释性和信任。ReAct通过在模型生成的每一步中交错推理和行动,允许模型在实际操作中动态地调整和优化行动计划。
3、研究的动机和目标
- 引言明确了ReAct的研究动机,即通过模拟人类在面对复杂任务时的思考和行为模式,来提高语言模型处理多样化语言和决策任务的能力。这一目标的实现可能会极大地推动自主系统在真实世界应用中的表现和可靠性。

三、KNOWLEDGE-INTENSIVE REASONING TASKS
通过与维基百科的API进行交互,ReAct能够通过检索信息来支持推理,同时也可以使用推理来确定下一步要检索的内容。体现了推理和行为的协同性。
3-1、SETUP
使用两个数据集来测试ReAct方法:
- HotPotQA:这是一个多跳问答基准测试,需要对两个或更多的维基百科段落进行推理。
- FEVER:这是一个事实验证基准测试,每个声明都被标注为SUPPORTS(支持)、REFUTES(反驳)或NOT ENOUGH INFO(信息不足),这些标注基于是否有维基百科的文章证明。
注意:模型仅接收问题或声明作为输入,没有访问相应文章的权限,必须依靠内部知识或通过与外部环境互动来检索知识以支持推理。
为了实验交互式信息检索,设计了一个简单的维基百科Web API,包含三种类型的操作:
- search[entity]:如果实体存在,返回对应维基百科页面的前5个句子;如果不存在,提供维基百科搜索中前5个类似实体的建议。
- lookup[string]:返回包含字符串的页面中的下一句话。
- finish[answer]:以答案结束当前任务。
3-2、METHODS
ReAct Prompting: 研究人员随机选择了HotPotQA和Fever训练集中的几个案例,并手工编写了符合ReAct格式的任务解决轨迹作为few-shot的案例。流程包含多个思考-行动-观察。
ReAct构成:每个ReAct包含多个思考-行动-观察步骤。这些步骤包括一系列过程,例如:
- 分解问题
- 根据观察提取信息(如从维基百科得到的信息来进行提取)
- 进行常识性或算术推理。
- 指导搜索重构并根据收集的信息综合最终答案。
Baseline构建:
- 标准Prompt:完全移除了React流程中的思考、动作和观察。
- CoT(Chain of Thought):移除动作和观察。其中CoT-SC(多CoT投票)通过多次投票机制提高推理的一致性和准确性。
- 仅动作提示:去除了思考过程,只保留动作和观察,用以检验这些组成部分对推理结果的直接影响。
在实验部分,作者观察到ReAct在构建事实依据方面表现出优势,而CoT在逻辑推理上更准确但容易受到幻觉影响。因此,作者提出将ReAct和CoT-SC结合使用的策略,当ReAct在限定步骤未能给出答案时采用CoT-SC。
3-3、RESULTS AND OBSERVATIONS
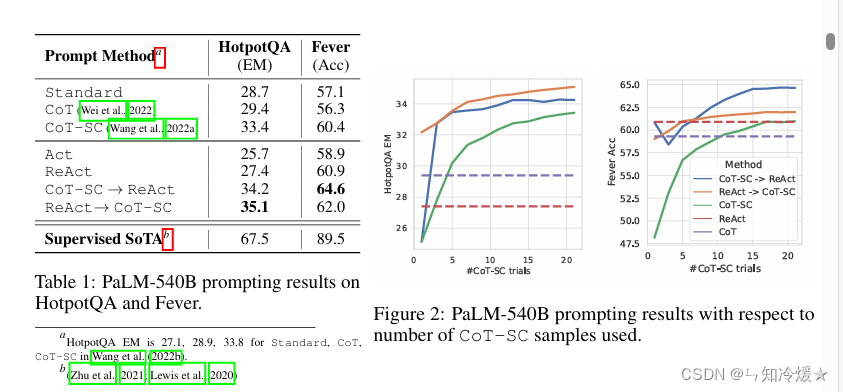
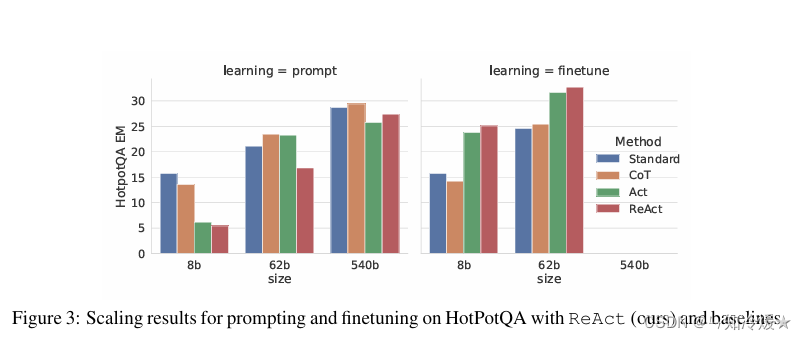
概要: 该章节对不同Prompt Method的性能进行了比较,使用的基础模型是PaLM-540B。这一部分主要展示了ReAct在处理HotpotQA和Fever任务时的优势。
以下为该章节的核心内容:
- ReAct与Act的比较:ReAct在两个任务上持续优于Act,显示出推理在指导行动尤其是在合成最终答案时的重要性。
- ReAct与CoT的比较:ReAct在Fever任务上表现优于CoT,但在HotpotQA任务上略逊一筹。这可能与任务的具体要求有关,例如Fever中支持/反驳的声明可能只有细微差别,这就需要精确和最新的知识来执行行动。

一些关键的观察结果:
- 幻觉是Cot的一个严重的问题,相比之下,由于ReAct采用了外部知识库,其解决问题的轨迹更加值得信赖
- 虽然交叉进行推理、行动和观察提高了ReAct的可信度,但是也限制了它制定推理步骤的灵活性,导致推理错误率高于Cot。
- 对于ReAct来说,通过搜索,成功地检索信息知识是至关重要的。
ReAct+CoT-SC:这两种方法结合的范式在两个数据集都得到了更好的效果,这说明模型内部知识和外部知识的合理结合对于模型的推理具有重要的作用。
微调:微调后,在数据集HotpotQA上,ReACT成为四种方法中最好的方法。微调后的Standar和CoT方法要明显弱于Act和ReAct,因为前者是教模型记忆,而后者是教模型如何行动以从维基百科获取信息。
四、DECISION MAKING TASKS
概要: 在两个交互式决策任务上测试ReAct。
4-1、ALFWorld TASK
ALFWorld: ALFWorld是一个基于文本的合成游戏,设计的目的是为了与ALFRED基准测试对应,后者是一个评估智能体在执行日常任务指令中的理解和操作能力的实体环境基准测试。ALFWorld的核心目的是通过一个文本接口来模拟智能体在虚拟家庭环境中的导航和互动,以此来培养和评估智能体的行动和决策能力。

1、ALFWorld的任务和挑战
在ALFWorld中,智能体面临的任务包括在虚拟环境中完成具体的目标,例如“在书桌灯下检查纸张”。这些任务要求智能体能够理解环境的复杂性,识别和操作对象,以及进行有效的问题解决。这些挑战包括:
- 多位置导航:一个任务实例可能包含超过50个不同的位置,智能体需要在这些位置中进行有效的导航。
- 子目标跟踪:智能体需要规划并跟踪完成任务所需的一系列子目标。
- 系统化探索:例如系统地检查每一个书桌来找到桌灯,这需要智能体能够记住已经检查过哪些位置,并决定下一步最有效的行动策略。
2、ReAct在ALFWorld的应用
在ALFWorld的应用中,ReAct通过生成思考过程来支持智能体的决策。这些思考过程帮助智能体分解任务目标,追踪和确认子目标的完成,并决定接下来的行动步骤。例如,智能体可能需要在文本环境中使用命令“去咖啡桌,拿纸,使用台灯”来完成任务。ReAct模型通过生成这些指令前的思考过程,帮助智能体理解其当前状态和后续需要采取的步骤。
以下为 ReAct在ALFWorld的轨迹:

4-2、WebShop TASK
WebShop :执行在线购物任务! 这是一个最近提出的在线购物网站环境,包含118万件真实产品和1.2万条真实指令。WebShop包含各种各样结构化和非结构化的文本,要求Agent根据用户指令购买产品。例如:“我想要一瓶3盎司的明亮柑橘味除臭剂,适合敏感皮肤,价格低于50美元”, 通过与网络交互,即搜索关键词,如“除臭剂”、“敏感肌”等。我们用搜索、选择产品、选择选项和购买的动作来制定Act提示,ReAct提示额外的推理来确定要探索什么,什么时候购买,以及哪些产品选项与指令相关。 详见表6。

五、RELATED WORK
1. 推理用的语言模型
- 链式思考(Chain of Thought,CoT):这是使用LLM进行推理的最著名的工作之一。它显示了LLM形成问题解决思路的能力。后续的研究包括用于解决复杂任务的从简到繁提示(least-to-most prompting),零样本链式思考(zero-shot-CoT),以及自洽推理(reasoning with self-consistency)。
- 选择推理(Selection-Inference)和星型推理(STaR):这些研究将推理过程分成选择和推理两个步骤,以增强推理过程。
2. 决策制定用的语言模型
- WebGPT和BlenderBot等聊天机器人:这些模型在互动环境中作为决策模型使用,但不如ReAct显式地模拟思考和推理过程,而是依赖人类反馈进行强化学习。
- SayCan和内部独白(Inner Monologue):这些工作将LLM应用于机器人的动作规划和决策制定,其中内部独白是第一个展示这种封闭环系统的工作,ReAct在此基础上进一步发展,但ReAct的推理轨迹更灵活和稀疏。
尽管存在多种推理和决策模型,ReAct的创新之处在于它不仅仅进行孤立的固定推理,而是将模型动作和相应的观察结果整合到一个连贯的输入流中,从而使模型能够更准确地推理并处理超出纯推理的任务,例如交互式决策制定 。
六、CONCLUSION
ReAct的性能优势:通过在多种任务上的应用,ReAct显示出了在处理复杂任务时的高效性,尤其是在有大量行动的情况下,其表现优于传统的行动生成模型。
学习的探索:虽然ReAct在基于文本的HotpotQA等任务上表现出良好的初步结果,但为了进一步提升性能,需要更多高质量的人类标注数据进行微调。
推理+动作,一个强大Agent的雏形。
参考文章:
Datawhale教程.
REACT原文
LLM Powered Autonomous Agents
Datawhale-Github仓库
MetaGPT
ChatDev-Github
crewAI-Github
autogen-Github
总结
不想当牛马打工了,想出去玩。🎇