一、K-means算法概述
K-means算法是一种非常经典的聚类算法,其主要目的是将数据点划分为K个集群,以使得每个数据点与其所属集群的中心点(质心)的平方距离之和最小。这种算法在数据挖掘、图像处理、模式识别等领域有着广泛的应用。
二、K-means算法的基本原理
K-means算法的基本原理相对简单直观。算法接受两个输入参数:一是数据集,二是用户指定的集群数量K。算法的输出是K个集群,每个集群都有其中心点以及属于该集群的数据点。
K-means算法的执行过程如下:
- 初始化:随机选择K个点作为初始集群中心(质心)。
- 分配数据点到最近的集群:对于数据集中的每个点,计算其与各个质心的距离,并将其分配到距离最近的质心所对应的集群中。
- 重新计算质心:对于每个集群,计算其内所有数据点的平均值,并将该平均值设为新的质心。
- 迭代优化:重复步骤2和3,直到满足某个终止条件(如质心的变化小于某个阈值,或者达到最大迭代次数)。
图解说明:
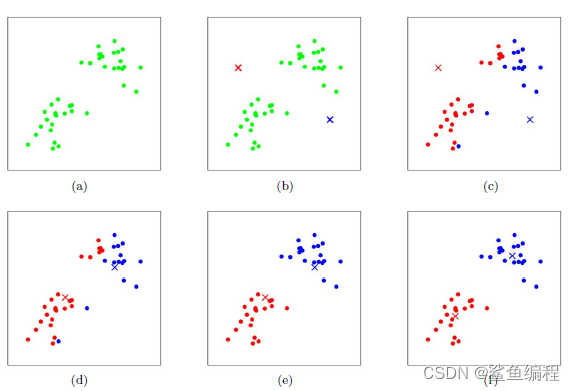
图a表示初始的数据集,在图b中随机找到两个类别质心,接着执行上述的步骤二,得到图c的两个集群,但此时明显不符合我们的要求,因此需要进行步骤三,得到新的类别质心(图d),重复的进行多次迭代(如图e和f),直到达到不错的结果。
三、K-means算法的数学表达
K-means 算法是一种迭代求解的聚类分析算法,其目标是将 n n n 个观测值划分为 k k k( k ≤ n k \leq n k≤n)个聚类,以使得每个观测值属于离它最近的均值(聚类中心或聚类质心)对应的聚类,以作为聚类的标准。
数学公式
-
数据表示
设数据集 D = { x 1 , x 2 , … , x n } D = \{x_1, x_2, \ldots, x_n\} D={x1,x2,…,xn},其中每个数据点 x i x_i xi 是一个 d d d 维向量。
-
聚类中心
假设我们要将数据集聚成 k k k 类,那么就会有 k k k 个聚类中心,记作 { μ 1 , μ 2 , … , μ k } \{\mu_1, \mu_2, \ldots, \mu_k\} {μ1,μ2,…,μk}。
-
目标函数
K-means 算法的目标是最小化每个数据点与其所属聚类的聚类中心之间的距离之和。这个距离通常使用欧几里得距离来衡量。目标函数可以表示为:
J = ∑ j = 1 k ∑ i = 1 n w i j ∥ x i − μ j ∥ 2 J = \sum_{j=1}^{k} \sum_{i=1}^{n} w_{ij} \| x_i - \mu_j \|^2 J=j=1∑ki=1∑nwij∥xi−μj∥2
其中, w i j w_{ij} wij 是一个指示变量,当数据点 x i x_i xi 属于聚类 j j j 时, w i j = 1 w_{ij} = 1 wij=1;否则 w i j = 0 w_{ij} = 0 wij=0。 ∥ x i − μ j ∥ 2 \| x_i - \mu_j \|^2 ∥xi−μj∥2 表示数据点 x i x_i xi 与聚类中心 μ j \mu_j μj 之间的欧几里得距离的平方。
-
迭代更新
分配步骤:固定聚类中心 { μ j } \{\mu_j\} {μj},为每个数据点 x i x_i xi 分配最近的聚类中心,即更新 w i j w_{ij} wij:
w i j = { 1 , if j = arg min l ∥ x i − μ l ∥ 2 0 , otherwise w_{ij} = \begin{cases} 1, & \text{if } j = \arg\min_{l} \| x_i - \mu_l \|^2 \\ 0, & \text{otherwise} \end{cases} wij={1,0,if j=argminl∥xi−μl∥2otherwise
更新步骤:固定 w i j w_{ij} wij,更新聚类中心 { μ j } \{\mu_j\} {μj},使得目标函数 J J J 最小化。聚类中心更新为所属聚类的所有数据点的均值:
μ j = ∑ i = 1 n w i j x i ∑ i = 1 n w i j \mu_j = \frac{\sum_{i=1}^{n} w_{ij} x_i}{\sum_{i=1}^{n} w_{ij}} μj=∑i=1nwij∑i=1nwijxi
-
算法终止条件
迭代进行分配步骤和更新步骤,直到聚类中心不再发生显著变化,或者达到预设的最大迭代次数。
四、K-means算法的C++实现
首先是头文件:
#include <iostream>
#include <vector>
#include <cmath>
#include <limits>
#include <algorithm>
第一步: 数据结构定义
我们定义了一个Point结构体来表示二维空间中的点。
struct Point {double x, y;Point(double x = 0, double y = 0) : x(x), y(y) {}
};
这个结构体很简单,只有两个成员变量x和y,分别表示点在二维空间中的横坐标和纵坐标。还有一个构造函数,用于创建点对象时初始化坐标。
第二步: 辅助函数
距离计算函数
double distance(const Point& a, const Point& b) {return std::hypot(a.x - b.x, a.y - b.y);
}
这个函数计算两个点之间的距离,使用了<cmath>库中的std::hypot函数,它接受两个参数(横坐标和纵坐标的差值),并返回这两点之间的欧几里得距离。
质心计算函数
Point centroid(const std::vector<Point>& cluster) {double sum_x = 0, sum_y = 0;for (const auto& point : cluster) {sum_x += point.x;sum_y += point.y;}return Point(sum_x / cluster.size(), sum_y / cluster.size());
}
这个函数计算一个点集的质心。质心是所有点的坐标平均值。函数遍历点集,累加所有点的x坐标和y坐标,然后分别除以点的数量,得到质心的坐标。
第三步: K-means算法主体
K-means算法的主体部分可以进一步拆分为几个小的步骤:初始化、分配点、重新计算质心和检查收敛性。
初始化
在K-means算法中,我们需要首先选择K个初始质心。在这个简单的实现中,我们随机选择数据集中的K个点作为初始质心。
std::vector<Point> centroids(k);
for (int i = 0; i < k; ++i) {centroids[i] = data[rand() % data.size()];
}
分配点
对于数据集中的每个点,我们需要找到最近的质心,并将其分配给该质心对应的集群。
std::vector<std::vector<Point>> clusters(k);
for (const auto& point : data) {double min_distance = std::numeric_limits<double>::max();int cluster_index = 0;for (int i = 0; i < k; ++i) {double dist = distance(point, centroids[i]);if (dist < min_distance) {min_distance = dist;cluster_index = i;}}clusters[cluster_index].push_back(point);
}
重新计算质心
分配完点后,我们需要重新计算每个集群的质心。
std::vector<Point> new_centroids(k);
for (int i = 0; i < k; ++i) {new_centroids[i] = centroid(clusters[i]);
}
检查收敛性
如果新旧质心之间的变化很小(在一个很小的阈值以内),则算法收敛,可以停止迭代。
bool converged = true;
for (int i = 0; i < k; ++i) {if (distance(centroids[i], new_centroids[i]) > 1e-6) {converged = false;break;}
}
如果算法未收敛,则更新质心并继续迭代。
第四步: 主函数和数据准备
在主函数中,我们准备了一个简单的数据集(整体代码见最后),并设置了K值和最大迭代次数。然后调用kmeans函数进行聚类。
这就是K-means算法的一个基本实现。在实际应用中,可能还需要考虑更多的优化和异常情况处理,比如处理空集群、改进初始质心的选择方法、添加对异常值的鲁棒性等。
结果输出:
Cluster 1 centroid: (3.5, 3.9)
(1, 0.6) (8, 5) (1, 4) (4, 6)
Cluster 2 centroid: (5.41667, 9.06667)
(2, 10) (2.5, 8.4) (5, 8) (8, 8) (9, 11) (6, 9)
五、K-means算法的优缺点
优点:
缺点:
- 需要预先指定集群数量K,这在实际应用中可能是一个挑战。
- 对初始质心的选择敏感,不同的初始质心可能导致完全不同的结果。
- 只能发现球形的集群,对于非球形或复杂形状的集群效果不佳。
- 对噪声和异常值敏感,因为它们会影响质心的计算。
六、源代码如下
#include <iostream>
#include <vector>
#include <cmath>
#include <limits>
#include <algorithm> struct Point { double x, y; Point(double x = 0, double y = 0) : x(x), y(y) {}
}; double distance(const Point& a, const Point& b) { return std::hypot(a.x - b.x, a.y - b.y);
} Point centroid(const std::vector<Point>& cluster) { double sum_x = 0, sum_y = 0; for (const auto& point : cluster) { sum_x += point.x; sum_y += point.y; } return Point(sum_x / cluster.size(), sum_y / cluster.size());
} void kmeans(std::vector<Point>& data, int k, int max_iterations) { std::vector<Point> centroids(k); std::vector<std::vector<Point>> clusters(k); // 随机化第一个质点for (int i = 0; i < k; ++i) { centroids[i] = data[rand() % data.size()]; } for (int iter = 0; iter < max_iterations; ++iter) { for (const auto& point : data) { double min_distance = std::numeric_limits<double>::max(); int cluster_index = 0; for (int i = 0; i < k; ++i) { double dist = distance(point, centroids[i]); if (dist < min_distance) { min_distance = dist; cluster_index = i; } } clusters[cluster_index].push_back(point); } // 清除前一个的质点for (auto& cluster : clusters) { cluster.clear(); } // 重新计算质点 for (int i = 0; i < data.size(); ++i) { int cluster_index = 0; double min_distance = std::numeric_limits<double>::max(); for (int j = 0; j < k; ++j) { double dist = distance(data[i], centroids[j]); if (dist < min_distance) { min_distance = dist; cluster_index = j; } } clusters[cluster_index].push_back(data[i]); } std::vector<Point> new_centroids(k); for (int i = 0; i < k; ++i) { new_centroids[i] = centroid(clusters[i]); } bool converged = true; for (int i = 0; i < k; ++i) { if (distance(centroids[i], new_centroids[i]) > 1e-6) { converged = false; break; } } if (converged) { break; } centroids = new_centroids; } // 输出结果 for (int i = 0; i < k; ++i) { std::cout << "Cluster " << i + 1 << " centroid: (" << centroids[i].x << ", " << centroids[i].y << ")" << std::endl; for (const auto& point : clusters[i]) { std::cout << "(" << point.x << ", " << point.y << ") "; } std::cout << std::endl; }
} int main() { srand(time(nullptr)); // 随机数种子,可以使用随机数生成数据集std::vector<Point> data = { // 数据集 {2.0, 10.0}, {2.5, 8.4}, {5.0, 8.0}, {8.0, 8.0}, {1.0, 0.6}, {9.0, 11.0}, {8.0, 5.0}, {1.0, 4.0}, {4.0, 6.0}, {6.0, 9.0} }; int k = 2; // 集群数量 int max_iterations = 5; // 迭代次数kmeans(data, k, max_iterations); return 0;
}