背景:
非局部注意力使用一个简单的相似度矩阵,因此会造成attention miss,为了解决这个问题,提出了fully attentional network,同时进行位置和通道编码。本文主要解决在通道非局部中的位置问题。
attention miss
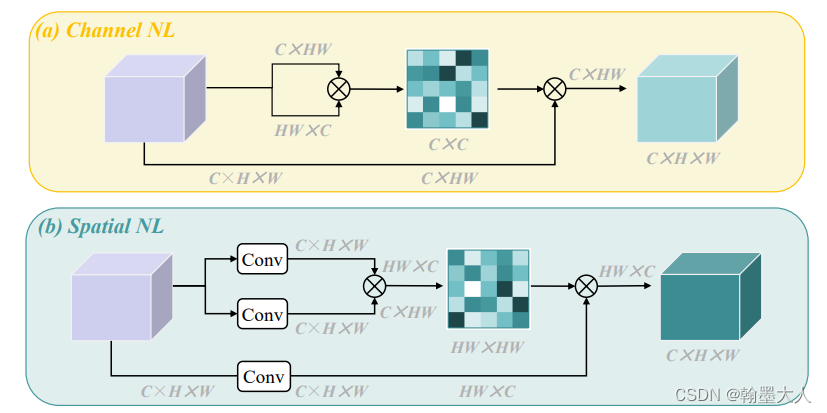
什么是attention miss?对于通道非局部注意力来说,两个维度分别为c x hw和hw x c的输入相乘得到通道注意力map,但是空间的信息融合了,每一个空间位置不能感知到其他位置的特征响应。空间非局部注意力同理。
为什么每一个空间位置不能感知到其他位置的特征响应?在我看来注意力map是二维的,为了进行相乘,feature map需要变成二维的,因此就将h x w转换成了hw,将二维转换成一维了,位置信息就消失了。
插曲
首先空间非局部在小物体上表现较好,通道非局部在大物体上表现较好,一些拿来对比的解决办法,如DANet,将空间和通道注意力并行放置,但是在大物体上表现不好,CBAM,将
空间和通道注意力串行放置,但是在小物体上表现不好。因此简单的堆叠效果不够好。
fully attentional block
在Fin输入之前,首先使用两个卷积层来降低维度,然后输入进FLA(fully attentional block)
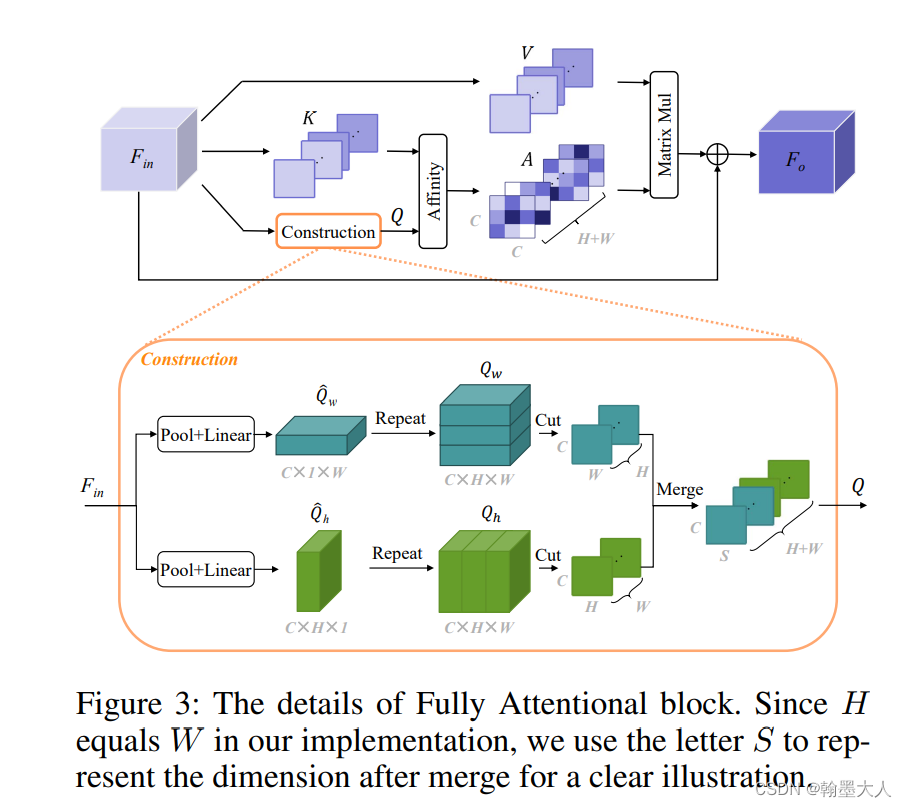
1:首先我们将Fin输入到上图中construction,经过全局平均池化和线性层,在全局平均池化中我们使用[HX1],[1XW]卷积,产生的特征图经过repeat,形成了global feature,接着将Qw沿着H维度进行cut,将Qh沿着w维度进行cut,最后将cut之后的特征图进行融合,即进行空间交互。
2:同时我们将Fin沿着h维度cut生成group of h,沿着w维度cut生成group of w,最后将两个group进行merge生成K,同理生成V。
3:最后的就是非局部注意力操作,Q和K进行softmax,然后A和V进行矩阵相乘,然后将结果分成两个group,再将两个group进行逐像素相加,乘以一个超参数。
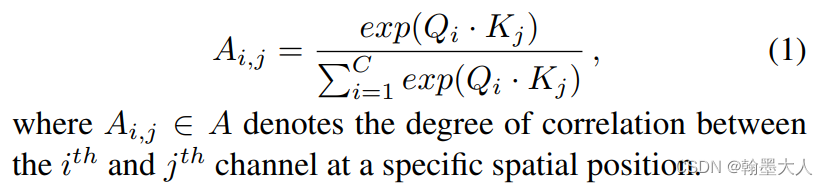
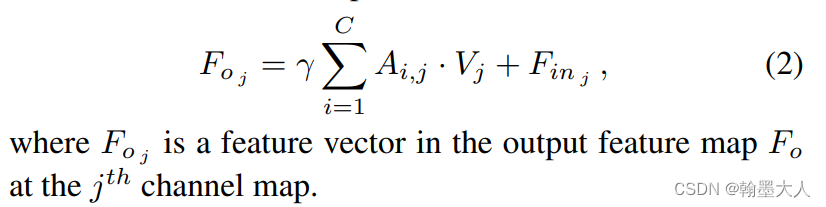
不同于传统的通道非局部,在FLA在不同的位置都有空间联系。
复杂度:

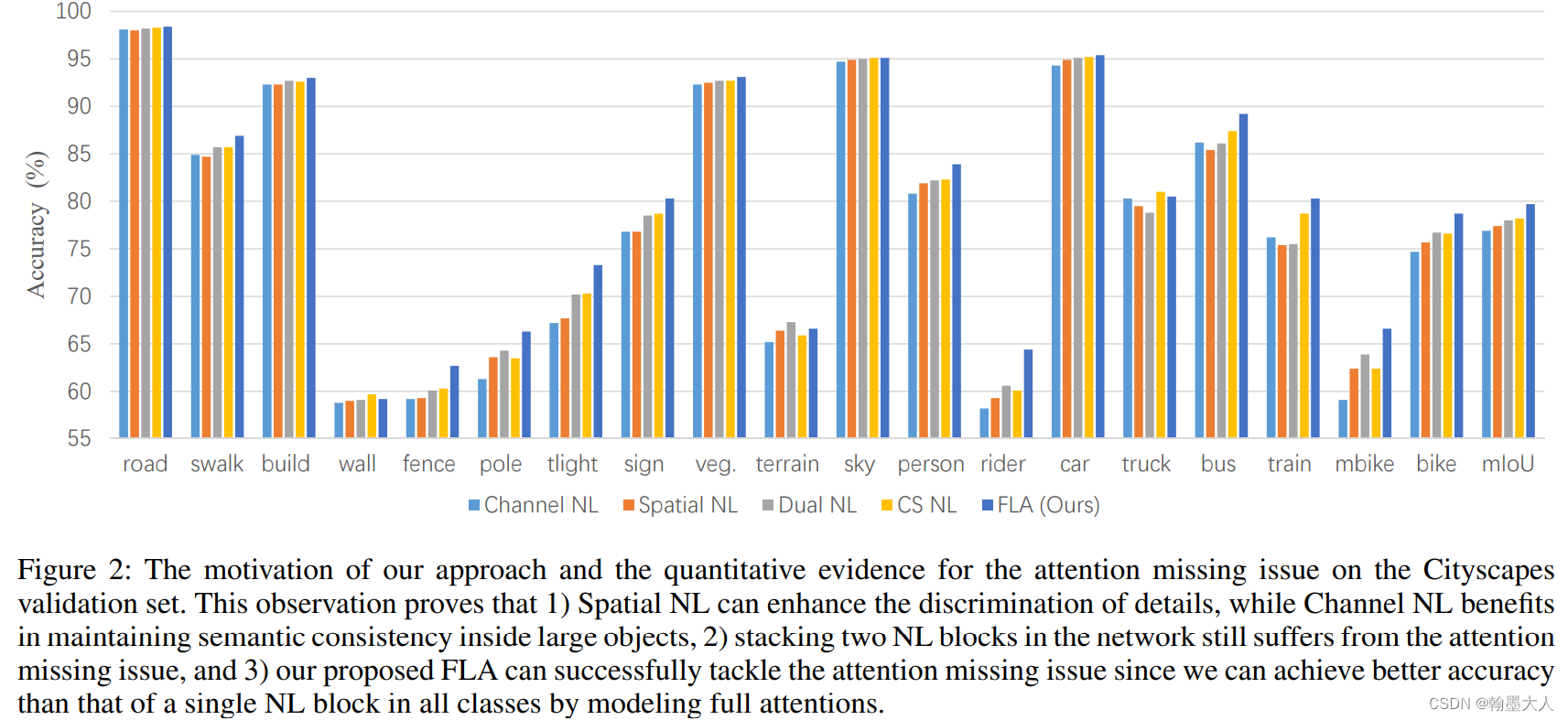
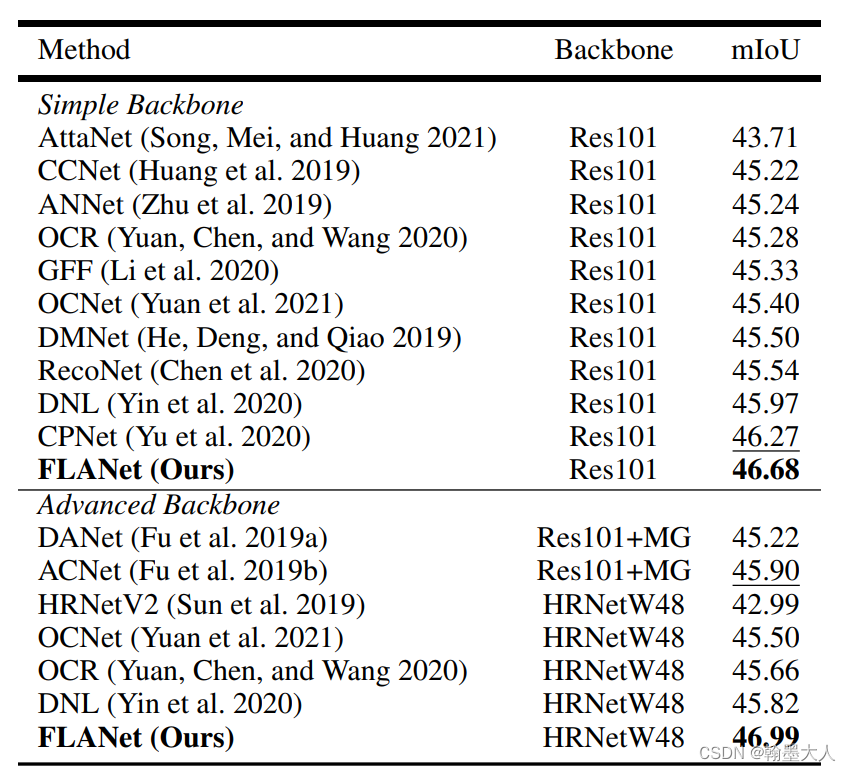
语义分割效果:
下一篇将看一下代码,以及具体的各种操作变换。