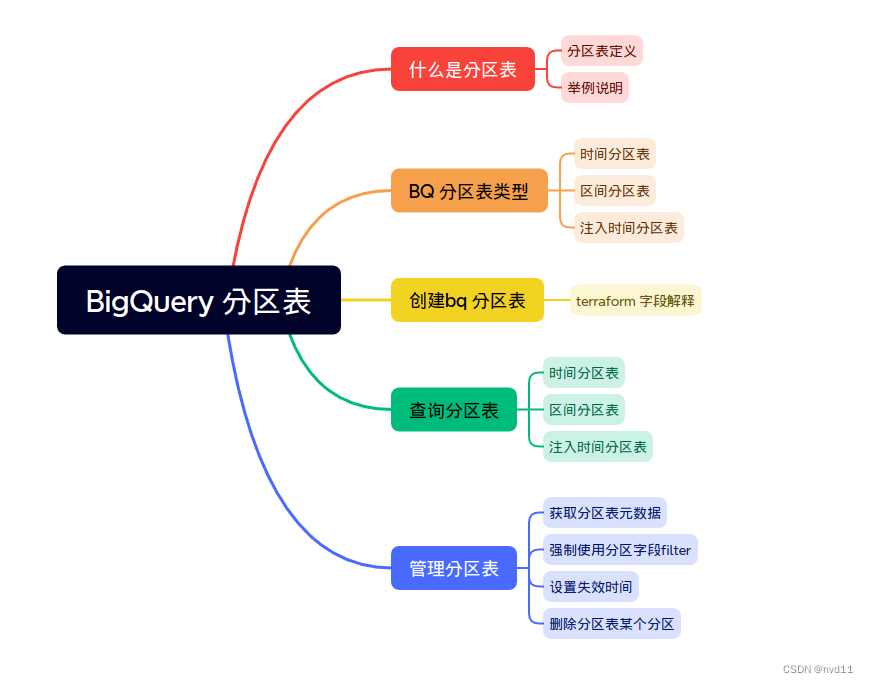
大纲
什么是分区表
我们先看定义:
分区表是一种数据库表设计和管理技术,它将表中的数据划分为逻辑上的多个分区,每个分区包含一组特定的数据。每个分区都根据定义的分区键(通常是一个列或字段)的值进行分类,使得数据可以按照特定的逻辑规则进行划分和组织。
通过使用分区表,可以将大型表分解为更小的、可管理的部分,以提高查询性能、数据维护效率和存储资源的利用率。分区表的实现方式和语法可能因数据库管理系统而异,但基本概念和原则是相似的。
具体给个例子:
我有张table sales_details, 和一些测试数据, 如下:
select * from DS2.sales_detailsOrder_ID|Product |Quantity_Ordered|Price_Each|Order_Date|Purchase_Address |
--------+------------------------+----------------+----------+----------+----------------------------------------+
176565 |updated | 1| 1700.0|2019-04-24|915 Willow St, San Francisco, CA 94016 |
176565 |updated | 1| 1700.0|2019-04-24|915 Willow St, San Francisco, CA 94016 |
176565 |updated | 1| 1700.0|2019-04-24|915 Willow St, San Francisco, CA 94016 |
176565 |updated | 1| 1700.0|2019-04-24|915 Willow St, San Francisco, CA 94016 |
176565 |updated | 1| 1700.0|2019-04-24|915 Willow St, San Francisco, CA 94016 |
176565 |updated | 1| 1700.0|2019-04-24|915 Willow St, San Francisco, CA 94016 |
176609 |Apple Airpods Headphones| 1| 150.0|2019-04-11|267 11th St, Austin, TX 73301 |
176609 |Apple Airpods Headphones| 1| 150.0|2019-04-11|267 11th St, Austin, TX 73301 |
176609 |Apple Airpods Headphones| 1| 150.0|2019-04-11|267 11th St, Austin, TX 73301 |
176609 |Apple Airpods Headphones| 1| 150.0|2019-04-11|267 11th St, Austin, TX 73301 |
176609 |Apple Airpods Headphones| 1| 150.0|2019-04-11|267 11th St, Austin, TX 73301 |
176609 |Apple Airpods Headphones| 1| 150.0|2019-04-11|267 11th St, Austin, TX 73301 |
176617 |Apple Airpods Headphones| 1| 150.0|2019-04-25|319 8th St, Portland, OR 97035 |
176617 |Apple Airpods Headphones| 1| 150.0|2019-04-25|319 8th St, Portland, OR 97035 |
176617 |Apple Airpods Headphones| 1| 150.0|2019-04-25|319 8th St, Portland, OR 97035 |
176617 |Apple Airpods Headphones| 1| 150.0|2019-04-25|319 8th St, Portland, OR 97035 |
176617 |Apple Airpods Headphones| 1| 150.0|2019-04-25|319 8th St, Portland, OR 97035 |
176617 |Apple Airpods Headphones| 1| 150.0|2019-04-25|319 8th St, Portland, OR 97035 |
176591 |Apple Airpods Headphones| 1| 150.0|2019-04-21|600 Maple St, Austin, TX 73301 |
176591 |Apple Airpods Headphones| 1| 150.0|2019-04-21|600 Maple St, Austin, TX 73301 |
176591 |Apple Airpods Headphones| 1| 150.0|2019-04-21|600 Maple St, Austin, TX 73301 |
176591 |Apple Airpods Headphones| 1| 150.0|2019-04-21|600 Maple St, Austin, TX 73301 |
当这个表的数据量增大时, 去查询这个表的性能会变慢。
这时我们定下1个规则, 我们查询这个表时都必须加上1个filter 字段。 这个字段设成是Order_Date (字段类型是DATE)
我们查询时都加上这个filter 查询某1天or 某段时间内的数据, 例如
select * from DS2.sales_details where Order_Date = '2019-04-11'
如果用户场景符合上面的前提, 那么我们就可以为这个表做成分区表了
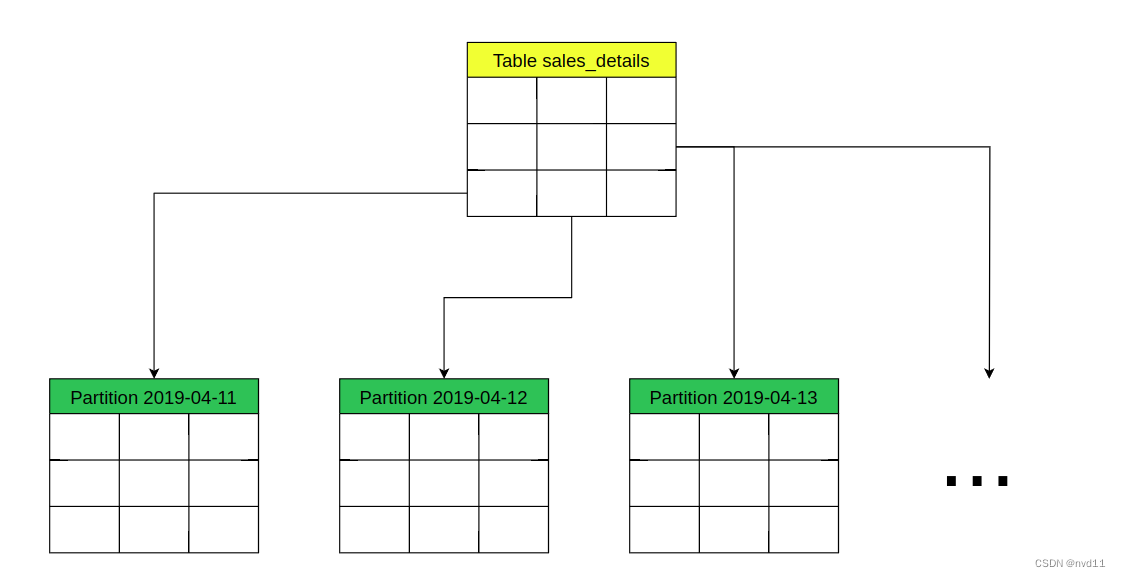
如上图, 我们可以利用Order_Date 做分区, 把整个table 以每一日创建1个分区。
那么当我们执行上面的sql
select * from DS2.sales_details where Order_Date = '2019-04-11'
那么它就会只在 2019-04-11的表分区里面查询, 避免了全表检索, 查询速度就大大加快了。
好了, 上面只是一些基本原理, 下面是一些常见问题。
1. 如果查询条件是1个区间, 例如 Order_Date >= ‘2019-04-11’, 分区表还有效吗?
有效, 这种情况下排除了 2019-04-11 之前的分区, 还是避免了全表检索, 这个查询会查询2019-04-11 之前的所有分区, 所以建议filter 加上下界
例如
select * from DS2.sales_details_p4 where Order_Date BETWEEN '2019-04-24' and '2019-04-29'
这样这个sql只会 在某几个表分区查询, 而Big Query是支持并发在多个表分区里查询数据的。
2. 以每一日做1个分区, 会导致表分区过多?
BigQuery 用时间分区表的话, 还支持用 hour, month , year来分区!
3. 如果查询分区表不加上分区字段filter, 查询效率会更差?
没错, 如果上面的例子, sql里不加上Order_date filter 的话, sql会在所有的分区里查询数据, 效率会比非分区表更差! 所以创建分区表时要考虑清楚表的查询场景!
4. 如果查询sql 一定要加上分区字段filter, 为何不直接加个索引? 一样能大大加快查询速度。
的确, 为filter 字段加上索引更加省事也更常用。 这是1个好问题。
为了回答这个问题, 要列出下面几点
a. BigQuery 不是普通关系数据库, 它不支持索引, BQ 本身是通过分区和分桶, 然后在背后实现并发查询来提高速度的。
下面的point是对于其他数据库的
b. 对于传统关系数据库, 例如Oracle Mysql, 表大小在1GB以下的还是建议索引更高效, 表越大, 分区表优势越大!
c. 如果查询结果集范围相对较小, 使用索引会更合适
d. 查询结果集的范围涉及多个分区, 使用多个分区表更高效
e. 复杂查询下, 即使使用索引, 也会涉及很多子查询, 子查询的数据可能会占用临时表空间甚至内存。 使用分区表只会在某些物理介质里查询, 更高效
f.数据管理和维护:分区表可以更好地管理数据,使数据维护操作更高效。你可以针对特定的分区执行数据导入、删除或重组操作,而无需处理整个表。这对于大型数据集或频繁进行数据维护的情况下尤为重要。
g.存储和成本控制:分区表允许你根据数据的生命周期和访问模式应用不同的存储策略和成本控制措施。例如,你可以选择将较旧的分区存储在低成本的存储介质上,而将最近的分区存储在高性能的存储介质上。这可以帮助降低存储成本,同时保持查询性能。
但是对于BQ, 核心技术是多分区并发查询!
BigQuery 分区表类型
根据本码农分析, BQ 的分区表大概分3种类型
1.时间分区表 (time_partitioning)
这个种分区表必须指定1个时间类型的字段。 也就是这个字段的类型为必须是 DATE 和 Timestamp的一种
其中DATE 类型只包含日期, 没有时分秒信息
而TIMESTAMP包含时分秒甚至毫秒
而且分区的类型要选择下面的4种之一
Hour, Day, Month, Year
本文只会用时间分区表作为详细例子, 其他两种会简单带过
2. 区间分区表 (integer-range_partitioning)
区间分区表必须以1个 Integer类型字段作为分区字段。 (例如 id值)
而且还需要设定1个属性 range, 也就多大的值范围作1个分区
例如, 我有1个张很多学生的考试分数表
可以对分数(前提是整数) 作为分区字段
range 可以set称10
那么这个分数表就大概分成 10 个分区了。
3. 注入时间分区表 (ingestion-time_partitioning)
这种比较特别, 其实也是时间分区表的一种, 但是不必制定分区字段。
这种分区表会用 当前record 被插入到表的时间戳作为分区字段。
一旦这种分区表被创建, 就有1个伪列 _PARTITIONTIME or _PARTITIONDATE
可以获得当前record的首次插入表的时间
同样
也需要制定type
Hour, Day, Month, Year 的一种
创建 BigQuery 分区表
有多种 方法, 包括 bq 命令, sql, google api等
这里只介绍terraform
resource "google_bigquery_table" "sales_details_p" {dataset_id = google_bigquery_dataset.dataset1.dataset_idtable_id = "sales_details_p"project = var.project_iddeletion_protection = falseschema = <<EOF
[{"name": "Order_ID","type": "STRING"},{"name": "Product","type": "STRING"},{"name": "Quantity_Ordered","type": "INTEGER"},{"name": "Price_Each","type": "FLOAT"},{"name": "Order_Date","type": "DATE"},{"name": "Purchase_Address","type": "STRING"}
]
EOFtime_partitioning {type = "DAY" # partitioning by Dayfield = "Order_Date" # Use it as the partition field//expiration_ms = 2592000000 # set the expired days to 30//require_partition_filter = true # must use partition filter}
}
上面的terraform 就定义了1个分区表资源 sales_details_p, 它以Order_Date 作为分区字段
值得注意的是
- 分区字段, 例如上面的Order_date, 类型不能为String, 根据实际选择DATE OR TIMESTAMP
- expiration_ms 表示当前分区表的分区的过期日期(毫秒表示), 可以不设置, 后面会详解
- require_partition_filter 表示是否强制要求对这个分区表的查询加上分区表字段filter, 后面会详解
当表被创建后,可以用bq show 来查看该表的分区信息
[gateman@manjaro-x13 coding]$ bq show DS2.sales_details_p
/home/gateman/devtools/google-cloud-sdk/platform/bq/bq.py:17: DeprecationWarning: 'pipes' is deprecated and slated for removal in Python 3.13import pipes
Table jason-hsbc:DS2.sales_details_pLast modified Schema Total Rows Total Bytes Expiration Time Partitioning Clustered Fields Total Logical Bytes Total Physical Bytes Labels ----------------- ------------------------------ ------------ ------------- ------------ ------------------------- ------------------ --------------------- ---------------------- -------- 23 Dec 04:18:36 |- Order_ID: string 0 0 DAY (field: Order_Date) 0 |- Product: string |- Quantity_Ordered: integer |- Price_Each: float |- Order_Date: date |- Purchase_Address: string [gateman@manjaro-x13 coding]$ 查询 BigQuery 分区表
当分区表sales_details_p 创建好后, 我们把数据从 非分区表 sales_details 插入到 sales_details_p
INSERT INTO DS2.sales_details_p
(Order_ID, Product, Quantity_Ordered, Price_Each, Order_Date, Purchase_Address)
select Order_ID, Product, Quantity_Ordered, Price_Each, PARSE_DATE('%Y-%m-%d', Order_Date) AS Order_Date, Purchase_Address
from DS2.sales_details
查询时间分区表
很简单上面已经举过例子了, 只需要加上分区key的filter
select * from DS2.sales_details_p where Order_Date BETWEEN '2019-04-24' and '2019-04-29'
查询区间分区表
一样, 例如
假设分区表 product 的分区字段是product_id (Interger)
select * from DS2.product where product_id BETWEEN 1000 and 2000
查询注入时间分区表
假设分区表product 是注入时间分区表
则我们需要用伪列来作filter
select * from DS2.product where _PARTITIONTIME BETWEEN TIMESTAMP('2016-01-01') AND TIMESTAMP('2016-01-02')
管理BigQuery 分区表
获取分区表元数据
就是查看当前的分区表共有多少个表分区等信息
我们可以看查询 《Dataset》.INFORMATION_SCHEMA.PARTITIONS 这个系统表
SELECT table_name, partition_id, total_rows,*
FROM `DS2.INFORMATION_SCHEMA.PARTITIONS`
WHERE table_name = 'sales_details_p'table_name |partition_id|total_rows|table_catalog|table_schema|table_name_1 |partition_id_1|total_rows_1|total_logical_bytes|total_billable_bytes|last_modified_time |storage_tier|
---------------+------------+----------+-------------+------------+---------------+--------------+------------+-------------------+--------------------+-----------------------+------------+
sales_details_p|20190401 | 6|jason-hsbc |DS2 |sales_details_p|20190401 | 6| 546| 546|2023-12-23 04:23:42.439|ACTIVE |
sales_details_p|20190411 | 30|jason-hsbc |DS2 |sales_details_p|20190411 | 30| 2676| 2676|2023-12-23 04:23:42.439|ACTIVE |
sales_details_p|20190421 | 18|jason-hsbc |DS2 |sales_details_p|20190421 | 18| 1590| 1590|2023-12-23 04:23:42.439|ACTIVE |
sales_details_p|20190417 | 12|jason-hsbc |DS2 |sales_details_p|20190417 | 12| 1068| 1068|2023-12-23 04:23:42.439|ACTIVE |
sales_details_p|20190419 | 12|jason-hsbc |DS2 |sales_details_p|20190419 | 12| 1110| 1110|2023-12-23 04:23:42.439|ACTIVE |
sales_details_p|20190430 | 30|jason-hsbc |DS2 |sales_details_p|20190430 | 30| 2718| 2718|2023-12-23 04:23:42.439|ACTIVE |
sales_details_p|20190407 | 24|jason-hsbc |DS2 |sales_details_p|20190407 | 24| 2286| 2286|2023-12-23 04:23:42.439|ACTIVE |
sales_details_p|20190429 | 12|jason-hsbc |DS2 |sales_details_p|20190429 | 12| 1074| 1074|2023-12-23 04:23:42.439|ACTIVE |
sales_details_p|20190415 | 18|jason-hsbc |DS2 |sales_details_p|20190415 | 18| 1626| 1626|2023-12-23 04:23:42.439|ACTIVE |
sales_details_p|20190403 | 12|jason-hsbc |DS2 |sales_details_p|20190403 | 12| 1020| 1020|2023-12-23 04:23:42.439|ACTIVE |
sales_details_p|20190425 | 6|jason-hsbc |DS2 |sales_details_p|20190425 | 6| 540| 540|2023-12-23 04:23:42.439|ACTIVE |
sales_details_p|20190405 | 12|jason-hsbc |DS2 |sales_details_p|20190405 | 12| 1140| 1140|2023-12-23 04:23:42.439|ACTIVE |
sales_details_p|20190427 | 30|jason-hsbc |DS2 |sales_details_p|20190427 | 30| 2790| 2790|2023-12-23 04:23:42.439|ACTIVE |
sales_details_p|20190412 | 18|jason-hsbc |DS2 |sales_details_p|20190412 | 18| 1554| 1554|2023-12-23 04:23:42.439|ACTIVE |
sales_details_p|20190424 | 12|jason-hsbc |DS2 |sales_details_p|20190424 | 12| 1008| 1008|2023-12-23 04:23:42.439|ACTIVE |
sales_details_p|20190402 | 30|jason-hsbc |DS2 |sales_details_p|20190402 | 30| 2646| 2646|2023-12-23 04:23:42.439|ACTIVE |
sales_details_p|20190409 | 12|jason-hsbc |DS2 |sales_details_p|20190409 | 12| 984| 984|2023-12-23 04:23:42.439|ACTIVE |
sales_details_p|20190420 | 6|jason-hsbc |DS2 |sales_details_p|20190420 | 6| 552| 552|2023-12-23 04:23:42.439|ACTIVE |
sales_details_p|20190422 | 6|jason-hsbc |DS2 |sales_details_p|20190422 | 6| 516| 516|2023-12-23 04:23:42.439|ACTIVE |
sales_details_p|20190410 | 12|jason-hsbc |DS2 |sales_details_p|20190410 | 12| 1092| 1092|2023-12-23 04:23:42.439|ACTIVE |
sales_details_p|20190428 | 6|jason-hsbc |DS2 |sales_details_p|20190428 | 6| 570| 570|2023-12-23 04:23:42.439|ACTIVE |
sales_details_p|20190408 | 6|jason-hsbc |DS2 |sales_details_p|20190408 | 6| 474| 474|2023-12-23 04:23:42.439|ACTIVE |
sales_details_p|20190418 | 18|jason-hsbc |DS2 |sales_details_p|20190418 | 18| 1590| 1590|2023-12-23 04:23:42.439|ACTIVE |
sales_details_p|20190404 | 24|jason-hsbc |DS2 |sales_details_p|20190404 | 24| 2250| 2250|2023-12-23 04:23:42.439|ACTIVE |
sales_details_p|20190426 | 12|jason-hsbc |DS2 |sales_details_p|20190426 | 12| 1074| 1074|2023-12-23 04:23:42.439|ACTIVE |
sales_details_p|20190416 | 12|jason-hsbc |DS2 |sales_details_p|20190416 | 12| 1026| 1026|2023-12-23 04:23:42.439|ACTIVE |
可以见到, 分区id (partition_id)就是日期
强制使用分区字段filter
就是上面提到的分区表属性 require_partition_filter
个人建议谨慎设置
设置为true的优点是, 强制所有其他开发人员写sql时加上分区字段filter, 否则会报错
SQL Error [100032] [HY000]: [Simba][BigQueryJDBCDriver](100032) Error executing query job.
Message: Cannot query over table 'DS2.sales_details_p2' without a filter over column(s) 'Order_Date' that can be used for partition elimination
缺点是, 所有包括count等所有就和函数也需要加上filter, 否则失败, 而且无法在GCP console上预览数据, 有时难以用sql获得表的总体信息.
设置失效时间
就是expiration_ms , 用毫秒表示
注意失效时间是以分区字段的值开始计算
例如expiration_ms 设成30日的话,
当我在20231221 插入一条Order_Date 为20190622 的数据时, 你以为用 Order_date =‘20190622’ 能查到数据?
其实是 分区20190622 一旦创建就马上过期(从20190622 算起。。) 今天已经是2023年了
所以这种情况下会导致分区创建后被删除, 数据会丢失
即使使用 select * from table 不加上分区字段filter (没有设成require_partition_filter=true的话) 也是查不出该数据的…
所以谨慎设置, 个人建议不要设置这个属性, 默认是分区永不过期
删除某个表分区
如果向手动删除一些旧数据, 而想直接删除某个分区的话
总之这个操作很危险, 对应的sql也没找到
我们可以用bq 民令来实现
bq rm --table project_id:dataset.table$partition
例如:
[gateman@manjaro-x13 coding]$ bq rm --table 'DS2.sales_details_p$20190407'
/home/gateman/devtools/google-cloud-sdk/platform/bq/bq.py:17: DeprecationWarning: 'pipes' is deprecated and slated for removal in Python 3.13import pipes
rm: remove table 'jason-hsbc:DS2.sales_details_p$20190407'? (y/N) y
[gateman@manjaro-x13 coding]$ 注意这个操作也是删除数据的操作!没事别删, BQ存储很便宜!
![基于博弈树的开源五子棋AI教程[4 静态棋盘评估]](https://img-blog.csdnimg.cn/direct/89a5a7c5e1af4310a1d23ac757f79e77.png)



