1. 报错内容
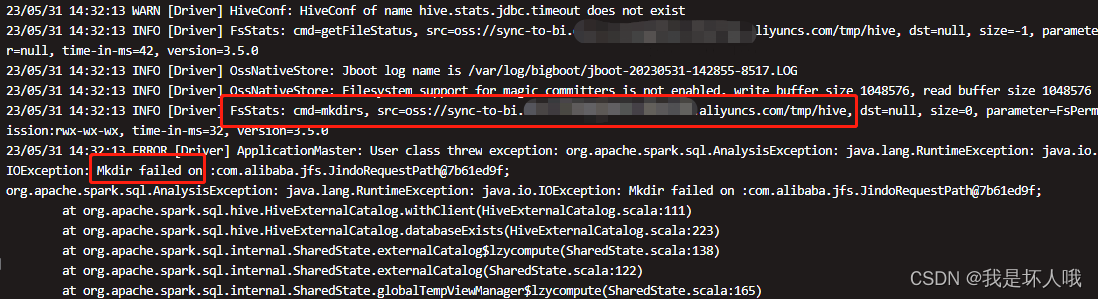
23/05/31 14:32:13 INFO [Driver] FsStats: cmd=mkdirs, src=oss://sync-to-bi.[马赛克].aliyuncs.com/tmp/hive, dst=null, size=0, parameter=FsPermission:rwx-wx-wx, time-in-ms=32, version=3.5.0
23/05/31 14:32:13 ERROR [Driver] ApplicationMaster: User class threw exception: org.apache.spark.sql.AnalysisException: java.lang.RuntimeException: java.io.IOException: Mkdir failed on :com.alibaba.jfs.JindoRequestPath@7b61ed9f;
org.apache.spark.sql.AnalysisException: java.lang.RuntimeException: java.io.IOException: Mkdir failed on :com.alibaba.jfs.JindoRequestPath@7b61ed9f;at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:111)at org.apache.spark.sql.hive.HiveExternalCatalog.databaseExists(HiveExternalCatalog.scala:223)at org.apache.spark.sql.internal.SharedState.externalCatalog$lzycompute(SharedState.scala:138)at org.apache.spark.sql.internal.SharedState.externalCatalog(SharedState.scala:122)at org.apache.spark.sql.internal.SharedState.globalTempViewManager$lzycompute(SharedState.scala:165)at org.apache.spark.sql.internal.SharedState.globalTempViewManager(SharedState.scala:160)at org.apache.spark.sql.hive.HiveSessionStateBuilder$$anonfun$2.apply(HiveSessionStateBuilder.scala:55)at org.apache.spark.sql.hive.HiveSessionStateBuilder$$anonfun$2.apply(HiveSessionStateBuilder.scala:55)at org.apache.spark.sql.catalyst.catalog.SessionCatalog.globalTempViewManager$lzycompute(SessionCatalog.scala:91)at org.apache.spark.sql.catalyst.catalog.SessionCatalog.globalTempViewManager(SessionCatalog.scala:91)at org.apache.spark.sql.catalyst.catalog.SessionCatalog.isTemporaryTable(SessionCatalog.scala:782)at org.apache.spark.sql.internal.CatalogImpl.tableExists(CatalogImpl.scala:260)at com.tcl.task.terminalmanage.TerminalManageUtils$.saveDataFrame2Hive(TerminalManageUtils.scala:148)at com.tcl.task.terminalmanage.warehouse.ods.Ods_Nps_Stability_Crash_Dropbox$.execute(Ods_Nps_Stability_Crash_Dropbox.scala:47)at com.tcl.task.terminalmanage.CommonMain.main(CommonMain.scala:28)at com.tcl.task.terminalmanage.warehouse.ods.Ods_Nps_Stability_Crash_Dropbox.main(Ods_Nps_Stability_Crash_Dropbox.scala)at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)at java.lang.reflect.Method.invoke(Method.java:498)at org.apache.spark.deploy.yarn.ApplicationMaster$$anon$2.run(ApplicationMaster.scala:685)
Caused by: java.lang.RuntimeException: java.io.IOException: Mkdir failed on :com.alibaba.jfs.JindoRequestPath@7b61ed9fat org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:606)at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:544)at org.apache.spark.sql.hive.client.HiveClientImpl.newState(HiveClientImpl.scala:199)at org.apache.spark.sql.hive.client.HiveClientImpl.<init>(HiveClientImpl.scala:129)at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)at java.lang.reflect.Constructor.newInstance(Constructor.java:423)at org.apache.spark.sql.hive.client.IsolatedClientLoader.createClient(IsolatedClientLoader.scala:284)at org.apache.spark.sql.hive.HiveUtils$.newClientForMetadata(HiveUtils.scala:386)at org.apache.spark.sql.hive.HiveUtils$.newClientForMetadata(HiveUtils.scala:288)at org.apache.spark.sql.hive.HiveExternalCatalog.client$lzycompute(HiveExternalCatalog.scala:67)at org.apache.spark.sql.hive.HiveExternalCatalog.client(HiveExternalCatalog.scala:66)at org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$databaseExists$1.apply$mcZ$sp(HiveExternalCatalog.scala:224)at org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$databaseExists$1.apply(HiveExternalCatalog.scala:224)at org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$databaseExists$1.apply(HiveExternalCatalog.scala:224)at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:102)... 20 more
Caused by: java.io.IOException: Mkdir failed on :com.alibaba.jfs.JindoRequestPath@7b61ed9fat com.alibaba.jfs.OssFileletSystem.mkdir(OssFileletSystem.java:184)at com.aliyun.emr.fs.internal.ossnative.OssNativeStore.mkdirs(OssNativeStore.java:521)at com.aliyun.emr.fs.oss.JindoOssFileSystem.mkdirsCore(JindoOssFileSystem.java:194)at com.aliyun.emr.fs.common.AbstractJindoShimsFileSystem.mkdirs(AbstractJindoShimsFileSystem.java:389)at org.apache.hadoop.hive.ql.exec.Utilities.createDirsWithPermission(Utilities.java:3385)at org.apache.hadoop.hive.ql.session.SessionState.createRootHDFSDir(SessionState.java:705)at org.apache.hadoop.hive.ql.session.SessionState.createSessionDirs(SessionState.java:650)at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:582)... 36 more
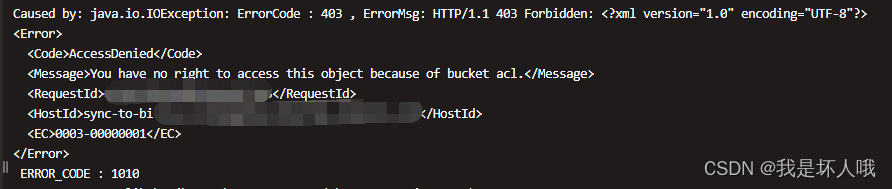
Caused by: java.io.IOException: ErrorCode : 403 , ErrorMsg: HTTP/1.1 403 Forbidden: <?xml version="1.0" encoding="UTF-8"?>
<Error><Code>AccessDenied</Code><Message>You have no right to access this object because of bucket acl.</Message><RequestId>6[马赛克]5</RequestId><HostId>sync-to-bi.[马赛克].aliyuncs.com</HostId><EC>0003-00000001</EC>
</Error>ERROR_CODE : 1010at com.alibaba.jboot.JbootFuture.get(JbootFuture.java:145)at com.alibaba.jfs.OssFileletSystem.mkdir(OssFileletSystem.java:178)... 43 more2. 报错程序
package com.tcl.task.terminalmanage.warehouse.odsimport com.tcl.task.terminalmanage.{CommonMain, TerminalManageUtils}
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._object Ods_Nps_Stability_Crash_Dropbox extends CommonMain {val HiveDatabase = "te[马赛克]"val HiveTableName = "ods_[马赛克]_di"val ck_Table = "ods_[马赛克]_cluster"val colNames = Array("[马赛克]", "[马赛克]","[反正就是一些字段名]")override def execute(spark: SparkSession, calcDate: String): Unit = {spark.sql("set spark.sql.caseSensitive=true")val sc = spark.sparkContextval logPath = "oss://[马赛克]@sync-to-bi.[马赛克]/" + dateConverYYmm(calcDate) + "*"if (!Mutils.isPathExistTest(logPath, sc)) {return}var df = spark.read.json(logPath)for (col <- colNames) {if (!df.columns.contains(col)) {df = df.withColumn(col, lit(""))}}val result = df.withColumn("recordDate",lit(calcDate)).select("[马赛克]", "[马赛克]","[反正就是一些字段名]","recordDate")TerminalManageUtils.saveDataFrame2Hive(spark,result,HiveDatabase,HiveTableName,calcDate,0)}//2022-10-15def dateConverYYmm(date: String) = {val str1 = date.substring(0, 4)val str2 = date.substring(5, 7)val str3 = date.substring(8, 10)str1 + str2 + str3}}
程序很简单,就是数仓ODS层计算逻辑,直接从阿里云OSS读取数据,补充上一些必要的列,最后数据落盘到hive表。
3. 问题分析
3.1 分析报错内容
根据下面两段报错提示可以得出:Spark Driver在写入Hive时,试图在oss://sync-to-bi.[马赛克].aliyuncs.com/tmp/hive这个路径下创建目录。但是sync-to-bi这个是数据源桶,只有读权限,没有写权限,自然会AccessDenied。
问题的关键在于:为什么Spark Driver要在写入Hive时,往数据源的/tmp/hive创建目录?
/tmp/hive目录存放的是Hive的临时操作目录比如插入数据,insert into插入Hive表数据的操作,Hive的操作产生的操作临时文件都会存储在这里,或者比如在${HIVE_HOME}/bin下执行,sh hive,进入Hive的命令行模式,都会在这里/tmp/hive目录下产生一个Hive当前用户名字命名的临时文件夹,这个文件夹权限是700,默认是hadoop的启动用户,我的hadoop用户是hadoopadmin,所以名字是hadoopadmin的文件夹
-- Hive的/tmp/hive以及/user/hive/warehouse目录对Hive的影响 | 码农家园
如果像上面说的,insert into操作会在tmp/hive产生临时文件。那为什么不是在目标OSS创建临时文件,而是在源数据的OSS创建?我能在代码中指定产生临时文件的位置吗?
3.2 根据猜想进行尝试
尝试修改默认fs,指向目标OSS,即hive表location所在的OSS
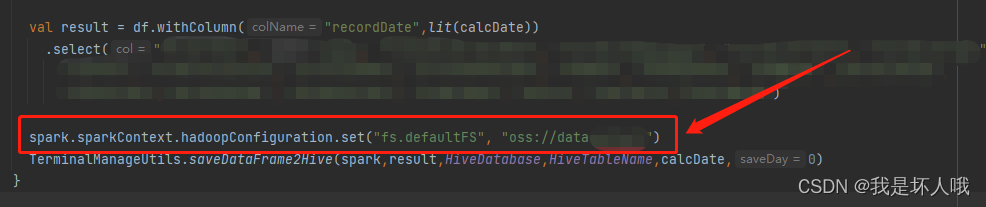
再次运行代码,竟然真的成功了!但是进一步思考,在父类CommonMain中本就是有默认fs的配置
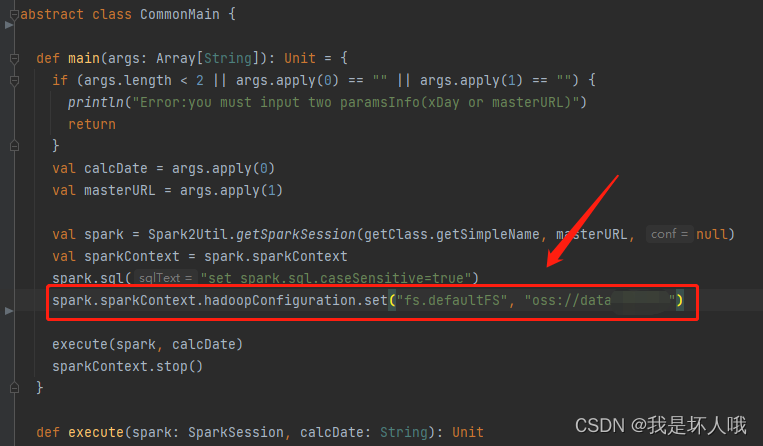
那么,为什么父类中的配置没有生效?
3.3 添加日志分析父类fs配置不生效的原因
package com.tcl.task.terminalmanage.warehouse.odsimport com.tcl.task.terminalmanage.{CommonMain, TerminalManageUtils}
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._object Ods_Nps_Stability_Crash_Dropbox extends CommonMain {private val logger = LoggerFactory.getLogger("Luo")val HiveDatabase = "te[马赛克]"val HiveTableName = "ods_[马赛克]_di"val ck_Table = "ods_[马赛克]_cluster"val colNames = Array("[马赛克]", "[马赛克]","[反正就是一些字段名]")override def execute(spark: SparkSession, calcDate: String): Unit = {logger.info("-------1--------" + spark.sparkContext.hadoopConfiguration.get("fs.defaultFS"))spark.sql("set spark.sql.caseSensitive=true")val sc = spark.sparkContextval logPath = "oss://[马赛克]@sync-to-bi.[马赛克]/" + dateConverYYmm(calcDate) + "*"logger.info("-------2--------" + spark.sparkContext.hadoopConfiguration.get("fs.defaultFS"))if (!Mutils.isPathExistTest(logPath, sc)) {return}logger.info("-------3--------" + spark.sparkContext.hadoopConfiguration.get("fs.defaultFS"))var df = spark.read.json(logPath)logger.info("-------4--------" + spark.sparkContext.hadoopConfiguration.get("fs.defaultFS"))for (col <- colNames) {if (!df.columns.contains(col)) {df = df.withColumn(col, lit(""))}}val result = df.withColumn("recordDate",lit(calcDate)).select("[马赛克]", "[马赛克]","[反正就是一些字段名]","recordDate")logger.info("-------5--------" + spark.sparkContext.hadoopConfiguration.get("fs.defaultFS"))TerminalManageUtils.saveDataFrame2Hive(spark,result,HiveDatabase,HiveTableName,calcDate,0)}//2022-10-15def dateConverYYmm(date: String) = {val str1 = date.substring(0, 4)val str2 = date.substring(5, 7)val str3 = date.substring(8, 10)str1 + str2 + str3}}
日志结果:
Luo: -------1--------oss://data[马赛克]
Luo: -------2--------oss://data[马赛克]
Luo: -------3--------oss://[马赛克]@sync-to-bi.[马赛克].aliyuncs.com
Luo: -------4--------oss://[马赛克]@sync-to-bi.[马赛克].aliyuncs.com
Luo: -------5--------oss://[马赛克]@sync-to-bi.[马赛克].aliyuncs.com
谁承想,问题竟然出现在了一个路径是否存在的分支判断。

由于很明显程序运行不会进入这个if分支,所以它自动被忽略了。分支不会执行,但判断条件一定是会执行的。 而越容易出问题的,往往就是在这种非常容易被忽略的地方。
4. 总结
如果程序出现了一些“灵异”现象,很有可能,问题出现在你一开始就忽略的地方。