一、说明
构建图像分类器已成为新的“hello world”。还记得当你第一次接触 Python 时,你的打印“hello world”感觉很神奇吗?几个月前,当我按照PyTorch 官方教程并为自己构建了一个运行良好的简单分类器时,我也有同样的感觉。

我对我的简单分类器的准确性感到惊讶。如果我没记错的话,在MNIST 手写数字数据集上,测试集上的准确率超过 98%。(顺便说一句,这表明我们在数小时内构建出高度准确的图像分类器方面已经取得了多大进展。ML 社区——是的,包括你——非常棒,因为知识和工具的自由共享)
尽管分类器的准确性很高,但有一个问题一直困扰着我:
即使我给它提供与它所训练的内容完全无关的图像,神经网络也会输出一个类别。
你知道该怎么做。训练猫与狗分类器,抛出一个人的图像,网络会将其分类为猫或狗。
我知道我对分类器的期望是不切实际的。它的行为完全按照编程的方式进行。如果我将最后一层(softmax)输出解释为概率,那么作为输入给出的任何图像总会有一个具有最大值的类别。该网络根本不知道举手投足并说:“这看起来像是我没有接受过训练的东西”的概念。但这正是我想要我的神经网络做的事情。
在几乎所有现实世界的问题中,您想要的不仅仅是结果,而且您还需要对该结果的信心/确定性的了解。如果您正在制造自动驾驶汽车,您不仅要检测行人,还要表达您对该物体是行人而不是交通锥的信心。同样,如果您正在编写一个在股票市场上交易的机器人,您希望它能够识别情况何时超出其舒适区,这样它就可以停止行动而不会破产。当一个人不确定时,智力的很大一部分就不会采取行动。因此,令人惊讶的是,对于许多机器学习项目来说,表达不确定性并不是其目的。

可能是一个吵闹的 boi(通过欺骗神经网络:创建你自己的对抗性示例)
我想通过构建一个 MNIST 分类器来探索这个方向,该分类器可以表达输入图像是特定数字的(不确定)确定性。当你向它显示数字时,这样的分类器将具有很高的准确性,但当你向它扔不相关的图像时,它会拒绝分类。我的最终分类器在 MNIST 上的准确度约为 97%,并且它拒绝对白噪声和大多数不相关(非 MNIST)图像进行分类。您可以在此处访问代码,并且可能希望按照存储库中包含的 Jupyter 笔记本以及本教程进行操作。
二、贝叶斯神经网络如何工作
我不会在这里介绍贝叶斯分析的全部内容,但我将提供足够的上下文供您理解并修改代码。
关键思想非常简单:在贝叶斯世界观中,一切都具有概率分布,包括模型参数(神经网络中的权重和偏差)。在编程语言中,我们有可以采用特定值的变量,每次访问该变量时,您都会获得相同的值。与此相反,在贝叶斯世界中,我们有类似的实体,称为随机变量,每次访问它时都会给出不同的值。因此,如果 X 是代表正态分布的随机变量,则每次访问 X 时,它都会有不同的值。
从随机变量中获取新值的过程称为采样。得出什么值取决于随机变量的相关概率分布。与随机变量相关的概率分布越宽,其值的不确定性就越大,因为它可以根据(宽)概率分布取任何值。

如果您的随机变量是两次掷骰子的数字之和,则每次掷骰子时您都会得到一个值,其概率取决于上面的分布。这意味着您最有可能得到的总和是 7,最不可能得到的总和是 2 和 12。(来自维基百科)
在传统的神经网络中,您有固定的权重和偏差来确定输入如何转换为输出。在贝叶斯神经网络中,所有权重和偏差都有一个概率分布。要对图像进行分类,您需要对网络进行多次运行(前向传递),每次都使用一组新的采样权重和偏差。您得到的不是一组输出值,而是多组输出值,每次运行一组。输出值集表示输出值的概率分布,因此您可以找出每个输出的置信度和不确定性。正如您将看到的,如果输入图像是网络从未见过的东西,那么对于所有输出类别,不确定性将会很高,您应该将网络解释为:“我真的不知道这张图像是关于什么的”。
三、使用 Pyro 和 PyTorch 编写您的第一个贝叶斯神经网络
该代码假设您熟悉概率编程和 PyTorch 的基本思想。如果您对其中任何一个都不熟悉,我建议您使用以下资源:
- 黑客学习贝叶斯建模和概率编程基础知识的贝叶斯方法
- 使用 PyTorch 进行深度学习:60 分钟的闪电战。具体来说,是关于训练分类器的教程。
PyTorch 有一个名为Pyro的配套库,它提供了对用 PyTorch 编写的神经网络进行概率编程的功能。将神经网络“自动”转换为贝叶斯对应物有两个步骤:
- 首先,它有助于将概率分布分配给网络中的所有权重和偏差,从而将它们转换为随机变量
- 其次,它有助于使用训练数据来推断这些概率分布,以便您可以使用它来对图像进行分类
推理是整个过程中最困难的一步。它基于您以前可能见过的著名贝叶斯定理。

统治世界的看似简单的方程式
深入了解这个方程的细节超出了本教程的范围,但我会尝试让您直观地了解正在发生的事情。假设A是权重和偏差的初始概率分布(称为先验,通常是一些标准分布,如正态分布或均匀随机分布),B是训练数据(图像/标签的输入/输出对)。
您应该记住的贝叶斯定理的关键思想是,我们希望使用数据来找出权重和偏差P(A | B)(后验)的更新分布。就像使用最初随机分配的网络权重和偏差一样,参数(先验)的初始分布会给我们带来错误的结果。只有使用数据获得更新的参数分布后,我们才能使用网络对图像进行分类。
权重和偏差的概率分布通过贝叶斯定理进行更新,考虑到它们的初始值P(A)以及这些初始分布描述输入数据P (B|A)的可能性(它被读作给定 A 时 B 的概率) 。更新后的权重分布P(A | B)(后验)取决于哪一个具有更强的拉力——先验分布或似然分布。(如果您对 P(B) 术语感到好奇,它将在本教程的后面部分变得清晰)。
我知道上面的这段话可能会让严格的贝叶斯主义者惊恐地哭泣。我知道这些定义并不精确。但本教程并不是要介绍贝叶斯查看数据的方法的全部优点。有很多关于它的书籍和课程,我无法在一篇教程中全面介绍它。本教程是关于贝叶斯神经网络的实际实现。我花了好几天的时间深入研究Pyro 教程,并试图将其中一个示例转换为分类器。我终于在IBM Watson 的网站上找到了关于在 MNIST 上使用 Pyro 的简短教程。我的代码基于该教程,但我将其扩展到非 MNIST 和白噪声数据,看看贝叶斯神经网络在遇到以前从未见过的输入时是否真的可以说“我不知道”。
尽管我将尝试解释 Pyro 的基础知识,但如果您完成前三个教程(第一部分、第二部分和第三部分),您将从本教程中获得很多价值。
四、准备好?我们直接上代码吧
class NN(nn.Module):def __init__(self, input_size, hidden_size, output_size):super(NN, self).__init__()self.fc1 = nn.Linear(input_size, hidden_size)self.out = nn.Linear(hidden_size, output_size)def forward(self, x):output = self.fc1(x)output = F.relu(output)output = self.out(output)return outputtrain_loader = torch.utils.data.DataLoader(datasets.MNIST('mnist-data/', train=True, download=True,transform=transforms.Compose([transforms.ToTensor(),])),batch_size=128, shuffle=True)test_loader = torch.utils.data.DataLoader(datasets.MNIST('mnist-data/', train=False, transform=transforms.Compose([transforms.ToTensor(),])),batch_size=128, shuffle=True)net = NN(28*28, 1024, 10)导入 PyTorch、Pyro 和其他标准库(如 matplotlib 和 numpy)后,我们定义了一个包含 1024 个单元的隐藏层的标准前馈神经网络。我们还加载 MNIST 数据。
def model(x_data, y_data):fc1w_prior = Normal(loc=torch.zeros_like(net.fc1.weight), scale=torch.ones_like(net.fc1.weight))fc1b_prior = Normal(loc=torch.zeros_like(net.fc1.bias), scale=torch.ones_like(net.fc1.bias))outw_prior = Normal(loc=torch.zeros_like(net.out.weight), scale=torch.ones_like(net.out.weight))outb_prior = Normal(loc=torch.zeros_like(net.out.bias), scale=torch.ones_like(net.out.bias))priors = {'fc1.weight': fc1w_prior, 'fc1.bias': fc1b_prior, 'out.weight': outw_prior, 'out.bias': outb_prior}# lift module parameters to random variables sampled from the priorslifted_module = pyro.random_module("module", net, priors)# sample a regressor (which also samples w and b)lifted_reg_model = lifted_module()lhat = log_softmax(lifted_reg_model(x_data))pyro.sample("obs", Categorical(logits=lhat), obs=y_data)
在 Pyro 中,model()函数定义了输出数据的生成方式。在我们的分类器中,当我们使用展平的 28*28 像素图像运行神经网络(在上面的网络变量中初始化)时,会生成对应于每个数字的 10 个输出值。在model()中,函数pyro.random_module()将神经网络的参数(权重和偏差)转换为随机变量,这些变量具有由fc1w_prior、fc1b_prior、outw_prior和outb_prior给出的初始(先验)概率分布(在我们的例子中,为你可以看到,我们用正态分布初始化它们)。最后,通过pyro.sample(),我们告诉Pyro该网络的输出本质上是分类的(即它可以是0、1、2等。)
def guide(x_data, y_data):# First layer weight distribution priorsfc1w_mu = torch.randn_like(net.fc1.weight)fc1w_sigma = torch.randn_like(net.fc1.weight)fc1w_mu_param = pyro.param("fc1w_mu", fc1w_mu)fc1w_sigma_param = softplus(pyro.param("fc1w_sigma", fc1w_sigma))fc1w_prior = Normal(loc=fc1w_mu_param, scale=fc1w_sigma_param)# First layer bias distribution priorsfc1b_mu = torch.randn_like(net.fc1.bias)fc1b_sigma = torch.randn_like(net.fc1.bias)fc1b_mu_param = pyro.param("fc1b_mu", fc1b_mu)fc1b_sigma_param = softplus(pyro.param("fc1b_sigma", fc1b_sigma))fc1b_prior = Normal(loc=fc1b_mu_param, scale=fc1b_sigma_param)# Output layer weight distribution priorsoutw_mu = torch.randn_like(net.out.weight)outw_sigma = torch.randn_like(net.out.weight)outw_mu_param = pyro.param("outw_mu", outw_mu)outw_sigma_param = softplus(pyro.param("outw_sigma", outw_sigma))outw_prior = Normal(loc=outw_mu_param, scale=outw_sigma_param).independent(1)# Output layer bias distribution priorsoutb_mu = torch.randn_like(net.out.bias)outb_sigma = torch.randn_like(net.out.bias)outb_mu_param = pyro.param("outb_mu", outb_mu)outb_sigma_param = softplus(pyro.param("outb_sigma", outb_sigma))outb_prior = Normal(loc=outb_mu_param, scale=outb_sigma_param)priors = {'fc1.weight': fc1w_prior, 'fc1.bias': fc1b_prior, 'out.weight': outw_prior, 'out.bias': outb_prior}lifted_module = pyro.random_module("module", net, priors)return lifted_module()理解这部分——由guide()函数代表——对我来说是最棘手的事情。在相当长的一段时间里,我不明白为什么需要它,特别是因为它看起来非常像 model ()函数。解释起来会很困难,但我会尝试。(如果您无法理解,我的解释我推荐Pyro 教程或下面我提供的有关该主题的链接)。
再看一下贝叶斯方程:
![]()
在model()函数中,我们定义了P(A) ——权重和偏差的先验。方程的P (B|A)部分由神经网络表示,因为给定参数(权重和偏差),我们可以对图像、标签对进行多次运行,并找出训练数据相应的概率分布。在训练之前,最初由于权重和先验的先验都是相同的(都是正态分布),因此给定图像获得正确标签的高概率的可能性会很低。
事实上,推理是学习权重和偏差的概率分布的过程,它最大化获得正确图像、标签对的高概率的可能性。
这个推理过程由P(A |B)表示,它是给定输入/输出对 ( B )的参数A的后验概率。我之前写过,推理是困难的。这是因为您在分母P(B)中看到的术语。这个术语称为证据,它只是在所有可能的参数值下观察数据(输入/输出对)的概率,并按各自的概率加权。
![]()
计算这个总数很困难,原因有以下三个:
- 假设,参数Aj的值范围可以从 -无穷大到 +无穷大
- 对于该范围内的每个Aj值,您必须运行模型来查找生成您观察到的输入、输出对的可能性(总数据集可能有数百万对)
- 这样的参数可能不止一个,而是很多个 (j >> 1)。事实上,对于我们这种规模的神经网络来说,我们有大约 800 万个参数(权重数量 = 1024*28*28*10)。
我上面描述的后验枚举方法类型对于除了非常琐碎的模型之外的任何东西都不实用。如果我们可以进行随机抽样,而不是这种类似网格的枚举,会怎样?事实上,基于抽样的方法被广泛使用,它们被称为蒙特卡罗方法。特别是,Metropolis-Hastings是一种流行的蒙特卡罗采样算法。(它包含在 Pyro 和大多数其他概率编程语言中)。
不幸的是,对于复杂的贝叶斯模型,例如具有 800 万个参数的神经网络,蒙特卡罗方法的收敛速度仍然很慢,并且可能需要数周时间才能发现完整的后验。
值得庆幸的是,有一种越来越流行的方法,称为变分贝叶斯,它似乎非常适合寻找神经网络参数的后验,即使对于大型数据集也是如此。要了解此技术背后的直觉,我强烈建议观看以下视频(最多前 40 分钟)。
变分贝叶斯方法的要点是,由于我们无法精确计算后验概率,因此我们可以找到最接近它的“行为良好”的概率分布。我所说的“行为良好”是指可以用一小组参数(例如平均值或方差)来表示的分布(例如正态分布或指数分布)。因此,在“行为良好”的分布中随机初始化这些参数后,您可以进行梯度下降并每次稍微修改分布的参数(例如均值或方差),以查看结果分布是否更接近后验分布你想要计算的。(如果您正在思考我们如何知道结果分布是否更接近后验,如果后验正是我们想要计算的,那么您已经理解了这个想法。答案是,令人惊讶的是,我们不需要确切的后验找到它与其他“行为良好”分布之间的接近度。观看上面的视频,了解我们实际优化的接近度度量:证据下界或 ELBO。我还发现这一系列 帖子 对该主题很有用)。
为了直观地理解变分贝叶斯,请参见下图:

通过变分方法初学者指南:平均场近似
蓝色曲线是如果您进行我们之前讨论过的长时间(枚举)计算,您将得到的真实后验。该曲线可以采用任意形状,因为它是枚举计算的结果。与此相反,因为它是一种像正态分布一样表现良好的分布,所以绿色曲线的整个形状可以用一个参数 Z 来描述。变分贝叶斯方法所做的是使用梯度下降方法来随机改变 Z 参数的值初始化值为其结果分布最接近真实后验的值。优化结束时,绿色曲线与蓝色曲线并不完全相同,但非常相似。我们可以安全地使用近似的绿色曲线而不是未知的真实蓝色曲线来进行预测。(如果这一切很难理解,我建议观看上面的视频。)
现在这就是引导函数的用武之地。它帮助我们初始化一个表现良好的分布,稍后我们可以优化该分布以近似真实的后验。再看一下:
def guide(x_data, y_data):# First layer weight distribution priorsfc1w_mu = torch.randn_like(net.fc1.weight)fc1w_sigma = torch.randn_like(net.fc1.weight)fc1w_mu_param = pyro.param("fc1w_mu", fc1w_mu)fc1w_sigma_param = softplus(pyro.param("fc1w_sigma", fc1w_sigma))fc1w_prior = Normal(loc=fc1w_mu_param, scale=fc1w_sigma_param)# First layer bias distribution priorsfc1b_mu = torch.randn_like(net.fc1.bias)fc1b_sigma = torch.randn_like(net.fc1.bias)fc1b_mu_param = pyro.param("fc1b_mu", fc1b_mu)fc1b_sigma_param = softplus(pyro.param("fc1b_sigma", fc1b_sigma))fc1b_prior = Normal(loc=fc1b_mu_param, scale=fc1b_sigma_param)# Output layer weight distribution priorsoutw_mu = torch.randn_like(net.out.weight)outw_sigma = torch.randn_like(net.out.weight)outw_mu_param = pyro.param("outw_mu", outw_mu)outw_sigma_param = softplus(pyro.param("outw_sigma", outw_sigma))outw_prior = Normal(loc=outw_mu_param, scale=outw_sigma_param).independent(1)# Output layer bias distribution priorsoutb_mu = torch.randn_like(net.out.bias)outb_sigma = torch.randn_like(net.out.bias)outb_mu_param = pyro.param("outb_mu", outb_mu)outb_sigma_param = softplus(pyro.param("outb_sigma", outb_sigma))outb_prior = Normal(loc=outb_mu_param, scale=outb_sigma_param)priors = {'fc1.weight': fc1w_prior, 'fc1.bias': fc1b_prior, 'out.weight': outw_prior, 'out.bias': outb_prior}lifted_module = pyro.random_module("module", net, priors)return lifted_module()该guide()函数描述了Z参数(例如权重和偏差的均值和方差),可以更改这些参数以查看结果分布是否非常接近model()得出的后验分布。现在,在我们的例子中,model()看起来与guide()非常相似,但情况并不总是如此。理论上,model()函数可能比guide()函数复杂得多。
弄清楚model()和guide()函数后,我们就可以进行推理了。首先,让我们告诉 Pyro 使用哪个优化器来进行变分推理。
optim = Adam({"lr": 0.01})
svi = SVI(model, guide, optim, loss=Trace_ELBO())您会注意到我们正在使用 PyTorch 中的 Adam 优化器(要了解有关它和其他优化算法的更多信息,这里有一个很棒的系列)。我们用于优化的损失函数是 ELBO(这类似于通过反向传播训练非贝叶斯神经网络时使用均方误差或交叉熵损失)。
让我们编写优化循环。
num_iterations = 5
loss = 0for j in range(num_iterations):loss = 0for batch_id, data in enumerate(train_loader):# calculate the loss and take a gradient steploss += svi.step(data[0].view(-1,28*28), data[1])normalizer_train = len(train_loader.dataset)total_epoch_loss_train = loss / normalizer_trainprint("Epoch ", j, " Loss ", total_epoch_loss_train)您会注意到这个循环几乎就是我们训练标准神经网络的方式。有多个时期/迭代(在本例中为 5)。在每次迭代中,我们都会检查一小批数据(图像、标签的输入/输出对)。变分推理的另一个好处是我们不必一次性输入整个数据集(可能是数百万)。由于优化器需要数千步才能找到引导函数参数的最佳值,因此在每一步我们都可以向其提供单独的小批量数据。这极大地加快了推理速度。
一旦损失似乎稳定/收敛到一个值,我们就可以停止优化并查看我们的贝叶斯神经网络的准确性。这是执行此操作的代码。
num_samples = 10
def predict(x):sampled_models = [guide(None, None) for _ in range(num_samples)]yhats = [model(x).data for model in sampled_models]mean = torch.mean(torch.stack(yhats), 0)return np.argmax(mean.numpy(), axis=1)print('Prediction when network is forced to predict')
correct = 0
total = 0
for j, data in enumerate(test_loader):images, labels = datapredicted = predict(images.view(-1,28*28))total += labels.size(0)correct += (predicted == labels).sum().item()
print("accuracy: %d %%" % (100 * correct / total))在predict()函数中首先要注意的是,我们使用学习到的guide()函数(而不是model()函数)来进行预测。这是因为对于model(),我们所知道的只是权重的先验,而不是后验。但对于优化迭代后的guide(),参数值给出的分布近似于真实的后验,因此我们可以用它来进行预测。
第二件需要注意的事情是,对于每个预测,我们都会对一组新的权重和参数进行 10 次采样(由num_samples给出)。这实际上意味着我们对一个新的神经网络进行 10 次采样以进行一次预测。正如您稍后将看到的,这使我们能够给出输出的不确定性。在上面的例子中,为了进行预测,我们对给定输入的 10 个采样网络的最终层输出值进行平均,并将最大激活值作为预测数字。这样做,我们发现我们的网络在测试集上的准确率为 89%。但请注意,在这种情况下,我们迫使我们的网络在每种情况下做出预测。我们还没有使用贝叶斯定理的魔力来让我们的网络说:“我拒绝在这里做出预测”。
这正是我们接下来将使用下面的代码执行的操作。
prob = np.percentile(histo_exp, 50) #sampling median probabilityif(prob>0.2): #select if network thinks this sample is 20% chance of this being a labelhighlight = True #possibly an answer我不会详细介绍估计不确定性的完整代码(您可以在笔记本中看到)。本质上,我们正在做的是:
- 对于输入图像,取 100 个神经网络样本,从最后一层得到 100 个不同的输出值
- 通过求幂将这些输出(对数软最大化)转换为概率
- 现在,给定输入图像,对于每个数字,我们有 100 个概率值
- 我们将这 100 个概率值的中值(第 50 个百分位数)作为每个数字的阈值概率
- 如果阈值概率大于0.2,我们选择该数字作为网络的分类输出
换句话说,如果在多个概率样本中,该数字的中值概率至少为 0.2,我们希望神经网络输出一个数字作为推荐。这意味着对于某些输入,网络可以输出两个数字作为分类输出,而对于其他输入,网络可以输出任何数字(如果我们给它非数字图像,这正是我们想要的)。
五、MNIST 数据集上的结果
当我在包含 10,000 张图像的整个 MNIST 测试集上运行网络时,我得到了以下结果:
- 网络拒绝分类的图像百分比:12.5%(10,000 张中的 1250 张)
- 其余 8750 张“已接受”图像的准确率:96%
请注意,当我们给网络一个拒绝分类的机会时,96% 的准确率远高于强制分类时 88% 的准确率。
可视化幕后发生的事情。我绘制了 MNIST 测试批次中的 100 张随机图像。对于 100 张图像中的大部分,网络分类准确。

上图显示输入图像的真实标签为 3,并且对于 10 个数字中的每一个,显示了对数概率的直方图。对于标签 3,中值对数概率实际上接近 0,这意味着该图像为 3 的概率接近 1 (exp(0) = 1)。这就是为什么它以黄色突出显示。由于网络选择的标签与真实标签相同,因此显示“正确”。您还可以查看输入图像的实际外观。
在我对 100 张图像进行多次运行时,网络做出预测的准确性为 94-96%。该网络经常选择不对 10-15% 的图像进行预测,并且查看一些网络表示“我不太确定”的图像很有趣。
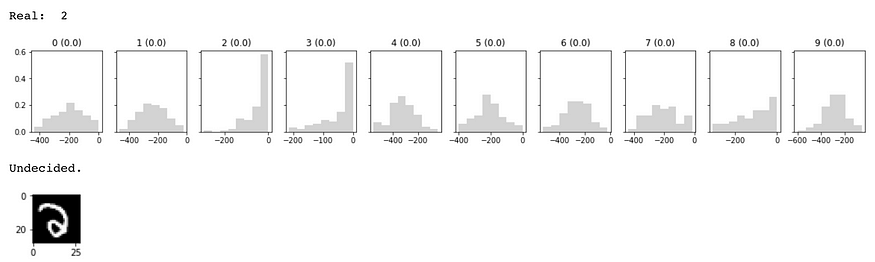
连我都很难分辨出这个数字是“2”。从直方图中可以看出,网络对于 2 个和 3 个标签都具有很高的不确定性。对于网络尚未确定的情况,所有标签的对数概率分布都很宽,而在上图中准确分类“3”的情况下,您会注意到数字 3 的分布很窄,而对于所有其他数字,它很宽(这意味着网络非常确定它是 3)。
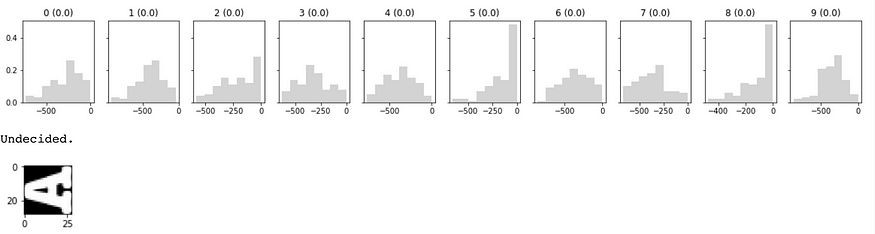
网络尚未决定的另一个情况。

你看图片都乱七八糟了。传统的神经网络可能会输出一些东西,但我们的贝叶斯网络拒绝说什么。
六、随机生成图像的结果
为了了解网络在输入纯白噪声时的表现,我生成了 100 张随机图像。
# generate random dataimages_random = torch.rand(100,28,28)
labels_random = torch.randint(0,10, (100,))当这些图像作为输入时,网络拒绝对其中 95% 的图像进行预测。
这是典型的随机生成图像的样子:

七、非 MNIST 数据集上的结果
我更进一步,下载了非 MNIST数据集,这是一个字母而不是数字的数据集。它看起来像这样:

对于非 MNIST 测试集,网络拒绝对约 80% 的图像进行分类(测试集中总共 459 张图像中的 363 张)。
下面显示了非 MNIST 图像的示例。
很高兴看到我们的网络对其训练内容(MNSIT)给出了很好的准确性,同时又没有被专门设计来愚弄它的数据集(非 MNIST)所愚弄。
八、结论以及如何使我们的贝叶斯网络变得更好
MNIST 数据集上最先进的结果具有 99.8% 的准确率。因此,我们大约 96% 的准确度(当我们想要做出预测时)与此相去甚远。
有四种方法可以提高准确性:
- 我们使用了一个非常简单的模型:具有 1024 个神经元的单层神经网络。如果我们使用更先进的卷积网络,我相信我们可以提高准确性。
- 如果我们持续运行优化更长时间,我们就可以提高准确性
- 如果我们对每个图像采样更多数据点(而不是 100 个),结果可能会有所改善
- 如果我们将接受标准设为从中值概率最小 0.2 到第 10 个百分位概率最小 0.5,我们的网络将拒绝更多图像,但对于接受的图像,它可能具有更高的准确度
总的来说,我对结果非常满意。我希望您能享受代码带来的乐趣:)
欢迎在这篇文章中提出您的问题,我会尽力回答。如果您能够改进代码,请在 github 上向我发送拉取请求。如果您在新的数据集或问题上使用基本代码,请发送电子邮件至 paras1987 <at> gmail <dot> com,我很乐意收到您的来信。
感谢 Nirant Kasliwal、Divyanshu Kalra 和 S. Adithya 审阅草案并提出有用的建议。
PS:我最近制作了一个 20 分钟的视频,介绍深度学习为何如此有效。现在就去观看吧!
参考资料:
- 一种神经网络,多种用途。使用单个模型构建图像搜索、图像字幕、相似词和相似图像
- 让深度神经网络绘画以了解它们是如何工作的。用 100 行 PyTorch 代码生成抽象艺术并探索神经网络的工作原理
- 通过机器学习为机器学习项目产生新想法。使用预先训练的语言模型从包含 2.5k 个句子的小语料库中生成特定于风格的文本。PyTorch 中的代码
- 无梯度强化学习:使用遗传算法进化代理。在 PyTorch 中实现深度神经进化来进化 CartPole 的代理 [代码 + 教程]
参考推文。帕拉斯·乔普拉