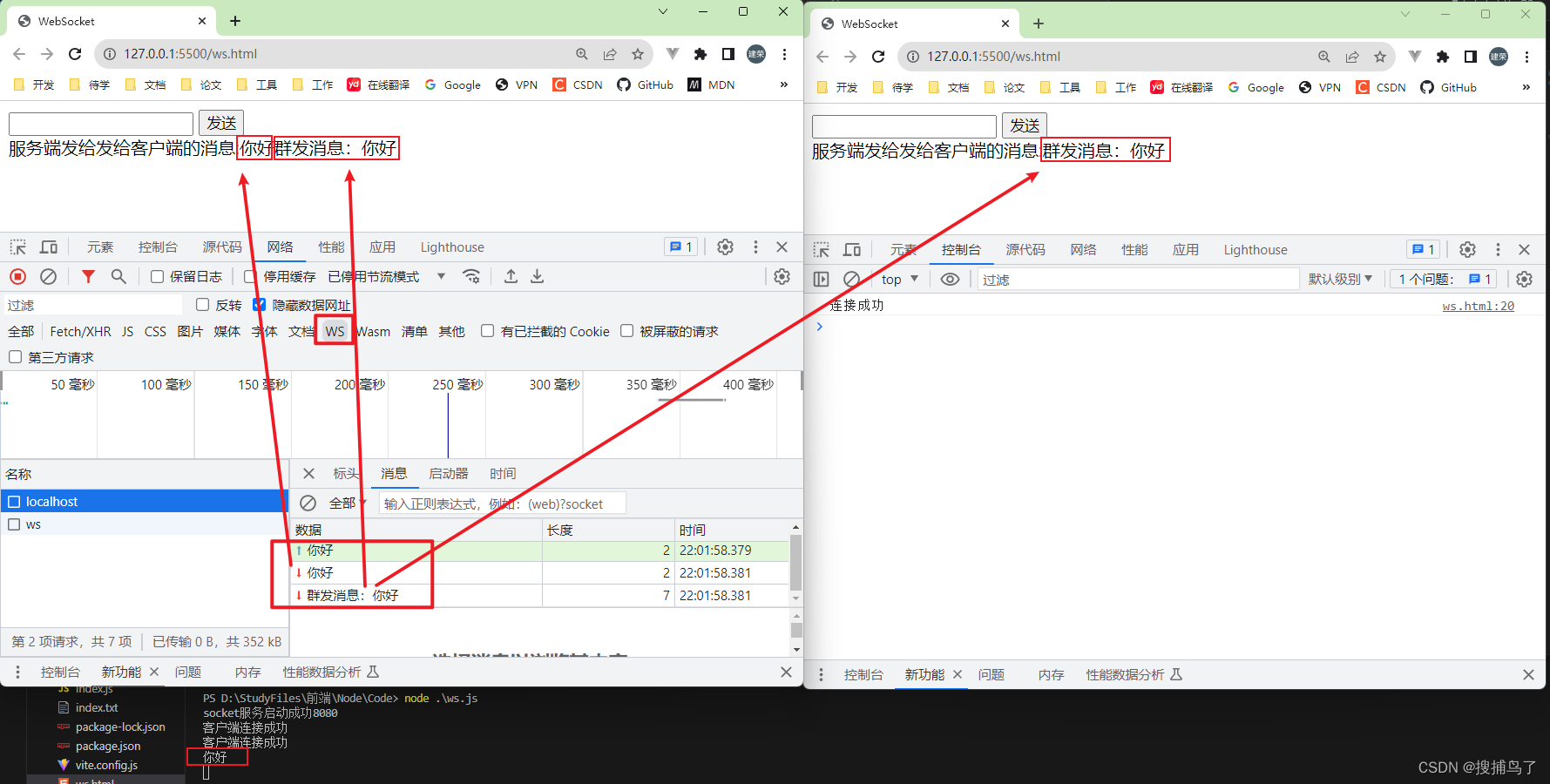
Patterns
图形模式匹配是Cypher的核心。它是一种用于通过应用声明性模式从图中导航、描述和提取数据的机制。在MATCH子句中,可以使用图模式定义要搜索的数据和要返回的数据。图模式匹配也可以在不使用MATCH子句的情况下在EXISTS、COUNT和COLLECT子查询中使用。
图模式使用类似于在白板上绘制属性图的节点和关系的语法来描述数据。在白板上,节点绘制为圆圈,关系绘制为箭头。Cypher将圆圈表示为一对括号,箭头表示为破折号和大于或小于符号: ()-->()<--()
这些节点和关系的简单模式构成了路径模式的构建块,可以匹配固定长度的路径。除了讨论简单的模式外,本章还将介绍更复杂的模式,展示如何匹配可变长度的模式,内联过滤器以提高查询性能,以及如何向路径模式添加循环和非线性形状。
概念
Node patterns
每个图模式至少包含一个节点模式。最简单的图形模式是单个空节点模式: MATCH ()。
空节点模式匹配属性图中的每个节点。为了获得对匹配节点的引用,需要在node模式中声明一个变量: MATCH (n)
通过这个变量引用,可以访问节点:MATCH (n) RETURN n.name
向节点模式添加Label表达式意味着只返回具有匹配标签的节点。MATCH (n:Stop)
更复杂模式:MATCH (n:(TrainStation&BusStation)|StationGroup)
属性名称和值的映射可用于基于与指定值的相等性来匹配节点属性。MATCH (n { mode: 'Rail' })
更一般的谓词可以用WHERE子句表示。MATCH (n:Station WHERE n.name STARTS WITH 'Preston')
Relationship patterns
最简单的关系模式: --。此模式匹配任何方向的关系,并且不过滤任何关系类型或属性。与节点模式不同,关系模式不能在两端没有节点模式的MATCH子句中使用。
为了获得对模式匹配的关系的引用,需要在模式中声明一个关系变量,方法是在破折号之间的方括号中添加变量名:-[r]-
为了匹配特定的方向,在左侧或右侧分别加上<或>: -[r]->
若要匹配关系类型,在冒号后添加类型名称: -[:CALLS_AT]->
与节点模式类似,可以添加属性名称和值的映射,以基于与指定值的相等性来过滤关系的属性: -[{ distance: 0.24, duration: 'PT4M' }]->。WHERE子句可以用于更一般的谓词: -[r WHERE time() + duration(r.duration) < time('22:00') ]->。
Path patterns
任何有效的路径都以一个节点开始和结束,每个节点之间都有关系(如果有多个节点)。路径模式具有相同的限制,对于所有有效的路径模式,以下条件为真:
-
它们至少有一个节点模式。
-
它们以节点模式开始和结束。
-
它们在节点和关系之间交替。
这些都是有效的路径模式:
()
(s)--(e)
(:Station)--()<--(m WHERE m.departs > time('12:00'))-->()-[:NEXT]->(n)
无效路径模式:
--> //无节点
()--> //尾部没有节点
()-->-->() //节点和关系之间无交替
路径模式匹配
Equijoins
等量连接是一种对路径的操作,它要求多个节点或路径之间的关系相同。通过在多个节点模式或关系模式中声明相同的变量来指定节点或关系之间的相等性。等量连接允许在路径模式中指定循环。
MATCH (n:Station {name: 'London Euston'})<-[:CALLS_AT]-(s1:Stop)-[:NEXT]->(s2:Stop)-[:CALLS_AT]->(:Station {name: 'Coventry'})<-[:CALLS_AT]-(s3:Stop)-[:NEXT]->(s4:Stop)-[:CALLS_AT]->(n)
RETURN s1.departs+'-'+s2.departs AS outbound,s3.departs+'-'+s4.departs AS `return`
量化路径模式
通过使用量化路径模式来匹配不同长度的路径,从而允许您搜索长度未知或在特定范围内的路径。
在搜索可从锚节点到达的所有节点、查找连接两个节点的所有路径,或者遍历可能具有不同深度的层次结构时,量化路径模式可能非常有用。
量化路径模式通过将路径模式的重复部分提取到括号中并应用量词来解决此问题。该量词指定要匹配的提取模式的可能重复范围。第一步是识别重复模式,
((:Stop)-[:NEXT]->(:Stop)){1,3}
(:Stop)-[:NEXT]->(:Stop) |
(:Stop)-[:NEXT]->(:Stop)(:Stop)-[:NEXT]->(:Stop) |
(:Stop)-[:NEXT]->(:Stop)(:Stop)-[:NEXT]->(:Stop)(:Stop)-[:NEXT]->(:Stop)这里的联合运算符(|)仅用于说明;以这种方式使用它不是Cypher语法的一部分。在上面的扩展中,如果两个节点模式彼此相邻,它们必须匹配相同的节点:服务的下一个部分从上一个部分结束的地方开始。因此,它们可以被重写为具有任何过滤条件组合的单节点模式。在本例中,这是微不足道的,因为应用于这些节点的过滤只是标签Stop:
MATCH (:Station { name: 'Denmark Hill' })<-[:CALLS_AT]-(d:Stop)((:Stop)-[:NEXT]->(:Stop)){1,3}(a:Stop)-[:CALLS_AT]->(:Station { name: 'Clapham Junction' })
RETURN d.departs AS departureTime, a.arrives AS arrivalTime
量化关系
量化关系允许以更简洁的方式重写一些简单的量化路径模式。
MATCH (d:Station { name: 'Denmark Hill' })<-[:CALLS_AT]-(n:Stop)((:Stop)-[:NEXT]->(:Stop)){1,10}(m:Stop)-[:CALLS_AT]->(a:Station { name: 'Clapham Junction' })
WHERE m.arrives < time('17:18')
RETURN n.departs AS departureTimeMATCH (d:Station { name: 'Denmark Hill' })<-[:CALLS_AT]-(n:Stop)-[:NEXT]->{1,10}(m:Stop)-[:CALLS_AT]->(a:Station { name: 'Clapham Junction' })
WHERE m.arrives < time('17:18')
RETURN n.departs AS departureTime
量词{1,10}的作用域是关系模式-[:NEXT]->,而不是与之相邻的节点模式。更一般地说,其中量化路径模式中包含的路径模式具有以下形式:
(() <relationship pattern> ()) <quantifier>
//可以简化为
<relationship pattern> <quantifier>
Group variables
顾名思义,这个属性表示两个站点之间的距离。为了返回连接一对station的每个服务的总距离,需要一个变量来引用所遍历的每个关系。类似地,要提取每个Stop的出发地和到达地属性,需要引用遍历的每个节点的变量。在这个在Denmark Hill和Clapham Junction之间匹配服务的示例中,变量l和m被声明为匹配stop, r被声明为匹配关系。变量origin只匹配路径中的第一个Stop:
MATCH (:Station { name: 'Denmark Hill' })<-[:CALLS_AT]-(origin)((l)-[r:NEXT]->(m)){1,3}()-[:CALLS_AT]->(:Station { name: 'Clapham Junction' })在量化路径模式中声明的变量称为组变量。之所以这样称呼它们,是因为当在量化路径模式之外引用时,它们是匹配中绑定到的节点或关系的列表。要理解如何考虑组变量绑定到节点或关系的方式,可以扩展量化路径模式,并观察不同变量如何匹配到整体匹配路径的元素。

(l1)-[r1:NEXT]->(m1) |
(l1)-[r1:NEXT]->(m1)(l2)-[r2:NEXT]->(m2) |
(l1)-[r1:NEXT]->(m1)(l2)-[r2:NEXT]->(m2)(l3)-[r3:NEXT]->(m3)
每个变量的下标表示它们属于路径模式重复的哪个实例。
l => [n2, n3, n4]
r => [r2, r3, r4]
m => [n3, n4, n5]
最短路径
MATCH p = shortestPath((hby)-[:LINK*]-(cnm))
WHERE hby.name = 'Hartlebury' AND cnm.name = 'Cheltenham Spa'
RETURN [n in nodes(p) | n.name] AS stopsMATCH p = shortestPath((hby)-[:LINK*]-(cnm))
WHERE all(link in relationships(p) WHERE link.distance < 20) ANDhby.name = 'Hartlebury' AND cnm.name = 'Cheltenham Spa'
RETURN [n in nodes(p) | n.name] AS stopsMATCH p = allShortestPaths((hby)-[link:LINK*]-(psh))
WHERE hby.name = 'Hartlebury' AND psh.name = 'Pershore'
RETURN [n in nodes(p) | n.name] AS stops
量化路径模式断言
primer
语法和语义
//节点模式
nodePattern ::= "(" [ nodeVariable ] [ labelExpression ][ propertyKeyValueExpression ] [ "WHERE" booleanExpression ] ")"//关系模式
relationshipPattern ::= fullPattern | abbreviatedRelationshipfullPattern ::="<-[" patternFiller "]-"| "-[" patternFiller "]->"| "-[" patternFiller "]-"abbreviatedRelationship ::= "<--" | "--" | "-->"patternFiller ::= [ relationshipVariable ] [ typeExpression ][ propertyKeyValueExpression ] [ "WHERE" booleanExpression ]//Lable 表达式
labelExpression ::= ":" labelTerm
//
labelTerm ::=labelIdentifier| labelTerm "&" labelTerm| labelTerm "|" labelTerm| "!" labelTerm| "%"| "(" labelTerm ")"
//
propertyKeyValueExpression ::="{" propertyKeyValuePairList "}"propertyKeyValuePairList ::=propertyKeyValuePair [ "," propertyKeyValuePair ]propertyKeyValuePair ::= propertyName ":" valueExpression
//
pathPattern ::= [{ simplePathPattern | quantifiedPathPattern }]+simplePathPattern ::= nodePattern[ { relationshipPattern | quantifiedRelationship } nodePattern ]*quantifiedPathPattern ::="(" fixedPath [ "WHERE" booleanExpression ] ")" quantifierfixedPath ::= nodePattern [ relationshipPattern nodePattern ]+ quantifiedRelationship ::= relationshipPattern quantifier
Quantifiers
quantifier ::="*" | "+" | fixedQuantifier | generalQuantifier
fixedQuantifier ::= "{" unsignedInteger "}"
generalQuantifier ::= "{" lowerBound "," upperBound "}"
lowerBound ::= unsignedInteger
upperBound ::= unsignedInteger
unsignedInteger ::= [0-9]+
| Variant | Canonical form | Description |
|---|---|---|
{m,n} | {m,n} | Between m and n iterations. |
+ | {1,} | 1 or more iterations. |
* | {0,} | 0 or more iterations. |
{n} | {n,n} | Exactly n iterations. |
{m,} | {m,} | m or more iterations. |
{,n} | {0,n} | Between 0 and n iterations. |
{,} | {0,} | 0 or more iterations. |
请注意,带有量词{1}的量化路径模式不等同于固定长度的路径模式。尽管最终的量化路径模式将与其中包含的固定长度路径在没有量词的情况下匹配,但量词的存在意味着路径模式中的所有变量都将作为组变量公开。
Graph patterns
graphPattern ::=pathPattern [ "," pathPattern ]* [ "WHERE" booleanExpression ]
Node pattern pairs
编写一对相邻的节点模式是无效的语法。例如,以下所有操作都会引发语法错误:
然而,相邻的节点模式对的放置是有效的,它间接来自于量化路径模式的扩展。
量化路径模式迭代
当一个量化的路径模式被展开时,包含在其括号中的固定路径模式被重复和链接。这导致成对的节点模式彼此相邻。
((x:X)<--(y:Y)){3}
通过重复三次固定路径模式(x: x)←-(y: y)来扩展它,并在变量上添加索引以表明没有隐含的等量连接
(x1:X)<--(y1:Y)(x2:X)<--(y2:Y)(x3:X)<--(y3:Y)
结果是两对节点模式最终彼此相邻,(y1:Y)(x2:X)和(y2:Y)(x3:X)。在匹配过程中,每对节点模式将匹配相同的节点,这些节点将满足节点模式中谓词的连接。例如,在第一对中,y1和x2将绑定到同一个节点,并且该节点必须具有X和y的标签。这种扩展和绑定如下图所示:
简单路径模式和量化路径模式
量化路径模式对
当两个量化路径模式相邻时,第一模式的最后一次迭代的最右节点与第二模式的第一次迭代的最左节点合并。例如,以下相邻的模式:
((:A)-[:R]->(:B)){2} ((:X)<--(:Y)){1,2}
将匹配与以下两个路径模式匹配的路径的并集相同的路径集:
(:A)-[:R]->(:B&A)-[:R]->(:B&X)<--(:Y)
(:A)-[:R]->(:B&A)-[:R]->(:B&X)<--(:Y&X)<--(:Y)
零迭代
如果量词允许模式的零次迭代,例如{0,3},那么该模式的第0次迭代将导致两边的节点模式配对。
(:X) ((a:A)-[:R]->(b:B)){0,1} (:Y)
//匹配
(:X&Y) // 节点具有X,Y标签
(:X&A)-[:R]->(:B&Y)
变长关系
在Neo4j 5.9中引入量化路径模式和量化关系的语法之前,Cypher中匹配可变长度路径的唯一方法是使用可变长度关系。这个语法仍然可用。
| Variant | Description |
|---|---|
* | 1 or more iterations. |
*n | Exactly n iterations. |
*m..n | Between m and n iterations. |
*m.. | m or more iterations. |
*..n | Between 1 and n iterations. |
| Variable-length relationship | Equivalent quantified path pattern |
|---|---|
(a)-[*2]->(b) | (a) (()-[]->()){2,2} (b) |
(a)-[:KNOWS*3..5]->(b) | (a) (()-[:KNOWS]->()){3,5} (b) |
(a)-[r*..5 {name: 'Filipa'}]->(b) | (a) (()-[r {name: 'Filipa'}]->()){1,5} (b) |
可变长度关系的变量可以在后续模式中使用,以引用该变量绑定到的关系列表。这与绑定到单个节点或关系的变量的等量连接相同。
值和类型
Cypher支持一系列数据值。在编写Cypher查询时,不可能声明数据类型。相反,Cypher将自动推断给定值的数据类型。
Property types
属性类型:BOOLEAN、DATE、DURATION、FLOAT、INTEGER、LIST、LOCAL DATETIME、LOCAL TIME、POINT、STRING、ZONED DATETIME和ZONED TIME。
-
属性类型可以从Cypher查询返回。
-
属性类型可以用作参数。
-
属性类型可以存储为属性。
-
属性类型可以用Cypher字面值构造。
简单类型的同构列表可以存储为属性,但一般列表(请参阅构造类型)不能存储为属性。作为属性存储的列表不能包含空值。
Cypher还提供了对字节数组的传递支持,字节数组可以作为属性值存储。由于性能原因,支持字节数组,因为使用Cypher的泛型LIST(其中每个INTEGER都有64位表示)的成本太高。但是,字节数组不被Cypher视为第一类数据类型,因此它们没有文字表示。
结构类型
结构类型:NODE、RELATIONSHIP和PATH。
-
结构类型可以从Cypher查询返回。
-
结构类型不能用作参数。
-
结构类型不能存储为属性。
-
结构类型不能用Cypher字面值构造。
NODE数据类型包括:id、label(s)和属性映射。注意标签不是值,而是模式语法的一种形式。
RELATIONSHIP数据类型包括:id、关系类型、属性映射、开始节点id和结束节点id。
PATH数据类型是节点和关系的交替序列。
构造类型
构造类型中:LIST和MAP。
-
可以从Cypher查询返回构造类型。
-
构造类型可以用作参数。
-
构造的类型不能存储为属性(同构列表除外)。
-
构造类型可以用Cypher字面值构造。
LIST数据类型可以是简单值的同构集合,也可以是异构的有序值集合,每个值都可以具有任何属性、结构类型或构造类型。
MAP数据类型是(键、值)对的异构、无序集合,其中键是文字,而值可以具有任何属性、结构类型或构造类型。
构造类型值也可以包含null。
类型同义词
| Type | Synonyms |
|---|---|
ANY | ANY VALUE |
BOOLEAN | BOOL |
DATE | |
DURATION | |
FLOAT | |
INTEGER | INT, SIGNED INTEGER |
LIST<INNER_TYPE> | ARRAY<INNER_TYPE>, INNER_TYPE LIST, INNER_TYPE ARRAY |
LOCAL DATETIME | TIMESTAMP WITHOUT TIMEZONE |
LOCAL TIME | TIME WITHOUT TIMEZONE |
MAP | |
NODE | ANY NODE, VERTEX, ANY VERTEX |
NOTHING | |
NULL | |
PATH | |
POINT | |
PROPERTY VALUE | ANY PROPERTY VALUE |
RELATIONSHIP | ANY RELATIONSHIP, EDGE, ANY EDGE |
STRING | VARCHAR |
ZONED DATETIME | TIMESTAMP WITH TIMEZONE |
ZONED TIME | TIME WITH TIMEZONE |
所有Cypher类型都包含空值。要使它们不可为空,可以将not NULL附加到类型的末尾(例如BOOLEAN not NULL, LIST<FLOAT not NULL>)。
属性类型明细
| Type | Min. value | Max. value | Precision |
|---|---|---|---|
BOOLEAN | False | True | - |
DATE | -999_999_999-01-01 | +999_999_999-12-31 | Days |
DURATION | P-292471208677Y-6M-15DT-15H-36M-32S | P292471208677Y6M15DT15H36M32.999999999S | Nanoseconds |
FLOAT | Double.MIN_VALUE [1] | Double.MAX_VALUE | 64 bit |
INTEGER | Long.MIN_VALUE | Long.MAX_VALUE | 64 bit |
LOCAL DATETIME | -999_999_999-01-01T00:00:00 | +999_999_999-12-31T23:59:59.999999999 | Nanoseconds |
LOCAL TIME | 00:00:00 | 23:59:59.999999999 | Nanoseconds |
POINT | Cartesian: (-Double.MAX_VALUE, -Double.MAX_VALUE)Cartesian_3D: (-Double.MAX_VALUE, -Double.MAX_VALUE, -Double.MAX_VALUE)WGS_84: (-180, -90)WGS_84_3D: (-180, -90, -Double.MAX_VALUE) | Cartesian: (Double.MAX_VALUE, Double.MAX_VALUE)Cartesian_3D: (Double.MAX_VALUE, Double.MAX_VALUE, Double.MAX_VALUE)WGS_84: (180, 90)WGS_84_3D: (180, 90, Double.MAX_VALUE) | The precision of each coordinate of the POINT is 64 bit as they are floats. |
STRING | - | - | - |
ZONED DATETIME | -999_999_999-01-01T00:00:00+18:00 | +999_999_999-12-31T23:59:59.999999999-18:00 | Nanoseconds |
ZONED TIME | 00:00:00+18:00 | 23:59:59.999999999-18:00 | Nanoseconds |
时间类型
| Type | Date support | Time support | Time zone support |
|---|---|---|---|
DATE | √ | ||
LOCAL TIME | √ | ||
ZONED TIME | √ | √ | |
LOCAL DATETIME | √ | √ | |
ZONED DATETIME | √ | √ | √ |
DURATION | - | - | - |
相比之下,DURATION不是即时类型。DURATION表示时间量,捕获两个瞬间之间的时间差,并且可以为负值。
新的版本,类型名字有所改变
| Type | Old type name |
|---|---|
DATE | Date |
LOCAL TIME | LocalTime |
ZONED TIME | Time |
LOCAL DATETIME | LocalDateTime |
ZONED DATETIME | DateTime |
DURATION | Duration |
空间类型
null操作
逻辑操作
逻辑运算符(AND、OR、XOR、NOT)将null作为三值逻辑的未知值。
| a | b | a AND b | a OR b | a XOR b | NOT a |
|---|---|---|---|---|---|
false | false | false | false | false | true |
false | null | false | null | null | true |
false | true | false | true | true | true |
true | false | false | true | true | false |
true | null | null | true | null | false |
true | true | true | true | false | false |
null | false | false | null | null | null |
null | null | null | null | null | null |
null | true | null | true | null | null |
总结:
AND:只要有一个为false,则为false。OR:只要有一个为true,则为true。
IN
IN操作符遵循类似的逻辑。如果Cypher可以确定列表中存在某物,则结果将为真。任何包含null且没有匹配元素的列表都将返回null。否则,结果将为false。
| Expression | Result |
|---|---|
2 IN [1, 2, 3] | true |
2 IN [1, null, 3] | null |
2 IN [1, 2, null] | true |
2 IN [1] | false |
2 IN [] | false |
null IN [1, 2, 3] | null |
null IN [1, null, 3] | null |
null IN [] | false |
使用all、any、none和single遵循类似的规则。如果结果可以确定地计算出来,则返回true或false。否则将产生null。
[ ]
访问带有null的list或map将返回null
返回null的表达式
-
从列表中获取缺失的元素:
[][0],head([])。 -
试图访问节点或关系上不存在的属性:
n.missingProperty。 -
当任何一方为空时的比较:1 < null。
-
包含null的算术表达式:1 + null。
-
某些函数调用的任何参数都为空:例如,sin(null)。
LIST
RETURN [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] AS list
RETURN range(0, 10)[3] AS element //range创建LIST
RETURN range(0, 10)[-3] AS element //下标支持负数
RETURN range(0, 10)[0..3] AS list //切片
RETURN range(0, 10)[0..-5] AS list //
RETURN range(0, 10)[-5..] AS list //
RETURN range(0, 10)[..4] AS list //
RETURN range(0, 10)[15] AS list //超过索引的单个元素返回null。
RETURN range(0, 10)[5..15] AS list //超过索引的LIST 元素截断。
MAP
RETURN {key: 'Value', listKey: [{inner: 'Map1'}, {inner: 'Map2'}]}Map 投影
Cypher支持Map投影,它允许从节点、关系和其他Map值构造Map投影。
Map投影以绑定到要进行投影的图形实体的变量开始,并包含一组逗号分隔的映射元素,由{和}括起来。
map_variable {map_element, [, ...n]}
MAP投影将一个或多个键值对投影到MAP投影。有四种不同类型的MAP投影元素:
-
属性选择器:将属性名称作为键进行投影,并将map_variable中的值作为投影的值。
-
字面量实体 :这是一个键值对,值是一个任意的表达式键:
<expression>。 -
变量选择器:投影一个变量,变量名作为键,变量指向的值作为投影的值。它的语法就是变量。
-
所有属性选择器:从map_variable值投射所有键值对。
-
如果map_variable指向null,则整个MAP投影的值将为null。
-
映射中的键名必须是
STRING类型。
MATCH (keanu:Person {name: 'Keanu Reeves'})-[:ACTED_IN]->(movie:Movie)
WITH keanu, collect(movie{.title, .released}) AS movies
RETURN keanu{.name, movies: movies} // name属性作为一个元素,movies字面量,作为KEY, movies变量作为VALUE,是个LIST
| keanu |
|---|
{movies: [{title: "The Devils Advocate", released: 1997}, {title: "The Matrix Revolutions", released: 2003}, {title: "The Matrix Resurrections", released: 2021}, {title: "The Matrix Reloaded", released: 2003}, {title: "The Matrix", released: 1999}], name: "Keanu Reeves"} |
| Rows: 1 |
类型转换
参考 Functions
附录
参考
https://neo4j.com/docs/cypher-manual/current/patterns/
https://neo4j.com/docs/cypher-manual/current/values-and-types/
https://neo4j.com/docs/cypher-manual/current/functions/
![[JavaScript游戏开发] Q版地图上让英雄、地图都动起来](https://img-blog.csdnimg.cn/725ebb89254c46589848d4a6335abbd6.png)