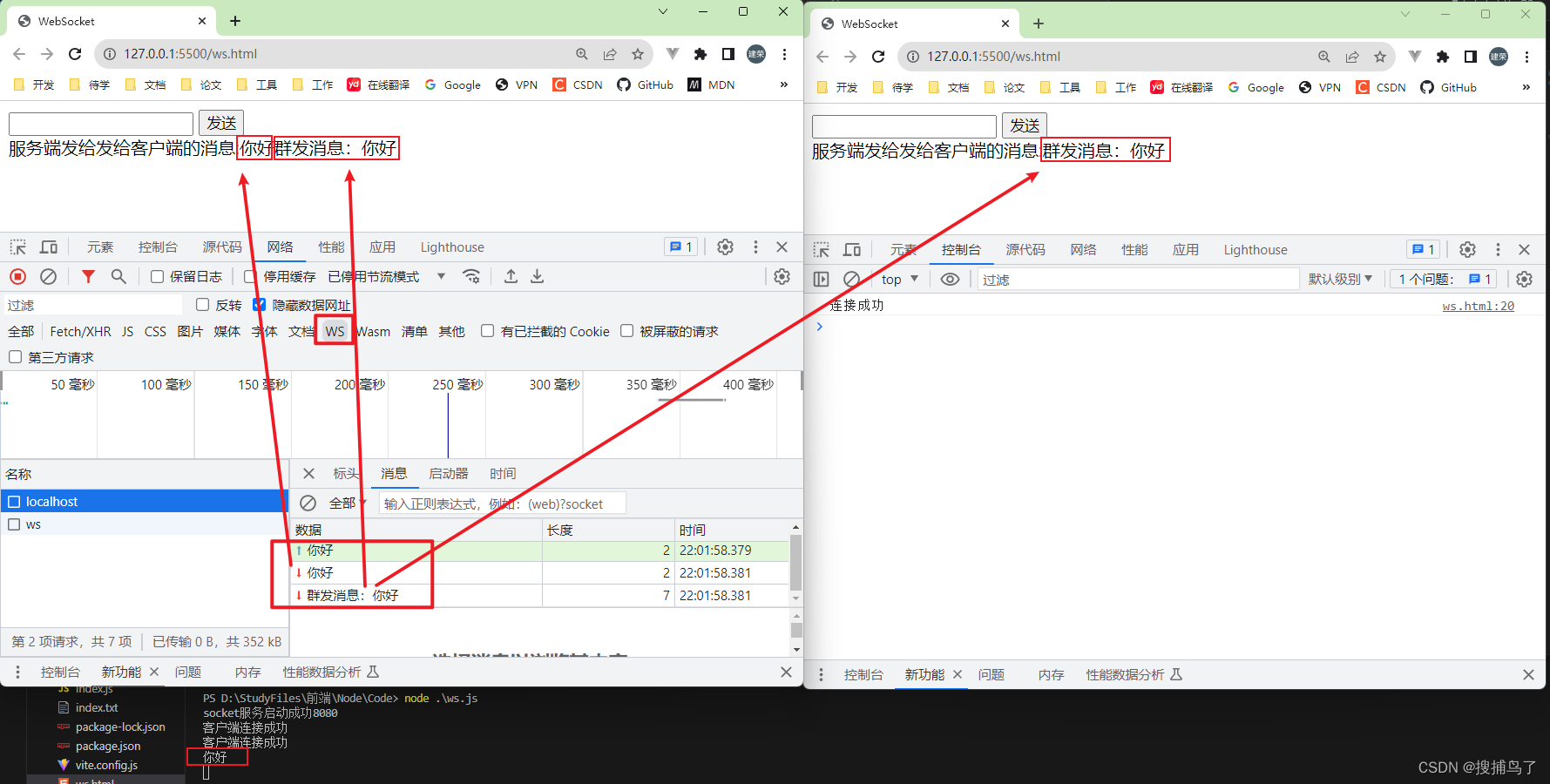
经验回放:Experience Replay(训练DQN的一种策略)
优点:可以重复利用离线经验数据;连续的经验具有相关性,经验回放可以在离线经验BUFFER随机抽样,减少相关性;
超参数:Replay Buffer的长度;
∙ Find w by minimizing L ( w ) = 1 T ∑ t = 1 T δ t 2 2 . ∙ Stochastic gradient descent (SGD): ∙ Randomly sample a transition, ( s i , a i , r i , s i + 1 ) , from the buffer ∙ Compute TD error, δ i . ∙ Stochastic gradient: g i = ∂ δ i 2 / 2 ∂ w = δ i ⋅ ∂ Q ( s i , a i ; w ) ∂ w ∙ SGD: w ← w − α ⋅ g i . \begin{aligned} &\bullet\text{ Find w by minimizing }L(\mathbf{w})=\frac{1}{T}\sum_{t=1}^{T}\frac{\delta_{t}^{2}}{2}. \\ &\bullet\text{ Stochastic gradient descent (SGD):} \\ &\bullet\text{ Randomly sample a transition, }(s_i,a_i,r_i,s_{i+1}),\text{from the buffer} \\ &\bullet\text{ Compute TD error, }\delta_i. \\ &\bullet\text{ Stochastic gradient: g}_{i}=\frac{\partial\delta_{i}^{2}/2}{\partial \mathbf{w}}=\delta_{i}\cdot\frac{\partial Q(s_{i},a_{i};\mathbf{w})}{\partial\mathbf{w}} \\ &\bullet\text{ SGD: w}\leftarrow\mathbf{w}-\alpha\cdot\mathbf{g}_i. \end{aligned} ∙ Find w by minimizing L(w)=T1t=1∑T2δt2.∙ Stochastic gradient descent (SGD):∙ Randomly sample a transition, (si,ai,ri,si+1),from the buffer∙ Compute TD error, δi.∙ Stochastic gradient: gi=∂w∂δi2/2=δi⋅∂w∂Q(si,ai;w)∙ SGD: w←w−α⋅gi.
注:实践中通常使用minibatch SGD,每次抽取多个经验,计算小批量随机梯度;
Replay Buffer代码实现如下:
@dataclass
class ReplayBuffer:maxsize: intsize: int = 0state: list = field(default_factory=list)action: list = field(default_factory=list)next_state: list = field(default_factory=list)reward: list = field(default_factory=list)done: list = field(default_factory=list)def push(self, state, action, reward, done, next_state):""":param state: 状态:param action: 动作:param reward: 奖励:param done::param next_state:下一个状态:return:"""if self.size < self.maxsize:self.state.append(state)self.action.append(action)self.reward.append(reward)self.done.append(done)self.next_state.append(next_state)else:position = self.size % self.maxsizeself.state[position] = stateself.action[position] = actionself.reward[position] = rewardself.done[position] = doneself.next_state[position] = next_stateself.size += 1def sample(self, n):total_number = self.size if self.size < self.maxsize else self.maxsizeindices = np.random.randint(total_number, size=n)state = [self.state[i] for i in indices]action = [self.action[i] for i in indices]reward = [self.reward[i] for i in indices]done = [self.done[i] for i in indices]next_state = [self.next_state[i] for i in indices]return state, action, reward, done, next_state训练时的代码如下:
离线数据放到BUFFER里面:
#动作、状态、奖励、结束标志、下一状态
replay_buffer.push(state, action, reward, done, next_state)
训练时采样然后计算损失
bs, ba, br, bd, bns = replay_buffer.sample(n=args.batch_size)
bs = torch.tensor(bs, dtype=torch.float32)
ba = torch.tensor(ba, dtype=torch.long)
br = torch.tensor(br, dtype=torch.float32)
bd = torch.tensor(bd, dtype=torch.float32)
bns = torch.tensor(bns, dtype=torch.float32)loss = agent.compute_loss(bs, ba, br, bd, bns)
loss.backward()
optimizer.step()
optimizer.zero_grad()