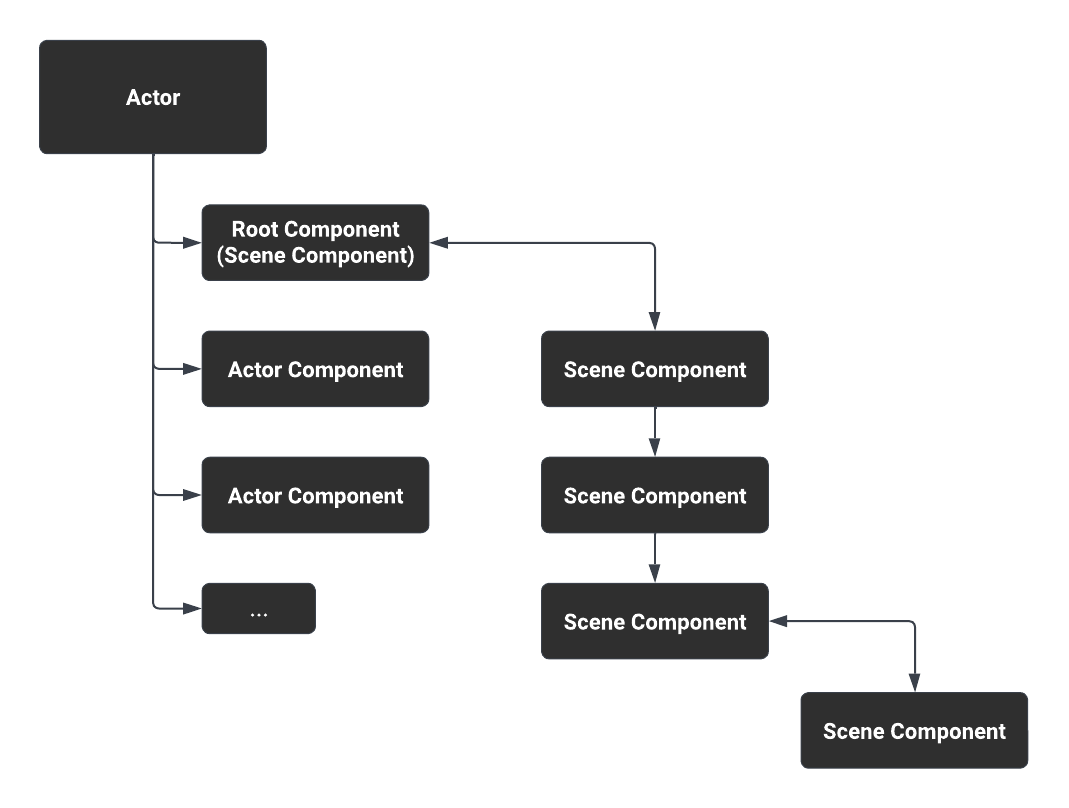
随着人工智能技术的飞速发展,大型语言模型(LLMs)已经成为自然语言处理领域的明星。它们以其庞大的知识库和生成连贯、上下文相关文本的能力,极大地推动了研究、工业和社会的进步。然而,这些模型在生成文本时可能会产生所谓的“幻觉”——即生成看似合理但事实上错误或无意义的信息。这种现象不仅引起了对安全性和伦理性的担忧,也对LLMs的可靠性提出了挑战。本文将深入探讨LLMs消除幻觉的一些解决方法,并基于新加坡国立大学学者Ziwei Xu、Sanjay Jain和Mohan Kankanhalli的研究,提出一系列切实可行的策略。
《Hallucination is Inevitable: An Innate Limitation of Large Language Models》
幻觉:LLMs的阿喀琉斯之踵
幻觉问题是指LLMs在没有足够证据支持的情况下生成虚假信息。这种现象在自然语言生成中尤为突出,其原因可以归结为数据收集、模型训练和推理等多个方面。例如,数据质量问题、训练策略的缺陷、注意力机制的局限性等都可能导致幻觉的产生。
幻觉的分类
幻觉可以根据其表现和成因分为不同类型。从现象上看,可以分为内在型和外在型;从成因上看,可以归因于数据、训练和推理阶段的问题。例如,内在型幻觉发生在模型输出与给定输入相矛盾时,而外在型幻觉则发生在模型输出无法通过输入信息验证时。
幻觉的不可避免性
Xu等人在论文中提出了一个关键观点:幻觉在LLMs中是不可避免的。他们通过形式化定义和学习理论的应用,证明了即使在理想情况下,LLMs也无法完全学习所有可计算函数,因此总会有幻觉发生。这一发现对于LLMs的设计和应用具有深远的影响。
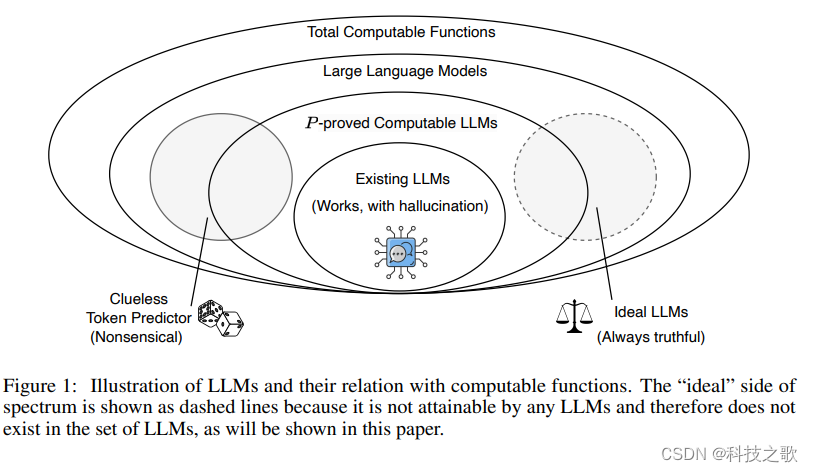
消除幻觉的策略
尽管幻觉不可避免,但研究人员已经提出了多种方法来减少幻觉的发生,并提高LLMs的输出质量。
1. 扩大模型规模和训练数据
一种直观的策略是增加模型的参数数量和训练数据的规模。更大的模型理论上能够捕捉更复杂的函数,而更多的训练数据可以帮助模型更好地泛化。然而,这种方法并不能保证完全消除幻觉,特别是对于那些模型能力范围之外的问题。
2. 改进模型架构
改进模型架构,如调整注意力机制或使用不同的网络层,可以减少幻觉的发生。例如,通过优化softmax函数来解决注意力稀释问题,或通过增强模型的逻辑推理能力来提高输出的准确性。
3. 使用提示技术
提示技术,如Chain-of-Thought或Tree-of-Thought,通过在模型输入中提供解决问题的示例或相关知识,引导模型朝着更合理的解决方案发展。这种方法在特定任务上表现出了减少幻觉的效果。
4. 模型集成
集成多个LLMs的输出,通过投票或共识来生成最终答案。这种方法利用了不同模型可能提供不同视角的优势,以减少个体模型的幻觉倾向。
5. 利用外部知识
结合外部知识库,如知识图谱或数据库,以及符号推理方法,可以在训练和推理过程中为模型提供额外的信息。这种方法可以帮助模型在缺乏内部知识的情况下做出更准确的判断。
6. 设计基准测试和度量标准
开发针对幻觉的基准测试和度量标准,可以帮助研究人员和开发者更好地评估和比较不同模型在减少幻觉方面的效果。
7. 实施安全约束
为LLMs设置安全约束,如guardrails和fences,确保模型的输出不会偏离人类价值观、伦理和法律要求。
未来展望
尽管当前的LLMs在消除幻觉方面存在限制,随着模型架构的优化、训练技术的改进和错误校正策略的发展,LLMs的幻觉问题将得到更好的控制和减轻。通过深入理解幻觉的成因和机制,以及积极寻求减少幻觉的策略,我们可以更安全、更有效地利用这些强大的工具,推动人工智能技术的进一步发展。
此外,幻觉现象也不应被完全视为负面。在艺术、文学和设计等领域,LLMs的非预期输出可能激发人类的创造力,成为灵感和创新的源泉。LLMs作为人工智能领域的重要成果,其发展和应用前景广阔。