这里写目录标题
- 1. 为什么test
- 2. 如何做test
- 3. 什么时候做test
- 4. 完整代码
1. 为什么test
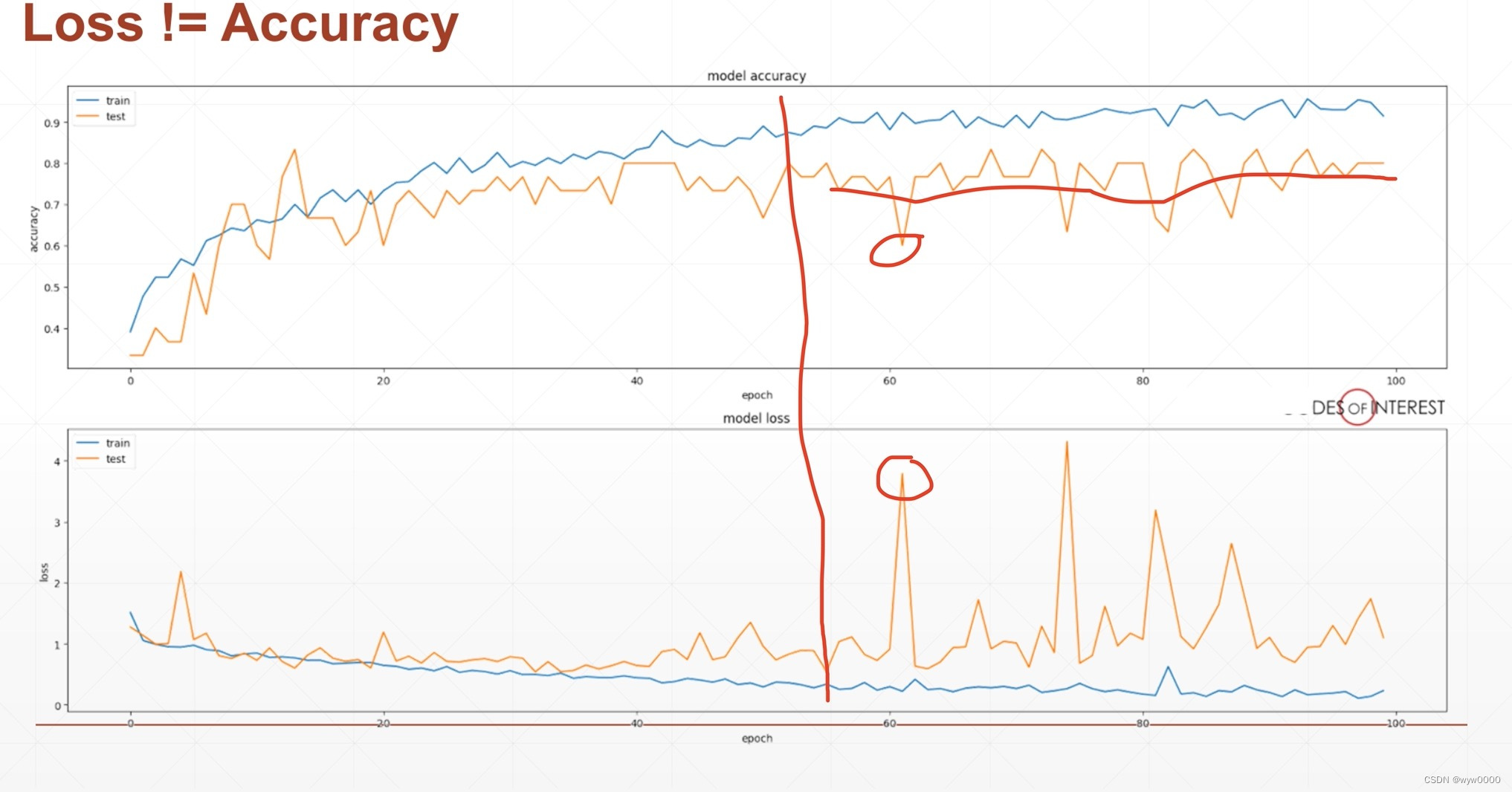
如下图:上下两幅图中蓝色分别表示train的accuracy和loss,黄色表示test的accuracy和loss,如果单纯看train的accuracy和loss曲线就会认为模型已经train的很好了,accuracy一直在上升接近于1了,loss一直在下降已经接近于0了,殊不知此时可能已经出现了over fitting(本数据集准确率很高,其他数据准确率很低),此时就需要test了,从图中可以看出test在红色划线右侧的accuracy已经不变甚至下降了,loss曲线波动也比较大,甚至已经上升了。
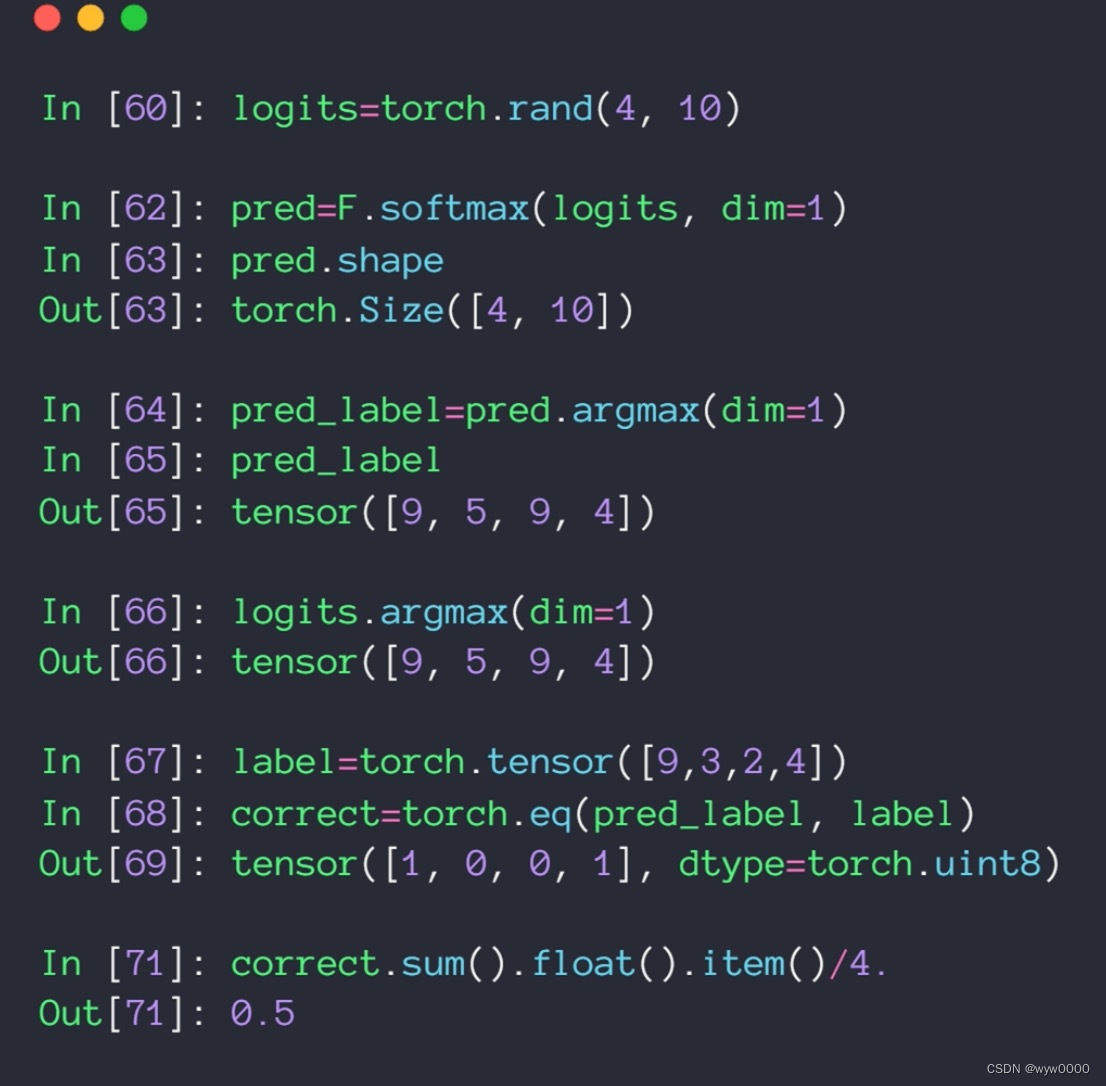
2. 如何做test
如下图所示:
argmax找出概率最大的数字的index
softmax在这里使用与不使用结果是一样的,因为softmax不改变单调性(大的依然大,小的依然小)
使用torch.eq计算预测值与目标值是否相当,相等返回1不等返回0
correct.sum().float().item() /4是用来计算accuracy的,其他sum()是计算正确的个数,item是tensor转bumpy; /4是除以总样本数
3. 什么时候做test
- 每几个batch做一次
- 一个epoch做一次
注意:为什么不一个batch做一次test呢?因为test的数据可能也比较大,每个batch都test会影响train的速度
4. 完整代码
从一下代码可知,test是一个epoch做一次,首先像train一样load test数据,并搬到GPU中,然后数据输入到网络中,计算loss,最后计算准确了并打印输出
python">import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transformsbatch_size=200
learning_rate=0.01
epochs=10train_loader = torch.utils.data.DataLoader(datasets.MNIST('../data', train=True, download=True,transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))])),batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(datasets.MNIST('../data', train=False, transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))])),batch_size=batch_size, shuffle=True)class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.model = nn.Sequential(nn.Linear(784, 200),nn.LeakyReLU(inplace=True),nn.Linear(200, 200),nn.LeakyReLU(inplace=True),nn.Linear(200, 10),nn.LeakyReLU(inplace=True),)def forward(self, x):x = self.model(x)return xdevice = torch.device('cuda:0')
net = MLP().to(device)
optimizer = optim.SGD(net.parameters(), lr=learning_rate)
criteon = nn.CrossEntropyLoss().to(device)for epoch in range(epochs):for batch_idx, (data, target) in enumerate(train_loader):data = data.view(-1, 28*28)data, target = data.to(device), target.cuda()logits = net(data)loss = criteon(logits, target)optimizer.zero_grad()loss.backward()# print(w1.grad.norm(), w2.grad.norm())optimizer.step()if batch_idx % 100 == 0:print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(epoch, batch_idx * len(data), len(train_loader.dataset),100. * batch_idx / len(train_loader), loss.item()))test_loss = 0correct = 0for data, target in test_loader:data = data.view(-1, 28 * 28)data, target = data.to(device), target.cuda()logits = net(data)test_loss += criteon(logits, target).item()pred = logits.argmax(dim=1)correct += pred.eq(target).float().sum().item()test_loss /= len(test_loader.dataset)print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(test_loss, correct, len(test_loader.dataset),100. * correct / len(test_loader.dataset)))