文章目录
前言
由于误操作、代码 bug 或平台误点,我们在操作数据时难免会遇到数据丢失的情况,比如一条 delete 删除了预期之外的数据。早期想要恢复数据,只能通过 全量备份 + 日志备份 恢复数据或业务人员通过日志以及业务逻辑进行手动订正,这些恢复数据的方法影响其恢复速度的变量很多,全量备份如果数据量很大,上传和解压缩的耗时很久,还要考虑增量日志应用。手动订正数据量大业务逻辑复杂的话,是一件非常消耗人力的事情,且容易出错。直到出现 Binlog 闪回技术,大大的提升了 DML 造成数据丢失的恢复速度。
本篇文章,将带你了解 SQL 闪回的三种方法,以及 Binlog 分析方法等。
1. 修改 event 实现闪回
这是一种可以将 delete 操作转换为 insert 操作的一种方法。MySQL binlog 中使用 type_code 来标记 binlog 的事件,例如一个 delete 操作会使用 32 来标记,一个 insert 操作会使用 30 来标记。通过将 delete 事件 type_code 32 修改为 30 就可以将一个删除操作转换为插入操作,就可以回滚 delete 误操作的数据。
该方法需要对 Binlog 的结构有了解,下面介绍一些相关知识。
PS:本文所有的演示,要求的 Binlog 参数配置如下:
binlog_format = ROW
binlog_row_image = FULL
1.1 binlog 结构
binlog 日志为 MySQL 记录数据库变化的日志,主要应用于主从复制和配合其它工具实现数据恢复。binlog 文件分为两类,其中一类为 mysql-bin.00000n 里面记录的是 binlog 事件,另一类为 mysql-bin.index 为 MySQL 二进制日志的索引文件,负责跟踪服务器上所有的 binlog 文件以便必要时可以正确的创建新的 binlog 文件。
每一个 binlog 文件由若干个 binlog 事件组成,以 Format_description(格式描述事件)作为文件头,以 Rotate(日志轮换事件)作为文件尾。除了控制事件,binlog 中其它事件被分为组,在事务存储引擎中,每个事务就是一个组,但是对于非事物存储引擎每条 SQL 语句就是一个组。
从 MySQL 5+ 版本开始,Binlog 采用的是 v4 版本。事件的类型根据 MySQL 的内部文档,有下面 36 类:
enum Log_event_type { UNKNOWN_EVENT= 0, START_EVENT_V3= 1, QUERY_EVENT= 2, STOP_EVENT= 3, ROTATE_EVENT= 4, INTVAR_EVENT= 5, LOAD_EVENT= 6, SLAVE_EVENT= 7, CREATE_FILE_EVENT= 8, APPEND_BLOCK_EVENT= 9, EXEC_LOAD_EVENT= 10, DELETE_FILE_EVENT= 11, NEW_LOAD_EVENT= 12, RAND_EVENT= 13, USER_VAR_EVENT= 14, FORMAT_DESCRIPTION_EVENT= 15, XID_EVENT= 16, BEGIN_LOAD_QUERY_EVENT= 17, EXECUTE_LOAD_QUERY_EVENT= 18, TABLE_MAP_EVENT = 19, PRE_GA_WRITE_ROWS_EVENT = 20, PRE_GA_UPDATE_ROWS_EVENT = 21, PRE_GA_DELETE_ROWS_EVENT = 22, WRITE_ROWS_EVENT = 23, UPDATE_ROWS_EVENT = 24, DELETE_ROWS_EVENT = 25, INCIDENT_EVENT= 26, HEARTBEAT_LOG_EVENT= 27, IGNORABLE_LOG_EVENT= 28,ROWS_QUERY_LOG_EVENT= 29,WRITE_ROWS_EVENT = 30,UPDATE_ROWS_EVENT = 31,DELETE_ROWS_EVENT = 32,GTID_LOG_EVENT= 33,ANONYMOUS_GTID_LOG_EVENT= 34,PREVIOUS_GTIDS_LOG_EVENT= 35, ENUM_END_EVENT /* end marker */
};
Binlog 日志由多个 event 组成,一个 event 分为 header 和 data 两部分,通过解析 header 事件就可以知道该事件的类型和长度。
+=====================================+
| event | timestamp 0 : 4 |
| header +----------------------------+
| | type_code 4 : 1 |
| +----------------------------+
| | server_id 5 : 4 |
| +----------------------------+
| | event_length 9 : 4 |
| +----------------------------+
| | next_position 13 : 4 |
| +----------------------------+
| | flags 17 : 2 |
| +----------------------------+
| | extra_headers 19 : x-19 |
+=====================================+
| event | fixed part x : y |
| data +----------------------------+
| | variable part |
+=====================================+
下面为我们使用 mysqlbinlog --hexdump 转换为十六进制的 binlog 可以看到 event_type 为 1e 转换为十进制为 1e(十六进制) = 30(十进制) 表明该事件为写入事件。
# at 355
#201209 17:01:52 server id 33061 end_log_pos 410 CRC32 0x31c97555
# Position Timestamp Type Master ID Size Master Pos Flags
# 163 80 92 d0 5f 1e 25 81 00 00 37 00 00 00 9a 01 00 00 00 00
# 176 ee 00 00 00 00 00 01 00 02 00 04 ff f0 02 30 33 |..............03|
# 186 06 e5 ad 99 e9 a3 8e 99 46 a8 00 00 03 e7 94 b7 |........F.......|
# 196 55 75 c9 31 |Uu.1|
# Write_rows: table id 238 flags: STMT_END_F
所以,通过修改 event_type 实现数据恢复的原理,就是定位到数据的 event_type 位置,将 DELETE_ROWS_EVENT 替换为 WRITE_ROWS_EVENT 实现回滚 SQL。
1.2 闪回案例
执行一个 delete 删除操作。
delete from student where SId = 04
准备一个简单的 Python 脚本,修改 Event_type。
import sysif len(sys.argv) != 3:sys.exit()inputType = open(sys.argv[1], "rb")
changedType = open(sys.argv[2], "wb")changedType.write(inputType.read(359))
changedType.write(chr(30).encode())
inputType.seek(1, 1)while True:line = inputType.readline()if not line:breakchangedType.write(line)inputType.close()
changedType.close()
执行脚本程序,执行完成之后会生成一个 bak 文件,是替换过 event code 的 binlog 文件。
python chtype.py mysql-bin.000001 mysql-bin.000001-bak
使用 mysqlbinlog 对比两个 binlog 文件内容,下方是原文件的内容。
BEGIN
/*!*/;
# at 293
#201201 11:13:06 server id 33061 end_log_pos 355 CRC32 0xfc95f44d Table_map: `school`.`student` mapped to number 238
# at 355
#201201 11:13:06 server id 33061 end_log_pos 410 CRC32 0x6912246f Delete_rows: table id 238 flags: STMT_END_F
### DELETE FROM `school`.`student`
### WHERE
### @1='04'
### @2='李云'
### @3='1990-12-06 00:00:00'
### @4='男'
# at 410
#201201 11:13:06 server id 33061 end_log_pos 441 CRC32 0x24c5d71c Xid = 4363
COMMIT/*!*/;
SET @@SESSION.GTID_NEXT= 'AUTOMATIC' /* added by mysqlbinlog */ /*!*/;
DELIMITER ;
# End of log file
/*!50003 SET COMPLETION_TYPE=@OLD_COMPLETION_TYPE*/;
/*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=0*/;
下方是经过篡改过 event code 后的 binlog 文件。
BEGIN
/*!*/;
# at 293
#201201 11:13:06 server id 33061 end_log_pos 355 CRC32 0xfc95f44d Table_map: `school`.`student` mapped to number 238
# at 355
#201201 11:13:06 server id 33061 end_log_pos 410 CRC32 0x6912246f Write_rows: table id 238 flags: STMT_END_F
### INSERT INTO `school`.`student`
### SET
### @1='04'
### @2='李云'
### @3='1990-12-06 00:00:00'
### @4='男'
# at 410
#201201 11:13:06 server id 33061 end_log_pos 441 CRC32 0x24c5d71c Xid = 4363
COMMIT/*!*/;
SET @@SESSION.GTID_NEXT= 'AUTOMATIC' /* added by mysqlbinlog */ /*!*/;
DELIMITER ;
# End of log file
/*!50003 SET COMPLETION_TYPE=@OLD_COMPLETION_TYPE*/;
/*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=0*/;
现在拿着替换后的 binlog 到数据库中执行一下,这条记录就可以恢复。
1.3 方法总结
这种直接修改 Binlog Event 的方法虽然可以将 delete 操作转换为 insert 操作,但较难实现 update 闪回(能实现但是更复杂)且计算 type_cdoe 需要对 Binlog 的结构非常熟悉。经过我们的统计,生产环境中 delete 误删事件只约占 10%,因为数据一般不会真正删除,而是表中有一个字段,用来标记删除,所以 update 导致的数据 “丢失” 占比较高有 80%,剩下的就是 drop 或者 truncate DDL 这种 binlog 不可逆的 DDL 操作,只能通过全量备份恢复。
由于操作复杂,且应对场景有限,这种恢复数据的方式,就没有继续探索下去了,不过是一个学习 binlog 非常好的案例。
PS:美团数据库团队,开源了一款 SQL 闪回工具,MyFlash 基于修改 Binlog Event 结构的方式回滚事务。其中 delete/insert 回滚的方法,与本小节介绍的方法相同。
2. 解析文本闪回
通过 mysqlbinlog 可以将 binlog 文件解析成文本,可以通过对内容进行文本处理正则匹配和替换,从而实现闪回。
mysqlbinlog_191">2.1 mysqlbinlog
下方是使用 mysqlbinlog 将 binlog 文件解析成文本的命令,还可以添加时间范围 position 位点等过滤条件。
mysqlbinlog -vv --base64-output=decode-rows ./mysqlbin.003626 > all.sql
mysqlbinlog 解析后的内容,多余内容已删除。
### UPDATE `test`.`test_semi`
### WHERE
### @1=10 /* INT meta=0 nullable=0 is_null=0 */
### @2=1 /* INT meta=0 nullable=1 is_null=0 */
### @3=10 /* INT meta=0 nullable=1 is_null=0 */
### SET
### @1=10 /* INT meta=0 nullable=0 is_null=0 */
### @2=1 /* INT meta=0 nullable=1 is_null=0 */
### @3=111 /* INT meta=0 nullable=1 is_null=0 */
这是一个 update 事件,通过 mysqlbinlog 就可以将 binlog 解析成文本,分为两部分 WHERE 表示修改前的内容,既 before_values,SET 表示修改后的内容,既 after_values。此时还不能直接使用,需要将 update 中的 before_values 与 after_values 进行互换,或者直接根据 before_values 转换为 replace into 操作。
delete 事件原理也相同,通过正则匹配进行文本操作,转换为 insert 语句,再放到数据库中执行。
2.2 闪回案例
接下来,用一个生产环境遇到的案例,带大家了解整个数据恢复的过程。
记得当时是一个晚上八点左右时间,正当我准备探索提瓦特大陆的时候,收到研发经理的电话,其实看到这个来电人,以及这个来电的时间,我就心头一紧,准没好事…
他告诉我刚才有研发执行了一个 SQL 脚本,由于执行前没检查,谁知 SQL 文件中,有一条 update 没有带 where 条件,导致整张表被更新了,相当于更新了预期外的数据,产生了数据错乱,需要尽快修复。
让研发经理拉群,找那名研发确认操作时间,误操作的 SQL 语句,以及大致的影响行数。得到如下信息:
- 误操作时间:19:30 分左右,具体时间不详。
- 误操作的 SQL 语句:
-- SQL 是脱敏后的,当时也是更新全表 update test_semi set c = 111; - 影响行数:约 1.7w 行。
第一步,定位事务的 position 位点:最原始方法是通过 mysqlbinlog 命令,指定时间范围,导出文本,如果打开文本文件,搜索关键字,匹配误操作的记录。
mysqlbinlog -vv --base64-output=decode-rows --start_datetime='2024-04-18 19:25:00' --stop_datetime='2024-04-18 19:45:00' --database='op_service_db_bak' ./mysql-bin.000014 > all.sql
通过不断缩小时间范围,搜索事务的 position 位点,下图为事务开始的位点。
PS:以下演示使用的是模拟数据,所以日志中的行数与案例描述不一致。
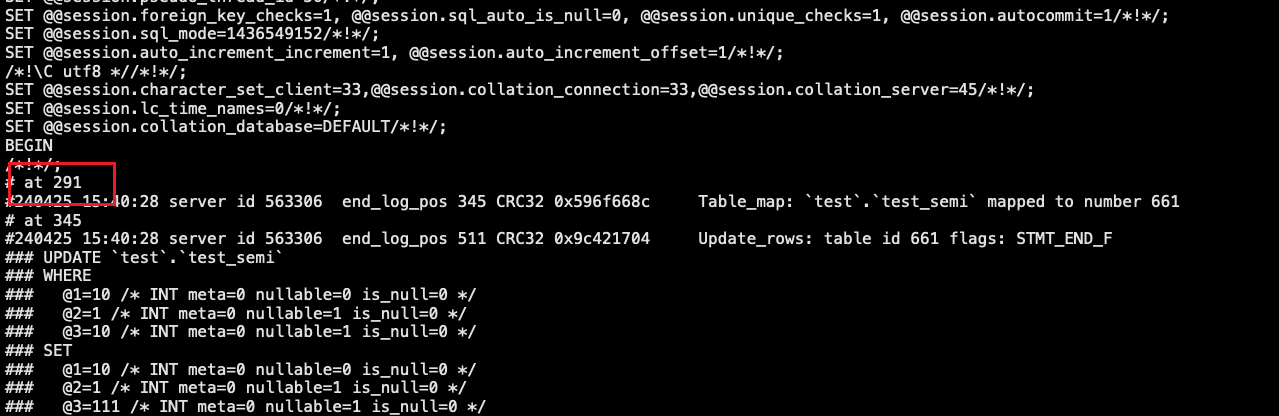
下图为事务结束的位点。
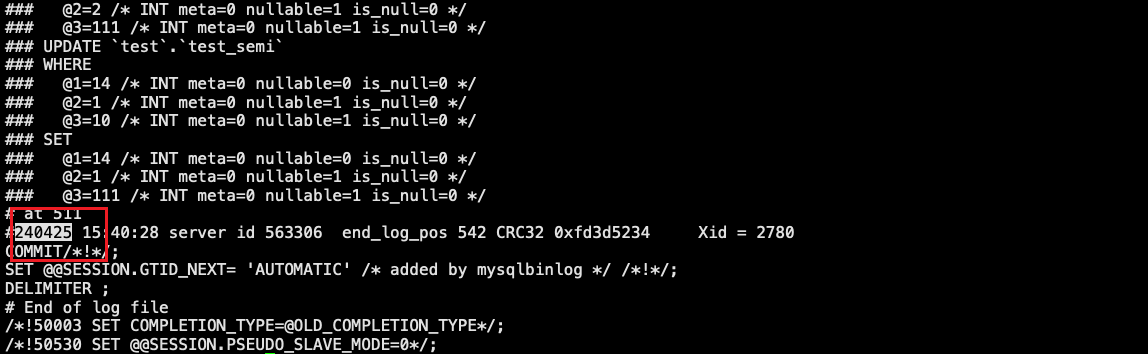 目前已经在 Binlog 中定位到误操作 position 位置,接下来需要使用脚本解析 update 语句将 WHERE 数据部分转换为 replace into 操作。
目前已经在 Binlog 中定位到误操作 position 位置,接下来需要使用脚本解析 update 语句将 WHERE 数据部分转换为 replace into 操作。
mysqlbinlog --base64-output=decode-rows -vvv --start-position=291 --stop-position=240425 ./mysql-bin.000002 | perl parse_binlog_preimage.pl > recover.sql
输出:
--table: `test`.`test_semi`
-- DML type: UPDATE, num of cols: 3
replace into `test`.`test_semi` values ( 10 , 1, 10);
--table: `test`.`test_semi`
-- DML type: UPDATE, num of cols: 3
replace into `test`.`test_semi` values ( 11 , 2, 0);
--table: `test`.`test_semi`
-- DML type: UPDATE, num of cols: 3
replace into `test`.`test_semi` values ( 12 , 1, 10);
--table: `test`.`test_semi`
-- DML type: UPDATE, num of cols: 3
replace into `test`.`test_semi` values ( 13 , 2, 0);
--table: `test`.`test_semi`
-- DML type: UPDATE, num of cols: 3
replace into `test`.`test_semi` values ( 14 , 1, 10);
脚本的作用是通过正则匹配到 binlog 文本 update 中的 WHERE 数据部分,然后转换为 replace into,这样做的好处是,导出的 SQL 研发可以先插入到测试表检查一遍数据,特别是回滚的行数较多的时候。
2.3 方法总结
这种方法适用于回滚数据量较小的场景,影响行数很大的话,解析效率远小于直接修改 Binlog event 的方法。
定位事务 Position 的方法,非常原始,全凭使用者的经验,而且在某些场景文本解析的方法的兼容性有待商榷。优点是脚本写起来比较简单,不需要学习 Binlog 结构就可以上手。
3. 在线订阅闪回
该方法是基于类 python-mysql-replication 库,伪装成一个 binlog dump 线程,实时订阅 MySQL Binlog 日志生成,从而实现闪回。从上文可以看到,binlog 中的字段是使用 @1 这种形式标记的,只有顺序没有字段名称,所以不能实现字段过滤。这种在线订阅 Binlog 的方法,因为需要连接数据库,所以可以基于 MySQL 元数据补充字段名称,从而实现字段过滤。
mysqlreplication_275">3.1 mysql-replication
之前文章中有详细介绍并演示过该模块,感兴趣的朋友可以根据文章的案例进行测试。
推荐阅读:MySQL 如何从 Binlog 找出变更记录并回滚
文章中,利用了在线订阅 Binlog 可以获得字段信息的优势,实现了事务过滤,通过写 if 条件过滤到我们需要定位的事务。
3.2 binlog2sql
基于 mysql-replication 模块,实现的一个 SQL 闪回工具,使用起来非常简单。通过在线拉取 binlog 获得 event 数据,拼接为 SQL 语句,支持将语句反转。我自己也写过类似的工具,叫 COOHSQL。
项目地址:binlog2sql github
一些开源的审核工具,比如 Archary,内置的闪回功能就是通过 binlog2sql 实现的。如果一条工单执行后,需要闪回,就可以利用该功能实现闪回。
3.3 方法总结
由于原生 Binlog 中没有字段信息,只有 Table_map 中的字段列表,所以只解析原生 Binlog 无法实现字段过滤,一个 Binlog 文件可能存着几百万个事务,人工定位误操作的事务是一件比较吃经验方法,不太通用。
现在通过在线订阅 Binlog 可以基于 MySQL 元数据库,补充字段信息,利于实现条件过滤,至少可以很大程度缩小搜索范围。
4. Binlog 分析方法
Binlog 中记录了数据库中的数据变动,除了用于增量恢复和 SQL 闪回(包含数据订正)场景外,还有一个数据生命周期管理场景,让 DBA 从更高的一个角度来看待所管理的数据。
4.1 分析场景
这里列举几个场景:
-
了解数据库中,每天有多少张表是通过后端自动删除重建的,有多少次 DDL 变更?记得有一次迁移场景,通过某云的 DTS 进行全量数据迁移,业务每小时都会对一张表进行 truncate,这个信息提前没有了解到,结果因为 DTS 迁移任务产生 MDL 锁争用,引发了一次小范围的故障。如果提前了解到业务规律,那么就可以协调停掉相关业务。这些信息可以从 Binlog 中的 Query Event 中分析得到。
-
引入数据的变更频率,把 DML 的频率量化出来,就可以知道数据库中的 DML 操作的比例,哪些是热点表,帮助 DBA 落实数据冷热分离。在一套 MySQL 集群中,如果 DML 变更频繁,可能会造成主从延迟,此时通过分析 Binlog 就可以快速定位到原因,精确到哪张表,有没有大事务?哪种类型的操作造成集群延迟?都可以通过分析 Binlog 得到答案。
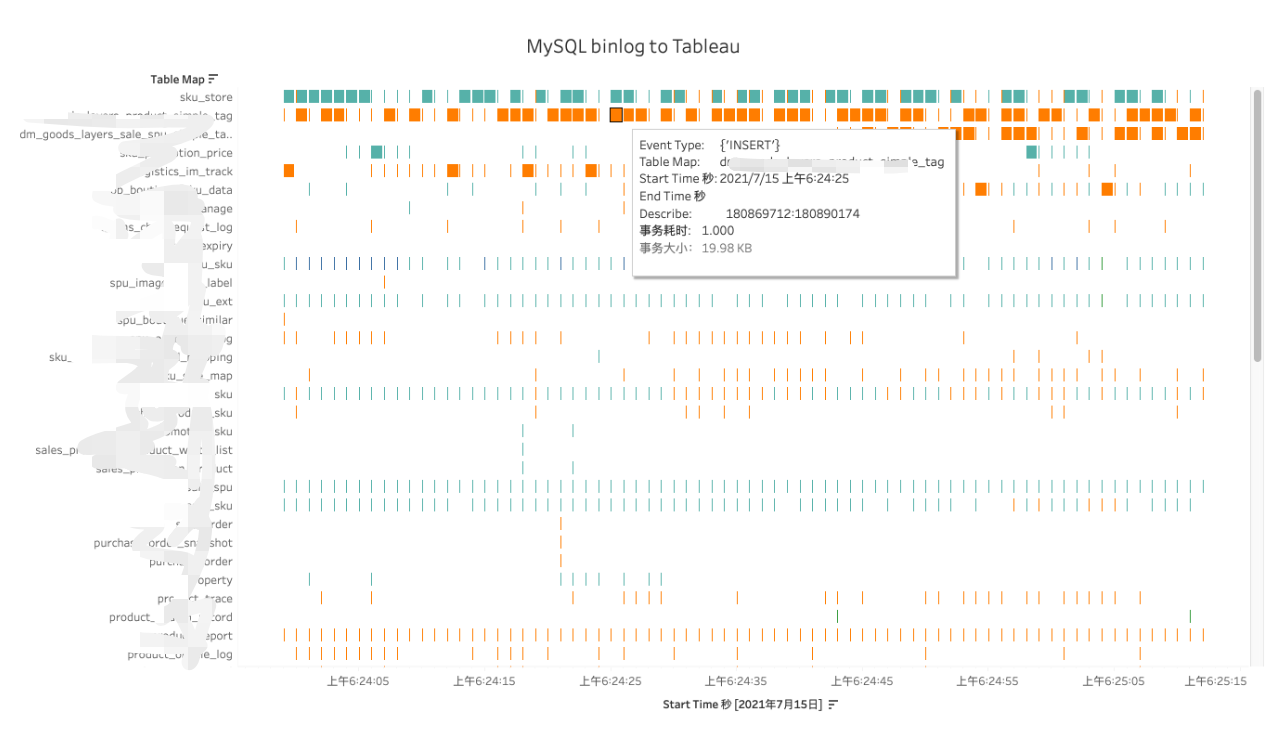
上图,是我自研的一个 Binlog 分析工具,将分析结果通过 Tableau 甘特图进行展示,可以清晰的看到每张表在各个时间段的 DML 情况。例如上图 sku_store update 操作量很大,其次是一些日志表,多为一些写入操作。
4.2 辅助定位事务
Binlog 分析工具,我已经开源,可以参考我之前的文章。
推荐阅读:MySQL Binlog 分析方法 - 自研分析工具 BinlogShow

该工具会扫描 Binlog 中的事务,然后生成一个事务列表。
在实际生产中,该工具可以帮助我们定位闪回事务的位点。这时候可能你会想:只有一个事务列表又不能使用字段过滤,为什么可以帮助定位闪回事务呢?
我们通过该工具分析了多个业务系统的 DML 规律,绝大部分表,每次更新的量基本都是一样的,误差不会很大,所以 event 日志量的大小也基本一致,一个误操作影响行数往往和业务 DML 的量不同,所以从 binlog 中事务大小,也有可能定位到误操作的 Position。
这里列举一个生产环境的案例:一张 user 表的用户状态被误更新了,影响行数大约是 10w 行。业务 SQL 一般只会更新一行,所以在 Binlog 中的事务大小也就几 KB,误操作影响行数是 10w 行,在 Binlog 中的事务大小是 30MB,定位该事务只需要使用我写的 Binlog 分析工具,拿到事务列表,然后对事务大小进行降序排序,就可以很明显的看出来误更新事务对应的 Position 位点。
4.3 方法总结
通过分析 Binlog 可以了解数据中的数据流动情况,也可用于某种场景下的 position 定位,定位到 position 位点后,可以搭配第 1 小节或第 2 小节的方法进行数据回滚。
5. 平台化的解决方案
上文,我们介绍了三种数据回滚的方法,其中在线订阅的方法,是可以实现字段过滤的,也是我个人常用的方法。生产上除了需要通过 Binlog 进行回滚外,也会有订正数据的需求,比如业务 bug 导致一行记录出现预期外的更新。数据库侧能提供的帮助就是解析 Binlog 追踪到相关记录,帮助研发订正数据。
工作至今,也参与过二十余数据恢复,有特别严重的直接惊动高层的故障,也有影响很小的的事件,研发要求能恢复就行。我个人从通过使用 SQL 文本搜索定位事务,再到 binlog 订阅自动化定位事务,一直在探索如何快速便捷的处理数据丢失事故。也在思考如何尽可能避免此类事故发生,于是分析了公司知识库中记录的所有数据故障(约 40 起)案例。
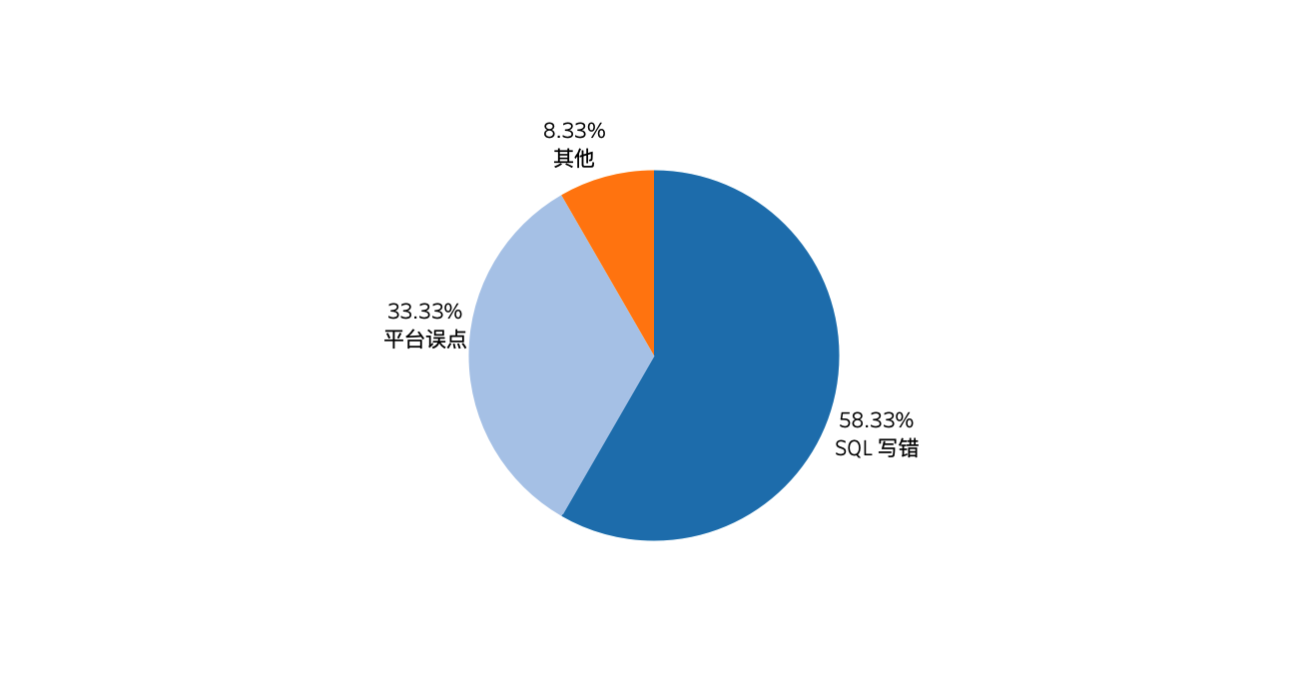
下图为导致数据丢失事件操作类型的分类,平台误点指在云平台 DROP DATABASE 或者数据库中执行 DROP TABLE。SQL 写错是指研发人员在数据库中执行 SQL 任务时,SQL 语句错误导致的效果未取得预期且对原数据造成伤害。
其中,暴露出来的问题如下:
-
平台误点,背后的问题是权限管控不到位,这种 drop 权限只能掌握在少数可靠的人手里。
-
SQL 写错,暴露的问题是,一条 SQL 语句对线上环境的影响,无人评估。
-
SQL 变更无管控审核,多次发生 SQL 忘记带 WHERE 条件、SQL 写错等失误,造成数据丢失。
如何应对这类问题呢?答案就是数据库管控平台化,SQL 任务变更走审核流程。另外还有一组数据,在多起数据丢失事件中,团队是否使用了审核流程和故障数量是否有关系呢?

从上图,可以看出没有使用审核流程的团队,故障(数据丢失故障)占比最高。使用了审核流程的团队,数据丢失故障仅占 8%,由此可以看出使用审核流程,能够很大程度减少数据丢失故障数量。
另外,在有审核流程的团队,如果没有重视或者严格遵守审核流程的话,故障数量占比依旧比较高。为什么有审核流程,却不全面使用呢?我采访了相关的研发团队,首先研发 leader 是知道审核流程的重要性,但是总会以太忙(发版着急,懒得提工单)为由,跳过审核流程,直接拿 SQL 到环境里面执行,从而导致生产环境的数据安全存在隐患。造成研发团队不重视审核流程的原因我总结有如下几个:
- 研发团队针对数据库的安全意识不够强,需要数据库团队多宣传和培训。
- 审核平台使用起来不顺手,一些开源的审核平台,用户体验上其实并不好,导致研发团队潜意识抵触审核流程。
- 研发团队对数据库平台化的技术发展不太关注,不了解目前数据库 DevOPS 发展程度,有多少可以提升研发效率和数据安全的技术,只有在出问题的时候,被动了解一部分。这也需要数据库团队潜移默化的传递。
总结一下,数据安全防护的尽头,是平台化,平台不仅要好用也要用好。
5.1 数据追踪
刚才有提到数据库 DevOPS 领域中也有很多提升研发效率和数据安全的技术,这里分享一个我个人非常喜欢的一款数据库平台 NineData。本文主题是数据恢复,那么我就带大家一起看看 NineData 是如何帮助用户快速追踪到误操作记录并完成回滚。
NineData 为用户提供了一个数据追踪的功能,可用于 SQL 闪回和数据订正场景。它是基于在线订阅 Binlog 的方式实现的,支持字段过滤,自动化的程度非常高,大大降低了使用门槛,即使不是 DBA 也能通过数据追踪功能快速恢复数据。
话不多说,一起从 0 开始测试一下该功能,首先需要注册一个账号:
NineData 注册地址
注册完成后,进入控制台,可以免费申请数据源,便于快速测试。
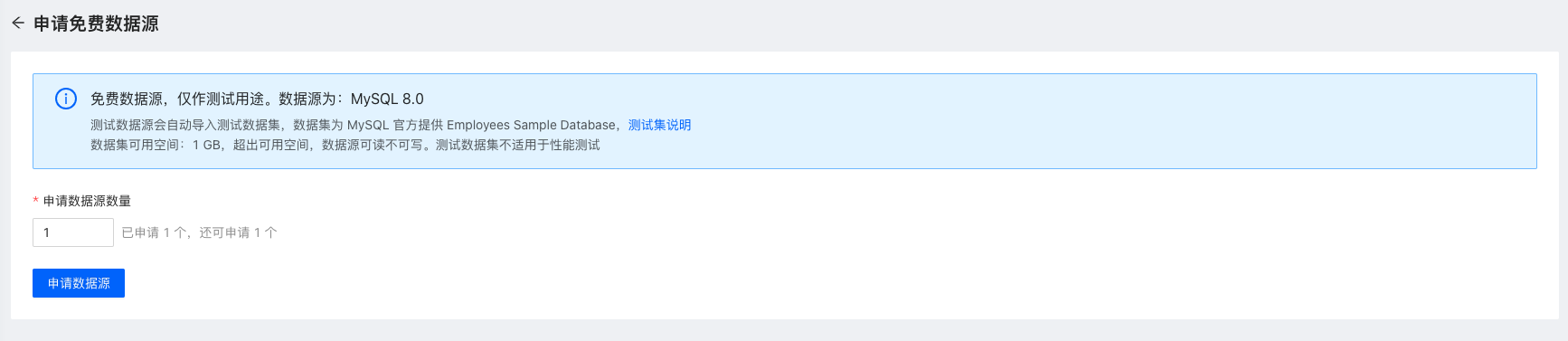
申请的测试数据源中,已经提供了测试的数据集。我们使用 sample_employees_8064 库中的 employees 员工表,模拟一次数据误更新故障。

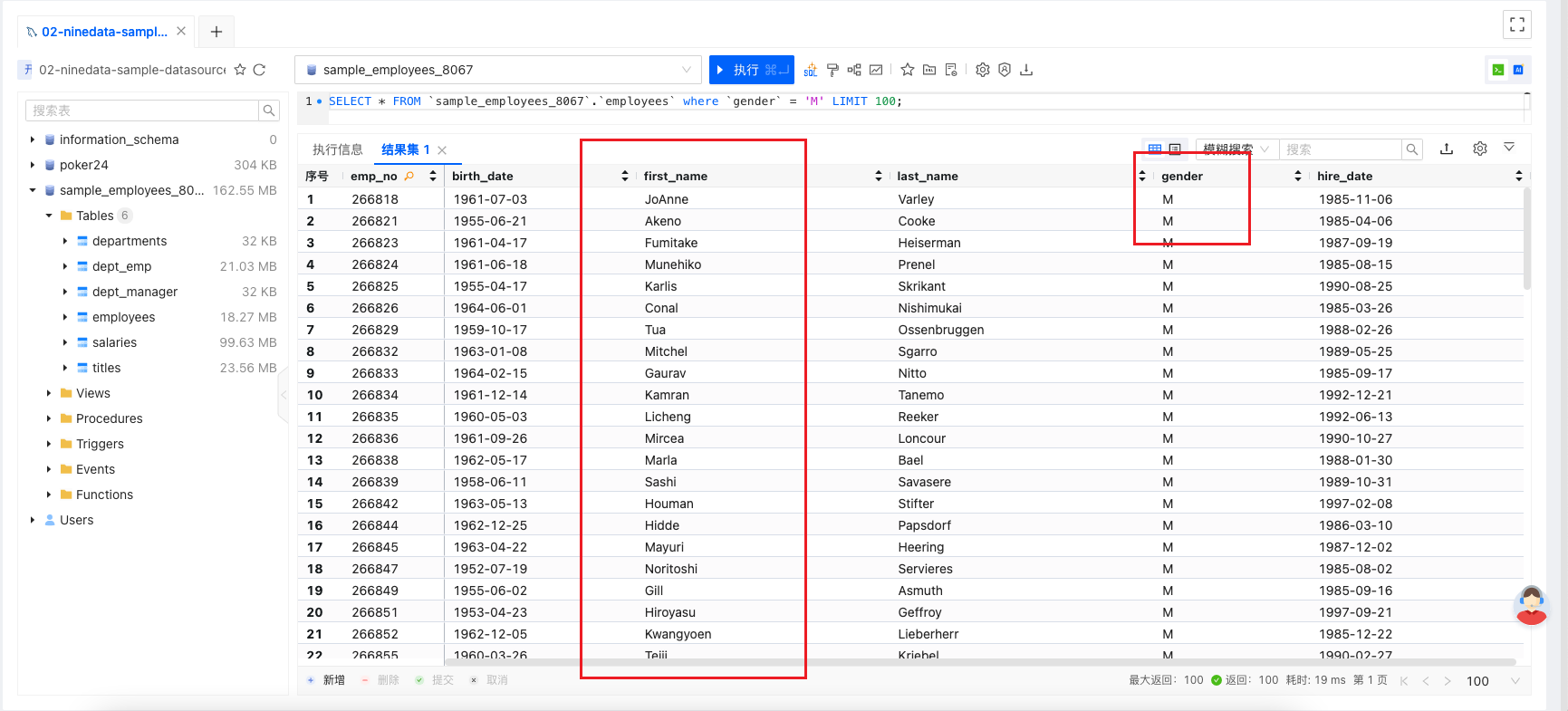
性别为男的员工有 79973 条记录,使用下方 SQL 将所有男性员工的名字修改为 Bing,影响行数为 79973。

现在所有男性员工的名字,出现了数据错误,现在需要立即恢复数据,该怎么做呢?
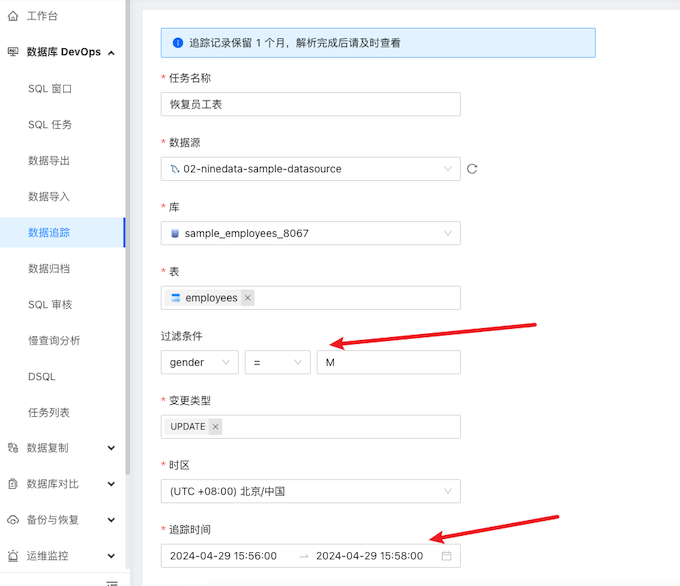
创建一个数据追踪任务,指定误操作的环境信息以及大致的时间范围,还有误操作的过滤条件即可。
从任务提交审批到 Binlog 解析完成,只花费了 2 分钟,就得到误操作的追踪记录。速度如此之快的原因可能也与是测试环境,数据库中几乎没有 DML 有关。不过即便如此,假如使用上方介绍的方法,两分钟我可能还没有把 Binlog 从环境中下载下来用于解析… 这也是平台化的魅力。
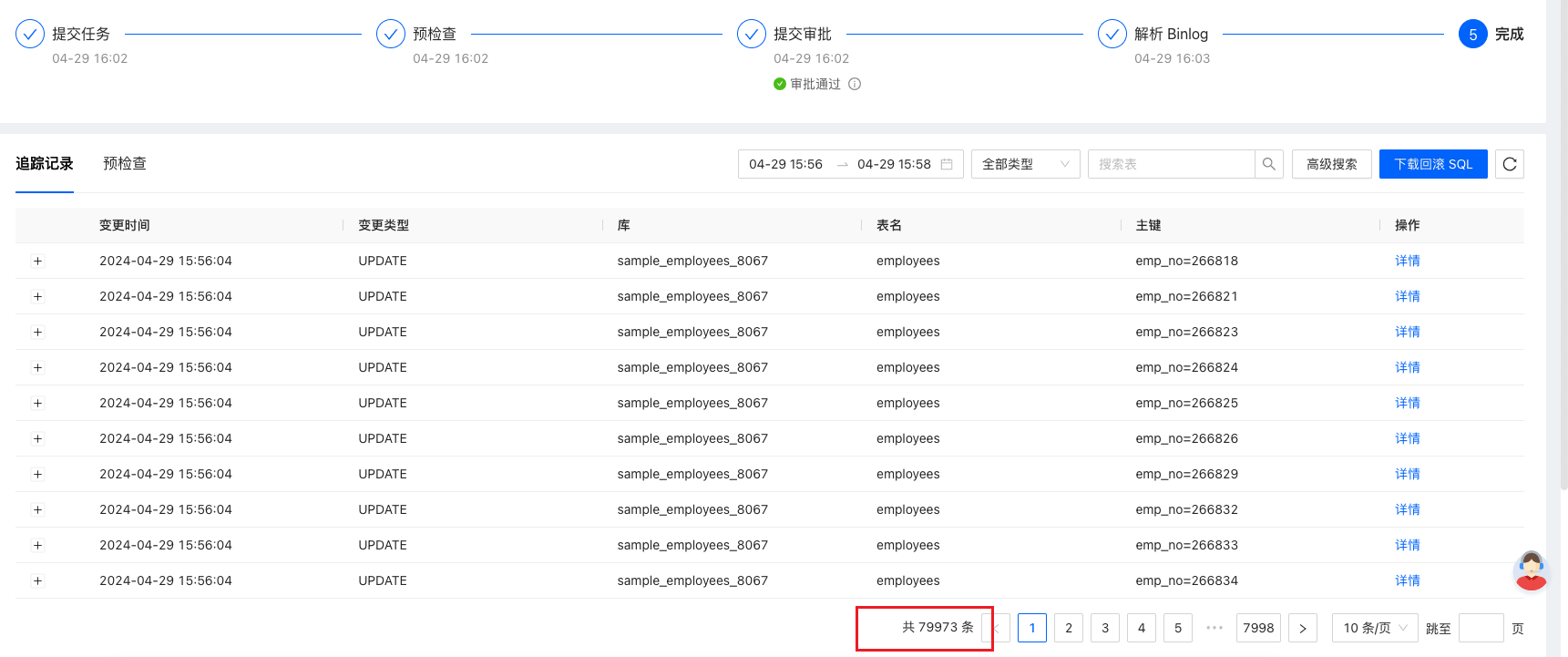
从上图,可以看到追踪出来的记录是 79973 条,与刚才执行窗口中的影响行数一致。
点击详情,就可以看到每行记录的变更记录。
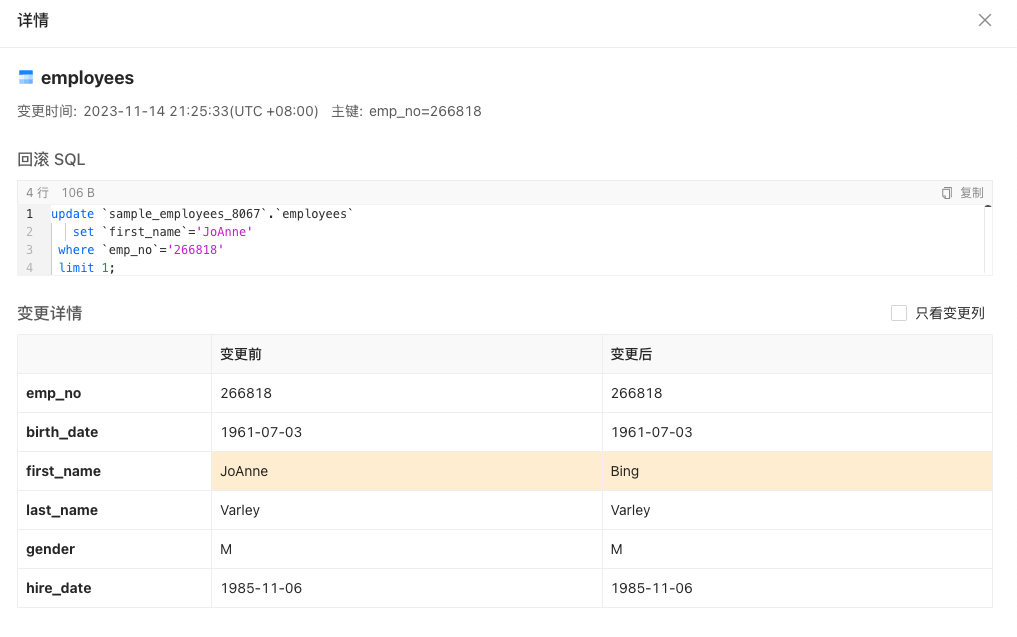
如果需要恢复到数据库,可以点击下载回滚 SQL 的选项,就可以拿到回滚 SQL 到环境中执行。
-- 这里只展示部分,SQL 通过主键字段进行数据回滚
update `sample_employees_8067`.`employees` set `first_name`='JoAnne' where `emp_no`='266818' limit 1 ;
update `sample_employees_8067`.`employees` set `first_name`='Akeno' where `emp_no`='266821' limit 1 ;
update `sample_employees_8067`.`employees` set `first_name`='Fumitake' where `emp_no`='266823' limit 1 ;
update `sample_employees_8067`.`employees` set `first_name`='Munehiko' where `emp_no`='266824' limit 1 ;
update `sample_employees_8067`.`employees` set `first_name`='Karlis' where `emp_no`='266825' limit 1 ;
update `sample_employees_8067`.`employees` set `first_name`='Conal' where `emp_no`='266826' limit 1 ;
update `sample_employees_8067`.`employees` set `first_name`='Tua' where `emp_no`='266829' limit 1 ;
update `sample_employees_8067`.`employees` set `first_name`='Mitchel' where `emp_no`='266832' limit 1 ;
update `sample_employees_8067`.`employees` set `first_name`='Gaurav' where `emp_no`='266833' limit 1 ;
在 NineData 中,可以提交一个 SQL 导入任务:

下图为 SQL 数据导入的流程,将回滚 SQL 导入到环境中执行。
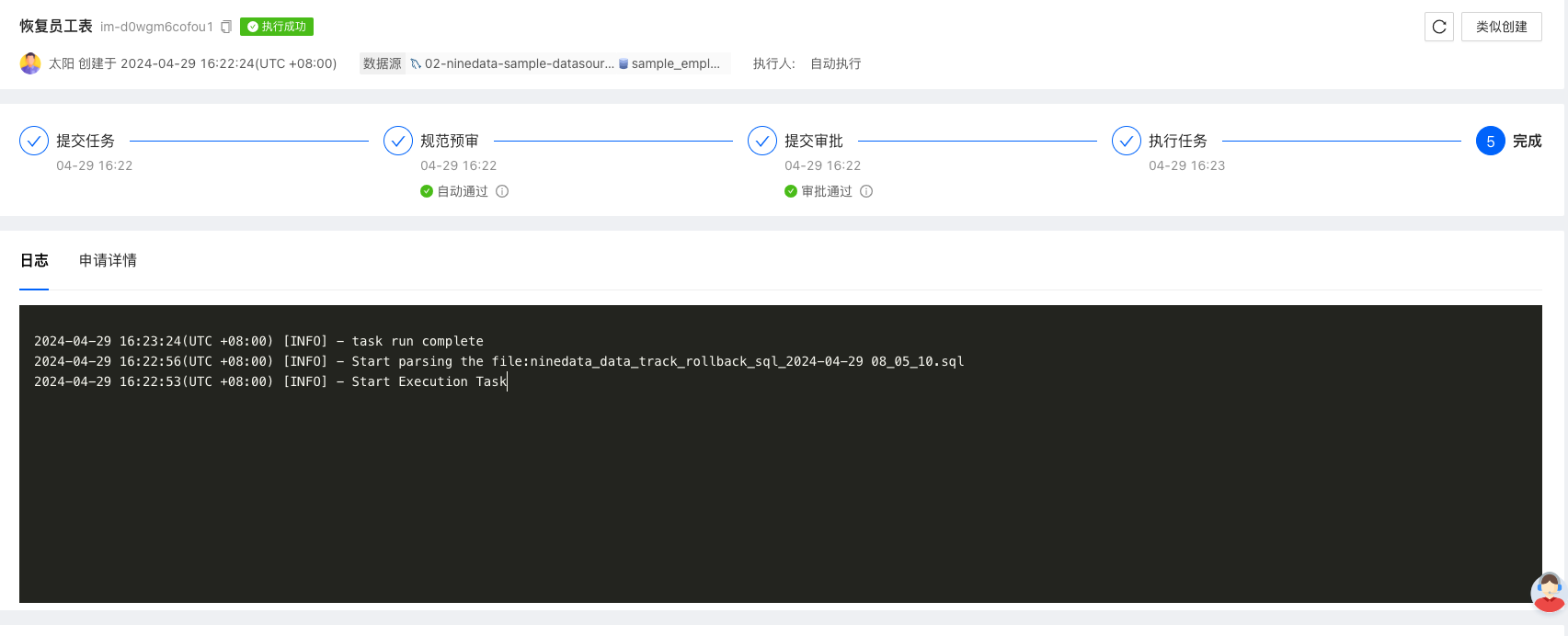
到目标环境中抽样检查数据,刚才所有男性的名字被修改为了 Bing,现在已完成回滚。
5.2 方法总结
NineData 结合平台化的优势,极大的提升数据追踪的自动化程度和任务效率。当故障(指数据丢失)发生的时候,运维人员往往需要在高压的环境下迅速做出决策,而自动化程度的提升则能大大减轻他们的负担,从而保障故障有条不紊的恢复,尽可能的减少 RTO 让业务快速恢复。
除了数据追踪功能外,NineData 还有很多耳目一新且非常实用的功能,感兴趣的朋友可以 注册 账号去体验。
总结
本文详尽地介绍了三种 Binlog 回滚方法,它们分别是修改 Binlog Event、文本解析以及 Binlog订阅。基本覆盖了 Binlog 解析的大部分内容。除此之外,还列举了定位事务 Position 的有效方法,为实际操作提供了有力指导。同时,文章也探讨了如何减少数据丢失故障的重要性,并强调了审核流程在保障数据安全与完整性中的不可或缺性。通过本文的阅读,可以全面了解 Binlog 回滚的方法与技巧,为日常的数据管理与维护工作提供有力支持。