目录
提交MapReduce程序至YARN运行
1、提交wordcount示例程序
1.1、先准备words.txt文件上传到hdfs,文件内容如下:
1.2、在hdfs中创建两个文件夹,分别为/input、/output
1.3、将创建好的words.txt文件上传到hdfs中/input
1.4、提交MapReduce程序至YARN
1.5、可通过node1:8088查看
1.6、返回我们的服务器,检查输出文件夹wc存不存在并查看统计结果
2、提交圆周率示例程序
总结
提交MapReduce程序至YARN运行
在部署并成功YARN集群后,我们就可以在YARN上运行各类应用程序了。
YARN作为资源调度管控框架,其本身提供资源供许多程序运行,常见的有:
- MapReduce程序
- Spark程序
- Flink程序
Spark与Flink是大数据后续学习内容,我们目前先来体验一下在YARN上执行MapReduce程序的过程。
Hadoop官方内置了一些预置的MapReduce程序代码,我们无需编程,只需要通过命令即可使用,常用的有2个MapReduce内置程序:
- wordcount:单词计数程序(统计指定文件内各个单词出现的次数)
- pi:求圆周率(通过蒙特卡罗算法求圆周率)
这些内置的示例MapReduce程序代码,都在:
$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar 这个文件内
可以通过hadoop jar命令来运行它,提交MapReduce程序到YARN中。
语法:hadoop jar 程序文件 java类名 [程序参数] ..... [程序参数]
1、提交wordcount示例程序
单词计数示例程序的功能很简单:
- 给定数据输入路径(HDFS)、给定结果输出的路径(HDFS)
- 将输出路径内的数据中的单词进行计数,将结果写到输出路径
我们可以准备一份数据文件,并上传到HDFS中。
1.1、先准备words.txt文件上传到hdfs,文件内容如下:

1.2、在hdfs中创建两个文件夹,分别为/input、/output

1.3、将创建好的words.txt文件上传到hdfs中/input

1.4、提交MapReduce程序至YARN
语法:hadoop jar 程序文件 java类名 [程序参数] ..... [程序参数]
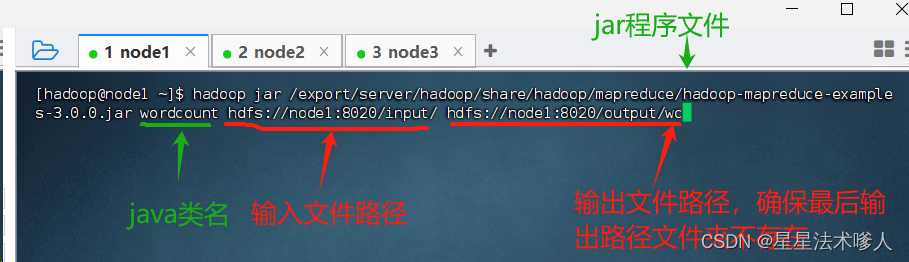
1.5、可通过node1:8088查看
YARN给MapReduce提供资源,相当于给他提供了容器,然后他在容器里面完成了数据计算

1.6、返回我们的服务器,检查输出文件夹wc存不存在并查看统计结果


2、提交圆周率示例程序
可以执行如下命令,使用蒙特卡罗算法模拟计算求PI(圆周率)
hadoop jar /export/server/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.0.jar pi 3 1000
- 参数pi表示要运行的Java类,这里表示运行jar包中的求pi程序
- 参数3,表示设置几个map任务
- 参数1000,表示模拟求pi的样本数(越大求得PI越准确,但是速度越慢)
运行如下:

总结
1、Hadoop自带的MapReduce示例程序的代码jar包是
$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar
2、使用什么命令提交MapReduce程序到YARN中执行?
hadoop jar 命令
语法:hadoop jar 程序文件 java类名 [程序参数] ..... [程序参数]
3、如何查看程序运行状态
在YARN WEB页面查看