配置结构
首先,我们知道MMSeg矿机的配置文件很多,主要结构如下图所示。
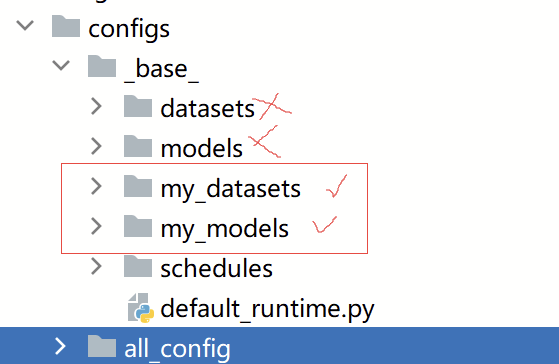
在configs/_base_下是模型配置、数据集配置、以及一些其他的常规配置和运行配置,四类。
configs/all_config目录下存放,即是将四种配置聚合在一起的一个总体文件。如下所示:
_base_ = ['../_base_/my_models/my_model.py', #模型配置'../_base_/my_datasets/my_dataset.py', # 数据集配置'../_base_/default_runtime.py', # 运行配置'../_base_/schedules/schedule.py' # 其他配置
]
# 一些参数修改,可根据上面四个文件自己定义
crop_size = (512, 512)
data_preprocessor = dict(size=crop_size)
model = dict(data_preprocessor=data_preprocessor,decode_head=dict(num_classes=2), # 解码# auxiliary_head=dict(num_classes=2)
) # 辅助
接下来,我们就搭建自己的网络
搭建网络configs/base/my_models/my_model.py
1、第一部分
这些不是本节的重点
# 批处理配置
norm_cfg = dict(type='SyncBN', requires_grad=True)
# 激活函数选择(原文件中没有,自己加的,需要在模型中加入)
act_cfg = dict(type='ReLU') # GELU
# 以上两个全局设置可以省掉很多细节上的麻烦,也有conv_cfg设置全局卷积,太复杂了,不考虑
# 数据集处理方式
data_preprocessor = dict(type='SegDataPreProcessor',mean=[123.675, 116.28, 103.53],std=[58.395, 57.12, 57.375],bgr_to_rgb=True,pad_val=0,seg_pad_val=255)
2、第二部分
是模型配置的重点
模型配置主要有以下几个方面
主要为骨干网络和解码头,辅助头可要可不要,看自己的模型
model = dict(
# 1 基本设置type='EncoderDecoder', # 模型的类型,一般是编码解码器结构,在mmseg/models/segmentors目录下,是分割网络的结构data_preprocessor=data_preprocessor, # 必须的pretrained='open-mmlab://resnet50_v1c',
# 2骨干网络backbone=dict(type='MyModel',。。。),
# 3解码头decode_head=dict(type='DepthwiseSeparableASPPHead', # sep_aspp_head.py。。。),
# 4辅助头auxiliary_head=[dict(。。。),dict(。。。),],
# 5model training and testing settingstrain_cfg=dict(),test_cfg=dict(mode='whole'))2.1 骨干网络
也是特征提取模块,也叫编码器。我们以resnet50_vd搭建自己的骨干网络,将其命名为MyBackbone
则配置文件中就写
backbone=dict(type='MyBackbone',depth=50,...其他参数等norm_cfg=norm_cfg,norm_eval=False,style='pytorch',act_cfg=act_cfg,),
在mmseg/models/backbones目录下创建自己的网络mybackbone.py,同时在__init__.py中引入
一个基本的骨干网络如下所示。
@MODELS.register_module()
class MyBackbone(BaseModule):def __init__(self,其他参数):# 初始化权重和基本模型,这一步基本是固定的,暂时没怎么改if init_cfg is None:init_cfg = [dict(type='Kaiming', layer='Conv2d'),dict(type='Constant', val=1, layer=['_BatchNorm', 'GroupNorm'])]super().__init__(init_cfg=init_cfg) # 初始化BaseModule1初始化各组件def forward(self, x):2执行过程return def train(self, mode=True):"""Convert the model into training mode while keep normalization layerfreezed."""super().train(mode)self._freeze_stages()if mode and self.norm_eval:for m in self.modules():# trick: eval have effect on BatchNorm onlyif isinstance(m, _BatchNorm):m.eval()def _freeze_stages(self):pass
接下来讲一下MyBackbone各组件搭建
首先MyBackbone由两个分支组成,基本是下图所示的样子。
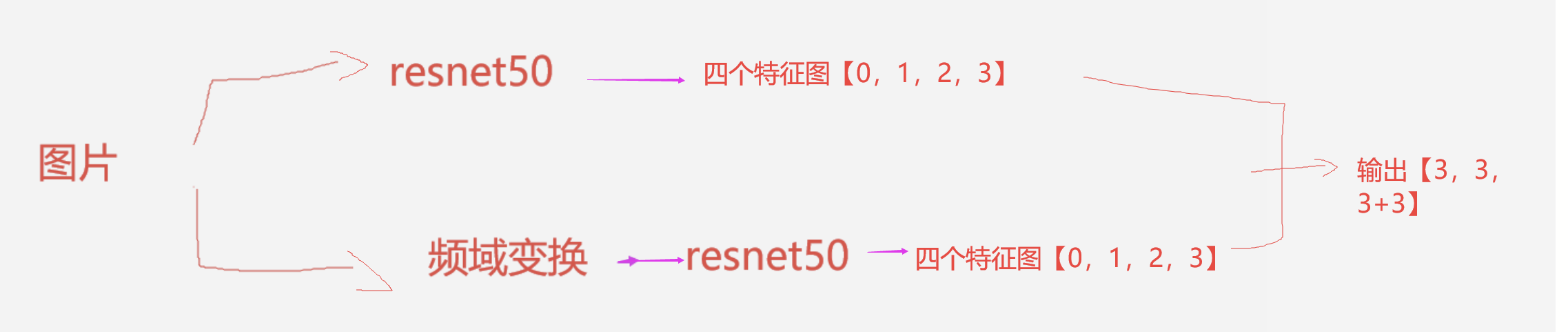
搭建组件一:
分支一很简单,主要由ResNet50构成,参数配置如下
self.branch1= ResNetV1d(depth=50, # 深度50in_channels=3, #输入通道stem_channels=64, # resnet的stem层base_channels=64,num_stages=4, # resnet的4个阶段# resnet四层的步长和扩张率strides=(1, 2, 1, 1),dilations=(1, 1, 2, 4), # 输出索引,表示输出哪一阶段的特征图out_indices=(0, 1, 2, 3),# 风格,暂时不太懂这个参数,但用的就是pytorchstyle='pytorch',# resnet的改进,目前最好的就是vd版本,需要了解的可以去搜索deep_stem=True, # deep_stem=True是v1cavg_down=True, # deep_stem和avg_down都等于True是v1d# frozen_stages=-1,norm_cfg=norm_cfg,# dict(type='BN', requires_grad=True), # 批处理norm_eval=False,# 网络策略,resnet改进后在第四阶段加入空洞卷积引入网格策略控制扩张率multi_grid=(1, 2, 4), # 只有stage[3])
因为PaddleSeg有用output_stride参数控制resnet的降采样倍数,例如
if output_stride == 8:dilation_dict = {2: 2, 3: 4}elif output_stride == 16:dilation_dict = {3: 2}
而MMSeg没有,直接用 dilations设置stage[2]的扩张倍数为2,stage[3]扩张率倍数为4。则输出降采样为8倍。
下面总结一下resnet的改进,以resnet50为例
1、resnet50初始为深度50,stem初始层,加上四阶段,四阶段分别为[3,4,6,3]的结构,每个结构是一个block块。如下图所示。
注意只有在2,3,4阶段的第一个block块的步长才会设为2,才会进行降采样,第一个阶段不降采样
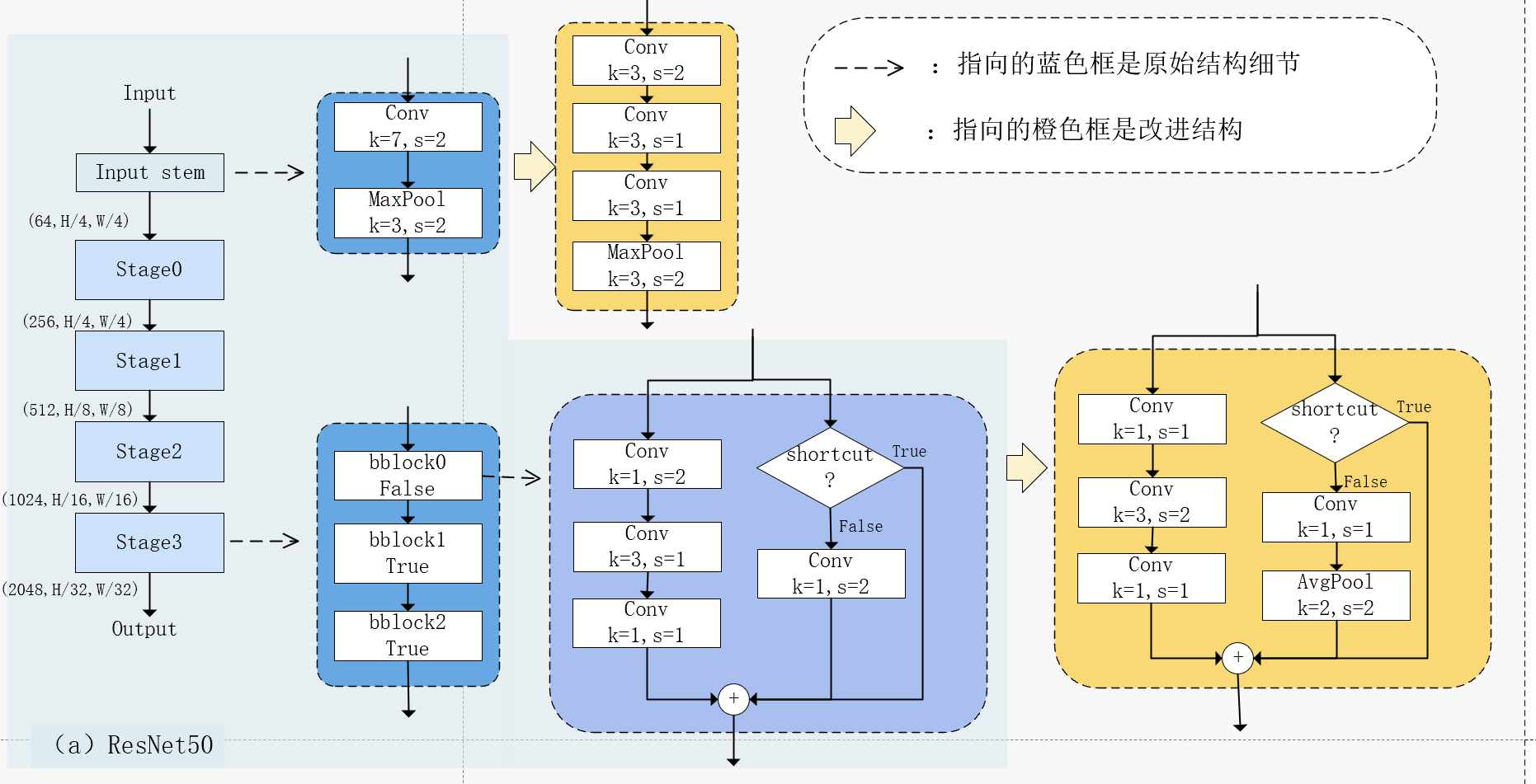
2、vb改进block块左路的步长,将stride=2下移到中间层
3、vc在vb的基础上,改进 stem层的7x7大卷积核,改成3个3x3的小卷积核
4、vd在vc的基础上,改进block右路的步长,将卷积的步长改为1,增加平均池化层降采样
原先resnet50输出特征图,每阶段分别是[256,H/4,W/4]、[512,H/8,W/8]、[1024,H/16,W/16]、[2048,H/32,W/32]
5、后续,在vd基础上引入空洞卷积和网格策略,实现对输出降采样倍数的控制,常见的有两种组合:
注意,当dilation_rate不等于1的时候,该层步长为1,即使是第一个block块也不再为2
5.1降采样16倍,stage[2].d=1,stage[3].d=2x【1,2,4】
每阶段分别是[256,H/4,W/4]、[512,H/8,W/8]、[1024,H/16,W/16]、[2048,H/16,W/16]
5.2降采样8倍,stage[2].d=2x1,stage[3].dx4【1,2,4】
每阶段分别是[256,H/4,W/4]、[512,H/8,W/8]、[1024,H/8,W/8]、[2048,H/8,W/8]
MMSeg和PaddleSeg默认实现的都是降采样8倍的组合
搭建组件二
组件二由两个噪声提取器和reanet50组成,如下所示
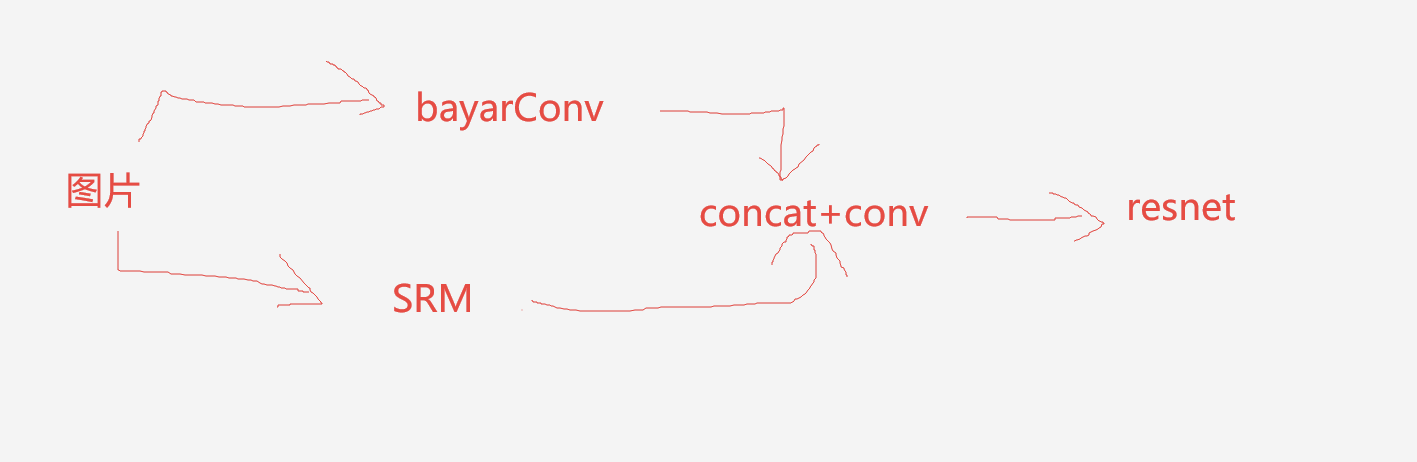
组件三
参考deeplabv3+中利用ASPP对低级特征图和高级特征图融合
每个resnet输出的四张特征图,利用ASPP融合
deeplabv3+中利用解码头输入实现,这次我们需要将其嵌入在骨干网络中
参考mmseg/models/decode_heads/sep_aspp_head.py中DepthwiseSeparableASPPModule的实现
1.首先对高级特征图利用ASPP,高级特征图尺寸[2048,H/8,W/8]
self.aspp1 = ASPPModule(dilations = (1, 12, 24, 36), # asppin_channels = 2048,#channels = 256, # 输出通道norm_cfg = norm_cfg,conv_cfg = conv_cfg,act_cfg = act_cfg,)
需要对其进行修改
class ASPPModule(nn.ModuleList):"""Atrous Spatial Pyramid Pooling (ASPP) Module.Args:dilations (tuple[int]): Dilation rate of each layer.in_channels (int): Input channels.channels (int): Channels after modules, before conv_seg.conv_cfg (dict|None): Config of conv layers.norm_cfg (dict|None): Config of norm layers.act_cfg (dict): Config of activation layers."""def __init__(self, dilations, in_channels, channels, conv_cfg, norm_cfg, act_cfg):super().__init__()self.dilations = dilationsself.in_channels = in_channelsself.channels = channelsself.conv_cfg = conv_cfgself.norm_cfg = norm_cfgself.act_cfg = act_cfgself.aspp = nn.ModuleList() # 注意这里不能直接用list[]。类似元组,tuple[]也不能用,要不然会导致weight不在cuda上for dilation in dilations:self.aspp.append(ConvModule(self.in_channels,self.channels,1 if dilation == 1 else 3,dilation=dilation,padding=0 if dilation == 1 else dilation,conv_cfg=self.conv_cfg,norm_cfg=self.norm_cfg,act_cfg=self.act_cfg))self.bottleneck = ConvModule((len(dilations)) * self.channels, # (len(dilations) + 1) * self.channels,self.channels,3,padding=1,conv_cfg=self.conv_cfg,norm_cfg=self.norm_cfg,act_cfg=self.act_cfg)# self.conv_seg = nn.Conv2d(channels, num, kernel_size=1)def forward(self, x):"""Forward function."""aspp_outs = []# print(len(self)) ## print(len(self.aspp)) #4for i in range(len(self.aspp)):# print(x.shape) #[N,2048,64,64]aspp_outs.append(self.aspp[i](x)) #4个【256,H/,W/】# print(len(aspp_outs))# print("#########")aspp_outs = torch.cat(aspp_outs, dim=1) # (4,2560,60,60)feats = self.bottleneck(aspp_outs) # (4,512,60,60)# output = self.conv_seg(feats)return feats
上采样4倍,输出[256,H/8,W/8]
2.进行resize 修改尺寸
x_vfb1 = resize(x_vfb1, # self.image_pool(output),size=x_vfb[0].size()[2:],mode='bilinear',align_corners=self.align_corners)
3.将低级特征图和高级特征图融合,低级特征图尺寸[256,H/4,W/4]
x_vfb = torch.cat([x_vfb1,x_vfb[0]], dim=1)
输出[512,H/4,W/4]
4.同理,将其应用在NFB分支
5.两分支concat
其中遇到一个坑点,已解决here
至此骨干网络搭建完毕,利用分类头进行测试
利用FCN测试
decode_head=dict(type='FCNHead',in_channels=256,in_index=2,channels=256,num_convs=0, # num_convs=0,assert self.in_channels == self.channelsconcat_input=True,dropout_ratio=0.1,num_classes=2,norm_cfg=norm_cfg,align_corners=False,loss_decode=dict(type='DiceLoss', use_sigmoid=False, loss_weight=1.0)),
2.2解码头
虽然我们上一步利用简单的FCN分割头实现,这一步,我们实现双注意力机制分割头,MMSeg代码中有给出。
我们只需要配置如下:
decode_head=dict(type='DAHead',in_channels=256,in_index=2,channels=128,pam_channels=64,dropout_ratio=0.1,num_classes=2,norm_cfg=norm_cfg,align_corners=False,loss_decode=dict(type='DiceLoss', use_sigmoid=False, loss_weight=1.0)),
至此模型搭建结束
关于其他细节,会在其他文件中讲到。