mapreduce
2024/9/13 22:41:56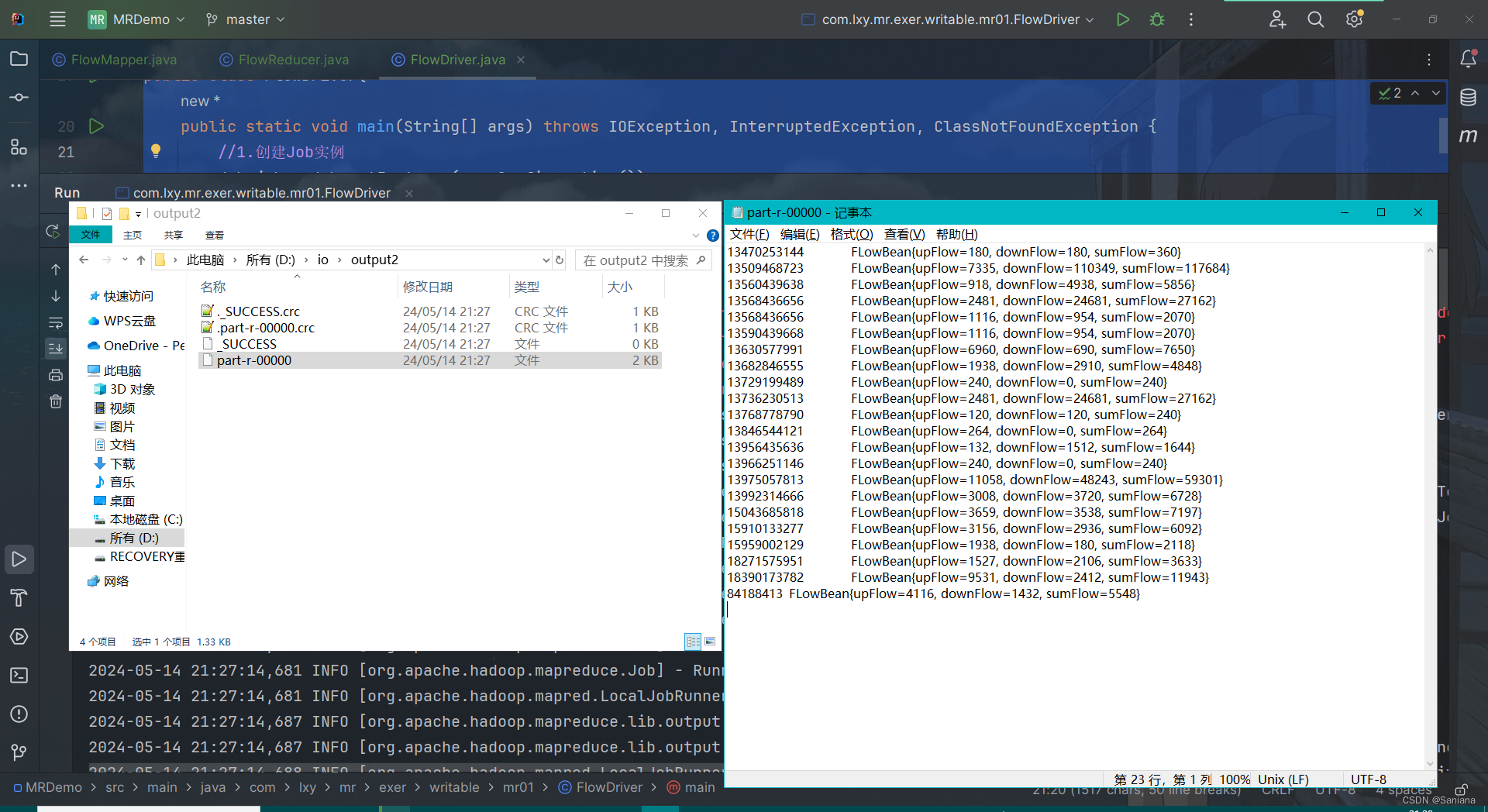
MapReduce代码
WordCount
数据准备:
a.txt
lxy lxy
lxy zhang
wsoossj liagn
guui
liang
liagn代码(在idea中创建一个Maven工程):
mapper:
package com.lxy.mr.wordcount.thi;import org.apache.hadoop.io.LongWritable;
import…

大数据-80 Spark 简要概述 系统架构 部署模式 与Hadoop MapReduce对比
点一下关注吧!!!非常感谢!!持续更新!!!
目前已经更新到了:
Hadoop(已更完)HDFS(已更完)MapReduce(已更完&am…
![【Hadoop】- MapReduce YARN 初体验[9]](https://img-blog.csdnimg.cn/direct/f09935e8bade4d16a28d0d5ce9f9e616.png)
【Hadoop】- MapReduce YARN 初体验[9]
目录
提交MapReduce程序至YARN运行
1、提交wordcount示例程序
1.1、先准备words.txt文件上传到hdfs,文件内容如下:
1.2、在hdfs中创建两个文件夹,分别为/input、/output
1.3、将创建好的words.txt文件上传到hdfs中/input
1.4、提交MapR…

MapReduce概述
批处理模式
首先我们需要先了解一个概念:批处理模式 批处理模式是一种最早进行大规模数据处理的模式。 批处理非常适合需要访问整个数据集合才能完成的计算工作。 批处理主要操作大规模静态数据集,并在整体数据处理完毕后返回结果。 例如,在计算总数和平均数时,必须…
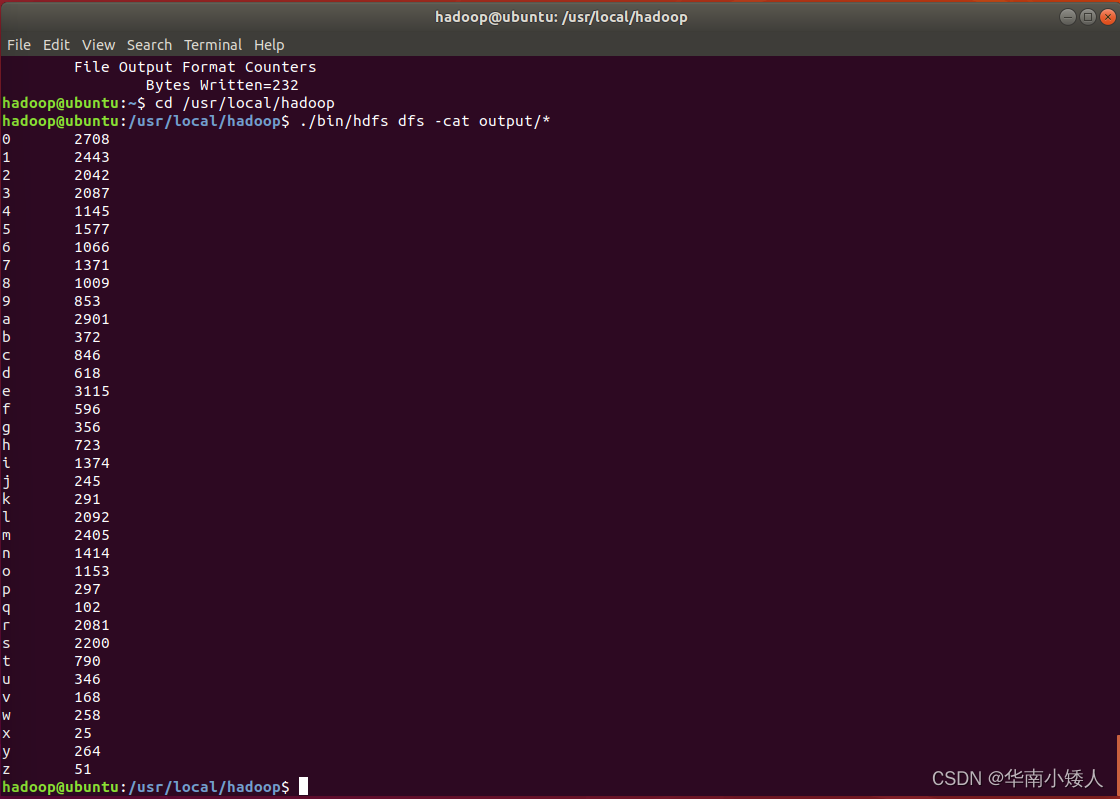
Hadoop实战——MapReduce-字符统计(超详细教学,算法分析)
目录
一、前提准备工作
启动hadoop集群
二、实验过程
1.虚拟机安装先设置端口转发
2.上传对应文件
3.编写Java应用程序
4. 编译打包程序
5. 运行程序
三、算法设计和分析
算法设计
算法分析
四、实验总结 实验目的:给定一份英文文本,统计每个…
![[Go]通用的 MapReduce 工具函数](/images/no-images.jpg)
[Go]通用的 MapReduce 工具函数
前言
最近在测试学习 aws s3 sdk 中的 Multi Part Upload 功能,其基本步骤就是 CreateMultipartUpload 后, 串行或并行地 UploadPart ,最后 CompleteMultipartUpload 或 AbortMultipartUpload 收尾。为了最高效率地完成整个传输,…
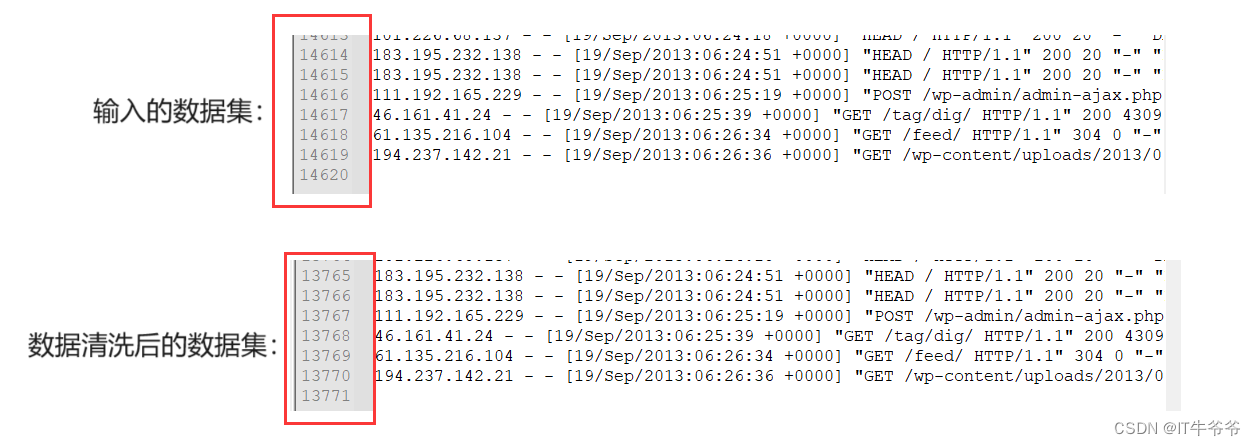
数据清洗(ETL)案例实操
文章目录 数据清洗(ETL)概述案例需求和分析代码实现和结果分析 数据清洗(ETL)概述
“ETL,是英文Extract-Transform-Load的缩写,用来描述将数据从来源端经过抽取(Extract)、转换&…
Hadoop的streamingAPI与MapReduce[Python]
文章目录 1.创建模拟文本2. 使用mapperduce统计标签分布和抽取指定标签3. 运行Map函数并排序结果以模拟Reduce任务:4.运行在无网络开发机上 1.创建模拟文本
1.1 机器模拟生成
from collections import namedtuple
from faker import Faker# 初始化Faker
fake Fak…
[Go]通用的 MapReduce 工具函数
前言
最近在测试学习 aws s3 sdk 中的 Multi Part Upload 功能,其基本步骤就是 CreateMultipartUpload 后, 串行或并行地 UploadPart ,最后 CompleteMultipartUpload 或 AbortMultipartUpload 收尾。为了最高效率地完成整个传输,…

【Tools】什么是MapReduce
我们从不正视那个问题 那一些是非题 总让人伤透脑筋 我会期待 爱盛开那一个黎明 一定会有美丽的爱情 🎵 范玮琪《是非题》 MapReduce是一种用于处理和生成大规模数据集的编程模型和算法,它由Google公司提出并广泛应用于分布式计算领…
MapReduce概述
批处理模式
首先我们需要先了解一个概念:批处理模式 批处理模式是一种最早进行大规模数据处理的模式。 批处理非常适合需要访问整个数据集合才能完成的计算工作。 批处理主要操作大规模静态数据集,并在整体数据处理完毕后返回结果。 例如,在计算总数和平均数时,必须…
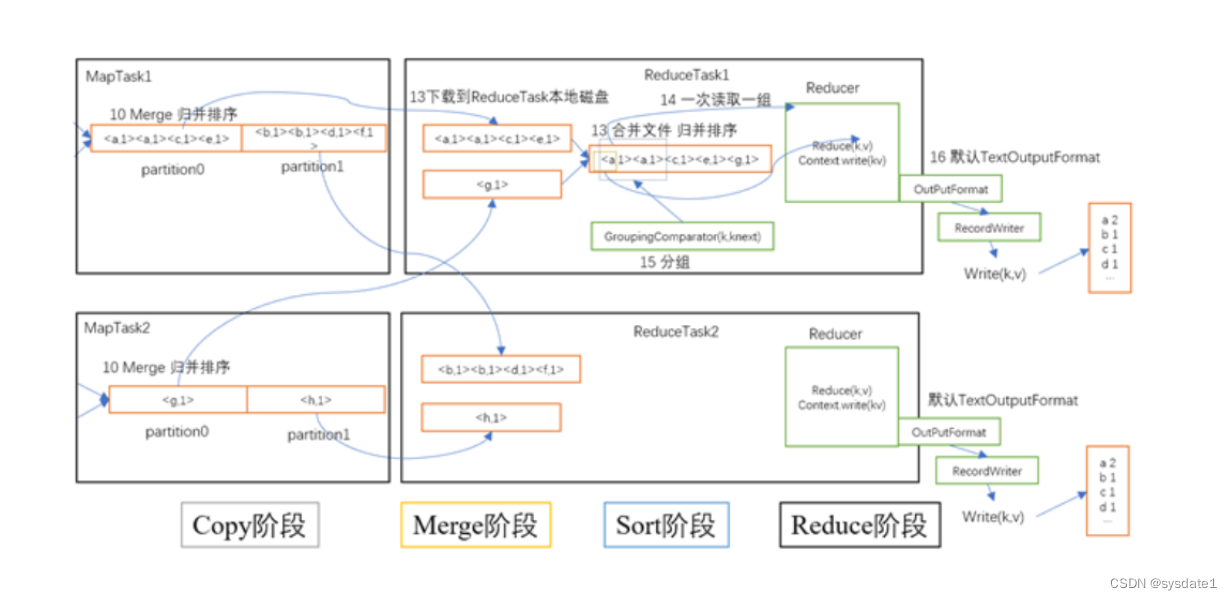
MapReduce 机理
1.hadoop 平台进程
Namenode进程:
管理者文件系统的Namespace。它维护着文件系统树(filesystem tree)以及文件树中所有的文件和文件夹的元数据(metadata)。管理这些信息的文件有两个,分别是Namespace 镜像文件(Namespace image)和操作日志文件(edit log)ÿ…
hadoop基础之MapReduce的学习
hadoop基础之MapReduce的学习
MapReduce的执行步骤:
1.Map
package com.shujia.mr.worcount;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapp…
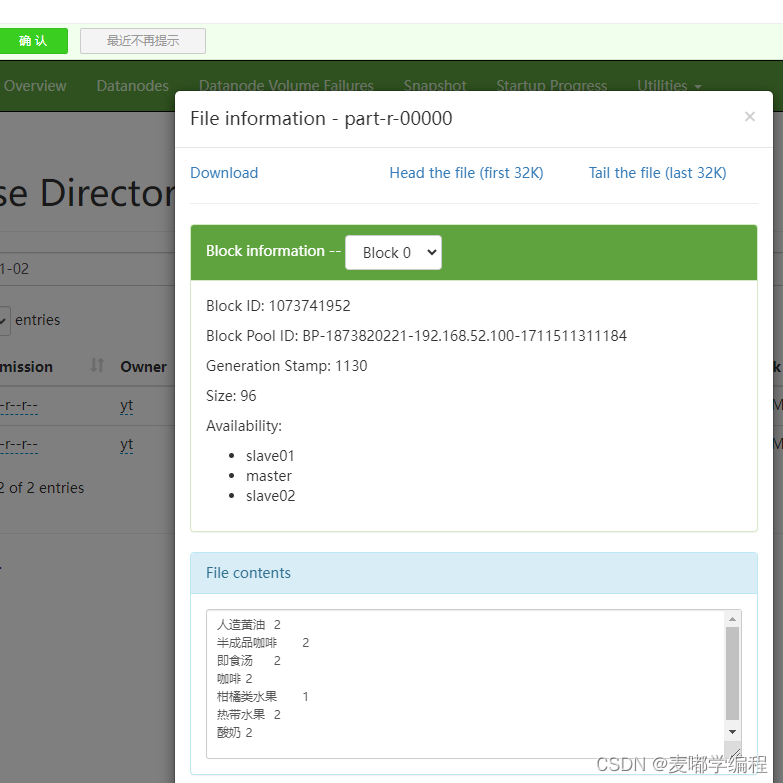
19 使用MapReduce编程统计超市1月商品被购买的次数
首先将1月份的订单数据上传到HDFS上,订单数据格式 ID Goods两个数据字段构成 将订单数据保存在order.txt中,(上传前记得启动集群)。 打开Idea创建项目 修改pom.xml,添加依赖
<dependencies><dependency>…