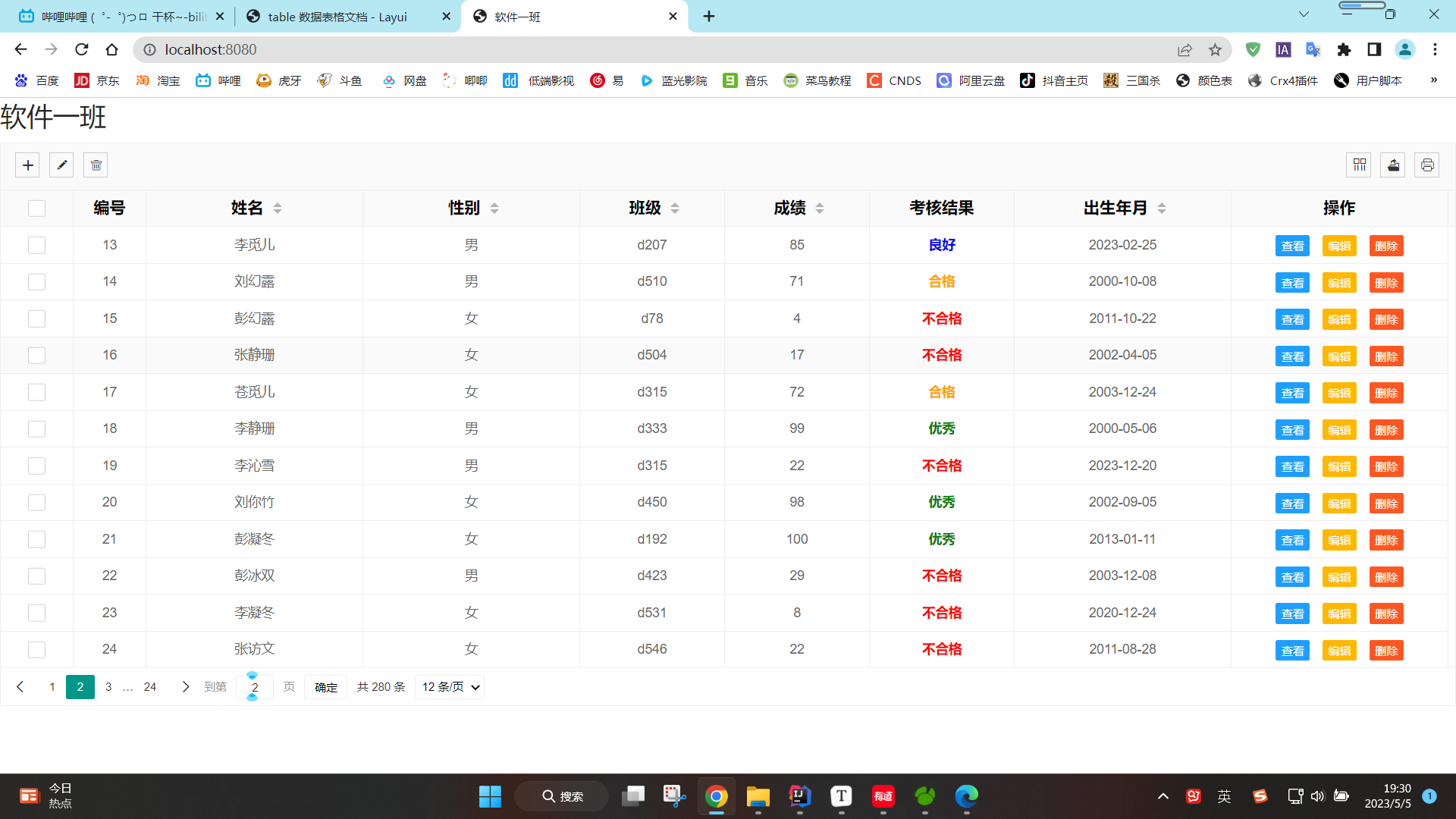
本篇文章发表于NeurIPS 2023 (oral),作者来自于MIT。
文章链接:https://arxiv.org/abs/2306.17844


一、概述
目前,多模态大语言模型的出现为人工智能带来新一轮发展,相关理论也逐渐从纸面走向现实,影响着人们日常生活的方方面面。在享受着技术提供给我们福利的同时,人们也在不断尝试去探索这些模型/算法背后的原理究竟是什么,不禁思考这样几个问题:
- 神经网络解决问题的具体机制是什么?
- 这种机制是否和我们现实生活中解决问题的方式是一致的(是否是人类可理解的)?
- 影响神经网络解决问题方式的因素是什么?
这些问题并不新鲜,理解神经网络背后原理/机制的研究在最近几年更是层出不穷。这些研究大概可以分为两类:第一类,对训练好之后的模型进行事后的解释(post-hoc explanation),探索这些模型解决问题的方式,并验证这些方式是否是人类可以理解的。显然,上述几个问题的答案可以通过这种方式获得。与之对应,第二类则是根据人类可理解的机制去设计模型,即,使模型具备所谓的内在可解释性(instrinct interpretabiltiy),比较具有代表性的例子如concept bottleneck models (CBMs)等。本篇博客将讨论重点放在第一类。
为了回答最初的几个问题,本篇文章以模加法(modular addition) —— 如,8+6=2 (mod 12) ——为例,对训练好的网络所学习到的算法进行逆向工程(reverse-engineering),尝试寻找神经网络进行模加法运算的原理。
研究发现,即使是执行像模加法这样简单的任务,神经网络的机制也十分复杂,并且也不仅仅局限于单一的解决方案。在不同条件下(如不同的模型超参数、模型大小、数据集规模等),模型的运算机制之间具有巨大差异。这些不同的机制构成了所谓的算法相空间 (algorithm phase space),从其中一种机制跳转为另一种机制的现象被称为“相变(phase transition)”。而在模加法的算法相空间中存在这样两种算法:clock算法和pizza算法。接下来就让我们具体看一下这两种算法。
二、模运算与Clock Algorithm
实验设置:
训练神经网络执行模加法运算,其中
。作者在整篇论文中使用
。在网络中,每一个整数
都有一个对应的embedding vector
。对于两个整数
,它们的embedding
将作为网络的输入,并预测得到categorical output
。经过训练,embedding以及网络参数都将被学习得到。
在实验中,作者在模加法运算任务上训练了两种不同的网络架构:模型A和模型B。
- model A: a one-layer ReLU transformer with constant attention
- model B: a standard one-layer ReLU transformer
由于model A并不包含attention,因此可以将其简单视为以ReLU作为activation function的MLP。
2.1 Review of the Clock Algorithm
作者发现,在模型A和模型B完成训练之后,embedding 通常在由它们的嵌入矩阵 (embedding matrix) 的前两个主成分所构成的平面上呈现出圆形分布。这与以前的工作的发现是一致的。
Formally, where
,
is an integer in
.
Nanda et al.[1] discovered a circuit that uses these circular embeddings to implement an interpretable algorithm for modular arithmetic, which we call the algorithm.
我们可以想象一个时钟,假设现在是上午9点,再过4个小时是下午1点,这个过程实际上就是模加法运算 .时钟(Clock)的运动可以简单地描述一个用来执行模加法运算的算法,将1到12共十二个数字排列在圆形表盘上,每两个连续数字之间的角度是
.对于上述例子而言,计算
以及
并将二者相加,最后的角度对应于
.
Nanda et al.[1]发现model B (standard one-layer ReLU transformer)执行的就是上述的clock algorithm。具体而言,clock algorithm会执行三个步骤:
1. Tokens a and b are embedded as
2. 两个embedding 的polar angles相加并通过三角恒等式得到相加结果
3. 对于每一个candidate output ,对应的logit为
总结如下:
最终,预测输出为 .
(以上三个步骤的具体执行方式请参考文献[1],本篇博客谨作为结论使用。)
Clock algorithm的关键在于,注意力机制可以用来执行乘法运算。然而我们可能会问,当注意力机制缺失时(如model A)会发生什么?
对此,作者研究发现了一些model A违反clock algorithm的证据。实际上,这个情况下model A将不再使用clock algorithm来完成模加法运算,而是使用另一种机制(pizza)。
2.2 Evidence I: Gradient Symmetry
回顾 的表达式:
我们不难发现 的梯度在参数顺序上缺乏permutation symmetry,即
因此,如果我们观察到相反的情况,即,某个算法符合permutation symmetry(上式等号成立),那么这个算法一定不是clock algorithm。
因此,作者计算了输入嵌入向量(input embedding vectors)最大的6个主成分,并计算output logits相对于输入嵌入向量的梯度,最后将计算得到的梯度投影到6个主成分方向上。model A与model B的结果如下图所示。

可以发现由于model B采取的是clock algorithm,因此logits对于不同embedding的梯度是不对称的(对应于图中红色圆点);相反,model A是对称的(图中黄色圆点),这就说明model A采取的一定不是clock algorithm。
2.3 Evidence II: Logit Patterns
除了检查模型的输入,检查模型的输出也揭示了model A与model B的差异。对于每个input pair ,作者可视化了分配给正确标签
的输出logit。

图中的行以作为索引,列以
作为索引。从图中可以看出,model A的correct logits对
有较为明显的依赖性。具体而言,model A每一行的correct logits大致是相同的,但在model B中并没有观察到这种pattern。这再一次表明model A和model B分别对应于不同的算法。
以上两点(2.2, 2.3)都印证了model A与model B之间算法/机制的不同。我们知道model B遵循的是clock算法,那model A遵循的是什么样的算法呢?但不管怎样,model A所遵循的算法一定拥有gradient symmetry以及如Fig.3所示的logit pattern。
在下一节中,作者描述了一种新的解决模加法运算的算法(pizza),并在后续证明model A实施的就是pizza算法。
三、另一种解决方案: the Pizza Algorithm
3.1 The Pizza Algorithm
与Clock算法不同,Pizza算法在embedding形成的圆内而不是在圆周上运行。(作者将这个过程形象地比喻成香肠铺满披萨,也是pizza algorithm名称的由来。)
Pizza算法的基本思想如下图右侧所示。
给定一个固定的标签 ,对于所有
且
,点
位于经过二维平面原点的一条直线上。不同的
可以形成若干条这样的直线,这些直线就将整个披萨切割成一个个小块。具体来说,每两条直线会将披萨切成镜像的两个“披萨片”。接下来,为了执行模运算,网络可以判断两个嵌入向量的平均值
位于哪个切片对中。
Pizza算法也包括三个步骤:
步骤1与Clock算法相同,将token a和b分别嵌入为:
步骤2和步骤3则与Clock算法不同:
步骤2.1,取 和
的平均值,得到
。
在步骤2.2和步骤3中,计算任何可能的输出 的logit
来(隐式地)计算
的极角。为了达到这个目的,一种(较为直观的)方式是取
与
的点积的绝对值,但这个做法在神经网络中并不常见,并且会导致不同的logit pattern,而与我们上面对logit可视化后的结果不一致。
实际上,步骤2.2会将 转换为向量
Note: 实际上就是clock algorithm种 乘以一个因子。
然后步骤3将转换后的向量与output embedding 进行点乘,得到
最后的预测结果依然是.
两种算法之间的关键区别在于二者所需要的非线性操作不同:Clock algorithm需要在步骤2中对输入进行乘法运算;而Pizza只需要绝对值运算,而绝对值运算很容易通过ReLU层实现。因此,如果神经网络在执行乘法时缺乏inductive bias,则模型更有可能实施的是Pizza algorithm而不是Clock algorithm,在后面会具体验证这一点。
3.2 Evidence I: Logit Patterns
由上可见,Clock和Pizza算法在步骤3中都计算了logits ,但是二者有不同的形式。具体来说,与
相比,
有一个额外的乘法因子
。因此,给定
,
依赖于
,但
对
则没有这种依赖关系。
直觉来看,如果 更“长”,则样本更有可能被正确分类,而
的范数依赖于
。这和我们在Fig.3中观察到的现象一致,即model A的logits表现出对
的强烈依赖。
3.3 Evidence II: Clearer Logit Patterns via Circle Isolation
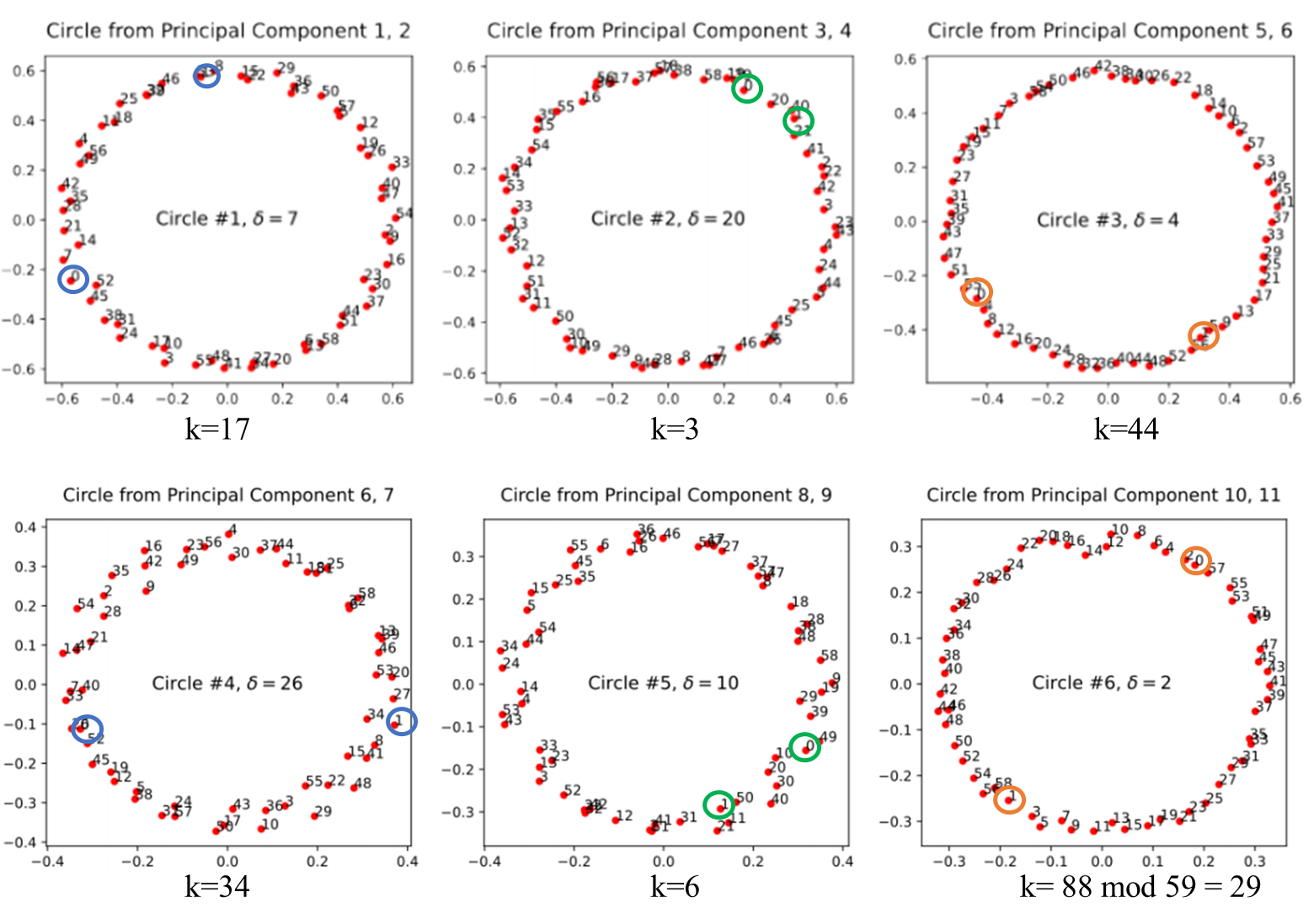
为了更好地理解pizza algorithm,我们将embedding matrix 替换为一系列rank-2矩阵来做近似,即,仅使用第一和第二主成分,或仅使用第三和第四主成分,以此类推。对于每个这样的矩阵,embedding位于一个 2-D 子空间(subspace)中。对于model A 和model B,经过可视化后发现embedding在这个subspace中均呈现出一个圆形,如下图所示。

这个过程称作“circle isolation”。使用近似的rank-2矩阵代替原始embedding,我们发现model A 和model B的预测结果仍然是预期之内的:部分 的预测准确度很高,这取决于isolated circle的周期性。
Note: 周期性可以用 表示,
的值等于两个连续数字之间在circle上的距离,例如上图Circle #1中,数字1和数字2之间的距离为17,Circle #2中则为3;而图中的
则代表相邻两个数字之间的差。
正如Fig.1中Pizza 和 Clock 算法所预测的那样,model A (pizza)的准确性在特定的值处下降到零,而model B (clock)的准确性与
无关。


此外,对于model A来说,我们只使用first 2 principle components所构成的isolated circle对应的embedding替换掉actual embedding,再根据Fig.1中clock与pizza的公式去计算各自的logits,将此结果与model A的actual logits做比较,发现 比
解释了更多的方差。这意味着model A倾向于遵循pizza algorithm而不是clock algorithm.

根据先前的分析,我们可以推测逻辑回归值 不会依赖于
,但并没有预测到它会依赖于
. 但是在上图中,我们预料之外地发现
对
的敏感性。
作者对此的推测是,clock algorithm中的第一步和第二步几乎是无噪声实现的,使得标签 相同的样本在第二步之后会坍缩到同一个点,使得有相同结果的
会产生相同的logits,这解释了上图中每一列的结果几乎是一致的。然而在circle isolation之后,第三步的classification可能并不完善从而导致logits出现波动,因此各个列之间的logits彼此不一致。
3.4 Evidence III: Accompanied & Accompanying Pizza
细心的小伙伴可能会发现,pizza algorithm有一个致命的弱点,就是当 位于circle的对侧时(antipodal,连线经过圆心),那么它们的中点将位于圆点,例如下图中的
,即使它们进行模加法之后会产生不同的结果,但此时模型将完全无法正确分类。即使对于奇数
,此时并没有严格的antipodal pairs,approximately antipodal pairs也比non-antipodal pairs分类更难,因为此时
更短。

有趣的是,对于(approximately) antipodal pairs,神经网络自行找到了一种“聪明”的方式来弥补这种failure mode. 作者发现,pizza通常会与“accompanying pizza”一起出现,accompanied pizza和accompanying pizza在某种意义上互补。原本在accompanied pizza中(approximately) antipodal pairs会在新的accompanying pizza中变得“很不antipodal”。
如果将circle上相邻数字之间的差异表示为 ,accompanied pizza与accompanying pizza上相邻数字之间的差异为
与
,那么二者之间将满足
. 在实验中,作者发现Fig.4 (见下图) 中的pizza #1 #2 #3 都有accompanying pizza,称之为pizza #4 #5 #6。
Note: 也满足二倍关系。

例如,上图最右侧的两个pizza(#3与#6)为accompanied and accompanying pizza, 之间满足取模后的二倍关系,原本位于圆点两侧的antipodal pairs现在变得十分相邻(绿色圆圈)。
Note: 两个pizza之间是单向的accompany关系,而不是互为accompanying pizza!
然而,这些accompanying pizza在最终模型预测中并不起重要作用:
“Accompanied pizzas #1 #2 #3 can achieve 99.7% accuracy, but accompanying pizzas #4 #5 #6 can only achieve 16.7% accuracy.”
作者对训练过程的推测是:
- 在初始化时,pizza #1 #2 #3 对应于三个不同的“lottery tickets”
- 在训练的早期阶段,为了弥补pizza #1 #2 #3 的缺陷(antipodal pairs),形成了pizza #4 #5 #6
- 随着训练的进行(in the presence of weight decay),神经网络被剪枝
最终,pizza #4 #5 #6将不会显著参与预测,尽管它们在embedding space中仍然是visible的。
Note: 判断accompanying pizza是否参与预测可以通过分析embedding的主要频率,即isolated circle对应的frequency 来实现。我们也可以发现,accompanied pizza和accompanying pizza的主要频率是不一致的。
一些题外话,参考文献[1]使用离散傅里叶变换DFT提取embedding matrix的主要频率,而本文是根据visualization来获得 —— 或许此处可以借鉴[1]使用DFT验证两种方式得到的频率是否一致。
四、算法相空间
在上一节中,我们介绍了一个典型的clock algorithm (model B)和一个典型的pizza algorithm (model A)。在本节,作者研究了架构和超参数将如何控制模型在这两个算法之间的选择,并提出了区分Pizza和Clock的量化指标。
4.1 Metrics
根据前面的叙述,我们发现clock algorithm和pizza algorithm具有梯度对称性、以及是否依赖于 的区别,因此作者得出两个指标:gradient symmetricity 和 distance irrelevance.
4.1.1 Gradient Symmetricity
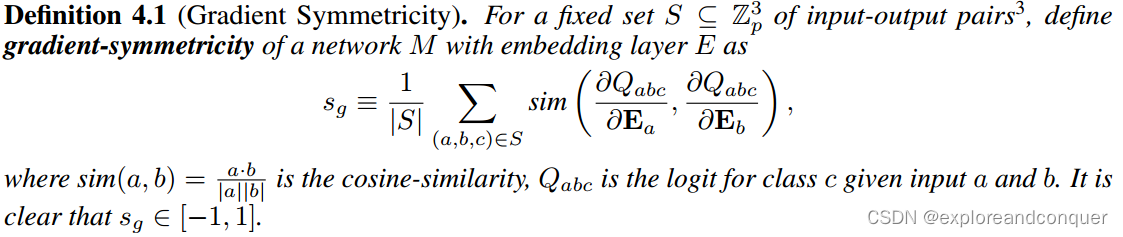
正如在第二节中所讨论的,Pizza算法具有symmetric gradients,而Clock算法具有asymmetric gradients.第三节中model A (pizza)和model B (clock)的梯度对称性分别为99.37%和33.36%,见下图↓

4.1.2 Distance Irrelevance

观察all inputs所对应的correct logits的方差有多少取决于具有相同距离 的input pairs产生的correct logits的方差来衡量distance irrelevance,取值为[0,1],越大代表越不相关。
值越小,代表分子小,也就是说,具有相同距离
的input pairs几乎不产生方差,这意味着logits在
相同时彼此差距很小,即logits依赖于
.
在Fig.3中,model A和model B的distance irrelavance分别是0.17和0.85。

最后作者指出:pizza algorithm的typical distance irrelevance范围为0到0.4(与距离相关),而clock为0.4到1(与距离相关)。
4.1.3 Which Metric is More Decisive?
当两个指标的结果相互冲突时,哪一个更具有决定性?作者认为:
- Distance irrelevance是pizza algorithm的决定性因素,因为依赖于距离的output logits高度暗示了pizza algorithm;
- Gradient symmetricity可以用来排除clock algorithm,因为它需要将输入相乘,而这将导致梯度不对称。
Fig.6证实了在distance irrelevance很低(对应于pizza)的情况下,gradient symmetricity几乎总是接近1(对应于non-clock)。如下图所示,虚线左侧倾向于pizza,右侧倾向于clock.

4.2 Identifying algorithmic phase transitions
模型是如何在clock algorithm和pizza algorithm之间进行选择的呢?
作者通过在model A(transformer without attention)和model B(standard transformer with attention)之间进行interpolation来探索这个问题。为此,引入了一个新的超参数attention rate .
对于attention rate为 的模型,将每个attention head的原注意力矩阵
修改为:
其中 是全1矩阵。也就是说,参数
定义了一批通过线性插值得到的由全1矩阵到original attention (post-softmax)之间的“过渡矩阵”,attention rate
可以控制模型保持多少attention。
对应于全1矩阵,
对应于原始的注意力矩阵。
随后,作者在transformer上进行了以下实验:
- width为128,
从[0,1]中均匀采样的one-layer transformer(Fig.7)
- width为[32,512],
- width为128,
结果如下(Fig.7):
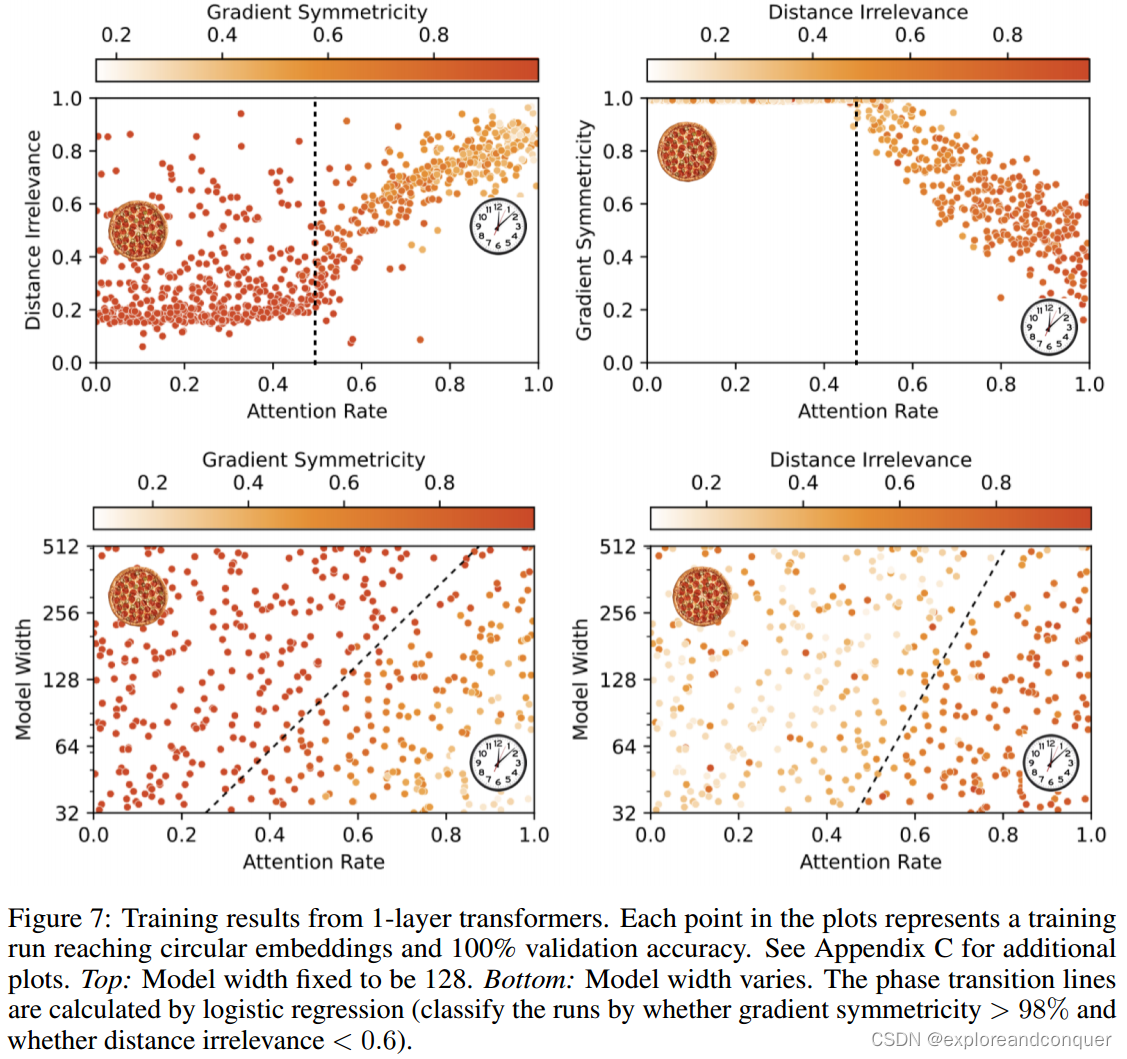
Fig.7上侧的两个图对应于固定width=128的one-layer transformer,下侧对应于width从32变化到512的one-layer transformer.
从Fig.7中我们可以发现:
- 对于circular models,模型要么具有low gradient symmetricity(对应于Clock算法),要么具有low distance irrelevance(对应于Pizza算法)
- 对于fixed width实验,观察到从Pizza算法到Clock算法的phase transition很明显
- 对于attention rate和varied width,phase的边界几乎是线性的。换句话说,随着模型变宽,the attention rate transition point也会增加,在图像上展现为一条倾斜的直线。也就是说,width越宽,越不容易通过增加attention rate使算法从pizza转变为clock。作者对此的解释是,当模型变得更宽时,线性层变得更capable,而注意力机制得到的benefit更少,使得线性层更占主导地位,从而使算法倾向于pizza而不是clock
- 连续的phase变化表明,在clock和pizza算法之间存在着其它networks ——"This is achievable by having some principal components acting as the Clock and some principal components acting as the Pizza." 这可以视为是不同算法的一种集成。
Fig.11:
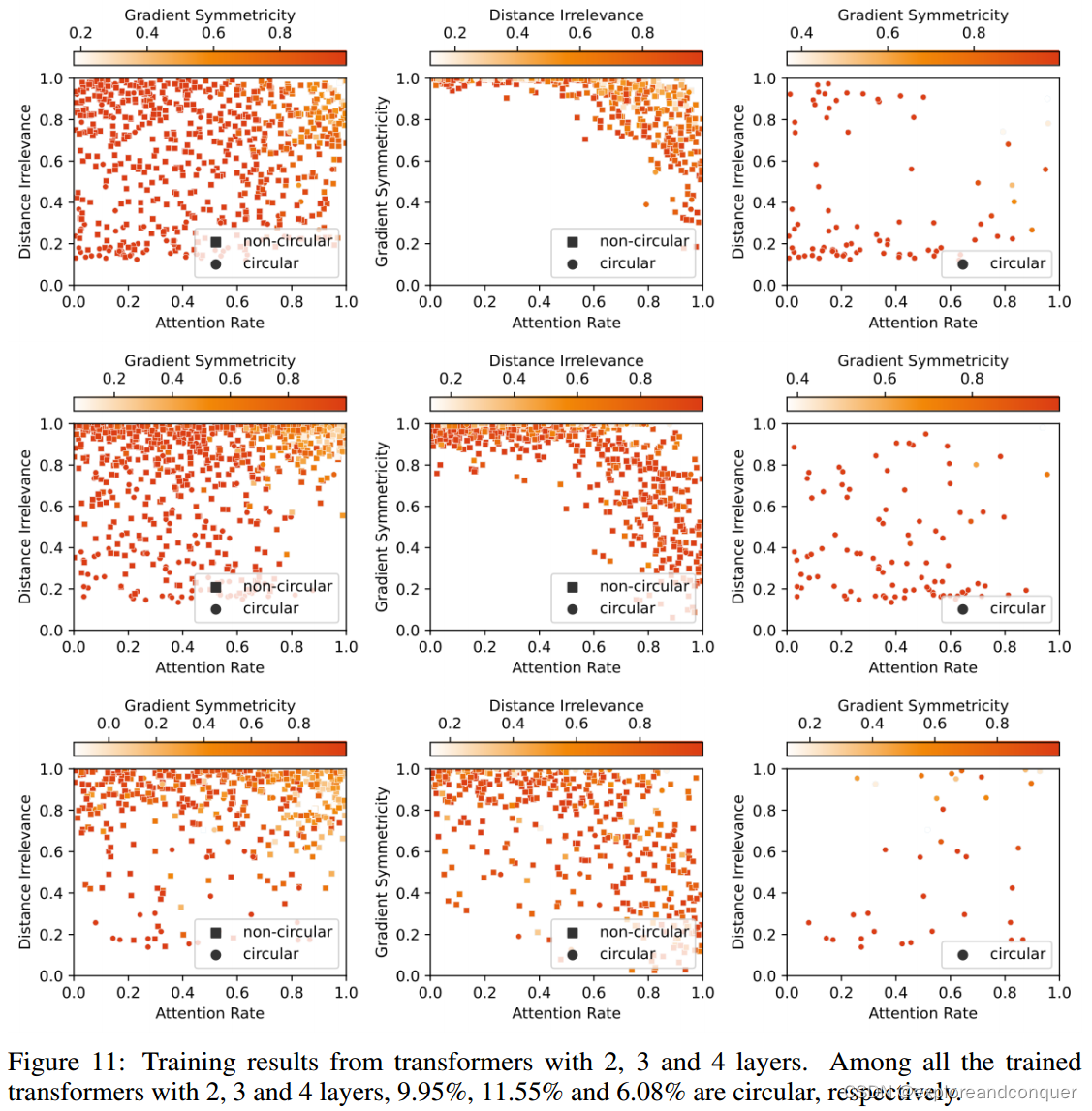
我们还可以发现non-circular algorithms的存在(即,其embedding project到任何平面都不是圆形)。
到这里本篇文章的正文部分基本就讲解完毕了。本文专注于模加法问题,而即使在这个受限的领域中,在不同的architecture和seeds之间也会产生不同的模型行为。要将这些技术扩展到实际任务中使用的更为复杂的模型还需要大量的额外工作。
五、补充材料及问题
本篇论文的supplementary materials中包含着很多有趣且有价值的信息,内容比较多并且我本人也没有全部看过一遍,所以在这里只列举几点。完整的信息请感兴趣的小伙伴自行查阅原论文。
5.1 Supplementary A
Mathematical Analysis and An Example of Pizza Algorithm
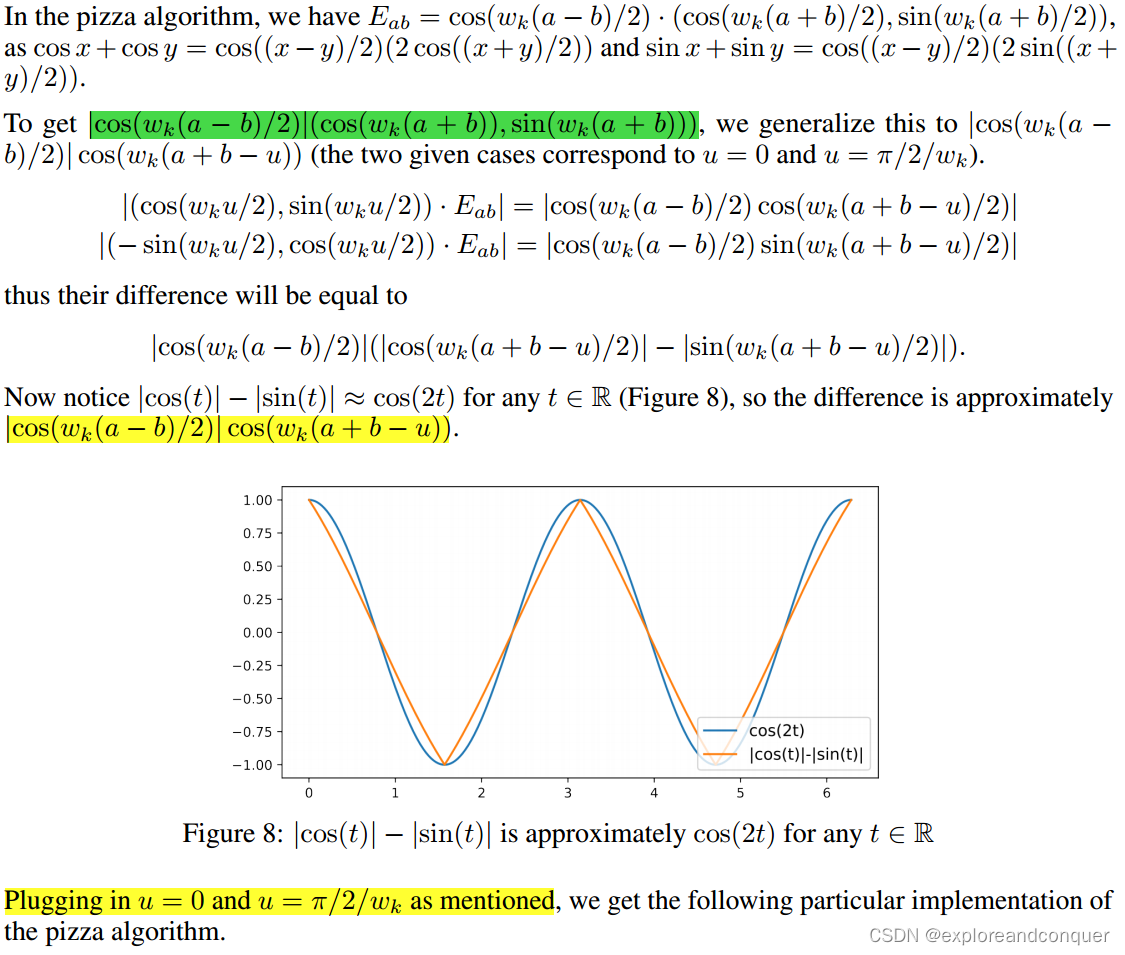
主要涉及一些三角函数的计算,不难,但是这个公式的得出以及近似的那一步需要一些想象力。
- Algorithm: Pizza, Example
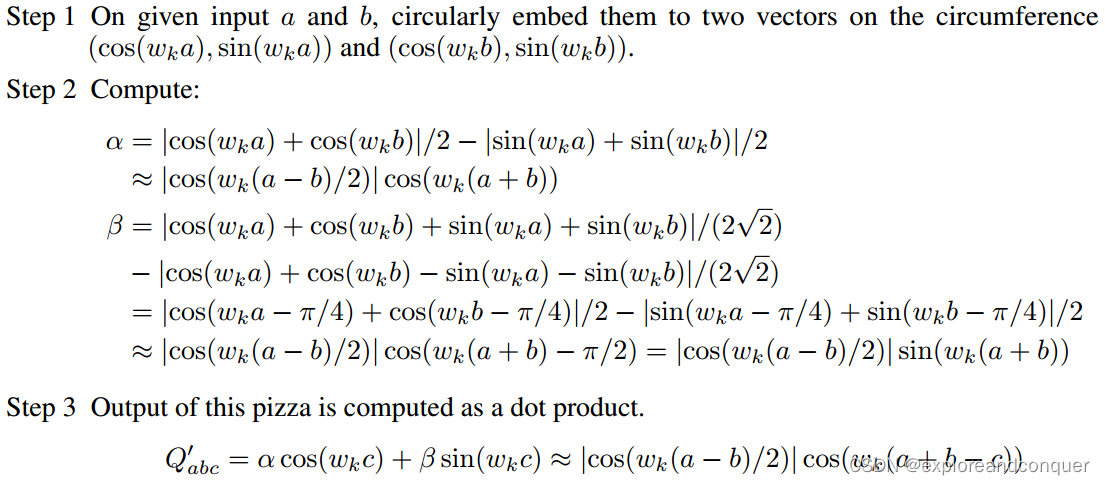
5.2 Supplementary D
Pizza comes in pairs

- Algorithm: Accompanying Pizza

这里再次体现出了accompnying and accompanied pizza角频率 之间的二倍关系。
5.3 Question 1
An Illustration on the Accompanying Pizza Algorithm

可以看到,原先在accompanied circle(左侧)中antipodal的两个点在accompanying circle(右侧)中彼此相邻。
TODO: 作者没有在文中对Fig.12做说明,我也暂时没有完全懂,留着以后再想...
现在仅有的信息是:所谓的negative/positive指的是正/负,当圆心与 ,
二者中点的连线经过圆上的某个点时,结果为负;反之,不经过某点时,则为正。
Note: 再次强调,两个pizza之间只有单向关系,而不是互为accompanying pizza. 比如右图的0和8在左图中并不相邻(adjecent)
5.4 Question 2

作者在这里说accompanying and accompanied pizza拥有相同的 . emmm...我对此表示怀疑。
具体看下图,分别是model A (pizza)的 accompanied and accompanying pizza:
以中间列的两个pizz为例,图中绿色圆圈所示圈出了数字0和数字1,二者的距离就是 . 上面的pizza
,下面的pizza
(如果我没数错的话),可以发现二者仍然呈二倍关系(mod p)。而根据
,二者也呈二倍关系(mod p)。总之
肯定是不同的,而不是作者说的 "Accompanying and accompanied pizza have the same w_k."
不知道这个地方是不是我理解错了,欢迎大家指出。
总体来说还是挺有意思的一篇文章,关于mechanism explanation的文章之前没有看过太多,有机会还是要扩充一下这方面的知识。
Reference
[1] Neel Nanda, Lawrence Chan, Tom Lieberum, Jess Smith, and Jacob Steinhardt. Progress measures for grokking via mechanistic interpretability. In The Eleventh International Conference on Learning Representations, 2023.