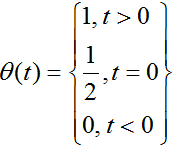本章将介绍一些此书后面常会用到的绘图模式。首先讲解与绘图优化相关的内容,此处涉及“帧资源 (frame resource)”等概念。若采用帧资源,我们就得修改程序中的渲染循环,好处:不必在每一帧都刷新命令队列,继而改善 CPU 和 GPU 的利用率。
接下来,我们会提出渲染项 (render item) 的概念,并解析如何基于更新频率来划分常量数据。
此外,我们将研究根签名的更多细节,并学习其他两种根参数类型:根描述符和根常量。
最后,我们还会展示怎样绘制更为复杂的物体。
完成本章的学习后,将能够绘制出形如山川的表面,还有圆台、球体以及模拟波浪运动的动画。
目标
1. 学会一种无须每帧都要刷新命令队列的渲染流程,由此来优化程序的性能。
2. 了解另外两种根签名参数类型:根描述符和根常量。
3. 探索如何在程序中生成和绘制常见的几何体,如栅格、圆台和球体。
4. 研究怎样通过动态顶点缓冲区来更新 CPU 中的顶点数据,并且向 GPU 上传顶点的新位置信息。
内容整理
1. 帧资源
2. 渲染项
3. 渲染过程中所用到的常量数据
4. 不同形状的几何体
5. 绘制多种几何体演示过程
6. 细探根签名
7. 陆地与波浪演示程序
小结
1. 在每帧中等待 GPU 处理完队列中所有命令的做法效率极低,因为这种策略在某些时刻会导致 CPU 或 GPU 处于空闲状态。一种更有效的技巧是创建帧资源 (frame resource) —— 一个由每帧都需 CPU 来修改的资源所构成的环形数组。这种方法令 CPU 无需等待 GPU 结束当前的任务,即可继续处理下一帧的相关工作;对此,CPU 只需处理下一个可用的(即 GPU 没在使用中的)帧资源。如果 CPU 处理帧的速度总是快于 GPU,则 CPU 必在某些时刻等待 GPU 追赶上来,但此情景又正是我们所期盼的:不仅 GPU 的处理能力将得到充分的发挥,同时,多出来的 CPU 资源又总是可被游戏的其他部分,如 AI,物理模拟与游戏逻辑所利用。
2. 我们可以用 ID3D12DescriptorHeap::GetCPUDescriptorHandleForHeapStart 方法来获取堆中第一个描述符的句柄,通过 ID3D12Device::GetDescriptorHandleIncrementSize 方法得到描述符的大小(依赖于硬件与描述符的类型)。一旦知道了描述符增量的大小,我们就能用两种 CD3DX12_CPU_DESCRIPTOR_HANDLE::Offset 方法之一偏移至第 n 个描述符的句柄处:
// 指定要偏移到的描述符的编号,再将它乘以描述符的增量大小
D3D12_CPU_DESCRIPTOR_HANDLE handle = mCbvHeap->GetCPUDescriptorHandleForHeapStart();
handle.Offset(n * mCbvSrvDescriptorSize);// 或者用另一种等价实现,先指定要偏移到的描述符编号,再设置描述符的增量大小
D3D12_CPU_DESCRIPTOR_HANDLE handle = mCbvHeap->GetCPUDescriptorHandleForHeapStart();
handle.Offset(n, mCbvSrvDescriptorSize);CD3DX12_GPU_DESCRIPTOR_HANDLE 类型有着同样的偏移方法。
3. 根签名定义了在绘制调用开始之前,需要与渲染流水线相绑定的资源,以及这些资源将被映射到的具体着色器输入寄存器。绑定到流水线的具体资源要根据着色器程序来确定。在创建 PSO 后,根签名与着色器程序的组合就开始生效了。根签名由一系列根参数所构成。根参数可以是描述符表、根描述符或根常量。描述符表在堆中指定了一块描述符的连续范围。根描述符用于直接绑定根签名中的描述符(此过程无需涉及描述符堆)。而根常量则用于直接绑定根签名中的常量数据。出于性能的原因,1 个根签名中所能容纳的数据大小被限制为最多 64 DWORD。每个描述符表占 1 DWORD,每个根描述符用 2 DWORD,而每个 32 位的根常量占用 1 DWORD。硬件会为每次绘制调用而自动保存根实参的快照。这样一来,我们就能在每次绘制调用的过程中安全地修改根实参了。但是,我们也应当尽量缩小根签名的规模,以此降低内存间数据的复制量。
4. 当顶点缓冲区的内容在运行时需要频繁更新(比如在每一帧,或每 1/30 秒就要更新一次),动态顶点缓冲区就派上了用场。我们可以使用 UploadBuffer 类来实现动态顶点缓冲区,但这次存储的是顶点数组,而非常量缓冲区数组。由于我们在每一帧都要从 CPU 向波浪动态顶点缓冲区上传新数据,所以需要将动态顶点缓冲区存为一种帧资源。在使用动态顶点缓冲区的过程中,难免会产生一些开销,这是因为新数据必将从 CPU 端内存回传至 GPU 端的显存。因此,在静态顶点缓冲区也可以胜任相同工作的情况下,它会比动态顶点缓冲区更受青睐。对此,Direct3D 的最新版本已经引进了一些新的特性,以减少动态缓冲区的使用。