解析
核心线程数与CPU核数相同:避免线程过多导致的上下文切换,提高CPU利用率。
无界队列:适合任务量大且任务执行时间短的场景,避免因队列满而拒绝任务。
IO密集型任务
场景描述
适用于执行大量IO操作的任务,如文件读写、网络通信、数据库访问等。这类任务在等待IO时线程处于阻塞状态,因此可以通过增加线程数来提高并发度。
线程池配置
核心线程数:根据CPU核数和IO等待时间来调整,通常设置为CPU核数的2倍或更多。
最大线程数:可以设置为更高,取决于系统资源和任务特性。
任务队列:使用有界队列(如
LinkedBlockingQueue),防止过多线程导致资源耗尽。java
import java.util.concurrent.*;public class IOBoundExample {public static void main(String[] args) {int cpuCores = Runtime.getRuntime().availableProcessors();int corePoolSize = cpuCores * 2;int maxPoolSize = cpuCores * 4;long keepAliveTime = 60L;ExecutorService executor = new ThreadPoolExecutor(corePoolSize,maxPoolSize,keepAliveTime, TimeUnit.SECONDS,new LinkedBlockingQueue<Runnable>(1000), // 有界队列new ThreadPoolExecutor.CallerRunsPolicy() // 饱和策略);for (int i = 0; i < 1000; i++) {executor.submit(() -> {// IO密集型任务,例如数据库查询performDatabaseQuery();});}executor.shutdown();}private static void performDatabaseQuery() {// 模拟IO操作System.out.println("Performing DB query by " + Thread.currentThread().getName());try {Thread.sleep(100); // 模拟IO延迟} catch (InterruptedException e) {Thread.currentThread().interrupt();}}
}长时间运行的任务
场景描述
适用于需要长时间处理的任务,如视频处理、数据分析、复杂计算等。这类任务占用线程时间较长,可能导致线程池中的线程被长期占用。
线程池配置
核心线程数:适中,不宜过多,以防止系统资源被长时间占用。
最大线程数:可以适当增加,但需要考虑系统资源限制。
任务队列:使用有界队列,并合理设置队列大小,防止大量长时间任务导致线程池资源耗尽。
import java.util.concurrent.*;public class LongRunningTaskExample {public static void main(String[] args) {int corePoolSize = 4;int maxPoolSize = 8;long keepAliveTime = 120L;ExecutorService executor = new ThreadPoolExecutor(corePoolSize,maxPoolSize,keepAliveTime, TimeUnit.SECONDS,new ArrayBlockingQueue<Runnable>(100), // 有界队列new ThreadPoolExecutor.AbortPolicy() // 饱和策略:拒绝任务);for (int i = 0; i < 50; i++) {executor.submit(() -> {// 长时间任务,例如视频处理processVideo();});}executor.shutdown();}private static void processVideo() {// 模拟长时间处理System.out.println("Processing video by " + Thread.currentThread().getName());try {Thread.sleep(5000); // 模拟长时间任务} catch (InterruptedException e) {Thread.currentThread().interrupt();}}
}网络IO密集:RPC调用通常涉及较多的网络IO,因此线程会存在等待IO的情况。
批量任务拆分:批量操作通常会将大量任务分发到多个节点或服务进行处理,确保每个节点的负载均衡尤为关键。
并发限制:为了避免对单个节点或服务的过度压力,线程池的大小和任务队列的处理策略必须合理控制。
产生进程的情况
服务启动:后端服务启动时,通常会通过操作系统创建一个或多个进程来运行服务。
任务分发:某些服务可能为了处理不同的任务,创建多个子进程来分担负载。例如,处理批量数据、并行计算等。
异步处理:当需要异步处理任务,或处理一些耗时较长的任务时,可以通过创建新的进程来避免阻塞主进程。
多进程架构:一些后端框架(如Django、Flask等)或部署工具(如Gunicorn、uWSGI等)会自动创建多个进程来处理多用户并发请求。
线程池是一种管理多个线程执行的机制,通过复用一组线程来避免频繁创建和销毁线程,节省系统资源。大部分编程语言和框架都会有内置的线程池机制。
在Java中,常用的线程池框架是java.util.concurrent包下的ExecutorService。创建和控制线程池通常涉及以下几个方面:
线程池的创建:
ExecutorService executorService = Executors.newFixedThreadPool(10); // 创建一个固定大小的线程池
FixedThreadPool:固定大小的线程池,适合处理稳定数量的任务。
CachedThreadPool:根据需求动态创建线程池,适合任务负载波动较大的场景。
ScheduledThreadPool:用于调度任务的线程池,支持周期性或延迟执行任务。
SingleThreadExecutor:只有一个线程的线程池,适合顺序执行任务。
线程池的控制:
执行任务:通过
submit()方法提交任务到线程池。
executorService.submit(() -> {// 任务逻辑
});关闭线程池:当不再需要使用线程池时,应该调用shutdown()方法关闭它。
executorService.shutdown();调用shutdown()后,线程池不再接受新任务,但会继续执行已提交的任务。可以使用awaitTermination()方法等待所有任务执行完成。
线程池的参数设置:
核心线程数(Core Pool Size) :线程池中保持活动线程数的最小值。
最大线程数(Maximum Pool Size) :线程池能够容纳的最大线程数量。
线程存活时间(Keep Alive Time) :当线程池中的线程数量超过核心线程数时,多余的空闲线程存活的时间。
任务队列(Task Queue) :当所有线程都在忙时,新的任务会被放入任务队列等待执行。
在创建线程池时可以指定这些参数:
ThreadPoolExecutor executor = new ThreadPoolExecutor(2, // 核心线程数4, // 最大线程数60, // 线程空闲存活时间TimeUnit.SECONDS, // 存活时间的单位new LinkedBlockingQueue<Runnable>() // 任务队列
);控制和调整线程池的参数
根据系统负载和任务类型的不同,选择合适的线程池大小和配置非常重要:
小任务并发:如果任务非常小且耗时短,建议使用较大的线程池和较小的任务队列。
长时间任务:如果任务执行时间较长,建议保持较小的线程池,避免线程上下文切换带来的开销。
队列的选择:常用的任务队列有
LinkedBlockingQueue(无界队列)和SynchronousQueue(直接提交队列)。
总结:
进程通常在服务启动、异步任务或多进程架构中产生。
线程池通过Executor框架创建,常见参数有核心线程数、最大线程数、存活时间和任务队列。
根据任务类型和系统负载选择合适的线程池配置,避免资源浪费或阻塞。
工厂方法模式,抽象工厂模式
模拟单机服务 RedisUtils
public class RedisUtils {private Logger logger = LoggerFactory.getLogger(RedisUtils.class);private Map<String, String> dataMap = new ConcurrentHashMap<>();public String get(String key) {logger.info("Redis获取数据 key: {}", key);return dataMap.get(key);}public String set(String key, String value) {logger.info("Redis写入数据 key:{} val:{}", key, value);dataMap.put(key, value);}public void set(String key, String value, long timeout, TimeUnit timeUNit) {logger.info("Redis写入数据 key:{} val:{} timeout: {} timeUnit: {}", key, value, timeout, timeUnit.toString());dataMap.put(key, value);}public void del(String key) {logger.info("Redis删除数据 key:{}", key);dataMap.remove(key);}
}模拟集群 EGM
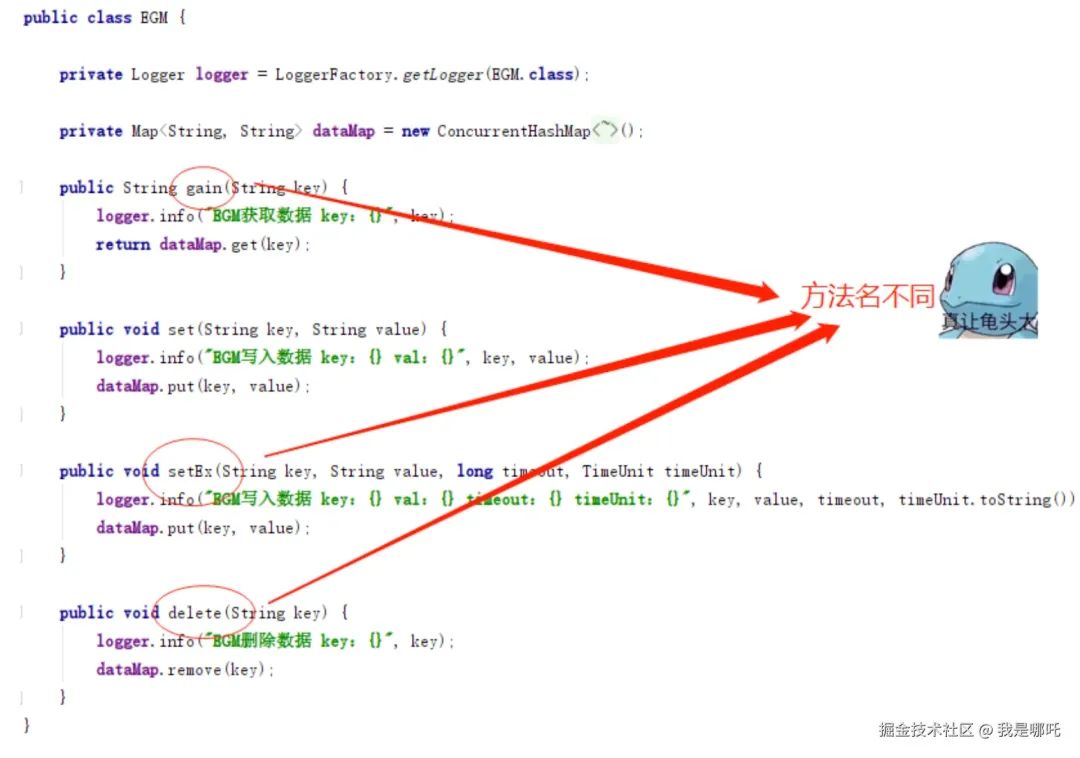
模拟集群 IIR

public interface CacheService {String get(final String key);void set(String key, String value);void set(String key, String value, long timeout, TimeUnit timeUnit);void del(String key);}public class CacheServiceImpl implements CacheService {private RedisUtils redisUtils = new RedisUtils();public String get(String key) {return redisUtils.get(key);}public void set(String key, String value) {redisUtils.set(key, value);}
public void set(String key, String value, long timeout, TimeUnittimeUnit) {redisUtils.set(key, value, timeout, timeUnit);}public void del(String key) {redisUtils.del(key);}}抽象⼯⼚模型结构
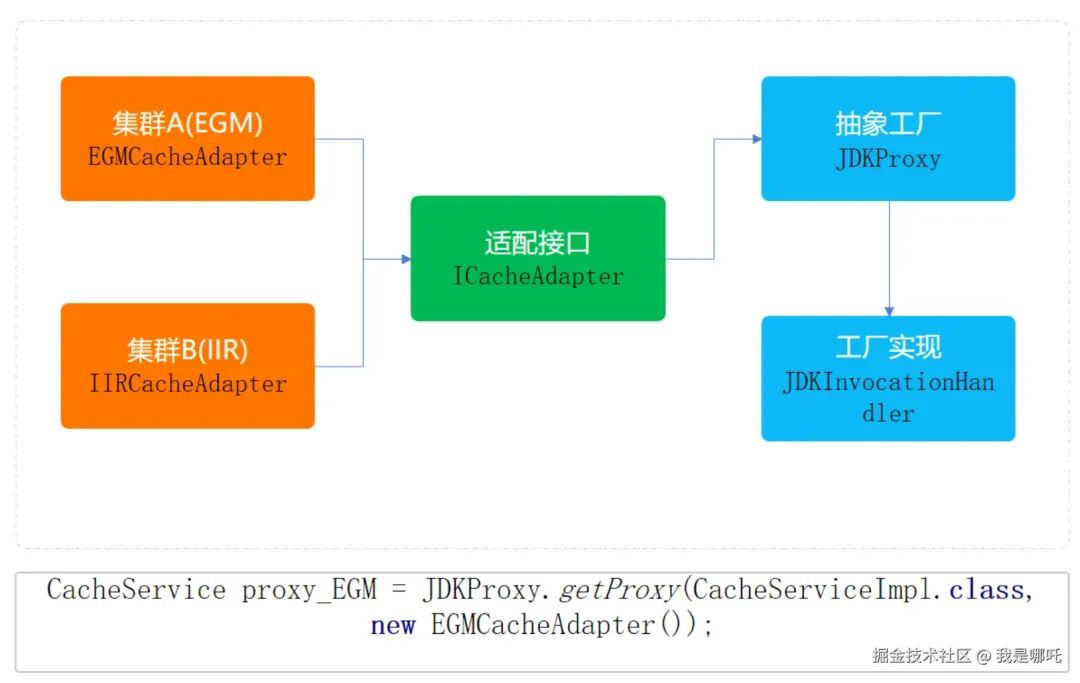
public interface ICacheAdapter {String get(String key);void set(String key, String value);void set(String key, String value, long timeout, TimeUnit timeUnit);void del(String key);}单⼀职责、开闭原则、解耦等优点
建造者模式
架构选型 、 功能设计 、 设计评审 、
代码实现 、 代码评审 、 单测覆盖率检查 、 编写⽂档 、 提交测试 。
原型模式介绍
public class ChoiceQuestion {private String name; // 题⽬private Map<String, String> option; // 选项;A、B、C、Dprivate String key; // 答案;Bpublic ChoiceQuestion() {}public ChoiceQuestion(String name, Map<String, String> option, Stringkey) {this.name = name;this.option = option;this.key = key;}// ...get/set}public class AnswerQuestion {private String name; // 问题private String key; // 答案public AnswerQuestion() {}public AnswerQuestion(String name, String key) {this.name = name;this.key = key;}// ...get/set}原型模式主要解决的问题就是创建⼤量᯿复的类,⽽我们模拟的场景就需要给不同的⽤户都创建相同的
试卷,但这些试卷的题⽬不便于每次都从库中获取,甚⾄有时候需要从远程的RPC中获取。这样都是⾮
常耗时的,⽽且随着创建对象的增多将严᯿影响效率。
在原型模式中所需要的⾮常᯿要的⼿段就是克隆,在需要⽤到克隆的类中都需要实现 implements
Cloneable 接⼝。
懒汉模式(线程不安全)
public class Singleton_01 {private static Singleton_01 instance;private Singleton_01() {}public static Singleton_01 getInstance(){if (null != instance) return instance;instance = new Singleton_01();return instance;}}单例模式有⼀个特点就是不允许外部直接创建,也就是 new Singleton_01() ,因此这⾥在默认
的构造函数上添加了私有属性 private 。
⽬前此种⽅式的单例确实满⾜了懒加载,但是如果有多个访问者同时去获取对象实例你可以想象成
⼀堆⼈在抢厕所,就会造成多个同样的实例并存,从⽽没有达到单例的要求。
懒汉模式(线程安全)
public class Singleton_02 {private static Singleton_02 instance;private Singleton_02() {}public static synchronized Singleton_02 getInstance(){if (null != instance) return instance;instance = new Singleton_02();return instance;}}此种模式虽然是安全的,但由于把锁加到⽅法上后,所有的访问都因需要锁占⽤导致资源的浪费。
如果不是特殊情况下,不建议此种⽅式实现单例模式。
饿汉模式(线程安全)
public class Singleton_03 {private static Singleton_03 instance = new Singleton_03();private Singleton_03() {}public static Singleton_03 getInstance() {return instance;}}此种⽅式与我们开头的第⼀个实例化 Map 基本⼀致,在程序启动的时候直接运⾏加载,后续有外
部需要使⽤的时候获取即可。
但此种⽅式并不是懒加载,也就是说⽆论你程序中是否⽤到这样的类都会在程序启动之初进⾏创
建。
那么这种⽅式导致的问题就像你下载个游戏软件,可能你游戏地图还没有打开呢,但是程序已经将
这些地图全部实例化。到你⼿机上最明显体验就⼀开游戏内存满了,⼿机卡了,需要换了。
使⽤类的内部类(线程安全)
public class Singleton_04 {private static class SingletonHolder {private static Singleton_04 instance = new Singleton_04();}private Singleton_04() {}public static Singleton_04 getInstance() {return SingletonHolder.instance;}}使⽤类的内部类(线程安全)
public class Singleton_04 {private static class SingletonHolder {private static Singleton_04 instance = new Singleton_04();}private Singleton_04() {}public static Singleton_04 getInstance() {return SingletonHolder.instance;}}使⽤类的静态内部类实现的单例模式,既保证了线程安全有保证了懒加载,同时不会因为加锁的⽅
式耗费性能。
这主要是因为JVM虚拟机可以保证多线程并发访问的正确性,也就是⼀个类的构造⽅法在多线程环境下可以被正确的加载。
双重锁校验(线程安全)
public class Singleton_05 {private static Singleton_05 instance;private Singleton_05() {}public static Singleton_05 getInstance(){if(null != instance) return instance;synchronized (Singleton_05.class){if (null == instance){instance = new Singleton_05();}}return instance;}}双重锁的⽅式是⽅法级锁的优化,减少了部分获取实例的耗时
CAS「AtomicReference」(线程安全)
java并发库提供了很多原⼦类来⽀持并发访问的数据安全
性; AtomicInteger 、 AtomicBoolean 、 AtomicLong 、 AtomicReference 。
AtomicReference 可以封装引⽤⼀个V实例,⽀持并发访问如上的单例⽅式就是使⽤了这样的⼀个
特点。
使⽤CAS的好处就是不需要使⽤传统的加锁⽅式保证线程安全,⽽是依赖于CAS的忙等算法,依赖
于底层硬件的实现,来保证线程安全。相对于其他锁的实现没有线程的切换和阻塞也就没有了额外
的开销,并且可以⽀持较⼤的并发性。
当然CAS也有⼀个缺点就是忙等,如果⼀直没有获取到将会处于死循环中。
结构型模式包括:适配器、桥接、组合、装饰器、外观、享元、代理,这7类。
⼀个框架随着时间的发展,它的复杂程度是越来越⾼的
适配器模式的主要作⽤就是把原本不兼容的接⼝,通过适配修改做到统⼀。
⽽这时候就会需要做⼀些营销系统,⼤部分常⻅的都是裂变、拉客,例如;你邀请⼀个⽤户开户、或者
邀请⼀个⽤户下单,那么平台就会给你返利,多邀多得。同时随着拉新的量越来越多开始设置每⽉下单
都会给⾸单奖励,等等,各种营销场景。
查询⽤户内部下单数量接⼝
public class OrderService {private Logger logger =LoggerFactory.getLogger(POPOrderService.class);public long queryUserOrderCount(String userId){logger.info("⾃营商家,查询⽤户的订单是否为⾸单:{}", userId);return 10L;}}查询⽤户第三⽅下单⾸单接⼝
public class POPOrderService {private Logger logger =LoggerFactory.getLogger(POPOrderService.class);public boolean isFirstOrder(String uId) {logger.info("POP商家,查询⽤户的订单是否为⾸单:{}", uId);return true;}}
统⼀的MQ消息体
public class RebateInfo {private String userId; // ⽤户IDprivate String bizId; // 业务IDprivate Date bizTime; // 业务时间private String desc; // 业务描述// ... get/set}桥接模式
public class PayController {private Logger logger = LoggerFactory.getLogger(PayController.class);public boolean doPay(String uId, String tradeId, BigDecimal amount,int channelType, int modeType) {// 微信⽀付if (1 == channelType) {logger.info("模拟微信渠道⽀付划账开始。uId:{} tradeId:{} amount:{}", uId, tradeId, amount);if (1 == modeType) {logger.info("密码⽀付,⻛控校验环境安全");} else if (2 == modeType) {logger.info("⼈脸⽀付,⻛控校验脸部识别");} else if (3 == modeType) {logger.info("指纹⽀付,⻛控校验指纹信息");
}}// ⽀付宝⽀付else if (2 == channelType) {logger.info("模拟⽀付宝渠道⽀付划账开始。uId:{} tradeId:{}amount:{}", uId, tradeId, amount);if (1 == modeType) {logger.info("密码⽀付,⻛控校验环境安全");} else if (2 == modeType) {logger.info("⼈脸⽀付,⻛控校验脸部识别");} else if (3 == modeType) {logger.info("指纹⽀付,⻛控校验指纹信息");}}return true;}}1. 高并发、短时间任务
场景描述
适用于处理大量独立且执行时间较短的任务,例如Web请求处理、快速计算等。这类任务通常是CPU密集型的,执行时间短,且数量庞大。
线程池配置
核心线程数:与CPU核心数相同,避免过度创建线程导致上下文切换开销。
最大线程数:一般设置为与核心线程数相同或略高。
任务队列:使用无界队列(如
LinkedBlockingQueue),避免因为任务量大而频繁创建和销毁线程。
import java.util.concurrent.*;public class HighConcurrencyExample {public static void main(String[] args) {int cpuCores = Runtime.getRuntime().availableProcessors();ExecutorService executor = new ThreadPoolExecutor(cpuCores, // 核心线程数cpuCores, // 最大线程数0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>() // 无界队列);for (int i = 0; i < 1000; i++) {executor.submit(() -> {// 短时间任务,例如处理一个请求processRequest();});}executor.shutdown();}private static void processRequest() {// 模拟处理请求System.out.println("Processing request by " + Thread.currentThread().getName());}
}Tomcat 默认使用的线程池参数如下:
最大线程数 (
maxThreads) : 200最小空闲线程数 (
minSpareThreads) : 10最大排队请求 (
acceptCount) : 100线程等待超时 (
connectionTimeout) : 20000 毫秒(20 秒)
不过,如果你希望为所有连接器使用共享的线程池,可以在 server.xml 中配置一个全局的 Executor,如下:
<Executor name="tomcatThreadPool" namePrefix="catalina-exec-"maxThreads="150" minSpareThreads="4"/>
<Connector port="8080" protocol="HTTP/1.1"connectionTimeout="20000"redirectPort="8443"executor="tomcatThreadPool" />加群联系作者vx:xiaoda0423
仓库地址:github.com/webVueBlog/…