目录
JDBC进阶
实体类和ORM
主键回显
批量操作
连接池
介绍
常见的连接池
Druid连接池
Hikari连接池
连接池与软编码
其他配置
Druid配置
Hikari配置
JDBC进阶
实体类和ORM
在使用JDBC操作数据库时会发现数据都是零散的,明明在数据库中是一行完整的数据,到了Java中变成了一个一个的变量,不利于维护和管理。但是Java是面向对象的,一个表对应的是一个类,一行数据就对应的是Java中的一个对象,一个列对应的是对象的属性,所以需要把数据存储在一个载体里,这个载体就是实体类
ORM(Object Relational Mapping)思想:对象到关系数据库的映射,作用是在编程中,把面向对象的概念跟数据库中表的概念对应起来,以面向对象的角度操作数据库中的数据,即一张表对应一个类,一行数据对应一个对象,一个列对应一个属性
当下JDBC中这种过程称其为手动ORM。后续也会学习ORM框架,比如MyBatis、JPA等。
使用ORM思想优化基础部分六大基本步骤:
- 创建对象,一个表就是一个类,表名中表示抽象事物的即为类名,例如
t_employee对应类名即为Employee - 将原有「接受一个一个变量逐个打印」的方式更改为「值对应对象的成员属性」
一般实体类会放在一个名为 pojo的包内部
表对应类:
java">@Data
@AllArgsConstructor
@NoArgsConstructor
public class Employee {private Integer empId;private String empName;private Double empSalary;private Integer empAge;
}优化六大基本步骤:
java">public class TestORM {@Testpublic void test() throws Exception{// 创建数据库连接Connection connection = DriverManager.getConnection("jdbc:mysql:///databaseTest", "root", "123456");// 预编译SQLPreparedStatement preparedStatement = connection.prepareStatement("SELECT * FROM t_emp WHERE emp_age = 26");// 获取结果ResultSet resultSet = preparedStatement.executeQuery();// 创建对象引用Employee employee = null;// 遍历结果将数据存储到对象中if(resultSet.next()) {// 创建对象employee = new Employee();// 获取值int empId = resultSet.getInt("emp_id");String empName = resultSet.getString("emp_name");double empSalary = resultSet.getDouble("emp_salary");int empAge = resultSet.getInt("emp_age");// 将获取到的值存储到对象中employee.setEmpId(empId);employee.setEmpName(empName);employee.setEmpSalary(empSalary);employee.setEmpAge(empAge);// 上面的也可以直接用构造方法// employee = new Employee(resultSet.getInt("emp_id"),// resultSet.getString("emp_name"),// resultSet.getDouble("emp_salary"),// resultSet.getInt("emp_id"));System.out.println(employee);}// 关闭资源resultSet.close();preparedStatement.close();connection.close();}
}如果有多行数据,则可以考虑使用集合,例如ArrayList集合:
java">public class TestORM01 {@Testpublic void test() throws Exception{// 创建数据库连接Connection connection = DriverManager.getConnection("jdbc:mysql:///databaseTest", "root", "123456");// 预编译SQLPreparedStatement preparedStatement = connection.prepareStatement("SELECT * FROM t_emp");// 获取结果ResultSet resultSet = preparedStatement.executeQuery();// 创建对象引用Employee employee = null;ArrayList<Employee> employees = new ArrayList<>();// 遍历结果将数据存储到对象中while (resultSet.next()) {// 上面的也可以直接用构造方法employee = new Employee(resultSet.getInt("emp_id"),resultSet.getString("emp_name"),resultSet.getDouble("emp_salary"),resultSet.getInt("emp_id"));employees.add(employee);}// 显示结果employees.stream().forEach(System.out::println);// 也可以不用Stream流,因为集合中已经有forEach方法,所以等价于下面的代码// employees.forEach(System.out::println);// 关闭资源resultSet.close();preparedStatement.close();connection.close();}
}主键回显
在数据中,执行新增操作时,主键列为自动增长,可以在表中直观的看到,但是在Java程序中执行完新增后,只能得到受影响行数,无法得知当前新增数据的主键值。
在Java程序中获取数据库中插入新数据后的主键值,并赋值给Java对象的操作称为主键回显
需要实现主键回显,就需要在创建PreparedStatement对象时传递一个参数Statement.RETURN_GENERATED_KEYS,该参数表示返回生成的主键,而在插入成功后就可以通过对应的PreparedStatement对象通过getGeneratedKeys()方法获取到一个结果集,但是这个结果集是一个单行单列的,并且因为不知道其表头名,所以需要通过列标的方式获取
例如下面的代码:
java">public class ReflectPrimKey {@Testpublic void test() throws Exception{Connection connection = DriverManager.getConnection("jdbc:mysql:///databaseTest", "root", "123456");PreparedStatement preparedStatement = connection.prepareStatement("insert into t_emp (emp_id, emp_name, emp_salary, emp_age) values (NULL, '李四', 2000, 20)", Statement.RETURN_GENERATED_KEYS);int i = preparedStatement.executeUpdate();if(i > 0) {System.out.println("插入成功");Employee employee = null;// 主键回显填充到对象ResultSet generatedKeys = preparedStatement.getGeneratedKeys();if (generatedKeys.next()) {int pk = generatedKeys.getInt(1);PreparedStatement preparedStatement1 = connection.prepareStatement("SELECT * FROM t_emp where emp_id = ?");preparedStatement1.setInt(1, pk);ResultSet resultSet = preparedStatement1.executeQuery();while (resultSet.next()) {employee = new Employee();employee.setEmpId(pk);employee.setEmpName(resultSet.getString("emp_name"));employee.setEmpAge(resultSet.getInt("emp_age"));employee.setEmpSalary(resultSet.getDouble("emp_salary"));}resultSet.close();}System.out.println(employee);generatedKeys.close();} else {System.out.println("插入失败");}preparedStatement.close();connection.close();}
}批量操作
前面插入多条数据时,需要一条一条发送给数据库执行,效率低下,所以需要通过批量操作提升多次操作效率
批量操作步骤:
- 在获取数据库连接的URL参数中的数据库后方添加参数
rewriteBatchedStatements=true - 添加时使用
PreparedStatement对象调用addBatch()方法将新增的数据插入到缓存中 - 插入完毕后,使用
PreparedStatement对象调用executeBatch()方法将缓冲区的数据直接加载到数据库
例如,使用前面的方式进行多条数据插入:
java">@Test
public void test() throws Exception{Connection connection = DriverManager.getConnection("jdbc:mysql:///databaseTest", "root", "123456");PreparedStatement preparedStatement = connection.prepareStatement("insert into t_emp (emp_name, emp_salary, emp_age) values (?, ?, ?)");for (int i = 0; i < 10000; i++) {preparedStatement.setString(1, "marry" + i);preparedStatement.setDouble(2, 100+i);preparedStatement.setInt(3, 10);preparedStatement.executeUpdate();}preparedStatement.close();connection.close();
}查看运行时长:
![]()
使用批量添加多条数据:
java">@Test
public void test1() throws Exception {Connection connection = DriverManager.getConnection("jdbc:mysql:///databaseTest", "root", "123456");PreparedStatement preparedStatement = connection.prepareStatement("insert into t_emp (emp_name, emp_salary, emp_age) values (?, ?, ?)");for (int i = 0; i < 10000; i++) {preparedStatement.setString(1, "marry" + i);preparedStatement.setDouble(2, 100 + i);preparedStatement.setInt(3, 10);preparedStatement.addBatch();}preparedStatement.executeBatch();preparedStatement.close();connection.close();
}查看运行时长:
![]()
连接池
介绍
前面使用JDBC连接数据库存在下面的两个问题:
- 每次操作数据库都要获取新连接,使用完毕后就
close释放,频繁的创建和销毁造成资源浪费 - 连接的数量无法把控,对服务器来说压力巨大
为了解决上面的两个问题就需要用到连接池:
连接池就是数据库连接对象的缓冲区,通过配置,由连接池负责创建连接、管理连接、释放连接等操作
预先创建数据库连接放入连接池,用户在请求时,通过池直接获取连接,使用完毕后,将连接放回池中,避免了频繁的创建和销毁,同时解决了创建的效率。当池中无连接可用,且未达到上限时,连接池会新建连接。如果池中连接达到上限,用户请求会等待,可以设置超时时间。
常见的连接池
JDBC 的数据库连接池使用javax.sql.DataSourc接口进行规范,所有的第三方连接池都实现此接口,自行添加具体实现。也就是说,所有连接池获取连接的和回收连接方法都一样,不同的只有性能和扩展功能,下面是五种常见的连接池,但是最主要的还是第四种和第五种:
- DBCP 是Apache提供的数据库连接池,速度相对C3P0较快,但自身存在一些BUG
- C3P0 是一个开源组织提供的一个数据库连接池,速度相对较慢,稳定性还可以
- Proxool 是sourceforge下的一个开源项目数据库连接池,有监控连接池状态的功能, 稳定性较c3p0差一点
- Druid(名:德鲁伊): 是阿里提供的数据库连接池,是集DBCP 、C3P0 、Proxool 优点于一身的数据库连接池,性能、扩展性、易用性都更好,功能丰富
- Hikari(ひかり[shi ga li]): 取自日语,是光的意思,是SpringBoot2.x之后内置的一款连接池,基于 BoneCP (已经放弃维护,推荐该连接池)做了不少的改进和优化,口号是快速、简单、可靠
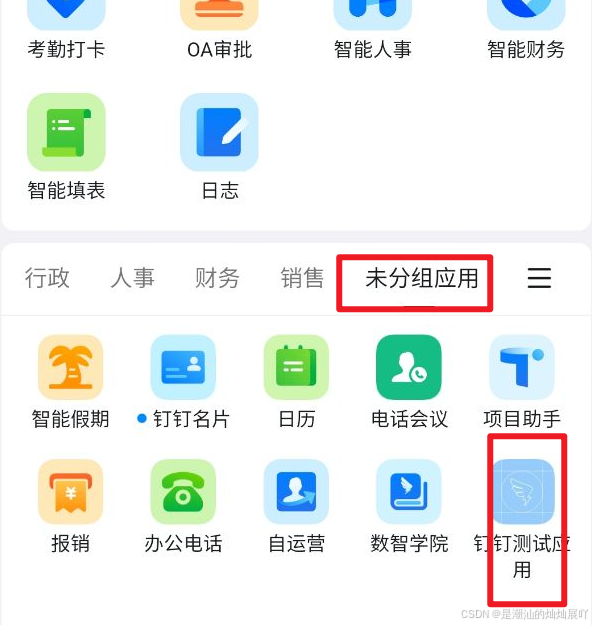
主流连接池的功能对比:
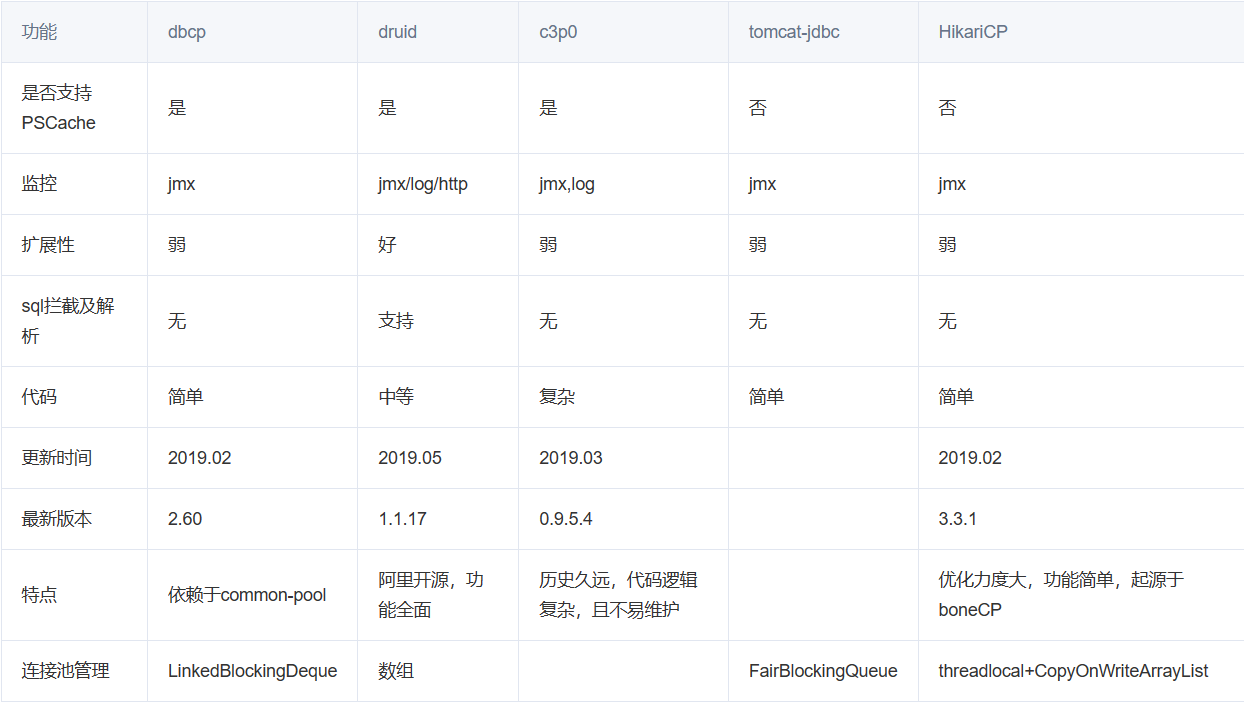
mock性能数据(单位:ms):
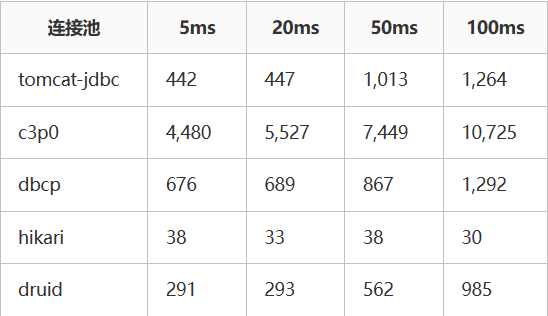
MySQL性能数据 (单位:ms):
Druid连接池
因为是第三方的工具,所以需要引入jar包
使用方式步骤:
- 创建连接池对象(使用
DruidDatasource的无参构造方法创建) - 为连接数据库提供必要数据:
- 可选设置:
- 连接池初始时提供连接的总数量(使用
DruidDatasource对象的方法:setInitialSize(),参数传递整数个数值) - 连接池最大可提供连接的数量(使用使用
DruidDatasource对象的方法:setMaxActive(),参数传递整数个数值)
- 连接池初始时提供连接的总数量(使用
注意,如果写了初始值,若初始值大于8,则必须要给最大值,否则会报错
- 获取连接池对象(使用
DruidDatasource对象的方法:getConnection(),返回DruidPooledConnection对象,但是DruidPooledConnection是Connection的实现类,所以也可以用Connection对象引用来接收) - 释放连接:使用连接对象调用
close()方法释放
示例代码:
java">public class DruidConnectionPool {@Testpublic void test() throws Exception{// 1. 创建DruidDataSource对象DruidDataSource druidDataSource = new DruidDataSource();// 2. 设置数据库信息druidDataSource.setDriverClassName("com.mysql.cj.jdbc.Driver");druidDataSource.setUrl("jdbc:mysql:///databaseTest");druidDataSource.setUsername("root");druidDataSource.setPassword("123456");// 3. 非必要信息设置druidDataSource.setInitialSize(10);druidDataSource.setMaxActive(20);// 4. 获取连接池连接DruidPooledConnection connection = druidDataSource.getConnection();System.out.println(connection);// 5. 处理CRUD// 释放连接池connection.close();}
}看到如下内容代表连接池创建完成:

Hikari连接池
因为是第三方的工具,所以需要引入jar包
使用步骤与Druid基本一致,只是部分方法的名称不同:
使用方式步骤:
- 创建连接池对象(使用
HikariDataSource的无参构造方法创建) - 为连接数据库提供必要数据:
- 可选设置:
- 连接池初始时提供连接的总数量(使用
HikariDataSource对象的方法:setMinimumIdle(),参数传递整数个数值) - 连接池最大可提供连接的数量(使用使用
HikariDataSource对象的方法:setMaximumPoolSize(),参数传递整数个数值)
- 连接池初始时提供连接的总数量(使用
注意,如果写了初始值,若初始值大于8,则必须要给最大值,否则会报错
- 获取连接池对象(使用
HikariDataSource对象的方法:getConnection(),返回Connection对象) - 释放连接:使用连接对象调用
close()方法释放
java">public class HikariConnectionPool {@Testpublic void test() throws Exception{// 1. 创建HikariDataSource对象HikariDataSource hikariDataSource = new HikariDataSource();// 2. 设置数据库信息hikariDataSource.setDriverClassName("com.mysql.cj.jdbc.Driver");hikariDataSource.setJdbcUrl("jdbc:mysql:///databaseTest");hikariDataSource.setUsername("root");hikariDataSource.setPassword("123456");// 3. 非必要信息设置hikariDataSource.setMinimumIdle(10);hikariDataSource.setMaximumPoolSize(20);// 4. 获取连接池连接Connection connection = hikariDataSource.getConnection();System.out.println(connection);// 5. 处理CRUD// 释放连接池connection.close();}
}看到如下结果代表连接池创建成功:

当在Java应用程序中看到「SLF4J: No SLF4J providers were found.」这条信息时,这意味着Simple Logging Facade for Java(SLF4J)没有找到任何绑定(binding),即它无法找到具体的日志实现来执行日志记录。SLF4J本身只是一个用于访问底层日志框架的接口或facade,它需要一个具体的实现(如Logback或log4j-over-SLF4J)来实际记录日志消息,但是目前可以不需要进行具体研究
连接池与软编码
前面在创建连接池时都是使用的硬编码,但是在实际开发中,如果将这些配置信息与Java代码耦合,则每一次更新迭代都需要改变源代码,导致维护成本升高,为了解决这个问题,可以将连接池的相关配置信息放到一个xxx.properties的文件,使用Properties集合的load()方法读取配置文件中的信息
配置文件创建基本步骤如下:
- 创建
resources文件夹并将其标记为根资源文件夹,存放配置文件 - 在配置文件中写入连接池的配置信息,一般包括如下内容:
- 可选写内容:
- 连接池初始连接总数量
- 连接池最大连接数量
建议在设置配置文件每一个key时,名字取setXxx方法后面的Xxx并将首字母小写,例如setDriverClassName,在配置文件中写driverClassName
使用软编码步骤如下:
- 创建
Properties集合 - 通过
当前类名.class.ClassLoader().getResourcesAsStream()获取一个InputStream对象 - 通过
Properties集合中的load()方法读取数据 - 将
Properties集合对象通过连接池的相关方法传入从而创建指定连接池:- 对于Druid:使用
DruidDataSourceFactory.createDataSource()方法,参数传递Properties集合对象 - 对于Hikari:使用构造方法:
HikariConfig(),参数传递Properties集合对象,创建一个HikariConfig对象,通过HikariConfig对象调用HikariDataSource()的构造方法,参数传递HikariConfig对象,创建HikariDataSource对象
- 对于Druid:使用
对于Druid来说:
配置文件:
java">driverClassName=com.mysql.jdbc.Driver
url=jdbc:mysql:///databaseTest
username=root
password=123456
initialSize=10
maxActive=20示例代码:
java">@Test
public void softCode() throws Exception{// 创建Properties集合Properties properties = new Properties();// 获取配置文件InputStream resourceAsStream = DruidConnectionPool.class.getClassLoader().getResourceAsStream("druid.properties");properties.load(resourceAsStream);DataSource dataSource = DruidDataSourceFactory.createDataSource(properties);// 获取连接对象Connection connection = dataSource.getConnection();System.out.println(connection);// 释放连接connection.close();
}对于Hikari来说:
配置文件:
java">driverClassName=com.mysql.jdbc.Driver
jdbcUrl=jdbc:mysql:///databaseTest
username=root
password=123456
minimumIdle=10
maximumPoolSize=20示例代码:
java">@Test
public void softCode() throws Exception{// 创建Properties集合Properties properties = new Properties();// 获取配置文件InputStream resourceAsStream = HikariConnectionPool.class.getClassLoader().getResourceAsStream("hikari.properties");properties.load(resourceAsStream);HikariConfig hikariConfig = new HikariConfig(properties);HikariDataSource hikariDataSource = new HikariDataSource(hikariConfig);// 获取连接对象Connection connection = hikariDataSource.getConnection();System.out.println(connection);// 释放连接connection.close();
}其他配置
Druid配置
| 配置 | 缺省 | 说明 |
|
| 配置这个属性的意义在于,如果存在多个数据源,监控的时候可以通过名字来区分开来。 如果没有配置,将会生成一个名字,格式是: | |
|
| 连接数据库的 | |
|
| 连接数据库的用户名 | |
|
| 连接数据库的密码。如果你不希望密码直接写在配置文件中,可以使用ConfigFilter。详细看这里:使用ConfigFilter · alibaba/druid Wiki · GitHub | |
|
| 根据 | |
|
| 0 | 初始化时建立物理连接的个数。初始化发生在显示调用 |
|
| 8 | 最大连接池数量 |
|
| 8 | 已经不再使用,配置了也没效果 |
|
| 最小连接池数量 | |
|
| 获取连接时最大等待时间,单位毫秒。配置了 | |
|
|
| 是否缓存 |
|
| -1 | 要启用 |
|
| 用来检测连接是否有效的 | |
|
|
| 申请连接时执行 |
|
|
| 归还连接时执行 |
|
|
| 建议配置为 |
|
| 有两个含义:
| |
|
| 不再使用,一个 | |
|
| ||
|
| 物理连接初始化的时候执行的 | |
|
| 根据 | |
|
| 属性类型是字符串,通过别名的方式配置扩展插件,常用的插件有: 监控统计用的 | |
|
| 类型是 |
Hikari配置
| 属性 | 默认值 | 说明 |
|
|
| 自动提交从池中返回的连接 |
|
| 30000 | 等待来自池的连接的最大毫秒数 |
|
| 1800000 | 池中连接最长生命周期如果不等于0且小于30秒则会被重置回30分钟 |
|
| 10 | 池中维护的最小空闲连接数 |
|
| 10 | 池中最大连接数,包括闲置和使用中的连接 |
|
|
| 连接池的用户定义名称,主要出现在日志记录和JMX管理控制台中以识别池和池配置 |
|
|
| 报告当前健康信息 |
|
|
| 连接池的用户定义名称,主要出现在日志记录和JMX管理控制台中以识别池和池配置 |
|
| 是允许连接在连接池中空闲的最长时间 |