文章目录
知识图谱的介绍
图
图是描述和分析实体关系/交互的通用语言、结构
生活中很多类型的数据都是图的结构
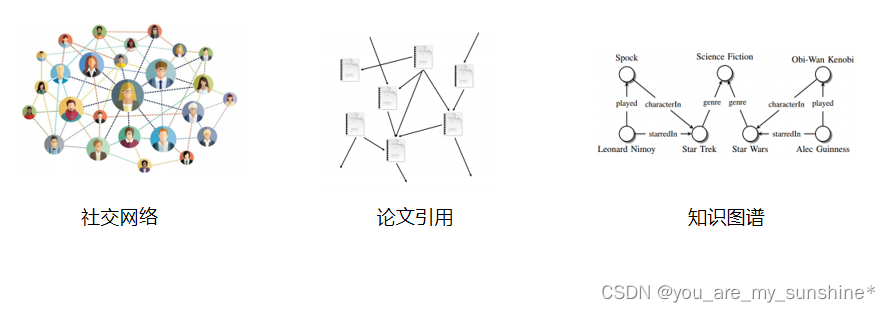
图能做些什么任务
节点分类:预测某网站是否是诈骗网站
关系预测:判断图谱中两个节点的关系
图分类:分子性质预测
聚类:社交网络分析
图生成:药物探索
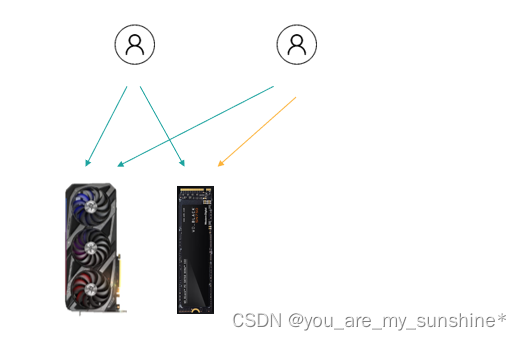
基于图的推荐系统
假设我们的图节点是由用户与商品信息构成,边表示的是用户与商品的交互操作
图的一些基本概念与表述
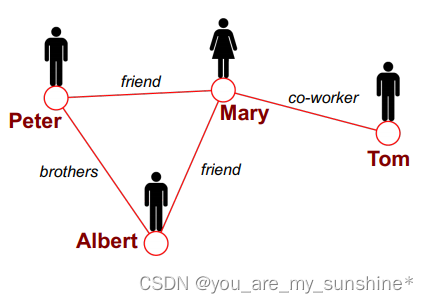
节点:nodes、vertices【N】
关系:edges【E】
图:network、graph【G(N,E)】
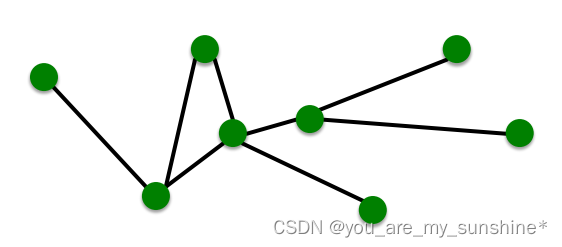
|N|=4
|E|=4
有向图与无向图
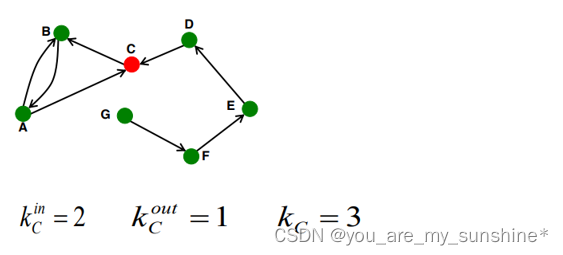
节点的度
节点的边的数量
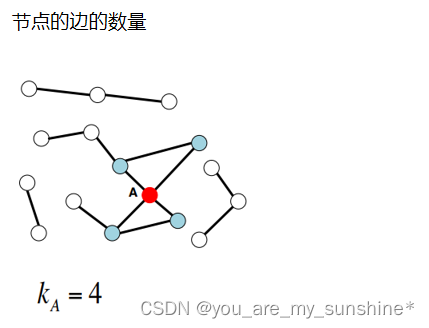
有向图又分为入度和出度
什么是知识图谱
知识图谱,是通过将应用数学、图形学、信息可视化技术、信息科学等学科的理论与方法与计量学引文分析、共现分析等方法结合,并利用可视化的图谱形象地展示学科的核心结构、发展历史、前沿领域以及整体知识架构达到多学科融合目的的现代理论。
知识图谱,最早起源于Google Knowledge Graph。知识图谱本质上是一种语义网络 。其结点代表实体(entity)或者概念(concept),边代表实体/概念之间的各种语义关系。
知识图谱属于异质图
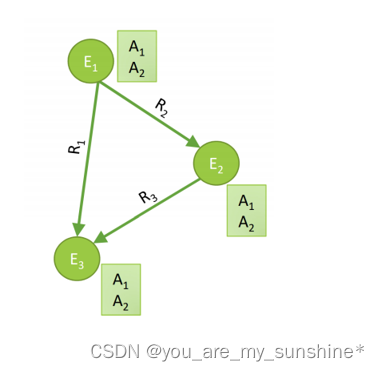
图谱有三个重要的属性,实体、类型、关系
实体entity就是图中的节点
类型表示的是图中节点的标识
关系标识的是图中节点的边
其次实体又包括头实体与尾实体
通俗地讲,知识图谱就是把所有不同种类的信息连接在一起而得到的一个关系网络。
查看如下可视化网址加深印象及理解
https://www.ownthink.com/knowledge.html
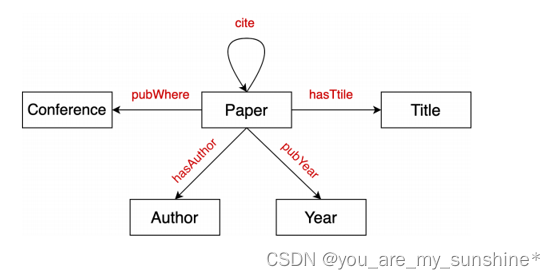
知识图谱的schema
schame即有哪些类型的实体,实体之间的关系
例如下图是一个关于论文的图谱schame
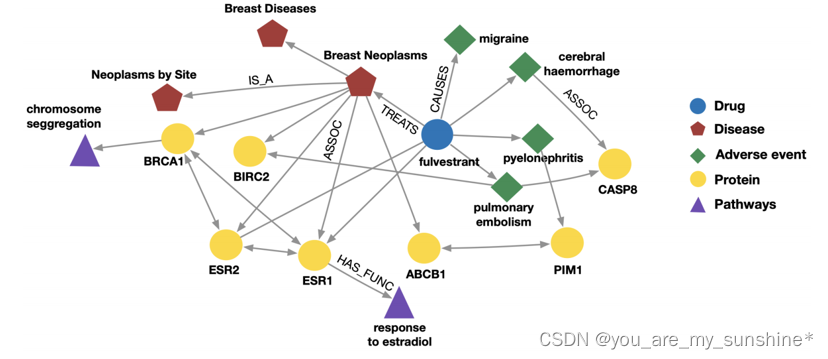
一个生物知识图谱
知识图谱的应用场景
1、数据可视化
2、基于图谱的问答系统
3、基于图谱的关系推理
4、便捷的关系查询,给模型提供更多数据特征
知识图谱的构建
三元组
知识图谱的三元组,指的是 <subject, predicate/relation, object> 。同学们会发现很多人类的知识都可以用这样的三元组来表示。例如:<中国,首都,北京>,<美国,总统,特朗普> 等等。
所有图谱中的数据都是由三元组构成
工业场景通常把三元组存储在图数据库中如neo4j,图数据的优势在于能快捷查询数据。
学术界会采用RDF的格式存储数据,RDF的优点在于易于共享数据。
如何构建知识图谱
构建知识图谱通常有两种数据源:
1、结构化数据,存储在关系型数据库中的数据,通过定义好图谱的schema,然后按照schema的格式,把关系型数据转化为图数据。
2、非结构化数据,采用模板或者模型的方式,从文本中抽取出三元组再入库。
对于非结构化的三元组抽取,主要涉及到2个任务
1、实体识别
2、关系抽取
实体识别主要作用在于抽取subject和object,关系抽取主要作用在于抽取predicate
例如:
中国的首都是北京
<中国,首都,北京>
拜登成功当选2020年美国总统
<美国,总统,拜登>
姚明是中国男篮的主席,曾在NBA火箭队效力
<中国男篮,主席,姚明> <火箭队,队员,姚明>
实体识别
subject与object在一个句子中会对应多个实体,所以对于实体识别我们会采用BIO labeling
我们一般把命名实体识别当做一个sequence labeling的任务来实现。这里的label一般包含BIO labeling:
B-XXX: B-ORG, B-LOC,表示一个entity的开始
I-XXX: I-ORG,I-LOC, 表示一个entity的中间与结尾
O: 表示不是entity
有时候也会采取别的方法来实现,例如指针法,根据具体的问题具体分析。
sequence labeling问题的主要模型使用BiLSTM, BERT等模型作为encoder,把文本转化为向量形式。然后使用CRF等layer增加label间的dependency。最后对每个位置针对我们的输入和label做一个cross entropy loss作为训练标注

关系抽取
识别识别做完后,把抽取出来的实体和原文一起作为输入,判断属于什么关系,通常都会提供好固定的一些关系,因此该任务就是一个分类问题。
Semantic Relation Classification via Convolutional Neural Networks with Simple Negative Sampling
https://arxiv.org/pdf/1506.07650.pdf
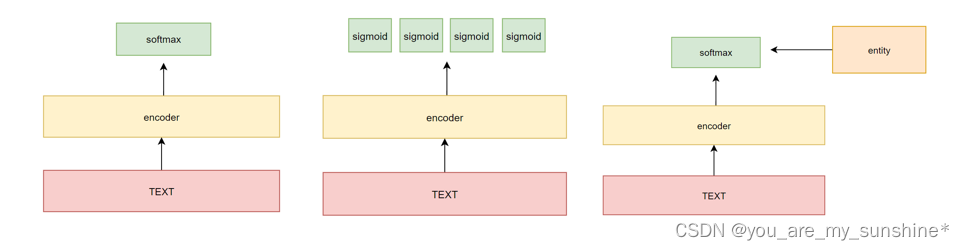
三元组抽取
上述的方法可行,但是也存在缺点
1、两个模型,效率低下
2、多对实体,会造成关系预测错误
因此,也有同时抽取的方法,如右图的模型结构
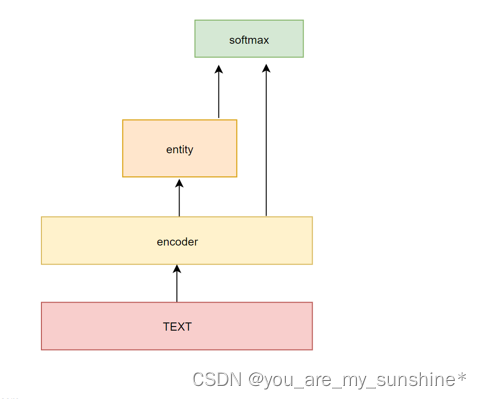
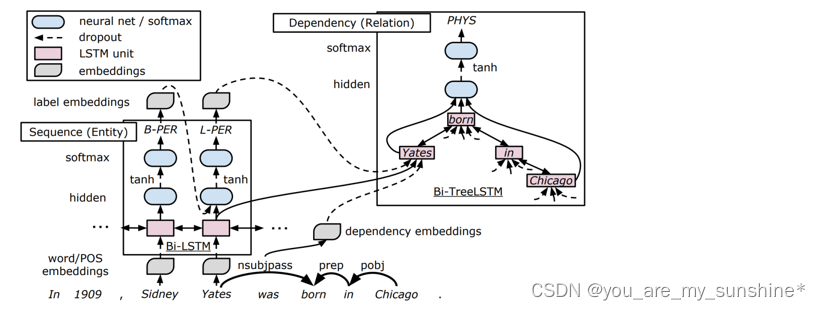
End-to-End Relation Extraction using LSTMs on Sequences and Tree Structures
https://www.aclweb.org/anthology/P16-1105.pdf
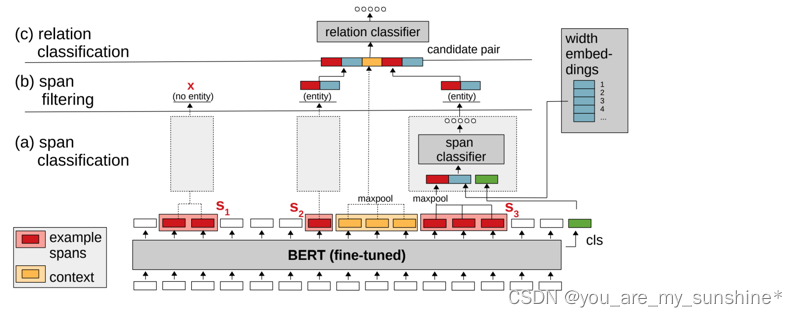
Span-based Joint Entity and Relation Extraction with Transformer Pre-training
https://arxiv.org/pdf/1909.07755.pdf
问答
图谱问答
根据问题,解析出三元组中的其中两个元素,查询第三个元素
例如:
<中国,首都,北京>
中国的首都是哪?
中国和北京是什么关系
北京是哪个国家的首都
大部分的问题还是以第一种情况为主,即查询object
挑战:
1、如何确定subject?
2、如何确定predicate?
3、使用subject和predicate去搜索KB,找到一系列三元组之后,如何确定哪个三元组是我们想要的。
例如:
<美国,总统,特朗普>
<美国,总统,拜登>
到底应该选择哪一个作为最终的答案
Entity Linking
Entity Linking指的是subject的识别,为了实现KBQA,我们要做的第一步是把问题中的subject实体(entity)给找出来,并且找到知识图谱中对应的entity,然后根据该entity的特征来回答问题。
Entity Linking非常有挑战性,主要有两个原因
Mention Variations:同一实体有不同的mention。(<科比>:小飞侠、黑曼巴、科铁、蜗壳、老科。)
Entity Ambiguity:同一mention对应不同的实体。(“苹果”:中关村苹果不错;山西苹果不错。)
针对上述两个问题,一般会用Candidate Entity Generation (CEG) 和Entity Disambiguation (ED) 两个模块来分别解决:
Candidate Entity Generation:从mention出发,找到KB中所有可能的实体,组成候选实体集 (candidate entities)
Entity Disambiguation:从candidate entities中,选择最可能的实体作为预测实体。
Candidate Entity Generation (CEG)
最重要的方法:Name Dictionary ( {mention: entity} )
哪些别名:首字母缩写、模糊匹配、昵称、拼写错误等。
CEG这部分,最主流也最有效的方法就是Name Dictionary,说白了就是配别名。虽然CEG很朴素,但作为EL任务中的第一道门槛,其重要性不言而喻。对于每一个entity,紧凑而充分地配置别名,才能保证生成的candidate entites没有遗漏掉ground truth entity。
具体的,要配置哪些别名,要用什么构建方法,往往取决于EL的使用场景。比如做百科问答或是通用文本的阅读增强,就很依赖于wikipedia和搜索引擎;但如果是某个具体的行业领域,就需要通过一些启发式的方法、用户日志、网页爬取,甚至人工标注的方法来构建Name Dictionary。

采用maximum matching的方法来做entity linking,具体可参考以下文章:Chinese Word Segmentation based on Maximum Matching and Word Binding Force 。
Entity Disambiguation (ED)
实体消歧时,不同场景的特征选取是非常重要的。总的来说,实体消歧的特征分为,context独立和context不独立的。
context独立:考虑mention到实体的LinkCount、实体自身的一些属性(比如热度、类型等等)。其中,LinkCount作为一个先验知识,在消歧时,往往很有用,比如当我们在问“姚明有多高?”时,大概率都是在问<篮球运动员姚明>,而不是其他不为人知的“姚明”。虽然context中完全没有包含篮球运动员这一信息,但LinkCount最高,选其作为实体进行查询,都会是一个不错的答案。
context不独立:我是实际上是在计算条件概率 P(e|m,c) ,其中 c 是输入文本,e 为实体, m 是mention,因此可以直接对该条件概率建模。也可加入一些先验知识,例如LinkCount信息
1、直接把mention和context作为输入,经过神经网络做一个分类
2、采用一些图算法,计算entity embedding,计算相似度
predicate预测
Predicate的预测有两种方法
1、和图谱构建很类似,做一个分类
2、把predicate和问题进行对比,找出最相似的那个predicate
KBQA
A Chinese Question Answering System for Single-Relation Factoid Questions
http://tcci.ccf.org.cn/conference/2017/papers/2003.pdf 在NLPCC 2017的比赛中获得了KBQA的第一名
http://tcci.ccf.org.cn/conference/2019/papers/183.pdf
同时使用QA和QA模型来解决Knowledge Base QA问题。
2018年NLPCC
http://tcci.ccf.org.cn/conference/2018/dldoc/CFPtaskr1.pdf
CCKS2020
http://sigkg.cn/ccks2020/?page_id=700
知识图谱知识小结
1.知识图谱就是把所有不同种类的信息连接在一起而得到的一个关系网络。
2.常见应用场景:基于图谱问答
3.知识图谱的三元组,指的是 <subject, predicate/relation, object>,所有图谱中的数据都是由三元组构成
4.构建知识图谱通常有两种数据源
(1).构化数据,存储在关系型数据库中的数据,通过定义好图谱的schema,然后按照schema的格式,把关系型数据转化为图数据。
(2).非结构化数据,采用模板或者模型的方式,从文本中抽取出三元组再入库。
5.对于非结构化的三元组抽取,主要涉及到2个任务:实体识别、关系抽取。
实体识别主要作用在于抽取subject和object,关系抽取主要作用在于抽取predicate。
6.图谱问答,根据问题,解析出三元组中的其中两个元素,查询第三个元素。
7.Entity Linking,主要有两个挑战:
Mention Variations:同一实体有不同的mention。(<科比>:小飞侠、黑曼巴、科铁、蜗壳、老科。)
Entity Ambiguity:同一mention对应不同的实体。(“苹果”:中关村苹果不错;山西苹果不错。)
一般会用这两个模块来分别解决:
Candidate Entity Generation:从mention出发,找到KB中所有可能的实体,组成候选实体集 (candidate entities)
Entity Disambiguation:从candidate entities中,选择最可能的实体作为预测实体。
学习的参考资料:
七月在线NLP高级班