GoogleMapReduceHadoopMapReduce_0">Google的MapReduce和Hadoop的MapReduce基本原理

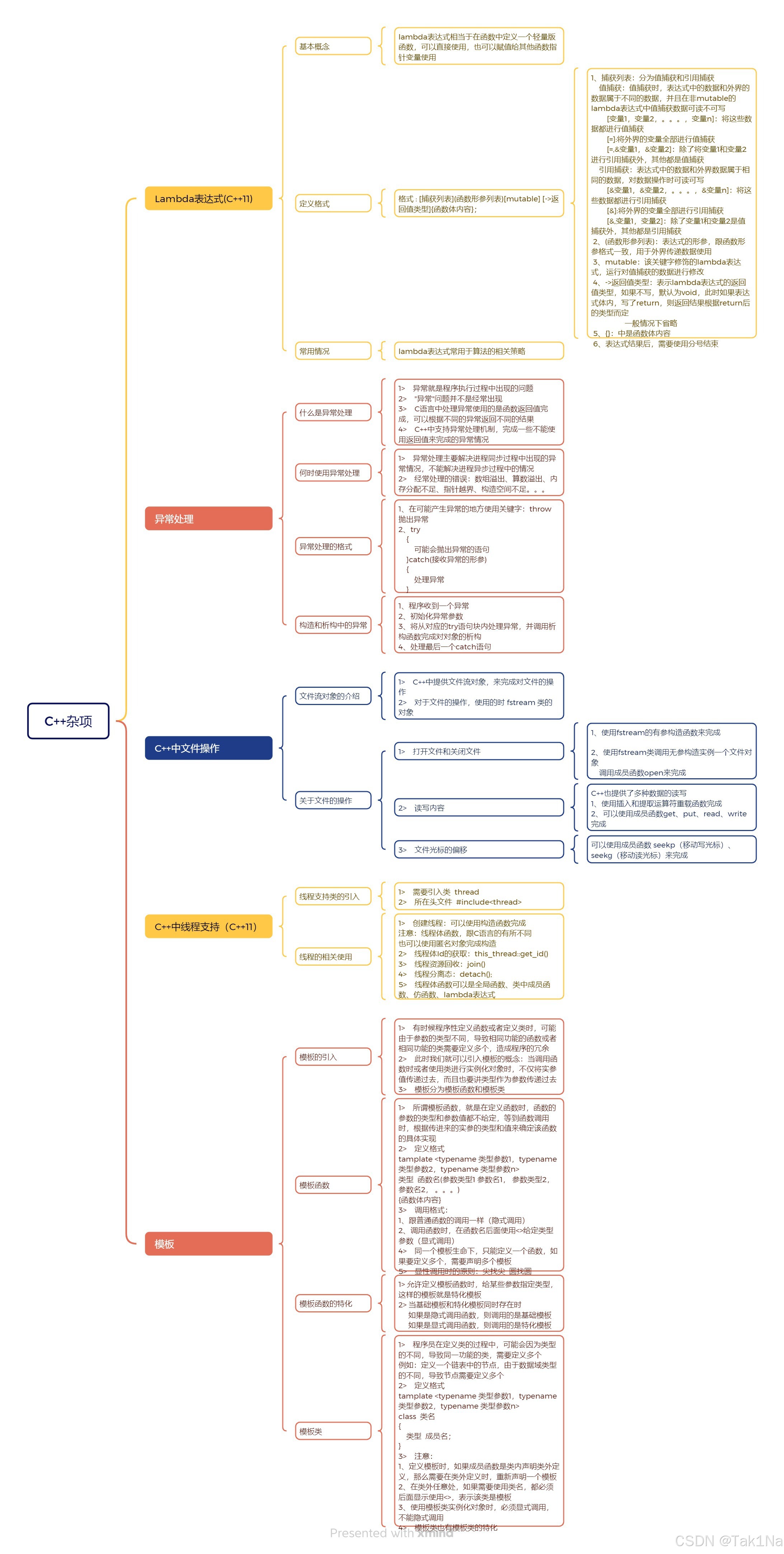
MapReduce框架的执行过程可以概述为以下几个关键步骤:
-
输入分割:用户程序中的
MapReduce库首先将输入文件分割成M个片段,每个片段通常大小在16MB到64MB之间,用户可以通过可选参数控制。 -
启动作业:程序在集群的多台机器上启动多个副本,其中一个机器作为
master,其余作为worker。 -
任务分配:
master负责分配M个map任务和R个reduce任务给空闲的worker。 -
Map任务执行:被分配
map任务的worker读取相应输入片段的内容,解析出键/值对,并将其传递给用户定义的Map函数。Map函数生成的中间键/值对在内存中缓冲。 -
中间数据写入:缓冲的中间数据定期写入本地磁盘,并根据分区函数划分为R个区域。这些缓冲数据在本地磁盘上的位置信息被发送回
master。 -
Reduce任务执行:
master通知reduce worker这些位置信息,reduce worker使用远程过程调用从map worker的本地磁盘读取缓冲数据。读取完所有中间数据后,reduce worker按中间键排序,并将每个唯一的中间键及其对应的值集合传递给用户定义的Reduce函数。 -
输出结果:
Reduce函数的输出被追加到最终输出文件中,每个reduce任务对应一个输出文件。 -
作业完成:所有
map和reduce任务完成后,master唤醒用户程序,MapReduce调用在用户程序中返回。
MapReduce的工作流程就像是在厨房里准备一场大型宴会:首先,大厨(Master节点)将大量的食材(数据)切成小块(分割数据),然后分配给一群厨师(Worker节点)去处理。每个厨师根据食谱(Map函数)进行初步烹饪,比如统计每种食材的使用量。接着,他们将处理好的食材暂时存放起来。随后,大厨将相同类型的半成品收集起来,交给另一组厨师进行最终烹饪(Reduce函数),比如将所有相同的食材合并成一道菜。最后,当所有菜肴都准备好后,大厨将它们端上桌,供宾客享用(输出结果)。如果某个厨师无法完成任务,大厨会迅速找其他厨师来替补,确保宴会能够顺利进行。整个过程是自动化的,每个步骤都紧密协调,以确保最终的菜肴既美味又及时。
Hadoop MapReduce的执行流程与Google MapReduce有许多相似之处,因为Hadoop的设计受到了Google MapReduce论文的启发。以下是Hadoop MapReduce执行流程的概述图。

在 Hadoop 3.x 版本中,MapReduce 作业的执行流程分为两个主要阶段:Map 阶段和 Reduce 阶段。以下是这两个阶段的详细描述:
Map 阶段:
- 作业提交:用户通过客户端提交 MapReduce 作业,包括
Map和Reduce任务。 - 资源申请:
ApplicationMaster向ResourceManager申请执行Map任务所需的资源。 - 任务分配:
ResourceManager根据集群资源情况,将Map任务分配给NodeManager执行。 Map任务执行:NodeManager在分配的容器中启动Map任务,Map任务读取输入数据,处理后生成中间键/值对。- 中间数据输出:
Map任务将处理结果输出到本地磁盘,为后续的 Shuffle 和 Sort 阶段做准备。
Reduce 阶段:
- Shuffle 阶段:
Map任务的输出被传输到Reduce任务。这个过程称为 Shuffle,它包括排序和合并Map任务的输出,以便为Reduce任务提供有序的输入。 - 资源申请:
ApplicationMaster向ResourceManager申请执行Reduce任务所需的资源。 - 任务分配:
ResourceManager将Reduce任务分配给NodeManager执行。 Reduce任务执行:NodeManager在分配的容器中启动Reduce任务,Reduce任务读取经过 Shuffle 阶段排序的中间数据,进行汇总和处理。- 输出结果:
Reduce任务将最终结果写入到 HDFS(Hadoop Distributed File System)中。
在整个过程中,ApplicationMaster 负责协调 Map 和 Reduce 任务的执行,监控任务进度,并与 ResourceManager 和 NodeManager 进行通信。此外,Hadoop 3.x 引入了更多的优化和改进,例如改进的 Shuffle 机制、更好的资源隔离和更高效的数据本地化,以提高 MapReduce 作业的性能和可靠性。
JobTracker是 Hadoop 1.x 版本中的关键组件,它负责管理和调度 MapReduce 作业。在 Hadoop 1.x 版本中,JobTracker与TaskTracker配合工作,其中JobTracker负责作业的调度和监控,而TaskTracker则在各个节点上执行实际的任务。
随着 Hadoop 生态系统的发展,为了解决 Hadoop 1.x 版本中的可扩展性和资源管理问题,Hadoop 2.x 版本引入了 YARN(Yet Another Resource Negotiator)作为集群资源管理器。在 Hadoop 2.x 版本中,JobTracker的职责被拆分,其中作业调度和监控的职责由ResourceManager组件承担,而任务的执行则由NodeManager组件负责。
// 设置Hadoop用户名为"hadoop"
System.setProperty("HADOOP_USER_NAME","hadoop");
// 创建Hadoop配置对象
Configuration configuration= new Configuration();
// 设置默认的文件系统为HDFS,并指定HDFS的地址
configuration.set("fs.defaultFS","hdfs://192.168.1.200:8020");
// 创建一个Job对象
Job job = Job.getInstance(configuration);
// 设置Job的Mapper类
job.setMapperClass(WordCountMapper.class);
// 设置Job的Reducer类
job.setReducerClass(WordCountReducer.class);
// 设置Mapper输出的Key和Value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 设置Reducer输出的Key和Value类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 获取FileSystem对象
FileSystem fs=FileSystem.get(new URI("hdfs://192.168.1.200:8020"),configuration,"hadoop");
// 设置输出路径
Path output=new Path("/map/output");
// 如果输出路径已存在,则删除它
if(fs.exists(output)){fs.delete(output,true);
}
// 设置作业的输入路径
FileInputFormat.setInputPaths(job,new Path("/map/input"));
// 设置作业的输出路径
FileOutputFormat.setOutputPath(job,new Path("/map/output"));
// 提交作业并等待作业完成
boolean result=job.waitForCompletion(true);
// 根据作业执行结果退出程序,成功返回0,失败返回-1
System.exit( result ? 0:-1);
详细见:Hadoop基础-07-MapReduce概述
https://blog.csdn.net/jankin6/article/details/109060857