向量数据库
2024/9/23 7:27:19
开源向量数据库比较:Chroma, Milvus, Faiss,Weaviate
语义搜索和检索增强生成(RAG)正在彻底改变我们的在线交互方式。实现这些突破性进展的支柱就是向量数据库。选择正确的向量数据库能是一项艰巨的任务。本文为你提供四个重要的开源向量数据库之间的全面比较,希望你能够选择出最符合自己特定需求的数据库。
什么是向量…
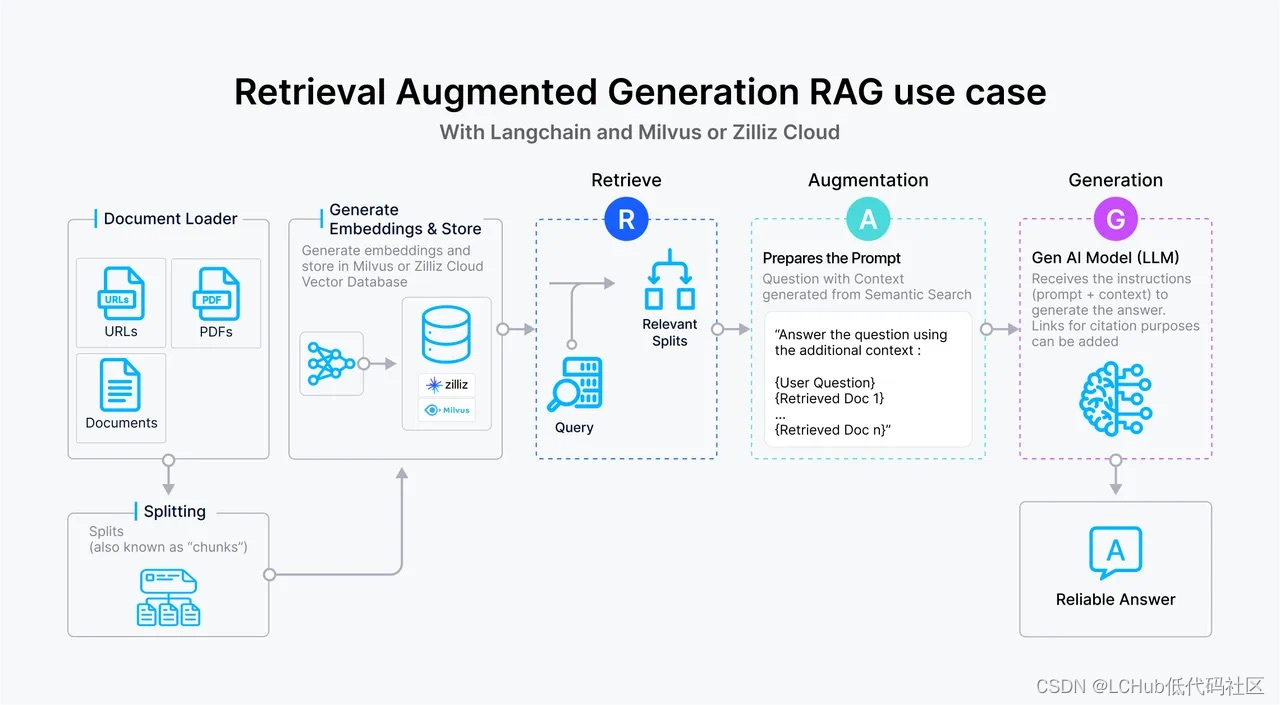
RAG 场景对Milvus Cloud向量数据库的需求
虽然向量数据库成为了检索的重要方式,但随着 RAG 应用的深入以及人们对高质量回答的需求,检索引擎依旧面临着诸多挑战。这里以一个最基础的 RAG 构建流程为例:检索器的组成包括了语料的预处理如切分、数据清洗、embedding 入库等,然后是索引的构建和管理,最后是通过 vecto…
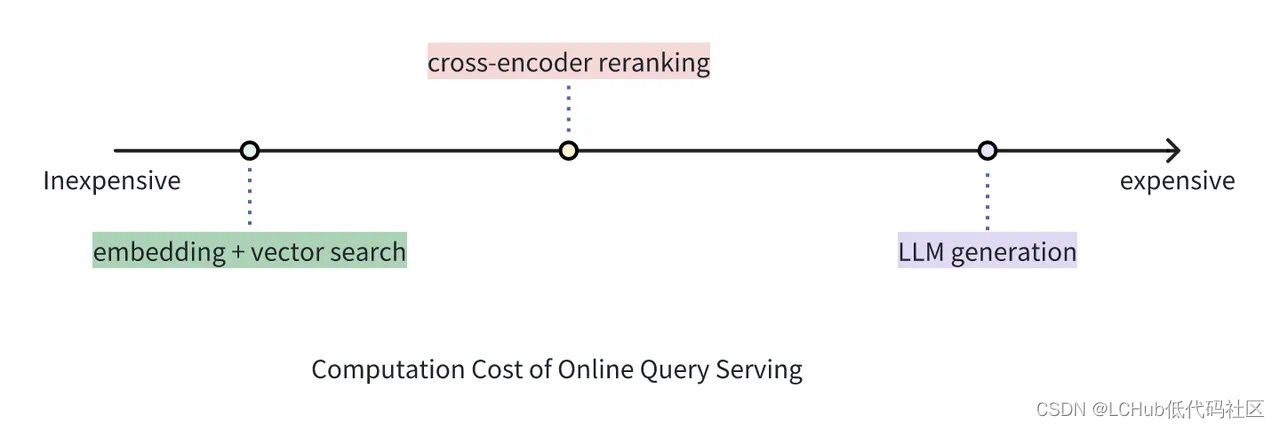
Milvus Cloud 向量数据库Reranker成本比较和使用场景
成本比较:向量检索 v.s. Cross-encoder Reranker v.s. 大模型生成 虽然 Reranker 的使用成本远高于单纯使用向量检索的成本,但它仍然比使用 LLM 为同等数量文档生成答案的成本要低。在 RAG 架构中,Reranker 可以筛选向量搜索的初步结果,丢弃掉与查询相关性低的文档,从而有…
Milvus Cloud 向量数据库Reranker成本比较和使用场景
成本比较:向量检索 v.s. Cross-encoder Reranker v.s. 大模型生成 虽然 Reranker 的使用成本远高于单纯使用向量检索的成本,但它仍然比使用 LLM 为同等数量文档生成答案的成本要低。在 RAG 架构中,Reranker 可以筛选向量搜索的初步结果,丢弃掉与查询相关性低的文档,从而有…
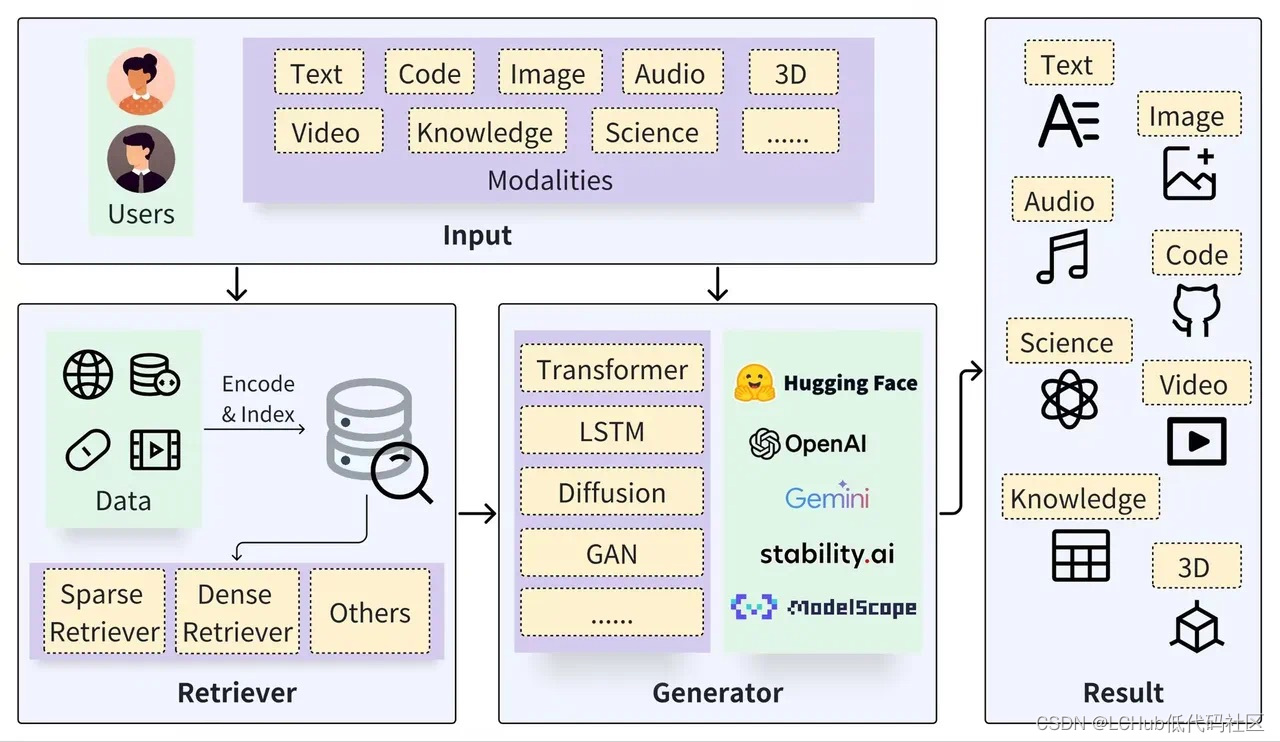
Milvus Cloud 的RAG 的广泛应用及其独特优势
一个典型的 RAG 框架可以分为检索器(Retriever)和生成器(Generator)两块,检索过程包括为数据(如 Documents)做切分、嵌入向量(Embedding)、并构建索引(Chunks Vectors),再通过向量检索以召回相关结果,而生成过程则是利用基于检索结果(Context)增强的 Prompt 来激…

.Net使用Elastic.Clients.Elasticsearch在Elasticsearch8中实现向量存储和相似度检索
文章目录 一、测试环境二、代码1、创建包含DenseVector的索引2、索引文档3、对向量字段进行近似knn检索 三、参考 一、测试环境
Elastic.Clients.Elasticsearch版本:8.13.0 Elasticsearch版本:8.13.0
二、代码
1、创建包含DenseVector的索引
public …

ChromaDB教程
使用 Chroma DB,管理文本文档、将文本嵌入以及进行相似度搜索。
随着大型语言模型 (LLM) 及其应用的兴起,我们看到向量数据库越来越受欢迎。这是因为使用 LLM 需要一种与传统机器学习模型不同的方法。
LLM 的核心支持技术之一是…
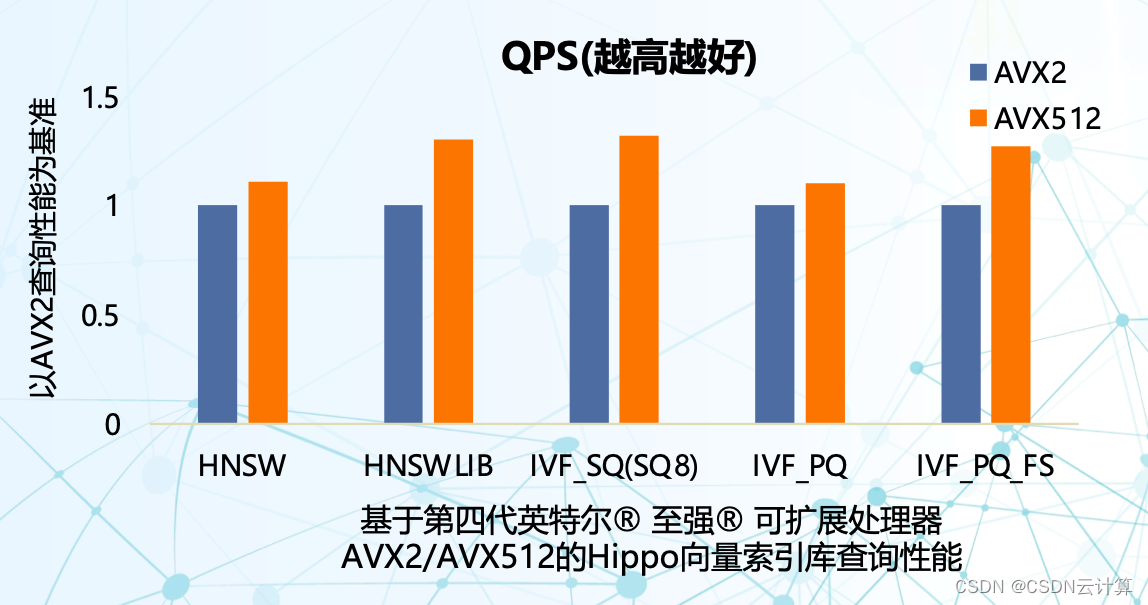
突破AI迷雾:英特尔携手星环科技打造向量数据库革新方案,直降大模型幻觉
去年爆火的大模型,正在从百模大战走向千行百业落地应用。不过行业数据规模有限,企业数据隐私安全的要求等等因素,都让行业大模型的准确率面临挑战。近期发布的《CSDN AI 开发者生态报告》数据显示,“缺乏数据/数据质量问题”在大模…
.Net使用Elastic.Clients.Elasticsearch在Elasticsearch8中实现向量存储和相似度检索
文章目录 一、测试环境二、代码1、创建包含DenseVector的索引2、索引文档3、对向量字段进行近似knn检索 三、参考 一、测试环境
Elastic.Clients.Elasticsearch版本:8.13.0 Elasticsearch版本:8.13.0
二、代码
1、创建包含DenseVector的索引
public …

Transformer直接预测完整数学表达式,推理速度提高多个数量级
前言
来自 Mata AI、法国索邦大学、巴黎高师的研究者成功让 Transformer 直接预测出完整的数学表达式。
转载自丨机器之心
符号回归,即根据观察函数值来预测函数数学表达式的任务,通常涉及两步过程:预测表达式的「主干」并选择数值常数&am…
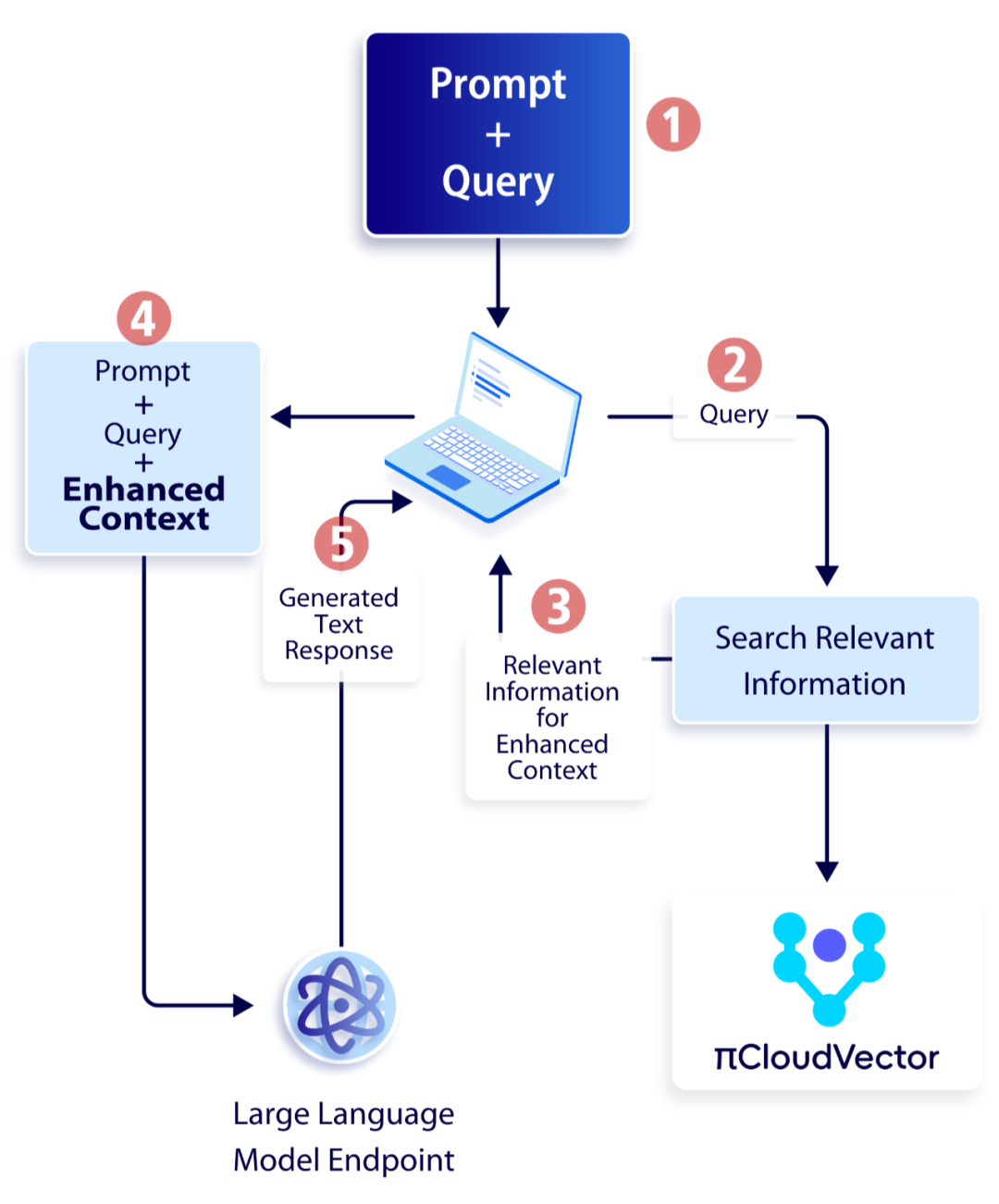
基于云原生向量数据库 PieCloudVector 的 RAG 实践
近年来,人工智能生成内容(AIGC)已然成为最热门的话题之一。工业界出现了各种内容生成工具,能够跨多种模态产生多样化的内容。这些主流的模型能够取得卓越表现,归功于创新的算法、模型规模的大幅扩展,以及海…
基于云原生向量数据库 PieCloudVector 的 RAG 实践
近年来,人工智能生成内容(AIGC)已然成为最热门的话题之一。工业界出现了各种内容生成工具,能够跨多种模态产生多样化的内容。这些主流的模型能够取得卓越表现,归功于创新的算法、模型规模的大幅扩展,以及海…
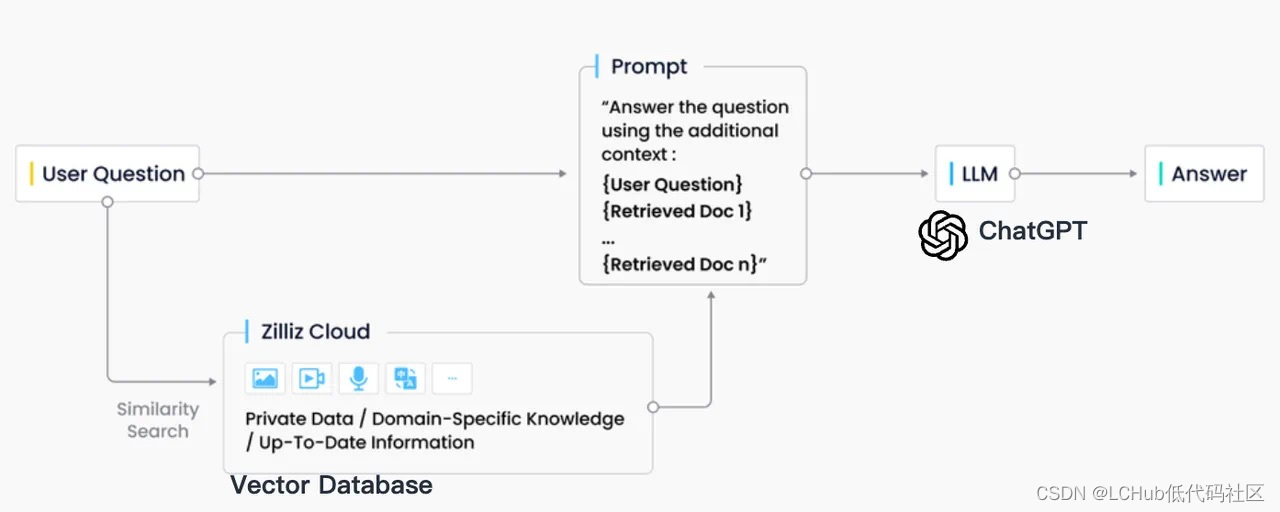
RAG 检索的底座:Milvus Cloud向量数据库
在业界实践中,RAG 检索通常与向量数据库密切结合,也催生了基于 ChatGPT + Vector Database + Prompt 的 RAG 解决方案,简称为 CVP 技术栈。这一解决方案依赖于向量数据库高效检索相关信息以增强大型语言模型(LLMs),通过将 LLMs 生成的查询转换为向量,使得 RAG 系统能在向…

探索LlamaIndex:如何用Django打造高效知识库检索
简介
LlamaIndex(前身为 GPT Index)是一个数据框架,为了帮助我们去建基于大型语言模型(LLM)的应用程序。
主要用于处理、构建和查询自定义知识库。
它支持多种数据源格式 excel,txt,pdf&…

深入理解Faiss:高效向量检索的利器
近年来,随着人工智能和机器学习技术的飞速发展,向量检索技术变得越来越重要。无论是在推荐系统、图像搜索还是自然语言处理等领域,向量检索都扮演着至关重要的角色。而在众多向量检索库中,Faiss(Facebook AI Similarit…
向量数据库 和 关系数据库的区别
向量数据库和关系数据库在架构和数据组织方式上有明显的区别。下面将详细解释向量数据库中的数据库、集合、数据、索引、分区等概念,以及它们之间的关系,并将其与 MySQL 这样的关系数据库中的数据库、表、列、索引等概念进行对比。 向量数据库的架构 数据…