bert
2024/9/19 11:01:25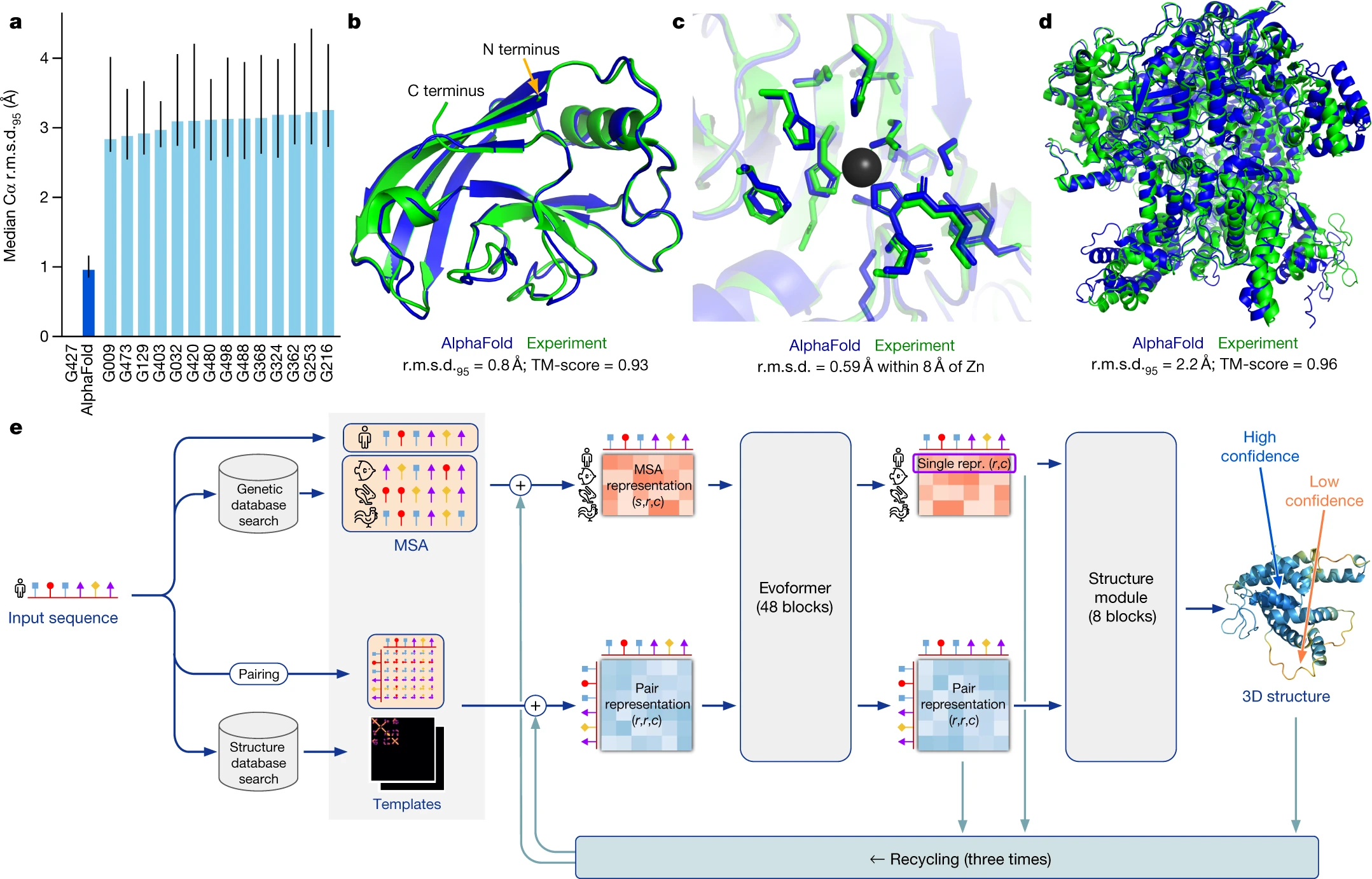
BERT一个蛋白质-季军-英特尔创新大师杯冷冻电镜蛋白质结构建模大赛-paipai
关联比赛: “创新大师杯”冷冻电镜蛋白质结构建模大赛
解决方案
团队介绍
paipai队、取自 PAIN AI,核心成员如我本人IvanaXu(IvanaXu GitHub),从事于金融科技业,面向银行信用贷款的风控、运营场景。但我们团队先后打过很多比赛…
预训练语言模型的前世今生 - 从Word Embedding到BERT
目录
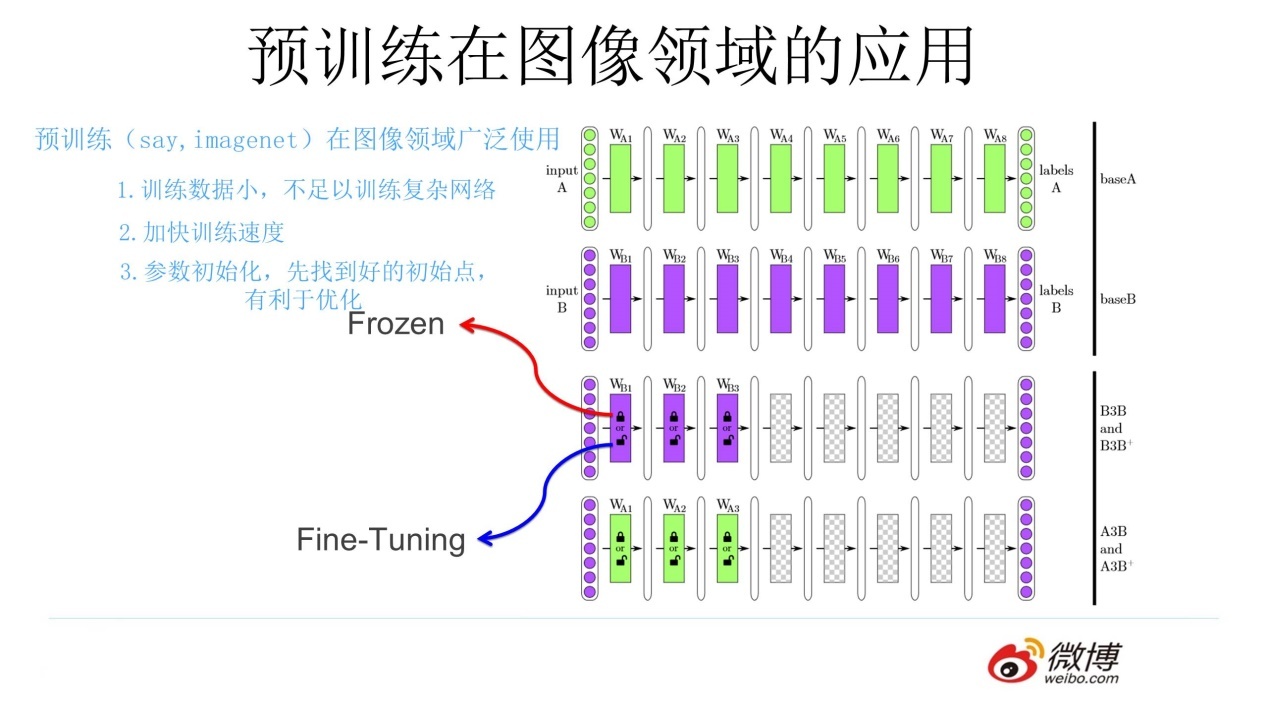
一、预训练 1.1 图像领域的预训练1.2 预训练的思想二、语言模型 2.1 统计语言模型2.2 神经网络语言模型三、词向量 3.1 独热(Onehot)编码3.2 Word Embedding四、Word2Vec 模型五、自然语言处理的预训练模型六、RNN 和 LSTM 6.1 RNN6.2 RNN 的梯度消…
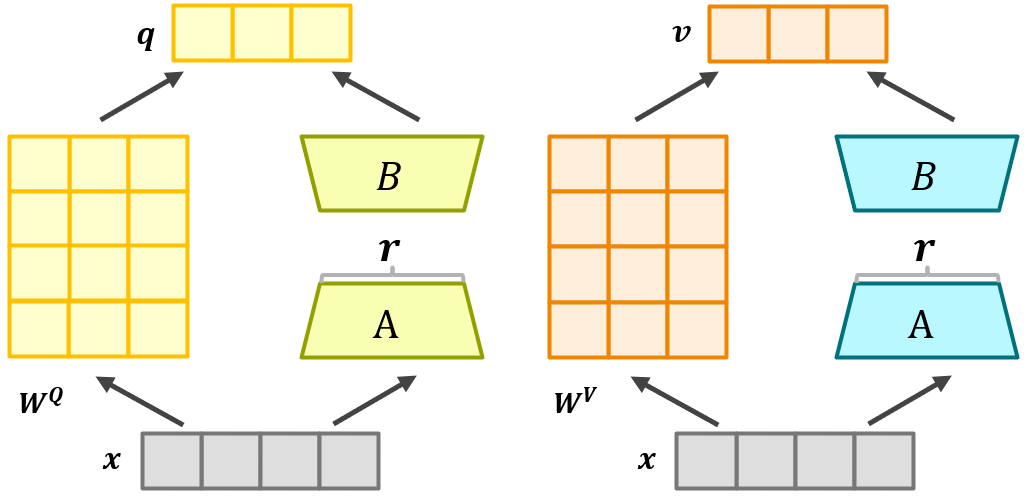
LoRA微调大语言模型Bert
LoRA是一种流行的微调大语言模型的手段,这是因为LoRA仅需在预训练模型需要微调的地方添加旁路矩阵。LoRA 的作者们还提供了一个易于使用的库 loralib,它极大地简化了使用 LoRA 微调模型的过程。这个库允许用户轻松地将 LoRA 层添加到现有的模型架构中&am…

【ML】为什么multi-lingual bert 有跨语言的能力?M-BERT有什么特点
【ML】为什么multi-lingual bert 有跨语言的能力? 1. Multi-lingual BERT的跨语言能力解析1.1 什么是Multi-lingual BERT?1.2 为什么Multi-lingual BERT有跨语言的能力?1.3 结论 2. 数据量减少对BERT识别能力的影响及Multi-lingual BERT的跨…

BERT-CRF 微调中文 NER 模型
文章目录 数据集模型定义数据集预处理BIO 标签转换自定义Dataset拆分训练、测试集 训练验证、测试指标计算推理其它相关参数CRF 模块 数据集
CLUE-NER数据集:https://github.com/CLUEbenchmark/CLUENER2020/blob/master/pytorch_version/README.md
模型定义
imp…

昇思MindSpore 应用学习-基于 MindSpore 实现 BERT 对话情绪识别
基于 MindSpore 实现 BERT 对话情绪识别
模型简介
BERT全称是来自变换器的双向编码器表征量(Bidirectional Encoder Representations from Transformers),它是Google于2018年末开发并发布的一种新型语言模型。与BERT模型相似的预训练语言模…

大模型种草书籍——BERT基础教程:Transformer大模型实战,看完头皮发麻!
《BERT基础教程:Transformer大模型实战》 是一本专注于介绍自然语言处理(NLP)领域的先进技术——BERT(Bidirectional Encoder Representations from Transformers)及其应用的教程书籍。
以下是这本书的简要介绍&#…
BERT一个蛋白质-季军-英特尔创新大师杯冷冻电镜蛋白质结构建模大赛-paipai
关联比赛: “创新大师杯”冷冻电镜蛋白质结构建模大赛
解决方案
团队介绍
paipai队、取自 PAIN AI,核心成员如我本人IvanaXu(IvanaXu GitHub),从事于金融科技业,面向银行信用贷款的风控、运营场景。但我们团队先后打过很多比赛…

小琳AI课堂:深入学习BERT
大家好,这里是小琳AI课堂。今天我们来聊聊BERT,这个在自然语言处理(NLP)领域掀起革命风潮的模型。
出现背景
在BERT之前,NLP领域主要依赖RNN或CNN模型,这些模型大多只能单向处理文本,从左到右…

Sentence-BERT实现文本匹配【回归目标函数】
引言
上篇文章我们通过Sentence-Bert提出的分类目标函数来训练句子嵌入模型,本文同样基于Sentence-Bert的架构,但改用回归目标函数。
架构 如上图,计算两个句嵌入 u \pmb u u和 v \pmb v v之间的余弦相似度,然后可以使用均方误…
【Tools】大模型中的BERT概念
摇来摇去摇碎点点的金黄 伸手牵来一片梦的霞光 南方的小巷推开多情的门窗 年轻和我们歌唱 摇来摇去摇着温柔的阳光 轻轻托起一件梦的衣裳 古老的都市每天都改变模样 🎵 方芳《摇太阳》 BERT(Bidirectional Encoder Representations…

【AI大模型】解锁AI智能:从注意力机制到Transformer,再到BERT与GPT的较量
文章目录 前言一、揭秘注意力机制:AI的焦点如何塑造智能1.什么是注意力机制?2.为什么需要注意力机制? 二、变革先锋:Transformer的突破与影响力1.什么是Transformer?2.为什么Transformer如此重要? 三、路径…
人工智能论文:GPT, GPT-2, GPT-3 对比和演进的思路
2018.6 GPT: Improving Language Understanding by Generative Pre-Training
第一篇主要强调 无监督预训练有监督微调transformer 主要成果: 1,无监督预训练:使得模型能够从海量未标记数据中自主学习,为后续任务提供了…

泛读笔记:从Word2Vec到BERT
自然语言处理(NLP)模型的发展历史 1.统计方法时期:使用贝叶斯方法、隐马尔可夫模型、概率模型等传统统计方法 2.机器学习时期:支持向量机(SVM)、决策树模型、随机森林、朴素贝叶斯等传统机器学习方法 3.深度学习革命:各种新的深度学习模型&am…
李沐69_BERT训练集——自学笔记
NLP里的迁移学习
1.使用预训练好的模型来抽取词、句子的特征,例如word2vec或语言模型
2.不更新预训练好的模型
3.需要构建新的网络来抓取新任务需要的信息:word2vec忽略了时序信息,语言模型只看了一个方向
BERT的动机
1.基于微调的NLP模…
【Tools】大模型中的BERT概念
摇来摇去摇碎点点的金黄 伸手牵来一片梦的霞光 南方的小巷推开多情的门窗 年轻和我们歌唱 摇来摇去摇着温柔的阳光 轻轻托起一件梦的衣裳 古老的都市每天都改变模样 🎵 方芳《摇太阳》 BERT(Bidirectional Encoder Representations…