1、HDFS架构
Hadoop Distribute File System,Hadoop分布式文件系统,HDFS是Hadoop核心组件之一,作为生态圈最底层的分布式服务而存在。
HDFS解决的问题就是大数据如何存储。
架构图:主从架构(master/slave)。通常包含一个主节点和多个从节点。主节点存储和管理namespace,即文件块、位置、权限、大小、其实地址等等,从节点存储文件数据块
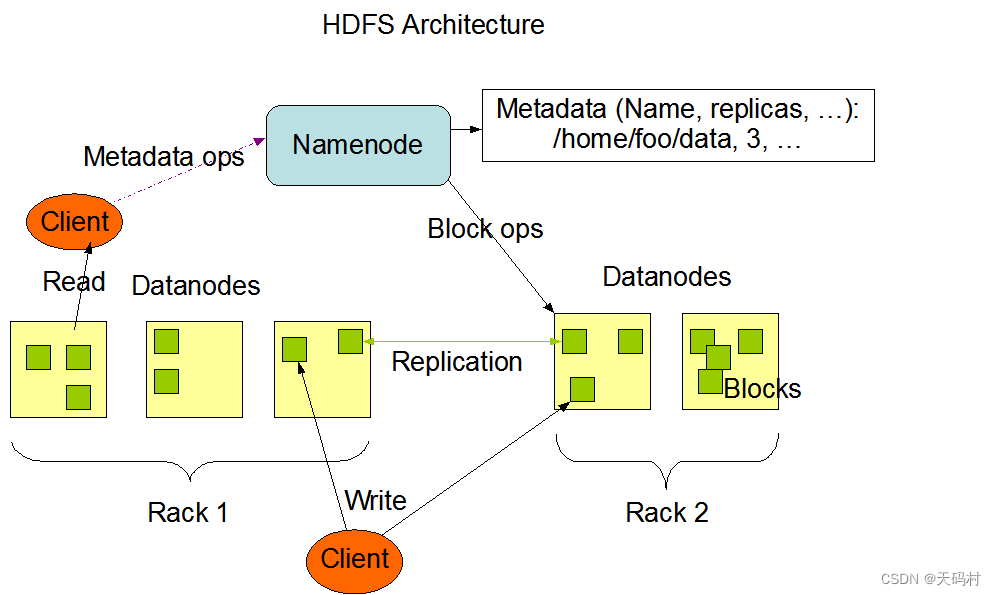
1.1 角色职责、
namenode是主节点,管理文件西戎元数据信息,包括namespace目录结构、文件块位置。分布式文件系统的核心,架构中的主角色,维护管理系统元数据,包括空间目录树结构、文件和块的位置信息、访问权限。NameNode成为了HDFS的唯一入口。
NameNode内部通过内存和磁盘文件两种方式管理元数据。,内存优点速度快、缺点不能持久保存。磁盘上的元数据包括Fsimage内存元数据镜像文件和edits log(Joural)编辑日志。
Hadoop2之前,namenode是单点故障,Hadoop2中引入的高可用,集群中热备运行两个或多个Namenode。
datanode是从节点,负责存储文件具体的数据块。从角色,负责具体数据块的存储,DataNode的数量决定了HDFS集群的整体数据存储能力,通过和NameNode配合维护着数据块。
两种角色各司其职,协调完成文件存储服务
SecondaryNameNode:主角色的辅助角色,帮助主角色进行元数据的合并,(和namenode不同,也不是备份,也不能代替namenode)。守护进程,充当Namenode的辅助,不能替代NameNode,当NameNode合并Fsimage和edit log文件以还原当前文件系统的名称空间,如果edit log过大不利于加载,SecondaryNameNode就是辅助从Namenode下载Fsimage文件和edits log文件进行合并。
1.2 重要特性
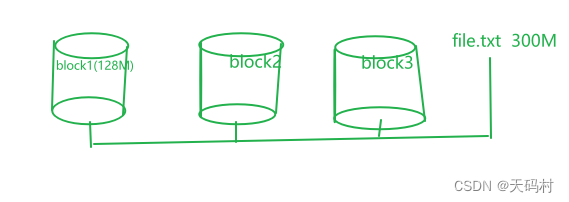
HDFS在文件的物理上是分块存储(Block)的,块的大小可以通过配置参数来规定,参数位于hdfs-default.xml中,dfs.blocksize。默认128M
副本机制,每一个块不是存储一份,默认存储三份,文件的所有block,默认dfs.replication 的值是3,也就是会额外在复制两个副本,可以通过配置文件修改。
Namespace:层次型文件组织结构,用户可以创建目录、保存文件,创建、删除、重命名文件。NomeNode负责维护namespace命名空间。
元数据管理:元数据两种类型(文件自身属性——名称、大小、修改时间、文件大小、复制因子、数据块大小;数据块位置映射信息:记录文件块和datanode之间的映射信息,即哪个块在那个旧机器上)。
2、HDFS Web Interface
Web Interface介绍:Hadoop还为HDFS提供了一个Web 界面,访问地址是namenode节点的机器上,端口为9870。地址形式化表示为“http://nn_host:port/”。本次学习的地址为
“http://node1:9870”,页面如下
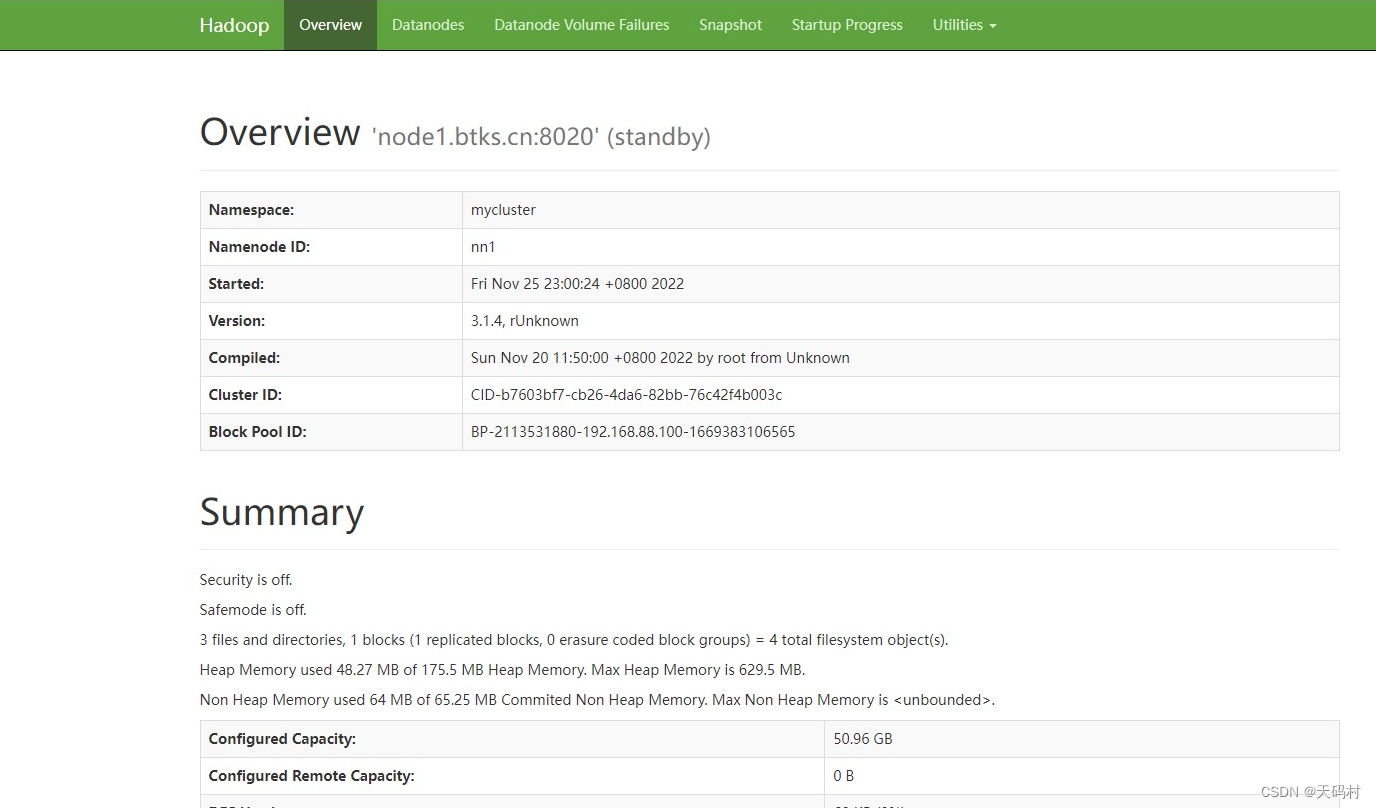
OverView模块:包含集群的基本信息、核心信息、总览信息。例如:安全模式、文件、文件块、堆内存大小,文件系统使用量表格(总量、使用量、剩余量、使用率)、Namedoe Joural State、NameNode Storage、DFS Storsge Types
DataNode模块:节点数,节点状态(在服务、下线、。。。)。
datanode Volume Failures模块:数据节点卷的错误信息。
Snapshot模块:快照概览、快照信息。
Start Progress模块:启动信息,启动步骤,完成率,完成时间
Utilities模块:包含了:文件浏览、日志、configuration(配置)等子模块
3、HDFS读写流程
3.1写流程
核心概念-pipeline(管道),这是HDFS在上传写数据过程中采用的一种数据传输方式。客户端将数据块写入第一个DN,第一个DN保存之后传给第二个,然后第二个DN传给第三个,。。。
管道传输顺序沿着一个方向传输,这样能够充分利用每个机器的带宽,避免
ACK(Acknowledge character)应答响应,确认字符。在数据通讯中,接收方向发送方的一种传输类控制字符,表示数据确认接收无误
HDFS pipeline管道传输数据过程中,传输反向会进行ack校验。
默认3副本存储策略。BlockPlacementPolicyDefault指定
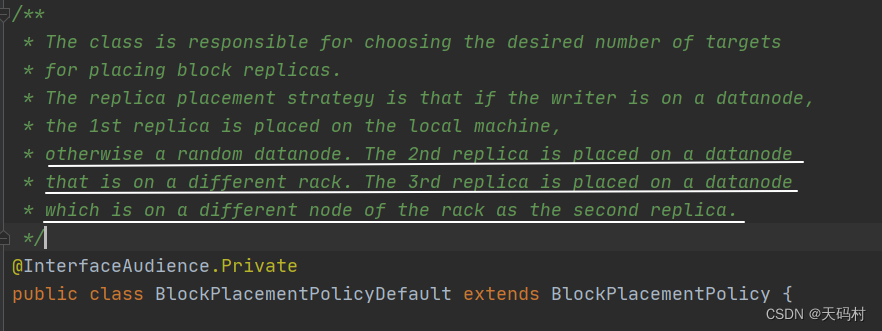
第一块副本:优先客户端本地,否则随机。
第二块副本:不同于第一块副本的不同机架
第三块副本:第二块副本相同机架的不同机器。
写数据的流程示意图:
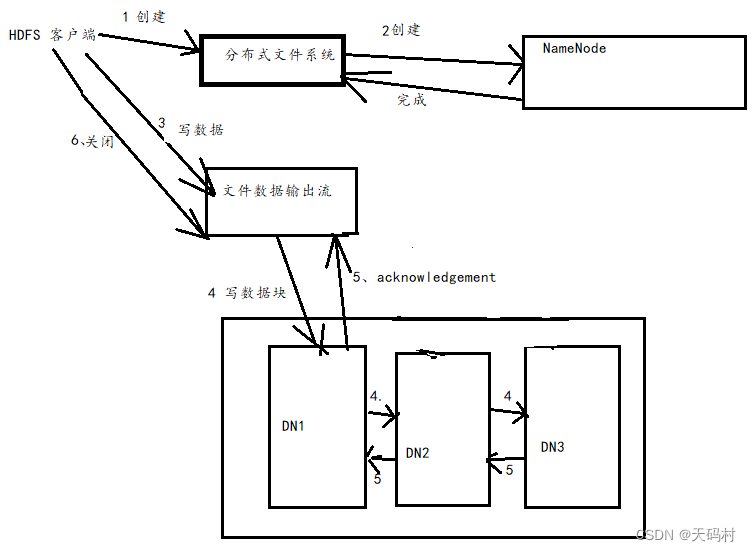
客户端创建FileSystem对象实例DistrubuteFIleSystem,调用其creat方法,通过RPC请求NameNode创建,NameNode检查文件是否存在,目录是否存在,权限,检查通过,返回文件数据输出流对象,客户端通过文件输出流向DN写数据,DN节点通过管道向下一个节点依次写数据,然后返回ack。客户端数据写入后,数据流关闭。
3.2 读数据流程
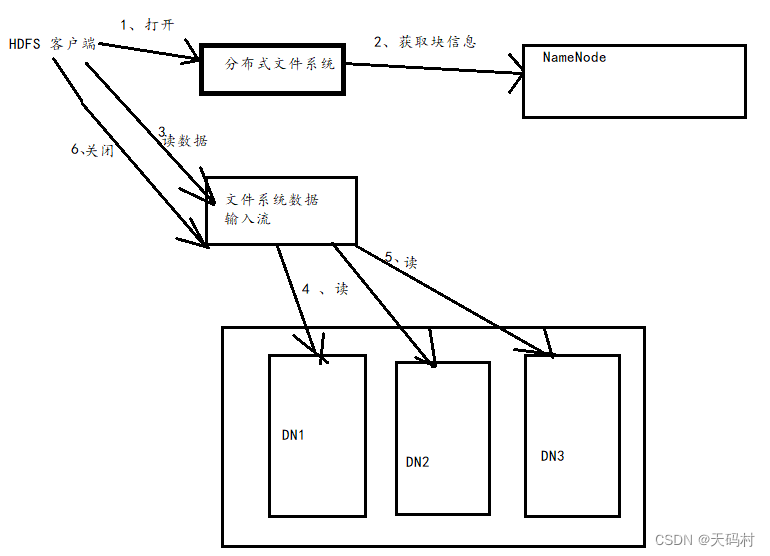
客户端首先打开分布式文件系统,然后从nn上获取文件数据的元数据,然后创建文件系统数据输入流,分别从相应的DN读取数据。
客户端必须首先连接namenode,namenode是HDFS唯一访问入口
NameNode:是HDFS的核心、集群的主角色,被称为master.
NameNode仅存储HDFS的元数据:文件系统namespace操作维护目录树,文件和块
NameNode不存储世家的数据和数据集,DataNode存储
NameNode知道HDFS任何给定文件的块列表及其位子
NameNode并不持久化每个文件中各个块所在的DataNode的位置信息,这些信息会在系统启动时从DataNode中重建。
NameNode对于HDFS至关重要,Name Node关闭时,HDFS/Hadoop集群无法访问
NameNode 在Hadoop 1.0中,单点故障,2.0支持主备切换。
NameNode需要配置大内存。
DataNode职责
DataNode负责将实际数据存储在HDFS中,是集群的从脚色。
DataNode启动时,他将自己发布到NameNode,并汇报自己负责持有的块列表。
根据NameNode的指令,执行块的创建、复制、删除操作。
DataNode会定期(dfs.heartbeat.interval配置项配置,默认3s)向NameNode发送心跳,如果NameNode长时间没有接收到DataNode发送的心跳,NameNode就会任务DataNode失效。
DataNode会定期向NameNode汇报自己持有的数据块,汇报时间间隔参数
dfs.blockreport.intervalMsec,参数未配置默认6小时。
DataNode所在的机器需要大磁盘。
4、NomeNode元数据管理
元数据:为描述数据的数据(data about data)
在HDFS中,元数据主要指的是文件相关的元数据,由NameNode维护管理。
文件自身属性信息
文件名称、权限、修改时间、文件大小、复制因子、数据块大小
文件块位置映射信息
记录文件块和DataNode之间的映射信息,即哪个块位于哪个节点上。
内存元数据
内存保证用户操作比较快,NameNode把所有元数据都存储在内存中,我们叫做内存元数据,内存中的元数据是最为完整的。
内存致命问题:断电数据丢失,数据不会持久化
元数据文件
fsimage内存镜像文件,内存元数据的一个持久化检查点,但是fsimage中仅包含hadoop文件系统中的自身文件属性相关的元数据ixni,不包含文件块位置信息,文件块位置信息只保存在内存当中,启动的时候由datanode上报。文件信息持久化到磁盘,IO过程对namenode性能产生影响,一般元fsImage镜像数据文件记录不能太频繁。
Edits Log编辑日志
为了避免两次持久化之间的数据丢失,又设计了Edits Log编辑日志文件,文件中记录的是HDFS所有更改操作(创建、删除、修改),文件系统客户端的操作首先记录到edits中。
namenode 启动的时候先加载fsimage,之后再执行edits文件中的各项操作
NameNode元数据管理相关的目录文件
HDFS首次启动之前需要首先进行format操作,format之前,HDFS在物理上还不存在,其次此处format并不是格式化,而是清楚与准备工作。
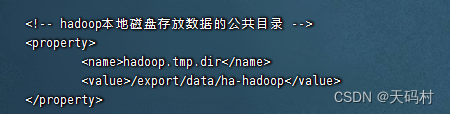
namenode元数据存储目录由参数:dfs.namenode.name.dir指定,在hdfs-site.xml文件中配置。默认值为

在core-site中查看配置的hadoop.tmp.dir值
查看
cat /export/servers/hadoop-3.1.4/etc/hadoop/core-site.xmlhadoop.tmp.dir的值
进入到相关目录

进入到current目录,查看最终存储的目录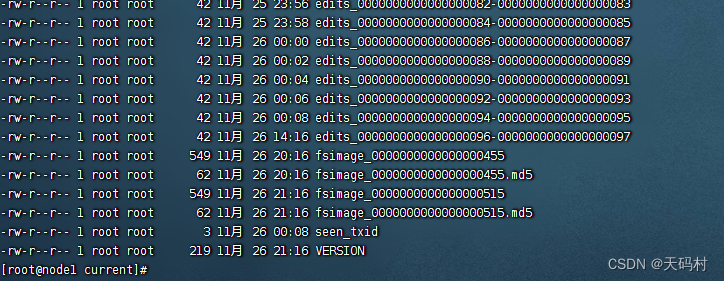
Version,查看
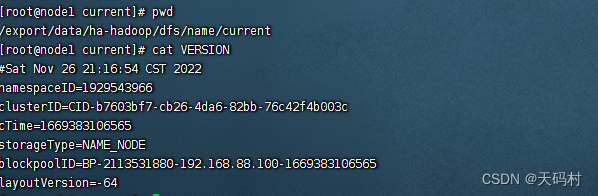
lnamespaceID、clusterID、blockpoolID这些都是(HDFS唯一标识符,联邦架构下)
namespaceID:每个的NameNode提供唯一的命名空间,并管理一组唯一的文件块池(blockpoolID)。clusterID将整个集群结合在一起作为单个逻辑单元,在集群中的所有节点上都是一样的
fsImage文件内容查看,直接无法查看
oiv是offline image viewer的缩写,可以转为xml格式查看
命令
hdfs oiv -i fsimage_0000000000000000515 -p XML -o fsiamge.xml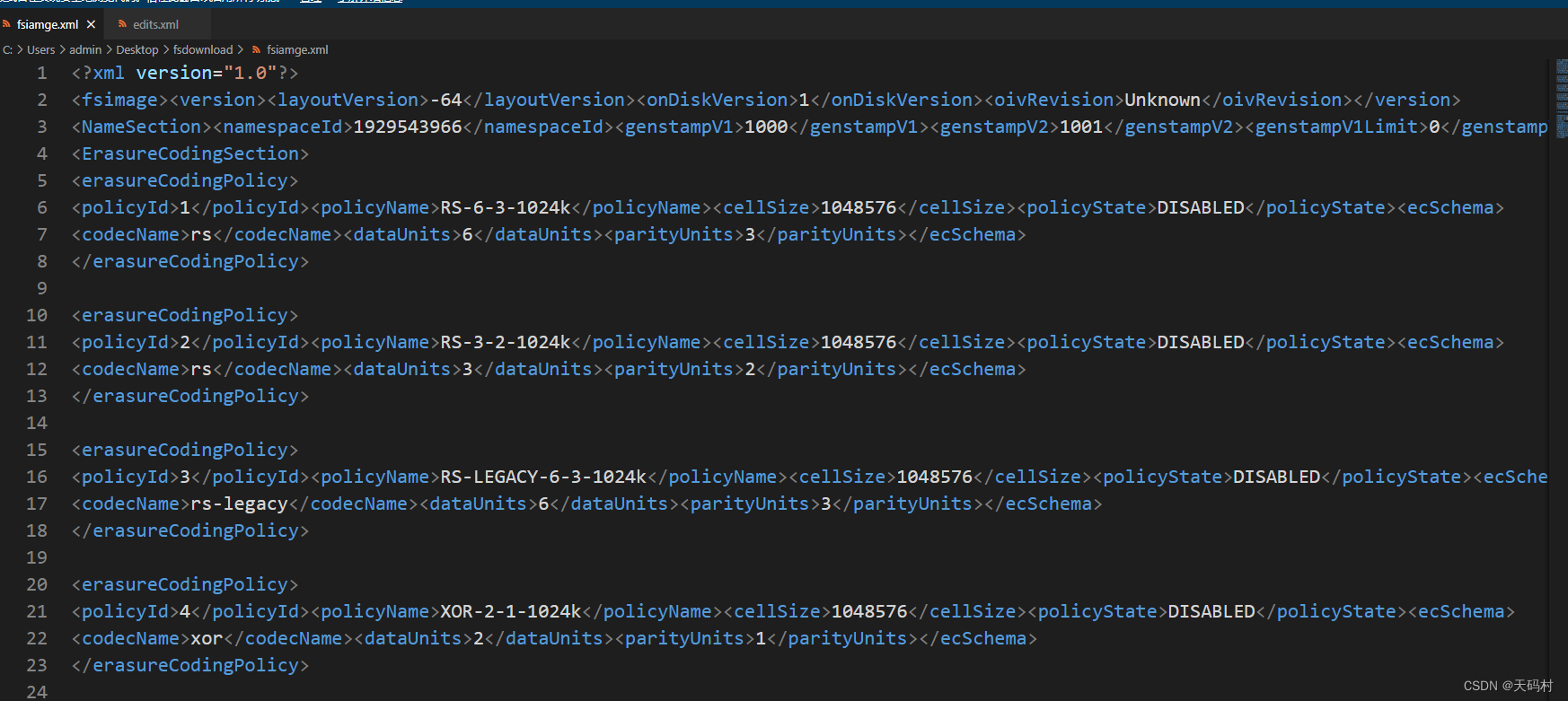
edits log 查看
命令
hdfs oev -i edits_0000000000000000010-0000000000000000017 -o edits.xml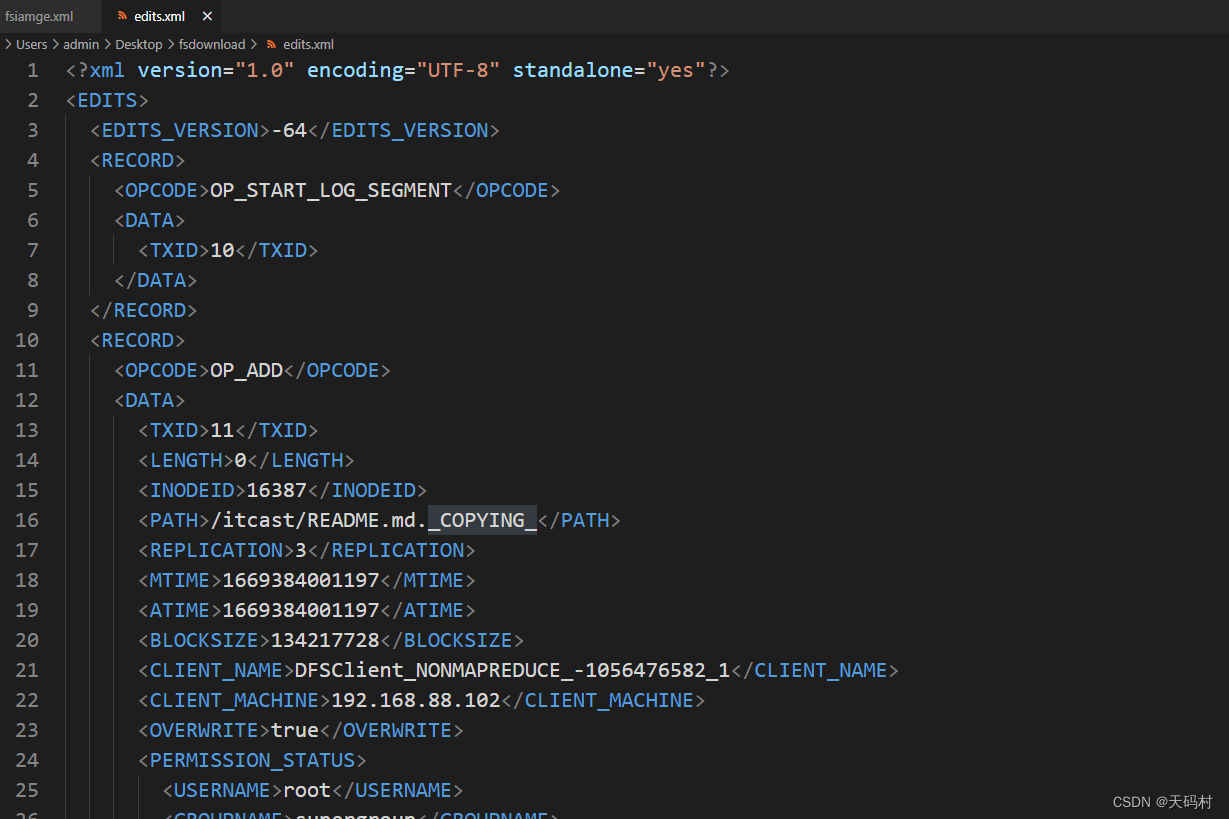
SecondaryNameNode
edit logs因操作过多,记录变多而变大
fsimage因时间间隔时间长将会变旧
namenode重启会花费很长的时间,因为有很多改动需要从edit log合并到fsimage
频繁进行持久化,影响NN正常服务
SNN为了克服上述问题,合并edit log 和 fsiamge,减小edit log文件的大小和得到一个新的fsimage文件,减小NN的压力。
SNN Checkpoint 核心是把fsimage与edits log合成以生成新的fsimage的过程。
第一步:出发checkpoint操作条件时,snn发送请求给nn滚动edit log。然后nn生成新的编辑日志,
第二步:snn将旧的edit log文件和上次fsimage复制到本地合并成一个新的fsimage文件。
第三步:snn首先将fsiamge载入内存,然后一条一条执行edit文件中的操作,使得内存中的fsimage不断更新,这个过程就是edits和fsimage文件合并。合并结束,snn在内存中生成一个fsiamge,写到磁盘
第四步:snn将新的fsimage文件复制到nn节点,至此刚好是一个轮回,等待下一次checkpoint出发snn进行工作,一直这样循环操作。
checkpoint的触发条件:
hdfs-site.xml
dfs.namenode.checkpoint.period=3600 //两次连续的checkpoint之间的时间间隔。默认1小时
dfs.namenode.checkpoint.txns=1000000 //最大没有执行checkpoint事务的数量,满足将强制执行紧急checkpoint,即使尚未达到检查点周期。默认100万事务数量。
NameNode元数据恢复
(1)NameNode存储 多目录
namenode元数据存储目录参数:dfs.namenode.name.dir指定,多个目录,生成的内容相同。
可以将目录指向网络文件系统。
(2)从SNN在checkpoint的时候会将fsimage和edit logs下载到本地,checkpoint之后也不会删除。

这个操作可以恢复部分数据,不能恢复全部数据。
(3)高可用,主备namenode。
5、小文件解决方案
Hadoop Archive文件归档
背景;HDFS不擅长存储小文件,因为每个文件最少一个block,block的元数据会占用namenode内存,小文件吃内存。
测试,生成小文件,存储到HDFS
[root@node2 ~]# echo 1 > 1.txt
[root@node2 ~]# echo 1 > 2.txt
[root@node2 ~]# echo 1 > 3.txt
[root@node2 ~]# ls
1.txt 2.txt 3.txt anaconda-ks.cfg core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml
[root@node2 ~]# hadoop fs -mkdir /smallfile
[root@node2 ~]# hadoop fs -put 1.txt 2.txt 3.txt /smallfile
每个小文件只有2B,但是需要记录文件名、大小、块信息等元数据到NN的内存。
Archive概述:可以有效的处理以上问题,把多个文件归档成一个文件,归档后文件还可以透明的访问每一个文件。文件越多,效果越明显。
创建Archive
[root@node2 ~]# hadoop archive --help
usage: archive <-archiveName <NAME>.har> <-p <parent path>> [-r <replication factor>] <src>* <dest>-archiveName <arg> Name of the Archive. This is mandatory option-help Show the usage-p <arg> Parent path of sources. This is mandatory option-r <arg> Replication factor archive files
-archiveName 要创建归档的文件名称,扩展名是*.har
-p <arg> 指定文件档案文件src的相对路径
-r <arg> Replication factor archive files
比如:-p /foo/bar a/b/c e/f/g,这里的/foo/bar是a/b/c与e/f/g的父路径,所以完整路径为/foo/bar/a/b/c与/foo/bar/e/f/g。
归档smallfile中的小文件
查看文件
[root@node2 ~]# hadoop fs -ls /smallfile
Found 3 items
-rw-r--r-- 3 root supergroup 2 2022-11-26 23:28 /smallfile/1.txt
-rw-r--r-- 3 root supergroup 2 2022-11-26 23:28 /smallfile/2.txt
-rw-r--r-- 3 root supergroup 2 2022-11-26 23:28 /smallfile/3.txt
启动yarn
start-yarn.sh执行归档
hadoop archive -archiveName test.har -p /smallfile /outoutdir查看归档内容
hadoop fs -ls /outputdir/test.har查看Archive--查看归档之前的样子
在查看har文件的时候,如果没有指定访问协议,默认使用的就是hdfs://,此时所能看到的就是归档之后的样子。
此外,Archive还提供了自己的har uri访问协议。如果用har uri去访问的话,索引、标识等文件就会隐藏起来,只显示创建档案之前的原文件:
Hadoop Archives的URI是:
har://scheme-hostname:port/archivepath/fileinarchive
scheme-hostname格式为hdfs-域名:端口提取
#按顺序解压存档(串行):
hadoop fs -cp har:///outputdir/test.har/* /smallfile1
#要并行解压存档,请使用DistCp,对应大的归档文件可以提高效率:
hadoop distcp har:///outputdir/test.har/* /smallfile2
Sequence File
<dependencies><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>3.1.4</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>3.1.4</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.1.4</version></dependency>
</dependencies>代码
写序列化
package cn.itcast.hdfs.sequence;import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.SequenceFile;import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.GzipCodec;/*** @description:* @author: Allen Woon* @time: 2020/12/23 15:56*/
public class SequenceFileWrite {private static final String[] DATA = {"One, two, buckle my shoe","Three, four, shut the door","Five, six, pick up sticks","Seven, eight, lay them straight","Nine, ten, a big fat hen"};public static void main(String[] args) throws Exception {//设置客户端运行身份 以root去操作访问HDFSSystem.setProperty("HADOOP_USER_NAME","root");//Configuration 用于指定相关参数属性Configuration conf = new Configuration();//sequence file key、valueIntWritable key = new IntWritable();Text value = new Text();//构造Writer参数属性SequenceFile.Writer writer = null;CompressionCodec Codec = new GzipCodec();SequenceFile.Writer.Option optPath = SequenceFile.Writer.file(new Path("hdfs://node1:8020/seq.out"));SequenceFile.Writer.Option optKey = SequenceFile.Writer.keyClass(key.getClass());SequenceFile.Writer.Option optVal = SequenceFile.Writer.valueClass(value.getClass());SequenceFile.Writer.Option optCom = SequenceFile.Writer.compression(SequenceFile.CompressionType.RECORD,Codec);try {writer = SequenceFile.createWriter( conf, optPath, optKey, optVal, optCom);for (int i = 0; i < 100; i++) {key.set(100 - i);value.set(DATA[i % DATA.length]);System.out.printf("[%s]\t%s\t%s\n", writer.getLength(), key, value);writer.append(key, value);}} finally {IOUtils.closeStream(writer);}}}
读序列化
package cn.itcast.hdfs.sequence;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.util.ReflectionUtils;import java.io.IOException;/*** @description:* @author: Allen Woon* @time: 2020/12/23 20:27*/
public class SequenceFileRead {public static void main(String[] args) throws IOException {//设置客户端运行身份 以root去操作访问HDFSSystem.setProperty("HADOOP_USER_NAME","root");//Configuration 用于指定相关参数属性Configuration conf = new Configuration();SequenceFile.Reader.Option option1 = SequenceFile.Reader.file(new Path("hdfs://node1:8020/seq.out"));SequenceFile.Reader.Option option2 = SequenceFile.Reader.length(174);//这个参数表示读取的长度SequenceFile.Reader reader = null;try {reader = new SequenceFile.Reader(conf,option1,option2);Writable key = (Writable) ReflectionUtils.newInstance(reader.getKeyClass(), conf);Writable value = (Writable) ReflectionUtils.newInstance(reader.getValueClass(), conf);long position = reader.getPosition();while (reader.next(key, value)) {String syncSeen = reader.syncSeen() ? "*" : "";//是否返回了Sync Mark同步标记System.out.printf("[%s%s]\t%s\t%s\n", position, syncSeen, key, value);position = reader.getPosition(); // beginning of next record}} finally {IOUtils.closeStream(reader);}}}
合并小文件
package cn.itcast.hdfs.sequence;/*** @description:* @author: Allen Woon* @time: 2020/12/24 11:21*/
import java.io.File;
import java.io.FileInputStream;
import java.nio.charset.Charset;
import java.util.ArrayList;
import java.util.List;import org.apache.commons.codec.digest.DigestUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileUtil;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.SequenceFile.Reader;
import org.apache.hadoop.io.SequenceFile.Writer;
import org.apache.hadoop.io.Text;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;public class MergeSmallFilesToSequenceFile {private Configuration configuration = new Configuration();private List<String> smallFilePaths = new ArrayList<String>();//定义方法用来添加小文件的路径public void addInputPath(String inputPath) throws Exception{File file = new File(inputPath);//给定路径是文件夹,则遍历文件夹,将子文件夹中的文件都放入smallFilePaths//给定路径是文件,则把文件的路径放入smallFilePathsif(file.isDirectory()){File[] files = FileUtil.listFiles(file);for(File sFile:files){smallFilePaths.add(sFile.getPath());System.out.println("添加小文件路径:" + sFile.getPath());}}else{smallFilePaths.add(file.getPath());System.out.println("添加小文件路径:" + file.getPath());}}//把smallFilePaths的小文件遍历读取,然后放入合并的sequencefile容器中public void mergeFile() throws Exception{Writer.Option bigFile = Writer.file(new Path("D:\\bigfile.seq"));Writer.Option keyClass = Writer.keyClass(Text.class);Writer.Option valueClass = Writer.valueClass(BytesWritable.class);//构造writerWriter writer = SequenceFile.createWriter(configuration, bigFile, keyClass, valueClass);//遍历读取小文件,逐个写入sequencefileText key = new Text();for(String path:smallFilePaths){File file = new File(path);long fileSize = file.length();//获取文件的字节数大小byte[] fileContent = new byte[(int)fileSize];FileInputStream inputStream = new FileInputStream(file);inputStream.read(fileContent, 0, (int)fileSize);//把文件的二进制流加载到fileContent字节数组中去String md5Str = DigestUtils.md5Hex(fileContent);System.out.println("merge小文件:"+path+",md5:"+md5Str);key.set(path);//把文件路径作为key,文件内容做为value,放入到sequencefile中writer.append(key, new BytesWritable(fileContent));}writer.hflush();writer.close();}//读取大文件中的小文件public void readMergedFile() throws Exception{Reader.Option file = Reader.file(new Path("D:\\bigfile.seq"));Reader reader = new Reader(configuration, file);Text key = new Text();BytesWritable value = new BytesWritable();while(reader.next(key, value)){byte[] bytes = value.copyBytes();String md5 = DigestUtils.md5Hex(bytes);String content = new String(bytes, Charset.forName("GBK"));System.out.println("读取到文件:"+key+",md5:"+md5+",content:"+content);}}public static void main(String[] args) throws Exception {MergeSmallFilesToSequenceFile msf = new MergeSmallFilesToSequenceFile();//合并小文件
// msf.addInputPath("D:\\datasets\\smallfile");
// msf.mergeFile();//读取大文件msf.readMergedFile();}
}