游游的you

思路
贪心:优先组成 you,最少的字母决定了you的数量。需要注意:如果oo剩下n个,那么相邻oo的个数是n-1个,而不是n/2个。
例如
oooooo
oo oo oooo oo
6个o,两两组合有3对,掐头去尾有2对,总共5对。
代码
#include <iostream>
#include <algorithm>
using namespace std;int main()
{int q;cin >> q;while (q--) {int a, b, c;cin >> a >> b >> c;int you_num = min({a, b, c});int oo_num = max(0, b - you_num - 1);cout << you_num * 2 + oo_num << endl;}return 0;
}
腐烂的苹果

BFS
将每个腐烂的苹果视为一个起点,同时扩展它们对周围苹果的影响。每个腐烂的苹果每分钟会将相邻的苹果腐烂,类似于层层扩散的波浪,因此 BFS 是非常适合的。
- 初始化队列:首先,我们需要找到所有腐烂的苹果,并将它们的坐标加入到 BFS 队列中。每个腐烂的苹果作为一个初始点,且时间为0。
- BFS 扩展:每次从队列中取出一个腐烂的苹果,检查它的四个方向(上下左右),如果相邻格子是一个完好的苹果,则将其腐烂,并将其加入到队列中,同时记录时间。
- 判断结果:BFS 结束后,检查是否还有完好的苹果。如果有,返回 -1;否则返回所需的最大时间。
代码
class Solution
{
public:// 定义方向数组,表示四个方向const int directions[4][2] = {{-1, 0}, {1, 0}, {0, -1}, {0, 1}};int rotApple(vector<vector<int>> &grid) {int n = grid.size(), m = grid[0].size();queue<pair<int, int>> q;int freshApples = 0; // 记录新鲜苹果的数量// 初始化队列,并统计新鲜苹果的数量for (int i = 0; i < n; ++i)for (int j = 0; j < m; ++j)if (grid[i][j] == 2) q.push({i, j});else if (grid[i][j] == 1) freshApples++;// 如果没有新鲜苹果,直接返回0if (freshApples == 0) return 0;int minutes = 0;// BFS 扩展while (!q.empty()){int size = q.size();bool rottenThisMinute = false;for (int i = 0; i < size; ++i){auto [x, y] = q.front();q.pop();for (int d = 0; d < 4; ++d){int nx = x + directions[d][0];int ny = y + directions[d][1];// 检查新位置是否合法,并且是否有新鲜苹果if (nx >= 0 && nx < n && ny >= 0 && ny < m && grid[nx][ny] == 1){grid[nx][ny] = 2; // 使其腐烂q.push({nx, ny});freshApples--;rottenThisMinute = true;}}}// 如果这分钟有苹果腐烂,增加时间if (rottenThisMinute) minutes++;}// 如果还有新鲜苹果,返回 -1return freshApples == 0 ? minutes : -1;}
};DFS
使用 DFS 来解决这个问题会有一些不方便之处,特别是在处理需要“波浪”式传播的情况时(例如,腐烂的苹果会同时向四周扩散)。DFS 适合用于深度优先搜索,而 BFS 更适合于层层扩展、逐层处理的场景。
- BFS 的层次扩展特性:
- BFS 一次处理一个层次上的所有节点(在这个问题中,相当于同一时间点所有腐烂的苹果),自然适合模拟每分钟同时传播腐烂的过程。
- 使用 BFS,每分钟的腐烂传播相当于从一个层次扩展到下一个层次,时间计数器每次增加1分钟。
- DFS 的局限性:
- DFS 适用于深度遍历,它会一直沿着一条路径深入,直到不能再走为止,然后回溯。这种遍历方式难以模拟同一时间点多个苹果同时腐烂的情况。
- 如果用 DFS,你需要额外的逻辑来同步和控制腐烂的时间进度,这样实现起来会非常复杂且容易出错。
实际 DFS 实现的难点:
- 多源同时起点处理:DFS 通常处理单源问题较多,而这里每个腐烂的苹果都是一个起点,需要多源处理。
- 同步时间控制:需要对每个腐烂的苹果扩散时间进行精确控制,使得同时腐烂的效果能正确实现。
即便如此,我们仍然可以尝试用 DFS 来实现,只是实现会更加复杂。
代码
class Solution
{
public:const int directions[4][2] = {{-1, 0}, {1, 0}, {0, -1}, {0, 1}};void dfs(vector<vector<int>> &grid, vector<vector<int>> &timeGrid, int x, int y,int currentTime){int n = grid.size();int m = grid[0].size();for (int d = 0; d < 4; ++d){int nx = x + directions[d][0];int ny = y + directions[d][1];if (nx >= 0 && nx < n && ny >= 0 && ny < m && grid[nx][ny] == 1){if (timeGrid[nx][ny] == -1 || timeGrid[nx][ny] > currentTime + 1){timeGrid[nx][ny] = currentTime + 1;dfs(grid, timeGrid, nx, ny, currentTime + 1);}}}}int rotApple(vector<vector<int>> &grid){int n = grid.size();int m = grid[0].size();vector<vector<int>> timeGrid(n, vector<int>(m, -1));int freshApples = 0;// 初始化腐烂的苹果时间为0for (int i = 0; i < n; ++i){for (int j = 0; j < m; ++j){if (grid[i][j] == 2){timeGrid[i][j] = 0;dfs(grid, timeGrid, i, j, 0);}else if (grid[i][j] == 1){freshApples++;}}}// 找到最大时间int maxTime = 0;for (int i = 0; i < n; ++i){for (int j = 0; j < m; ++j){if (grid[i][j] == 1){if (timeGrid[i][j] == -1)return -1;maxTime = max(maxTime, timeGrid[i][j]);}}}return maxTime;}
};
孩子们的游戏(圆圈中最后剩下的数)
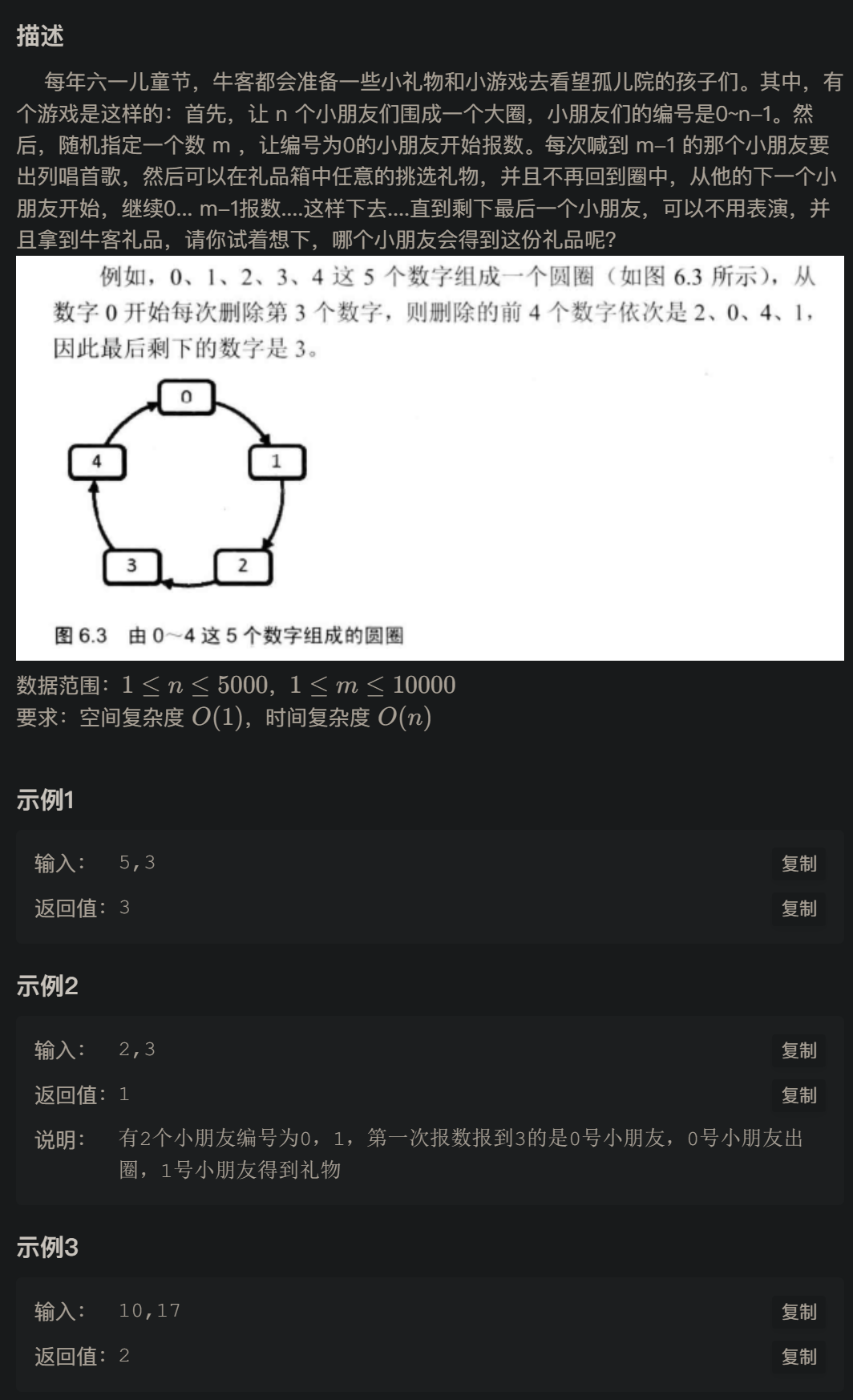
思路
这个问题可以用著名的约瑟夫环(Josephus Problem)的思路来解决。我们要找出最后剩下的那个小朋友的编号。经典的约瑟夫问题可以通过递归或迭代的方式来解决,并且时间复杂度为 O(n),空间复杂度为 O(1)。
约瑟夫问题的递推公式如下:
- 令 f(n, m) 表示在 n 个人报数,每次报到 m 出列的情况下,最后一个人的位置(0-based)。
- 初始状态下,当只有一个人时,唯一的那个人的位置为0,即 f(1, m) = 0。
- 当有 n 个人时,最后剩下的人的位置可以通过 f(n-1, m) 的结果来递推得到,即 f(n, m) = (f(n-1, m) + m) % n。
代码
递归(朴素动态规划——大问题化简为子问题):
class Solution {
public:int LastRemaining_Solution(int n, int m) {// 返回当前i个人,报数j的第k个人的编号function <int(int, int, int)> dfs = [&](int i, int j, int k) -> int{// 第1个人,说明是从0开始报数if (k == 1) return (j - 1 + i) % i;// 返回i-1个人,报数j的第k-1个人,后面j个人的编号return (dfs(i - 1, j, k - 1) + j) % i;};return dfs(n, m, n);}
};
循环链表(最符合手动操作):
在约瑟夫环问题中,每次删除一个元素后,我们需要确保剩余元素仍然形成一个有效的循环链表。这就需要我们在删除某个元素时,正确更新它的指针。
初始化链表:通过数组nxt和pre来表示链表中每个节点的下一个和上一个节点。
遍历链表:每次移动m步,找到要删除的元素。
删除元素:更新前驱和后继指针,将当前节点从链表中移除。
class Solution
{
public:int LastRemaining_Solution(int n, int m){// 初始化双向循环链表vector<int> nxt(n);vector<int> pre(n);for (int i = 0; i < n - 1; i++){nxt[i] = i + 1;pre[i + 1] = i;}nxt[n - 1] = 0; // 形成一个循环pre[0] = n - 1; // 完成循环int x = 0; // 从第一个元素开始// 删除元素直到只剩下一个while (n > 1){// 找到第 m 个节点for (int i = 1; i < m; i++){x = nxt[x];}// 删除第 m 个节点(关键操作)nxt[pre[x]] = nxt[x];pre[nxt[x]] = pre[x];x = nxt[x]; // 移动到下一个节点n--; // 减少链表的大小}return x; // 最后剩下的节点}
};动态规划:
由递归进行的子问题分析可以知道:忽略环形链表的下标,可以认为它的任意一个节点都是起点和终点的交界处。对于第i个人,认为它上一个人的编号是链表的起点,那么上一个人的编号+报数,就是第i个人的编号。由于是环形链表,对其长度取余数,就是真实的编号了。
转移:
-
只有一个数,结果为0。
-
否则: d p [ i ] = ( d p [ i − 1 ] + 报数 ) % 数组长度 dp[i] = (dp[i-1]+报数) \% 数组长度 dp[i]=(dp[i−1]+报数)%数组长度
class Solution
{public:int LastRemaining_Solution(int n, int m) {int dp[n + 1];dp[1] = 0;for (int i = 2; i <= n; i++) dp[i] = (dp[i - 1] + m) % i;return dp[n];}
};
迭代:
由于填充DP数组是一个根据上一个结果来推出现在的结果的过程,而旧状态只被使用一次,所以我们不需要用数组保留原先的旧状态。
class Solution {
public:int LastRemaining_Solution(int n, int m) {if (n == 0) return -1; // 边界条件处理int last = 0; // 初始状态下,当只有一个人时,唯一的那个人的位置为0for (int i = 2; i <= n; ++i)last = (last + m) % i;return last;}
};
初始状态处理:
- 当 n 为 0 时,返回 -1,这是一种边界条件处理,虽然根据题目描述 n 不会为 0,但防止无效输入。
迭代过程:
- 从 2 人开始,一直迭代到 n 人。
- 每次迭代计算出当前人数下最后剩下的人的位置。
结果返回:
- 最后得到的 last 即为 n 个人情况下最后剩下的人的编号。
这个算法利用了迭代而非递归,避免了栈溢出问题,同时空间复杂度也为 O(1),非常高效。