1.匿名对象
当我们实例化对象后,有的对象可能只使用一次,之后就没用了。这个时候我们往往要主动去析构它,否则会占着浪费空间。但是如果遇到大量的这种情况,我们并不想每次都去创建对象、调用、析构,这样会写出很多重复无聊的代码,为了精简,可以考虑使用匿名对象
下面是它使用的一个实例:
#include <iostream>
using namespace std;class A
{
public:A(int a = 0, int b = 0):_a(a),_b(b){cout << "A(int a = 0, int b = 0)" << endl;}~A(){cout << "~A()" << endl;}void Fun(){cout << "调用函数" << endl;}
private:int _a;int _b;
};int main()
{cout << "在这之后构造\n" << endl;A().Fun();cout << "\n在这之前析构" << endl;return 0;
}运行的结果是
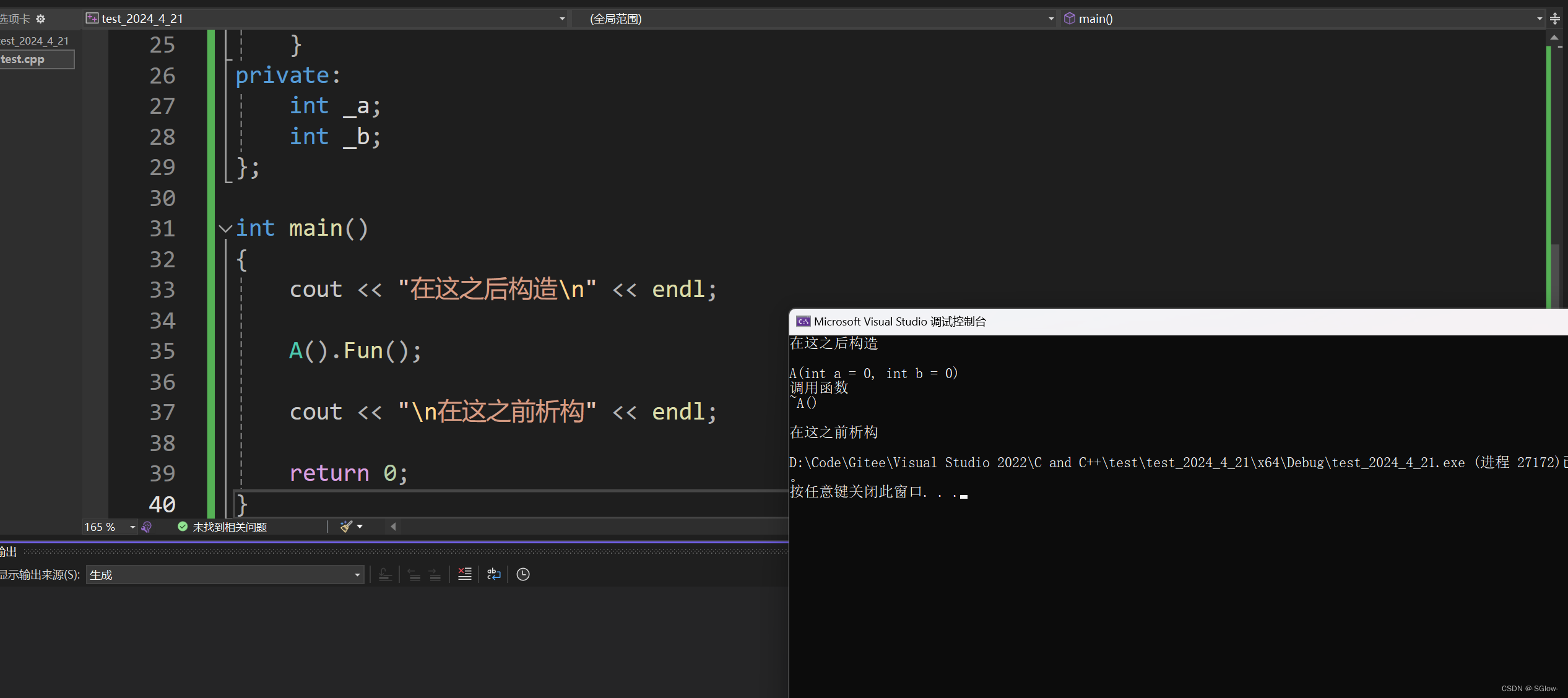
我们可以发现,匿名对象的生命周期就在那一行,在调用之后就会立马销毁。这会让我们在某些情况下代码量大大减少,看上去也很直观。
注意书写格式:
2.构造函数、拷贝构造、析构函数的优化
对于任何表达式,它都会有一个返回值,这个返回值是一个临时常变量,如果有变量接收就赋值给它,如果没有就抛弃。对于类和对象的相关操作理论上也应如此。但和内置类型不同,对象每次进行一次复制需要的开销都很大,对性能影响很大,所以编译器会做出优化,简化现有逻辑,提高效率。
下面是一些常见的在VS2022上Debug下的优化:
对于优化问题,我们常常讨论的是构造次数,因为析构和构造成对出现。
主要的优化类型是:构造+拷贝构造->构造
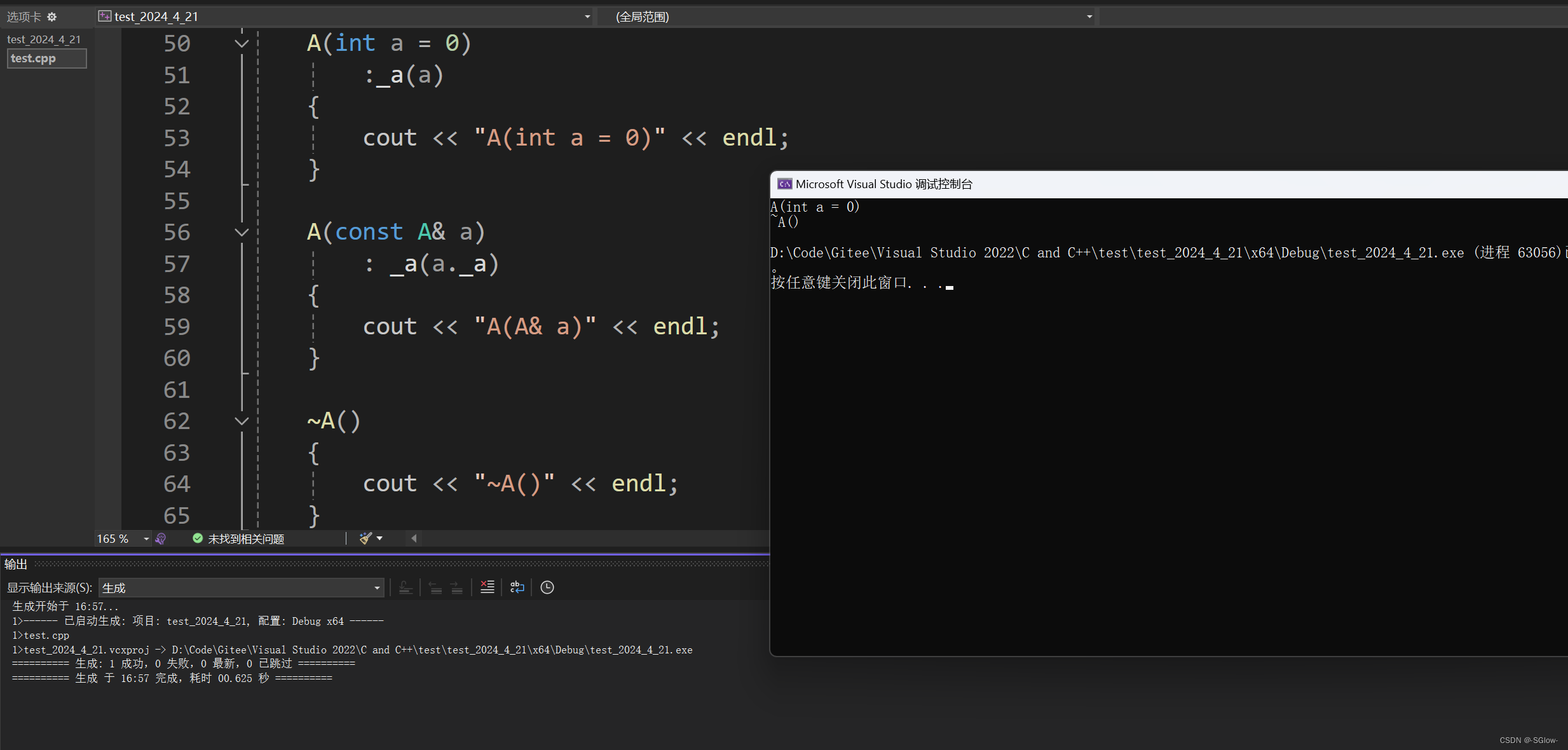
a.隐式类型转换
#include <iostream>
using namespace std;class A
{public:A(int a = 0):_a(a){cout << "A(int a = 0)" << endl;}A(const A& a): _a(a._a){cout << "A(A& a)" << endl;}~A(){cout << "~A()" << endl;}private:int _a;
};int main()
{A a = 1;return 0;
}对于A a = 1,一般逻辑是先将1作为形参调用单参数的A的构造函数得到临时常对象tmp,再采用拷贝构造给a初始化。
但是优化之后就不会生成这个临时变量了。编译器会直接将1作为参数调用对象a对应的构造函数进行初始化。这样的话就少了一次拷贝。
b.隐式类型转换+调用函数
#include <iostream>
using namespace std;class A
{public:A(int a = 0):_a(a){cout << "A(int a = 0)" << endl;}A(const A& a): _a(a._a){cout << "A(A& a)" << endl;}~A(){cout << "~A()" << endl;}static void Fun(A a){cout << "Fun(A a)" << endl;}private:int _a;
};int main()
{A::Fun(1);return 0;
}
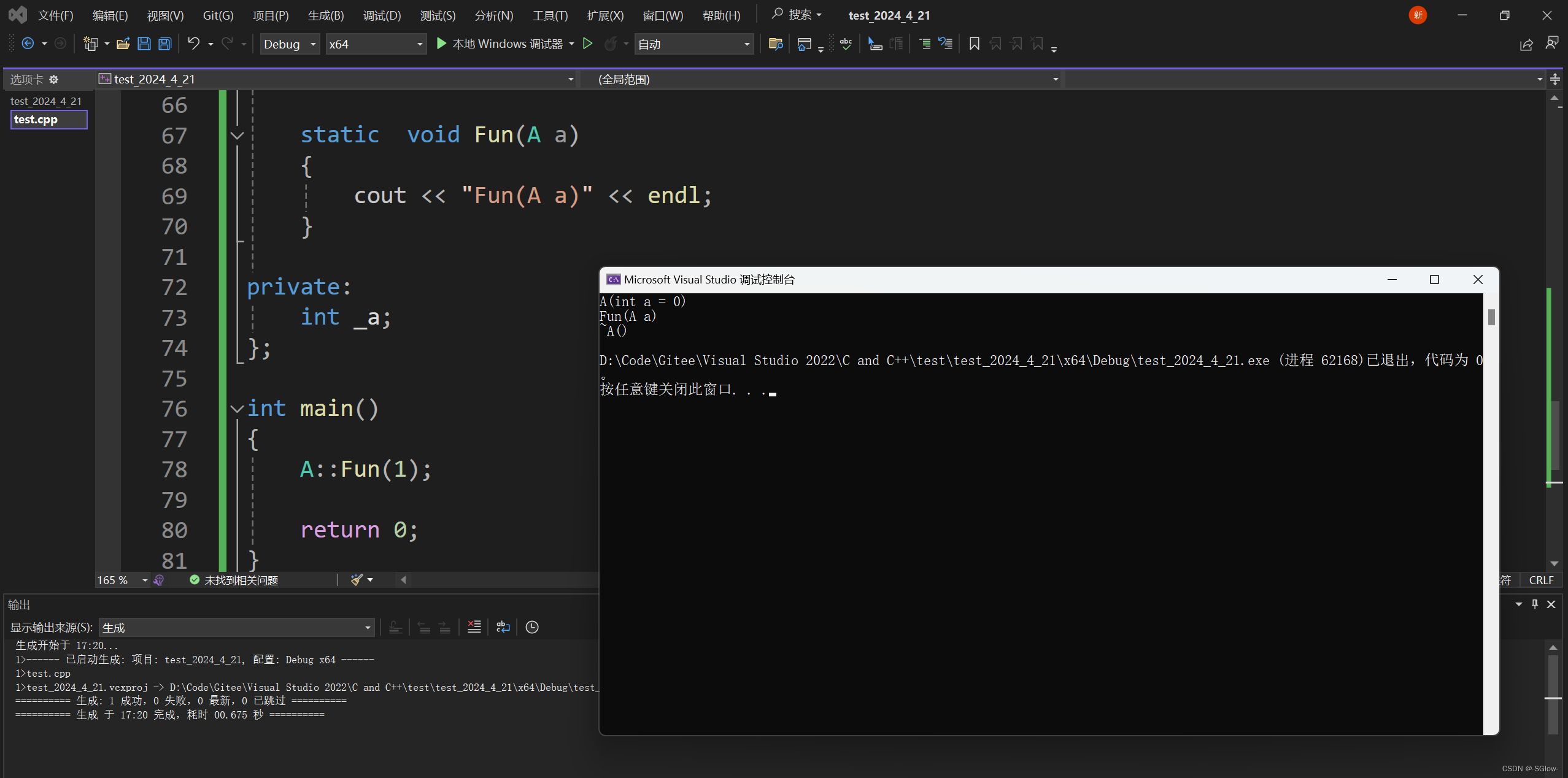 在这段代码中,1应该先调用构造生成临时对象,再将这个对象拷贝构造给形参a。
在这段代码中,1应该先调用构造生成临时对象,再将这个对象拷贝构造给形参a。
但是在这里,我们就直接将1作为参数去调用a的对应的构造函数,就不会去生成那个临时变量了。
c.当匿名对象作为实参
#include <iostream>
using namespace std;class A
{public:A(int a = 0):_a(a){cout << "A(int a = 0)" << endl;}A(const A& a): _a(a._a){cout << "A(A& a)" << endl;}~A(){cout << "~A()" << endl;}static void Fun(A a){cout << "Fun(A a)" << endl;}private:int _a;
};int main()
{A::Fun(A(1));return 0;
}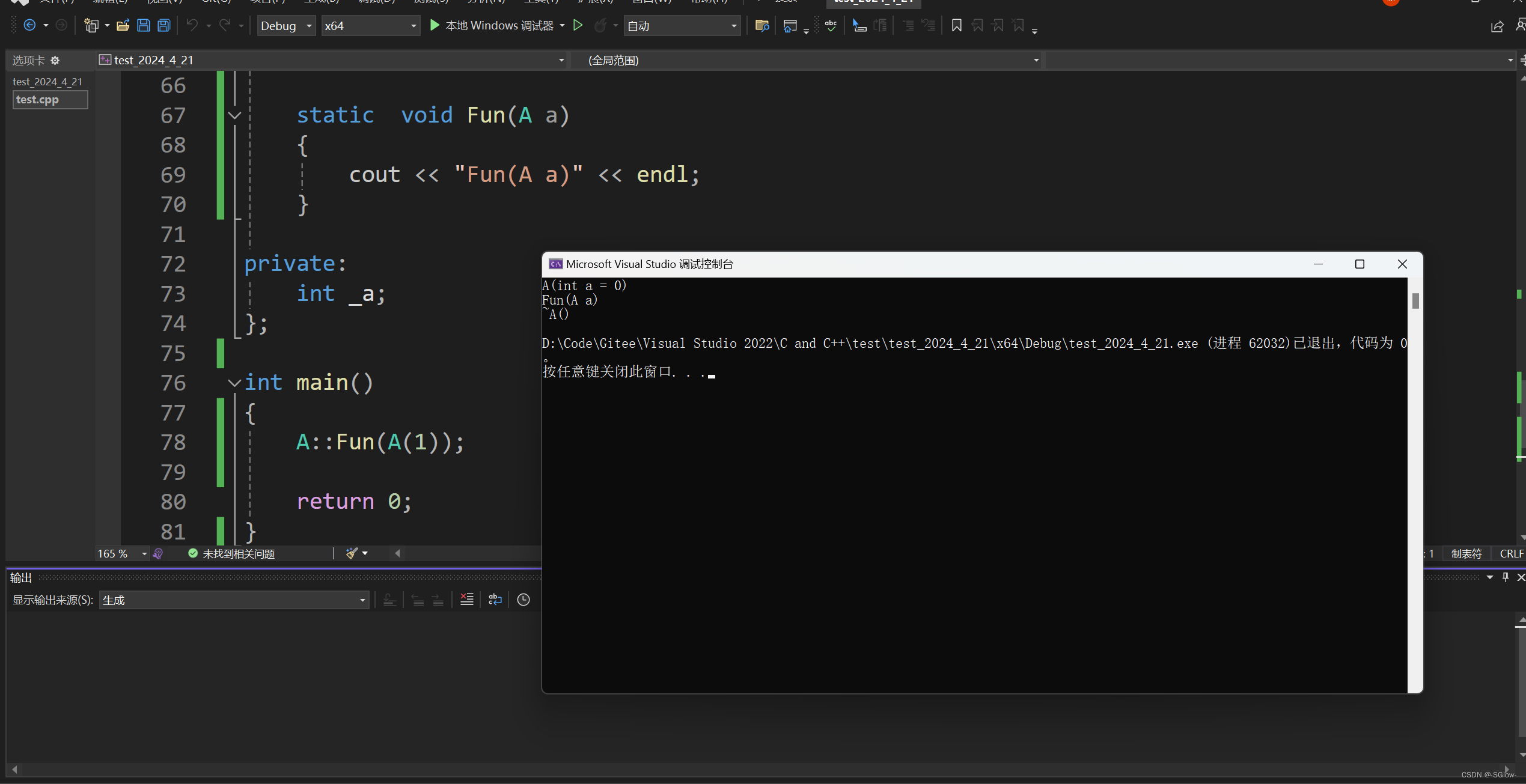
这里,本来的逻辑是1先去调用匿名对象的构造函数,完成匿名对象的初始化;然后匿名对象再去调用形参a的拷贝构造,完成a的初始化。
但是我们知道匿名对象是即用即扔的,它和临时对象没什么区别,都只在当前行有作用,因此这里依然是跳过构造匿名对象,直接将1作为参数去调用形参的构造函数。
借助这个优化,我们可以减少代码量
int main()
{A::Fun(A(1));//两种写法相同A::Fun(1);return 0;
}
一般来说采用后者的写法,毕竟要写的代码量更小,而且提高可读性。
d.函数返回值是自定义类型
#include <iostream>
using namespace std;class A
{public:A(int a = 0):_a(a){cout << "A(int a = 0)" << endl;}A(const A& a): _a(a._a){cout << "A(A& a)" << endl;}~A(){cout << "~A()" << endl;}static A Fun(){cout << "Fun(A a)" << endl;return A(2);}private:int _a;
};int main()
{A ret = A::Fun();return 0;
}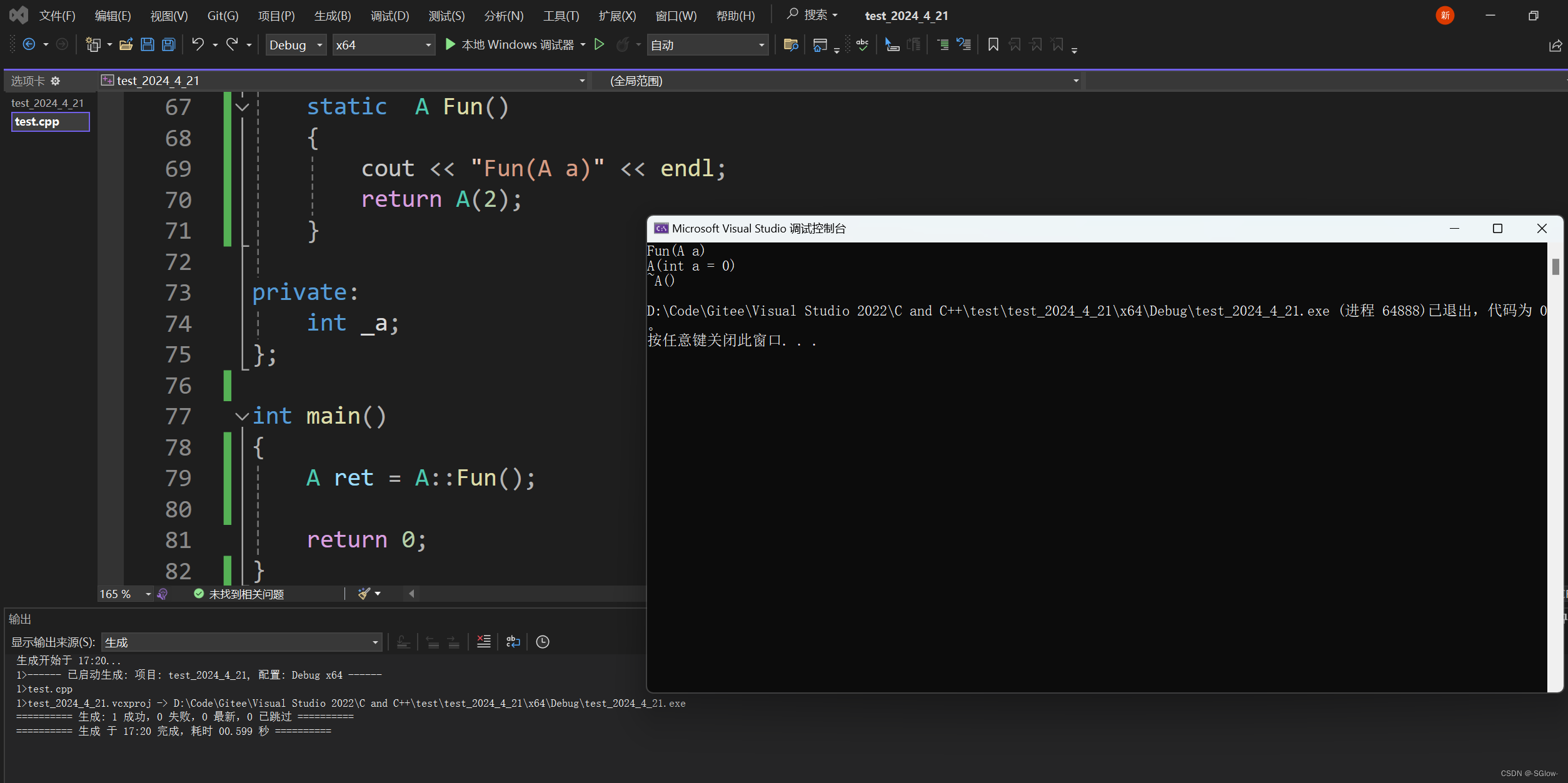 在调用完函数后,函数应该返回值并赋值。这里的逻辑应该是先将2作为参数去调用匿名对象的构造函数,然后将这个匿名对象拷贝构造给ret,使其初始化。
在调用完函数后,函数应该返回值并赋值。这里的逻辑应该是先将2作为参数去调用匿名对象的构造函数,然后将这个匿名对象拷贝构造给ret,使其初始化。
在优化后,我们直接将2作为参数去调用ret的构造函数。
但是,有的情况并不会优化,主要是看构造函数和拷贝构造有没有在一行代码中连续调用。
#include <iostream>
using namespace std;class A
{public:A(int a = 0):_a(a){cout << "A(int a = 0)" << endl;}A(const A& a): _a(a._a){cout << "A(A& a)" << endl;}~A(){cout << "~A()" << endl;}A& operator= (const A& tmp){cout << "A& operator= (const A& tmp)" << endl;_a = tmp._a;return *this;}static A Fun(){cout << "Fun(A a)" << endl;return A(2);}private:int _a;
};int main()
{A ret;ret = A::Fun();return 0;
}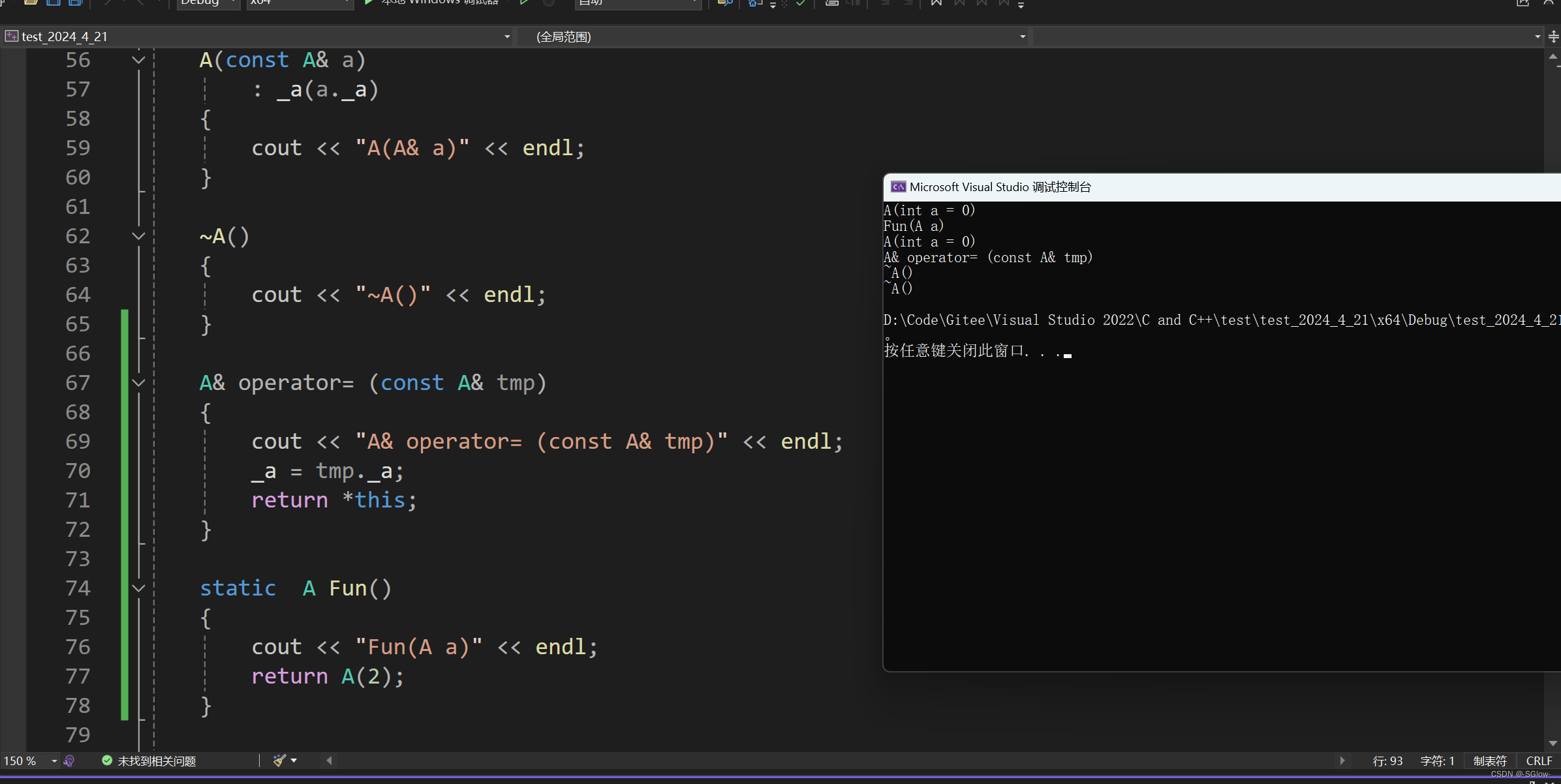
很明显,这里ret的初始化在调用函数前一行,会直接调用它的构造函数。之后进入函数,返回值需要再调用一次匿名对象的构造函数 ,之后调用的是赋值重载运算符。
在这里没有使用构造+拷贝构造,所以没有可优化的地方,一切执行逻辑和我们的推导逻辑一致。
3.构造和析构的顺序
(1)全局对象最先构造,在程序开始时就按顺序构造。
(2)局部static对象在第一次调用才构造,第二次就不构造了。
(3)普通的局部对象按顺序构造
(4)除了static修饰的局部对象以外,所有对象(局部、全局)先构造的后析构。
(5)static修饰的局部对象因为生命周期发生了改变,在所有局部对象都析构之后,在全局对象析构之前按“栈”的规则析构