前言:还没有整理,后续有时间再整理,目前只是个人思路,文章较乱。
注意路径匹配的“/”
我们的url里面加了“/”,但是用apifox等非浏览器的工具发起请求时没有加“/”,而且还不是get请求,那么这个请求就会被加上“/”且重定向成一个get请求。从而导致返回None且报错。
譬如现在有个视图类:
python">class BookView(APIView):def get(self, request):return Response("get success")def post(self, request):return Response("post success")
urls.py
python">urlpatterns = [path('admin/', admin.site.urls),path('book/', views.BookView.as_view())
]
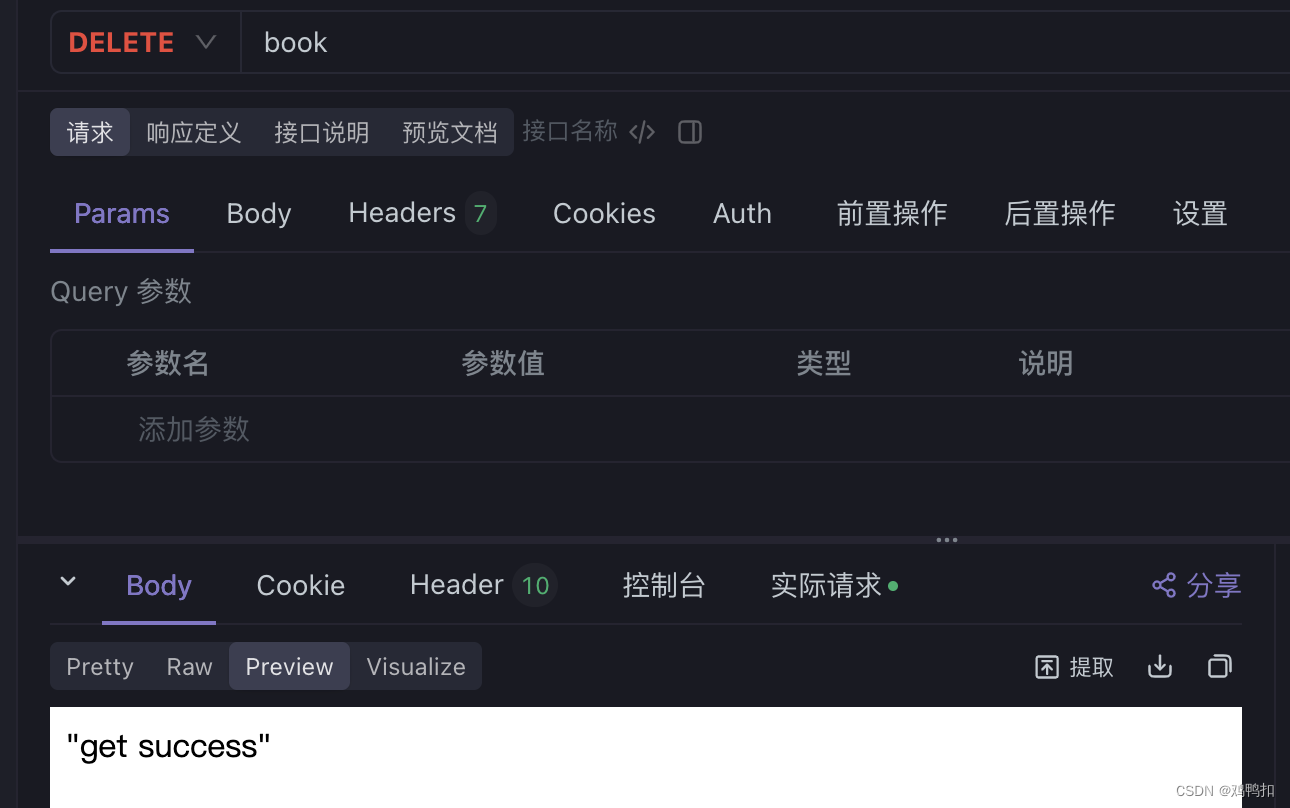
可以发现如果走DELETE方法,它结果返回的是get请求中的内容。
但是为什么发送POST请求的时候,它不会返回的是get请求中的内容,反而报错如下呢?
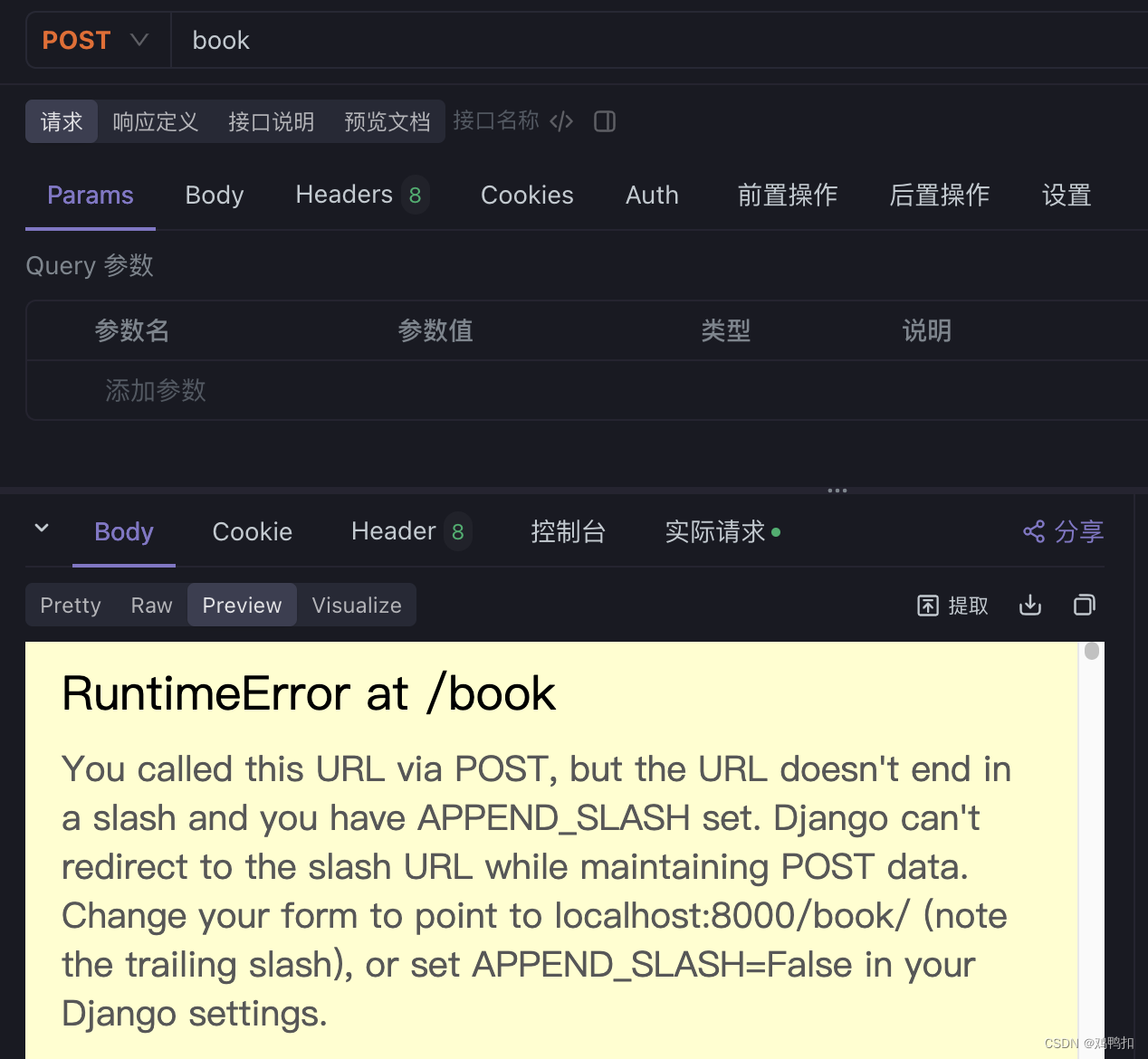
翻译为:你通过 POST 方法调用了这个 URL,但是 URL 没有以斜杠结尾,同时你的 APPEND_SLASH 设置为开启状态。Django 无法在保持 POST 数据的情况下重定向到带斜杠的 URL。请更改你的表单,使其指向 localhost:8000/book/(注意尾部的斜杠),或者在你的 Django 设置中将 APPEND_SLASH 设置为 False。
实际上这个重定向的设置和我们django的默认设置global_settings里面的APPEND_SLASH = True有关。
官方关于他的解释如下:
APPEND_SLASH
Default: TrueWhen set to True, if the request URL does not match any of the patterns in the URLconf and it doesn't end in a slash, an HTTP redirect is issued to the same URL with a slash appended. Note that the redirect may cause any data submitted in a POST request to be lost.The APPEND_SLASH setting is only used if CommonMiddleware is installed (see 中间件). See also PREPEND_WWW.
所以当请求是POST时不会像DELETE一样进行重定向,因为很有可能损失post里面携带的数据。
APIView源码解析:
当我们启动django框架时,django开始。
当我们匹配到相应路由时,先去BookView里面找as_view方法,发现没有找到,所以去BookView继承的APIView中找。
其中classmethod表示这是一个类方法,不是一个类实例化对象方法。
cls表示的是哪个类调用的这个方法,谁就是cls。
他和self不同的是self精确到了哪个类的实例化对象调用的这个方法,谁就是self。
所以这里的cls就是BookView
self就是BookView的一个实例化对象本身。
其中as_view最核心的代码如下:
python">class APIView(View):@classmethoddef as_view(cls, **initkwargs):view = super().as_view(**initkwargs)view.cls = clsreturn view
可以看到APIView的as_view()实际上走了其父类View的as_view(),结果也相当于父类as_view方法的结果。
所以我们把View的as_view()拿过来。
python">@classonlymethoddef as_view(cls, **initkwargs):def view(request, *args, **kwargs):self = cls(**initkwargs)return self.dispatch(request, *args, **kwargs)view.view_class = clsview.view_initkwargs = initkwargsreturn view
可以看到as_view的结果就是view这个方法。
也就是说:views.BookView.as_view()➡️View.as_view()➡️View.view
而且!view这个方法的第一件事,就是实例化一个对象。
现在是BookView这个实例化对象调用到了View层的view方法,然后self = cls(**initkwargs)创建了BookView的对象赋值给了self。然后再返回了
as_view 方法只是构建了 view 函数,并设置了必要的属性和注解,然后返回这个函数。
python"> def dispatch(self, request, *args, **kwargs):if request.method.lower() in self.http_method_names:handler = getattr(self, request.method.lower() )
意思就是views.BookView.as_view()➡️View.as_view()➡️View.view➡️View.view()➡️View.dispatch()➡️BookeView.get()
从而实现转发。
views.BookView.as_view()➡️View.as_view()➡️View.view➡️View.view()➡️APIView.dispatch()➡️BookeView.get()
从而实现转发。
python"> def dispatch(self, request, *args, **kwargs):# 构建一个新的request对象,不再是django原生的request。self.args = argsself.kwargs = kwargsrequest = self.initialize_request(request, *args, **kwargs)self.request = requesttry:# 认证、权限、限流等 self.initial(request, *args, **kwargs)if request.method.lower() in self.http_method_names:handler = getattr(self, request.method.lower(),self.http_method_not_allowed)else:handler = self.http_method_not_allowedresponse = handler(request, *args, **kwargs)except Exception as exc:response = self.handle_exception(exc)self.response = self.finalize_response(request, response, *args, **kwargs)return self.response
为什么APIView需要构建一个新的request对象?因为django原生的request对于解析POST请求的数据很有局限性,例如前端发送的数据有多种格式时,譬如有urlencoded和json格式时,django原生的request.POST只能解析并携带urlencoded格式的数据。而DRF.html" title=drf>drf的request则不一样,它的request.body支持解析并携带各种格式的数据。而DRF.html" title=drf>drf的request的_request实际上就是django原生的request。
注意序列化器相关:
还是书本的那个视图。
当我post请求时,我需要先验证前端传来的数据,转化成模型对象插入到数据库中,然后我返回校验后的数据。
models.py
python">class Book(models.Model):title = models.CharField(max_length=32, verbose_name="书籍名称")price = models.IntegerField(verbose_name="价格")pub_date = models.DateField(verbose_name="出版日
serializers.py
python">
python">class BookView(APIView):def get(self, request):book_list = Book.objects.all()serializer = BookSerializer(instance=book_list, many=True)return Response(serializer.data)def post(self, request):serializer = BookSerializer(data=request.data)if serializer.is_valid():Book.objects.create(**serializer.validated_data)return Response(serializer.data)else:return Response(serializer.errors)
虽然从本质上,我的序列化器的代码和我的模型代码没有关联性,但是在代码逻辑上,这两者一定是强相关的。所以如果一个字段我在序列化器中要求他可以为非必需的字段,那么前端就有可能传空值过来。此时在模型代码中又没有把对应的字段设置为null=True,那么就会导致存储到数据库时报错如下:
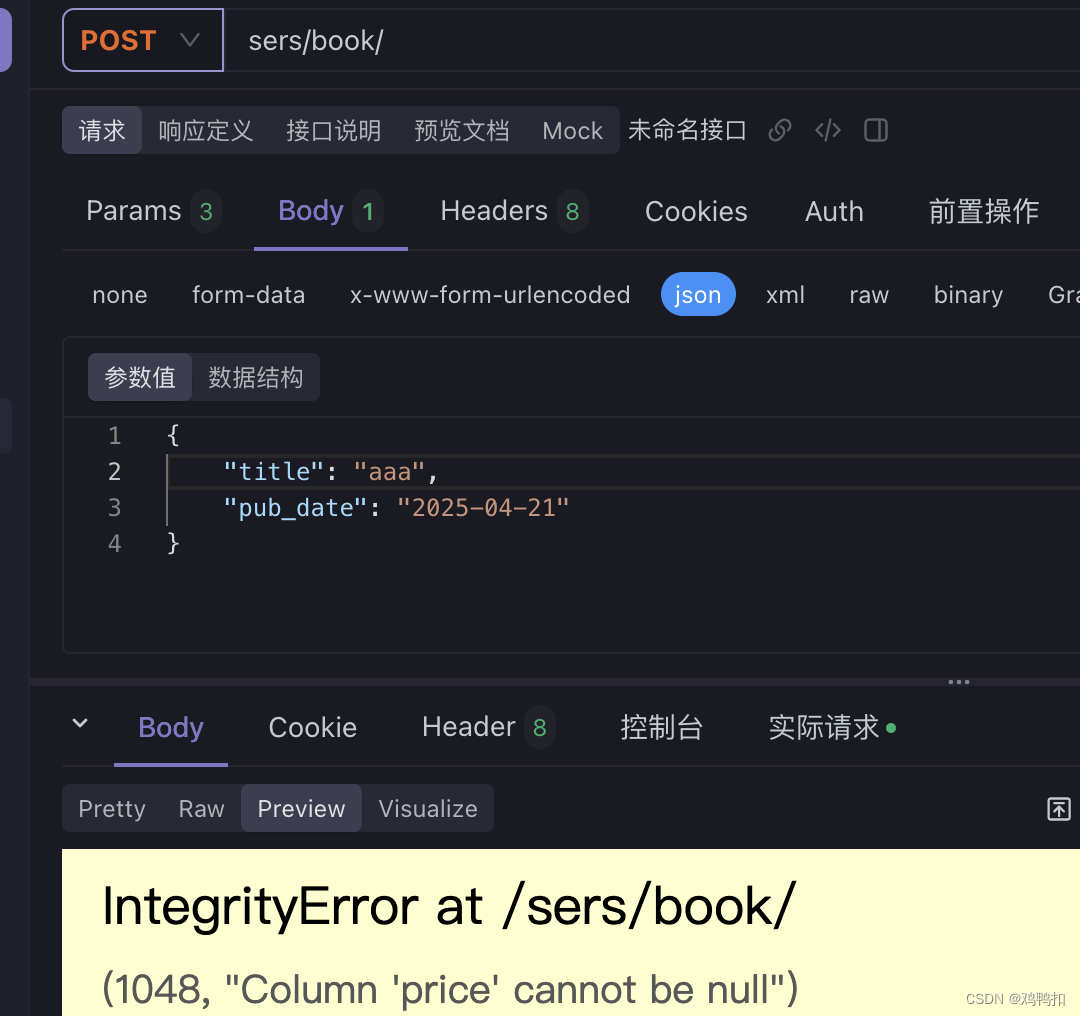
所以一般序列化器中设置为required=False的字段在模型中也都是null=True,反之也是。
所以这里代码要加上null=True
注意还要先运行数据库迁移的migrate等操作,才能再次启动服务器发请求。
如上代码还是有一定问题的,就是在视图函数中其实只应该做数据校验、返回响应之类的操作,数据库里新增数据等orm操作应该解耦出去,不应该绑定在数据校验的if else分支里面。所以序列化器中定义了一个叫save1的方法。
python"> def post(self, request):serializer = BookSerializer(data=request.data)if serializer.is_valid():# Book.objects.create(**serializer.validated_data)serializer.save()return Response(serializer.data)else:return Response(serializer.errors)
serialize.save()首先去找的是BookSerializer中是否有save方法,发现没有。于是去serializers.Serializer里面找,发现也没有,于是去BaseSerializer中找,然后发现找到了。
python">class BaseSerializer(Field):def save(self, **kwargs):validated_data = {**self.validated_data, **kwargs}if self.instance is not None:self.instance = self.update(self.instance, validated_data)assert self.instance is not None, ('`update()` did not return an object instance.')else:self.instance = self.create(validated_data)assert self.instance is not None, ('`create()` did not return an object instance.')return self.instance
在这里发现做了个判断instance属性是否为空。
因为我们在视图函数中创建serializer对象时用的是serializer = BookSerializer(data=request.data),注入的是data属性不是instance属性,所以这里肯定走if为空的判断,然后发现调用了create方法。
那么首先肯定还是看BookSerializer中是否有create方法,发现没有。于是去serializers.Serializer里面找,发现也没有,于是去BaseSerializer中找,然后发现找到了。
python"> def create(self, validated_data):raise NotImplementedError('`create()` must be implemented.')
也就是说其实我们的BookSerializer应该重写这个方法,不重写的话,现在请求会报错说create() must be implemented.
于是我们重写,而且应该返回数据,从而实现解耦。
python"> def create(self, validated_data):return Book.objects.create(**validated_data)
或者
python"> def create(self, validated_data):return Book.objects.create(**self.validated_data)
且虽然是一个资源,但建议路径中有参数的化为一个单独的视图类。譬如BookView和BookDetailView。
python">class BookView(APIView):def get(self, request):book_list = Book.objects.all()serializer = BookSerializer(instance=book_list, many=True)return Response(serializer.data)def put(self, request, id):book = Book.objects.get(pk=id)serializer = BookSerializer(instance=book, data=request.data)if serializer.is_valid():Book.objects.filter(pk=id).update(**serializer.validated_data)return Response(serializer.data)
现在来看一下serializer.data。
python"> @propertydef data(self):ret = super().datareturn ReturnDict(ret, serializer=self)
可以看到实际上这是一个data方法。
其父类的data方法为:
python">@propertydef data(self):if not hasattr(self, '_data'):if self.instance is not None and not getattr(self, '_errors', None):self._data = self.to_representation(self.instance)elif hasattr(self, '_validated_data') and not getattr(self, '_errors', None):self._data = self.to_representation(self.validated_data)else:self._data = self.get_initial()return self._data
这几个判断,第一个判断的意思是如果instance属性不为空且_errors属性为空。那么_data属性就是instance属性数据序列化后的内容。
也就是说每次我们序列化返回响应时,实际上就在返回序列化后的instance属性数据。
那么关于普通的get、post、delete方法,都没什么毛病。但是对于更新put方法。因为我们创建serializer时用的是:
python">serializer = BookSerializer(instance=book, data=request.data)
按理来说返回的响应内容应该是更新后的数据,
但实际上返回的是更新前的数据,虽然更新操作做了,但是响应不是我们想要的。所以我们应该写成如下:
python"> if serializer.is_valid():Book.objects.filter(pk=id).update(**serializer.validated_data)updated_book = Book.objects.get(pk=id)serializer.instance = updated_bookreturn Response(serializer.data)
手动指定下instance为更新后的数据。
这里不写成
python"> updated_book = Book.objects.filter(pk=id).update(**serializer.validated_data)serializer.instance = updated_bookreturn Response(serializer.data)
是因为update方法返回的数据不是updated_book,而是修改了多少条记录的一个int值。
那么关于post方法,明明创建serializer时没有给她的instance属性赋值,那么为什么最终还是可以正常返回data?
那是因为在save()方法里面
python"> def save(self, **kwargs):validated_data = {**self.validated_data, **kwargs}if self.instance is not None:self.instance = self.update(self.instance, validated_data)assert self.instance is not None, ('`update()` did not return an object instance.')else:self.instance = self.create(validated_data)assert self.instance is not None, ('`create()` did not return an object instance.')return self.instance
其中最关键的是self.instance = self.create(validated_data)
也就是说create方法返回的值赋值给了instance。
当然,为了解耦,我们实际上还是要把更新数据的逻辑暴露出去的。
python">class BookSerializer(serializers.Serializer):title = serializers.CharField(max_length=32)price = serializers.IntegerField(required=False)pub_date = serializers.DateField()def create(self, validated_data):return Book.objects.create(**validated_data)def update(self, instance, validated_data):Book.objects.filter(pk=instance.pk).update(**validated_data)updated_book = Book.objects.get(pk=instance.pk)return updated_book
python"> def put(self, request, id):book = Book.objects.get(pk=id)serializer = BookSerializer(instance=book, data=request.data)if serializer.is_valid():serializer.save()return Response(serializer.data)
序列化器可以升级为modelSerializer
此时不仅代码逻辑上强相关,代码语法上也完全强相关了。
python">class BookSerializer(serializers.ModelSerializer):date = serializers.DateField(source="pub_date")class Meta:model = Bookexclude = ['pub_date']
如果此时新增一个资源,完成相应视图。可以发现每个视图的方法涉及到的变量就是模型和序列化器。
所以GenericAPIView出现了。
python">class BookView(GenericAPIView):serializer_class = BookSerializerqueryset = Book.objects.all()def get(self, reverse, *args, **kwargs):serializer = self.get_serializer(instance=self.get_queryset(), many=True)return Response(serializer.data)
python">class GenericAPIView(views.APIView):queryset = Noneserializer_class = Nonelookup_field = 'pk'lookup_url_kwarg = Nonedef get_queryset(self):assert self.queryset is not None, ("'%s' should either include a `queryset` attribute, ""or override the `get_queryset()` method."% self.__class__.__name__)queryset = self.querysetif isinstance(queryset, QuerySet):queryset = queryset.all()return querysetdef get_serializer(self, *args, **kwargs):serializer_class = self.get_serializer_class()kwargs.setdefault('context', self.get_serializer_context())return serializer_class(*args, **kwargs)def get_object(self):queryset = self.filter_queryset(self.get_queryset())filter_kwargs = {self.lookup_field: self.kwargs[lookup_url_kwarg]}obj = get_object_or_404(queryset, **filter_kwargs)# May raise a permission deniedself.check_object_permissions(self.request, obj)return objdef get_serializer_class(self):assert self.serializer_class is not None, ("'%s' should either include a `serializer_class` attribute, ""or override the `get_serializer_class()` method."% self.__class__.__name__)return self.serializer_class
可以看到其实
python"> def get(self, reverse, *args, **kwargs):# serializer = self.get_serializer(instance=self.get_queryset(), many=True)serializer = self.get_serializer_class()(instance=self.get_queryset(), many=True)return Response(serializer.data)
是一样的。
现在来仔细看下get_object()方法:
python">def get_object(self):queryset = self.filter_queryset(self.get_queryset())filter_kwargs = {self.lookup_field: self.kwargs[lookup_url_kwarg]}obj = get_object_or_404(queryset, **filter_kwargs)# May raise a permission deniedself.check_object_permissions(self.request, obj)return obj
这里filter_kwargs取决于lookup_field是什么。
点进去发现默认为lookup_field = ‘pk’
这就意味着我们的url需要改为
python">path('sers/book/<int:pk>/', views.BookDetailView.as_view())
否则报错。如果我们坚持想要用id
那么就需要:
python">class BookDetailView(GenericAPIView):serializer_class = BookSerializerqueryset = Book.objects.all()lookup_field = 'id'def get(self, request, id):serializer = self.get_serializer(instance=self.get_object(), many=False)return Response(serializer.data)
python"> path('sers/book/<int:id>/', views.BookDetailView.as_view())
此时视图类中的各个方法的代码就固定了。DRF再封装了一层,将各个固定的处理对应请求的逻辑分别封装到五个Mixin类中。
我们的视图函数只要利用多继承同时继承GenericAPIView和对应的MIxin就好了。如下:
python">class BookView(GenericAPIView, ListModelMixin, CreateModelMixin):serializer_class = BookSerializerqueryset = Book.objects.all()def get(self, request):return self.list(request)def post(self, request):return self.create(request)class BookDetailView(GenericAPIView, ListModelMixin, RetrieveModelMixin, UpdateModelMixin, DestroyModelMixin):serializer_class = BookSerializerqueryset = Book.objects.all()lookup_field = 'id'def get(self, request, id):return self.retrieve(request, id)def put(self, request, id):return self.update(request, id)def delete(self, request, id):return self.destroy(request, id)
随便查看一个Mixin类,譬如这里查看全部对应的ListModelMixin类,可以看到其逻辑和我们原来写的Get方法的逻辑几乎一致。
python">class ListModelMixin:"""List a queryset."""def list(self, request, *args, **kwargs):queryset = self.filter_queryset(self.get_queryset())page = self.paginate_queryset(queryset)if page is not None:serializer = self.get_serializer(page, many=True)return self.get_paginated_response(serializer.data)serializer = self.get_serializer(queryset, many=True)return Response(serializer.data)
注意此时各个方法的代码也固定了。所以DRF又做了一层封装。将GenericAPIView, ListModelMixin, CreateModelMixin和对应的
python">def get(self, request):return self.list(request)def post(self, request):return self.create(request)
封装到了一起,成为ListCreateAPIView
同理GenericAPIView, ListModelMixin, RetrieveModelMixin, UpdateModelMixin, DestroyModelMixin和对应的
python">def get(self, request, id):return self.retrieve(request, id)def put(self, request, id):return self.update(request, id)def delete(self, request, id):return self.destroy(request, id)
也封装到了一起,叫RetrieveUpdateDestroyAPIView。
所以最后整个视图代码如下:
python">class BookView(ListCreateAPIView):serializer_class = BookSerializerqueryset = Book.objects.all()class BookDetailView(RetrieveUpdateDestroyAPIView):serializer_class = BookSerializerqueryset = Book.objects.all()lookup_field = 'id'
那么有些时候我只需要GenericAPIView, ListModelMixin, RetrieveModelMixin, UpdateModelMixin和对应方法的组合怎么办?也有对应封装的MixinAPIView类。
现在以上的代码已经很简洁很好了,唯一一点不足就是,分发机制不够好,导致必须有两个url,两个针对同一资源的视图类。而且请求方法固定了,一定要是get、post、put、delete等。此时ViewSet出现了。
我们重新写一下视图类代码,就拿最典型的获取所有资源和单一资源为例:
python">class BookView(ViewSet):def get_all(self, request):return Response("查看所有资源")def get_one(self, request, pk):return Response("查看单一资源")
python"> path('sers/book/', views.BookView.as_view({"get": "get_all"})),path('sers/book/<int:pk>/', views.BookView.as_view({"get": "get_one"})),
可以看ViewSet的源码:
python">class ViewSet(ViewSetMixin, views.APIView):"""The base ViewSet class does not provide any actions by default."""passclass ViewSetMixin:"""This is the magic.Overrides `.as_view()` so that it takes an `actions` keyword that performsthe binding of HTTP methods to actions on the Resource.For example, to create a concrete view binding the 'GET' and 'POST' methodsto the 'list' and 'create' actions...view = MyViewSet.as_view({'get': 'list', 'post': 'create'})"""@classonlymethoddef as_view(cls, actions=None, **initkwargs):# actions must not be emptyif not actions:raise TypeError("The `actions` argument must be provided when ""calling `.as_view()` on a ViewSet. For example ""`.as_view({'get': 'list'})`")# sanitize keyword argumentsfor key in initkwargs:if key in cls.http_method_names:raise TypeError("You tried to pass in the %s method name as a ""keyword argument to %s(). Don't do that."% (key, cls.__name__))if not hasattr(cls, key):raise TypeError("%s() received an invalid keyword %r" % (cls.__name__, key))# name and suffix are mutually exclusiveif 'name' in initkwargs and 'suffix' in initkwargs:raise TypeError("%s() received both `name` and `suffix`, which are ""mutually exclusive arguments." % (cls.__name__))def view(request, *args, **kwargs):self = cls(**initkwargs)if 'get' in actions and 'head' not in actions:actions['head'] = actions['get']# We also store the mapping of request methods to actions,# so that we can later set the action attribute.# eg. `self.action = 'list'` on an incoming GET request.self.action_map = actions# Bind methods to actions# This is the bit that's different to a standard viewfor method, action in actions.items():handler = getattr(self, action)setattr(self, method, handler)self.request = requestself.args = argsself.kwargs = kwargs# And continue as usualreturn self.dispatch(request, *args, **kwargs)# take name and docstring from classupdate_wrapper(view, cls, updated=())# and possible attributes set by decorators# like csrf_exempt from dispatchupdate_wrapper(view, cls.dispatch, assigned=())# We need to set these on the view function, so that breadcrumb# generation can pick out these bits of information from a# resolved URL.view.cls = clsview.initkwargs = initkwargsview.actions = actionsreturn csrf_exempt(view)
最核心的代码就是:
python"> # Bind methods to actions# This is the bit that's different to a standard viewfor method, action in actions.items():handler = getattr(self, action)setattr(self, method, handler)
相当于写了个拦截器,把方法get对应的函数变量从get()换为了urls中“get”对应的值的实例化变量,这里就是get_all()或者get_one()
意味着后续用getattr(self,method)时拿到的不是get()而是get_all()或者get_one()
也就是说ViewSet其实没有重写dispatch,而是在前面多加了个拦截器。
但是此时问题又来了,这个ViewSet没有之前Mixin和GenericAPIView的功能了。
所以GenericViewSet出现了。代码如下:
python">class BookView(GenericViewSet, ListModelMixin, CreateModelMixin, RetrieveModelMixin, UpdateModelMixin, DestroyModelMixin):serializer_class = BookSerializerqueryset = Book.objects.all()urls.py
python"> path('sers/book/', views.BookView.as_view({"get": "list", "post": "create"})),path('sers/book/<int:pk>/', views.BookView.as_view({"get": "retrieve", "put": "update", "delete": "destroy"})),
此时还有个封装:
python">GenericViewSet, ListModelMixin, CreateModelMixin, RetrieveModelMixin, UpdateModelMixin, DestroyModelMixin
都封装成一个ModelViewSet。
python">class BookView(ModelViewSet):serializer_class = BookSerializerqueryset = Book.objects.all()
然后还发现存在最后一个问题,就是ModelViewSet对应的路由还是很长很复杂,而且很固定。
此时路由组件router出现了。
python">router = routers.DefaultRouter()
router.register("sers/book", views.BookView)urlpatterns = [path('admin/', admin.site.urls),
]urlpatterns += router.urls至此,DRF.html" title=drf>drf视图相关的演化完毕。