目录
日志是什么
日志的作用
日志的使用
SLF4J
门面模式
打印日志
日志格式
日志级别
日志配置
配置日志级别
日志持久化
日志输出的简单方式
日志是什么
日志: 在生活中,日志是指记录生活中的点滴,而在这里,日志指的是 软件、系统或设备中记录事件、操作或状态的记录
在我们刚开始学习Java 时,我们就在使用 System.out.println() 来打印日志了,通过打印日志,我们可以发现问题和定位问题,从而解决问题,而在Spring中,也经常根据控制台的日志来分析和定位问题
日志的作用
(1)故障排查与调试:日志记录了系统运行过程中的各种事件、错误和异常情况,有助于我们定位和解决 bug 和故障。通过分析日志,可以更快速地找出问题的根源,并进行修复
(2)性能监控与优化:日志可以记录系统的性能指标、请求响应时间、资源利用率等信息,帮助系统管理员和开发人员监控系统的性能表现。通过分析日志,可以及时发现系统的性能瓶颈,并进行优化改进,提升系统的性能和稳定性
(3)安全审计与监控:日志记录了系统的各种操作和事件,包括用户登录、权限变更、安全事件等,有助于系统管理员进行安全审计和监控。通过分析日志,可以及时发现系统的安全风险和异常行为,并采取相应的措施进行防范和应对
(4)业务分析与决策支持:日志可以记录用户行为、业务流程、交易记录等信息,帮助业务分析师和决策者了解用户需求、业务趋势和市场动态。通过分析日志,可以为企业制定合适的业务策略和决策提供数据支持。
(5)法律合规与证据保全:日志可以作为法律合规的证据,记录系统操作和事件的完整过程,有助于企业应对法律诉讼和审计检查。通过合理规范的日志记录,可以保证系统操作的合法合规性,并为企业提供法律保障。
日志的使用
SpringBoot项目在启动时默认就会有日志输出:

我们通过 System.out.println 打印日志:
java">import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;@RestController
public class LoggerController {@RequestMapping("/logger")public String logger(){System.out.println("打印日志");return "打印日志";}
}运行结果:

我们可以发现,SpringBoot打印的日志比我们通过 System.out.println 打印的日志多了很多信息
SpringBoot内置了日志框架 slf4j,我们可以直接在程序中调用 slf4j 来输出日志
SLF4J
SLF4J(Simple Logging Facade for Java): 是一个为 Java 应用程序提供简单日志门面的库。它允许应用程序通过统一的 API 记录日志,而不受底层日志实现的影响。SLF4J 提供了一种简单的方式来在应用程序中使用日志记录,同时允许开发人员在部署时选择合适的日志框架作为底层实现,如 Logback、Log4j、java.util.logging 等。

SLF4J 不是一个真正的日志实现,而是一个抽象层,因此,SLF4J不能独立使用,需要和具体的日志框架配合使用
SLF4J是其他日志框架的门面,什么是门面?接下来,我们来了解一下门面模式
门面模式
门面模式(Facade Pattern):又称为外观模式,是一种结构型设计模式,旨在为复杂系统提供简化的接口。该模式通过创建一个简单的接口来隐藏系统的复杂性,使得客户端可以更容易地与系统交互,而不必了解系统内部的复杂结构和实现细节。
在门面模式中,通常有一个称为“门面”的类,它提供了一个简单的接口,客户端可以通过这个接口与系统进行交互。门面类将客户端的请求委派给系统内部的各个子系统,客户端无需直接与子系统交互,而是通过门面类来进行操作。

门面模式主要包含两个角色:
门面角色:也称为外观角色,是系统对外的统一接口
子系统角色:子系统指的是组成整个系统的各个模块或组件。这些子系统可能是相互独立的模块,也可能是紧密相关的组件,子系统的具体实现对客户端是透明的,客户端只需要通过门面系统与子系统进行交互,而不需要了解子系统的内部实现细节
子系统是组成整个系统的各个模块或组件,而门面类则充当了客户端与子系统之间的接口。
门面模式的优点:
1. 简化接口: 门面模式提供了一个简单的接口给客户端使用,隐藏了系统的复杂性。客户端只需要与门面类交互,而不需要了解系统内部的复杂结构和实现细节。
2. 降低耦合度: 门面模式将客户端与子系统之间的依赖关系解耦,客户端只依赖于门面类而不依赖于子系统的具体实现。这样,当子系统发生变化时,不会影响到客户端的代码,提高了系统的灵活性和可维护性。
3. 提高可复用性: 门面模式将系统的复杂功能封装在一个门面类中,使得这些功能可以被多个客户端共享和复用。这样,可以避免代码重复,提高了代码的可复用性。
4. 隐藏实现细节: 门面模式隐藏了系统的内部实现细节,客户端只需要关心所需功能的调用,而不需要了解功能是如何实现的。这样可以减少客户端与系统之间的交互,降低了系统的复杂度。
5. 提高安全性: 通过门面模式,可以控制客户端对系统的访问权限,只暴露必要的接口给客户端使用,从而提高了系统的安全性。
6. 易于维护: 由于门面模式将系统的复杂性封装在一个门面类中,使得系统的维护变得更加容易。当系统发生变化时,只需要修改门面类的实现,而不需要修改客户端的代码。
当未引入日志门面时:
若一个项目依赖log4j,需要将其加载到项目中,
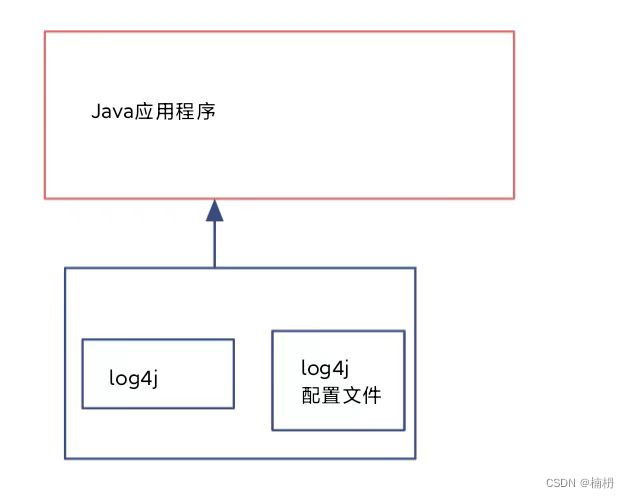
而当依赖的另一个类库,其依赖于另一个日志框架 logback,此时,需要将 logback 也加载进去

不同日志框架的API接口和配置文件不同,若多个日志框架共存,则必须要维护多套配置文件
而当要更换日志框架时,应用程序则不得不修改代码,在修改过程中可能会存在一些代码冲突
若引入了多套三方框架,就不得不维护多套配置
而当引入了日志门面后:

此时 ,应用程序和日志框架之间有了统一的API接口(门面日志框架实现),应用程序只需要维护一套日志文件配置,当底层实现框架发生改变时,不需要更改应用程序代码
SLF4J就是其他日志框架的门面,使代码独立于任意一个特定的日志API
打印日志
打印日志:
1. 在程序中得到日志对象
2. 使用日志对象输出要打印的内容
得到日志对象:
使用 日志工厂 LoggerFactory 来获取日志对象:
java">import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.web.bind.annotation.RestController;@RestController
public class LoggerController {private static Logger logger = LoggerFactory.getLogger(LoggerController.class);
}注意:在创建Logger对象时导入 org.slf4j 对应的包,不要导错包
使用日志对象打印内容:
java">import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;@RestController
public class LoggerController {private static Logger logger = LoggerFactory.getLogger(LoggerController.class);@RequestMapping("/logger")public String logger(){logger.info("--------打印日志----------");return "打印日志";}
}运行结果:

我们可以看到 SpringBoot 打印的日志有许多内容,这些分别代表着什么呢?
日志格式
日志输出内容元素从左到右分别为:
时间日期(精确到毫秒)
日志级别(包括 ERROR、WARN、INFO、DEBUT及TRACE)
进程ID
线程名
Logger名(通常使用源代码的类名)
日志内容
日志级别
日志级别代表着日志信息对应问题的严重性,能够更快的筛选符合目标的日志信息
日志的级别从高到低依次为: FATAL、ERROR、WARN、INFO、DEBUT、TRACE
FATAL:致命信息,表示需要立即被处理的系统级错误
ERROR:错误信息,级别较高的错误日志信息,但仍然不影响系统的继续运行
WARN:警告信息,不影响使用,但需要注意的问题
INFO:普通信息,用于记录应用程序正常运行时的一些信息,如系统启动完成,请求处理完成等
DEBUG:调试信息,需要调试时的关键信息打印
TRACE:追踪信息,比DEBUG更细粒度的信息事件
日志级别的顺序:

级别越高,收到的消息越少
日志级别是开发人员设置的,用来给开发人员看的,开发人员根据自己的理解来判断该信息的重要程度,若将ERROR级别的日志设置成INFO,很有可能会影响开发人员对项目运行情况的判断,当出现较多ERROR级别的日志信息时,也可能没有任何问题,测试的BUG级别更多的是依据现象和影响范围来判断
针对不同级别的日志,Logger对象提供了对应的方法来输出日志:
java"> @RequestMapping("/logger")public String logger(){logger.trace("--------trace----------");logger.debug("--------debug----------");logger.info("--------info----------");logger.warn("--------warn----------");logger.error("--------error----------");return "打印不同级别的日志";}SpringBoot默认的日志框架是 logback,logback没有 FATAL级别,它被映射到 ERROR
当出现FATAL级别的日志时,说明服务已经出现了某种程度的不可用,需要联系系统管理员紧急介入处理,通常情况下,一个经常的生命周期中应该最多只有一次FATAL记录
运行结果:

我们可以看到,只打印了INFO、WARN 和 ERROR 级别的日志
这与日志级别的配置有关,日志的输出级别默认是 INFO,因此只会打印大于此级别的日志
要想打印DEBUG 和 TRACE级别的日志,可以通过在配置文件中进行设置
因此,接下来我们学习日志配置
日志配置
配置日志级别
日志级别配置只需要在配置文件中设置 logging.level 配置项即可:
若使用 .properties:
logging.level.root: debug
若使用 .yml:
logging:level:root: debug
重新运行,观察结果:
 此时,就能够打印出 debug 级别的日志,若想要打印出 trace 级别的日志,只需要将上述配置文件中的 debug 修改为 trace
此时,就能够打印出 debug 级别的日志,若想要打印出 trace 级别的日志,只需要将上述配置文件中的 debug 修改为 trace
上述日志都是输出在控制台上的,若我们想要将日志保存下来,以便出现问题后追溯问题,该如何实现呢?
日志持久化
将日志保存下来就叫做日志的持久化
日志持久化有两种方式:
1. 配置日志文件名
2. 配置日志的存储目录
配置日志文件的路径和文件名:
properties:
logging.file.name: logger/springboot.log
yml:
logging:file:name: logger/springboot.log
路径可以是绝对路径也可以是相对路径
再次运行,可以看到日志内容保存在了对应的目录下:

配置日志文件的保存路径:
properties:
logging.file.path:logger
yml:
logging:file:path: logger
再次运行程序,可以看到对应目录下:

通过这种方式只能设置日志的路径,其文件名为固定的 spring.log
当 logging.file.name 和 logging.file.path两个都配置的情况下,会怎样呢?
我们来测试一下:

删掉原有的日志文件,再次运行:

可以看到,当logging.file.name 和 logging.file.path都配置时,以 logging.file.name 为准
更多的内容,可参考:Chapter 6: Layouts (qos.ch)
日志输出的简单方式
我们每次都需要在程序中得到日志对象
lombok为我们提供了一种更简单的方式
我们只需要:
1. 添加 lombok 框架支持
2. 使用 @Slf4j 注入输出日志
添加 lombok 依赖
<dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional> </dependency>
输出日志:
java">@Slf4j
@RestController
public class LogController {@RequestMapping("/log")public void log(){log.info("--------info----------");}
}lombok提供的@Slf4j 会帮我们提供一个日志对象 log,我们可以直接使用