一、环境准备
1.1:在ubuntu上安装idea
我们知道,在hdfs分布式系统中,MapReduce这部分程序是需要用户自己开发,我们在ubuntu上安装idea也是为了开发wordcount所需的Map和Reduce程序,最后打包,上传到hdfs上。
在ubuntu上安装idea的教程我参考的是这篇Ubuntu 中安装 IDEA
1.2:下载maven
maven是什么?- maven是一个项目构建和管理的工具,提供了帮助管理 构建、文档、报告、依赖、scms、发布、分发的方法。
Maven的安装和配置参考这篇Ubuntu20.04下配置Maven+IDEA配置
二、MapReduce的实现
2.1:在IDEA中配置Maven
🆘注意:确保你是在IDEA的欢迎界面进行配置,这一步很重要,决定了你的配置是不是全局的,如果你在项目中的话,请点击菜单的“文件”-"关闭项目"回到欢迎界面,一定要注意!!
步骤1—— 在欢迎界面打开设置
点击所有设置,或者直接用打开设置的快捷键 Ctrl + Alt + S
步骤2—— 找到maven配置项
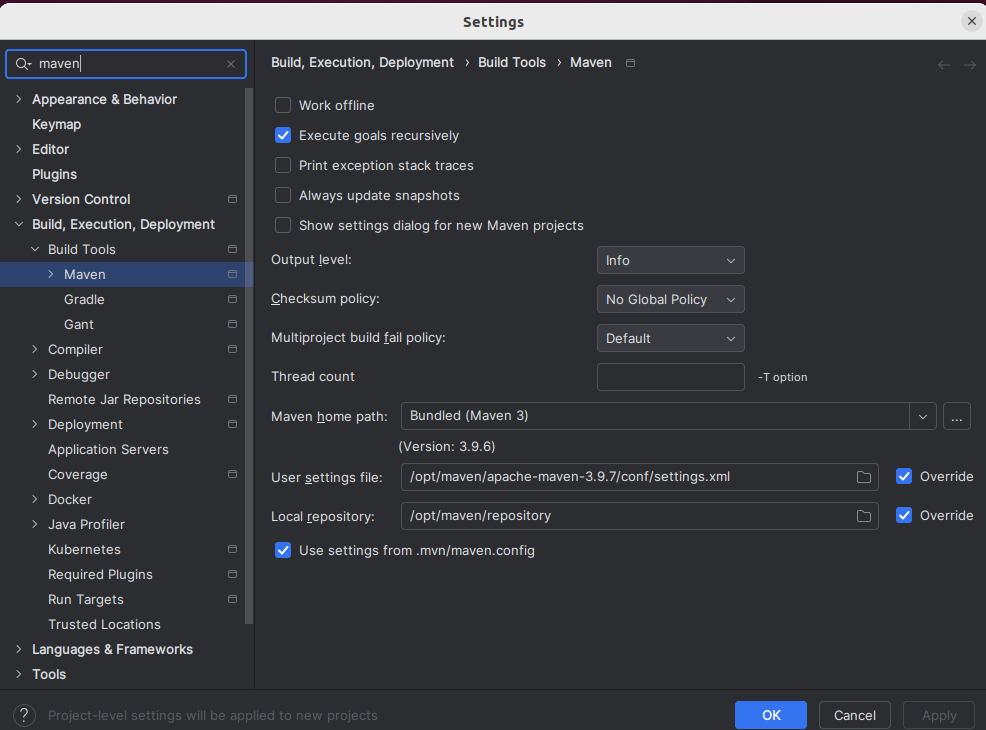
左上角搜索框搜索maven,回车,主要修改红色框内的几个配置

步骤3—— 修改maven配置
按照下图配置即可,maven的主路径指的就是maven的主文件夹,用户设置文件就是我们刚刚上面下载maven中配置的那个文件settings.xml,本地仓库就是我们自己新建的一个文件夹,所有从中央仓库下载的jar包会放在这里面,如果你按照我上面1.2的思路配置,那么这三个路径应该是这种:
Maven主路径:/opt/maven/apache-maven-3.9.7
用户设置文件:/opt/maven/apache-maven-3.9.7/conf/settings.xml
本地仓库:/opt/maven/repository(用来存储从远程仓库或中央仓库下载的插件和jar包,项目使用一些插件或jar包,优先从本地仓库查找)
🚨:注意,设置完后需要重启IDEA,设置才可生效
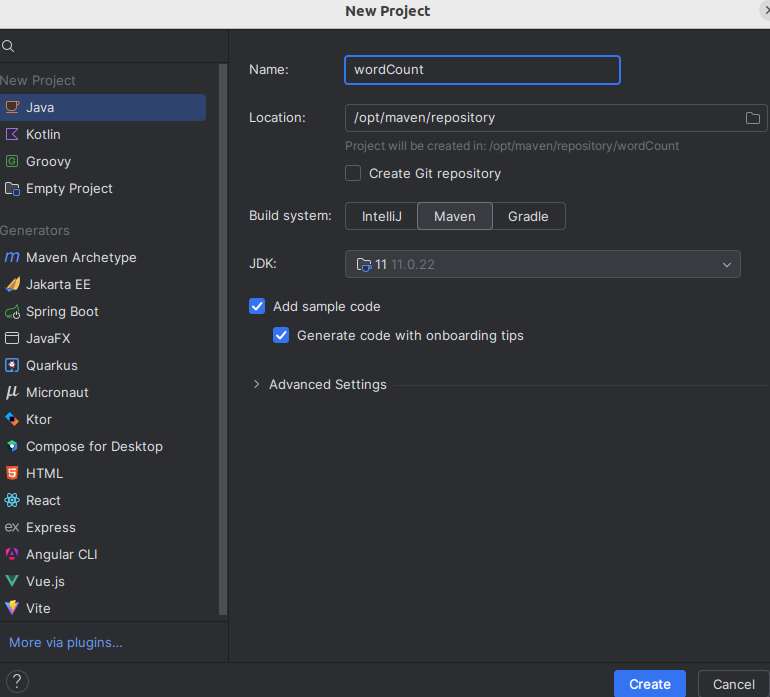
2.1:新建一个Maven空项目:wordCount
2.2:添加依赖
<dependencies><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>3.3.5</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>3.3.5</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-core</artifactId><version>3.3.5</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.3.5</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-jobclient</artifactId><version>3.3.5</version><scope>provided</scope></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-common</artifactId><version>3.3.5</version></dependency></dependencies>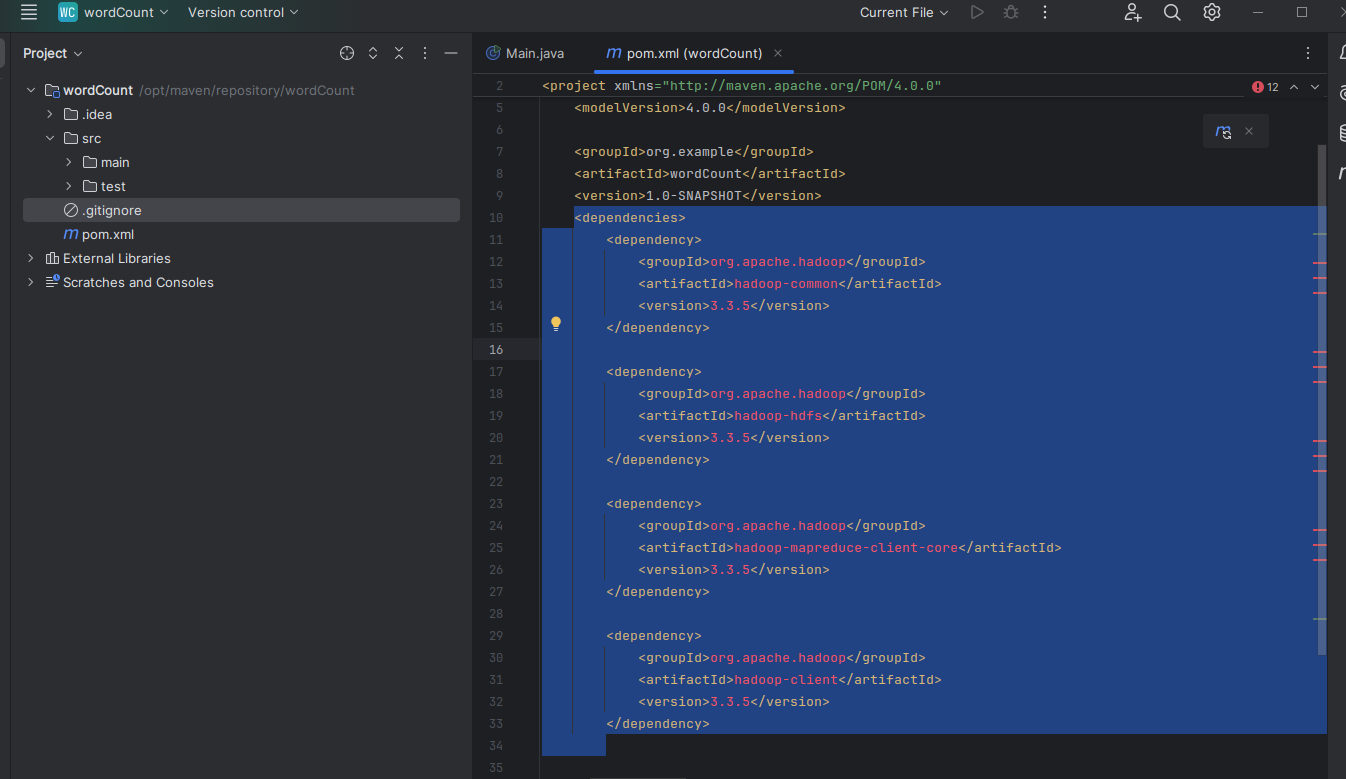
2.3:创建WordCount类
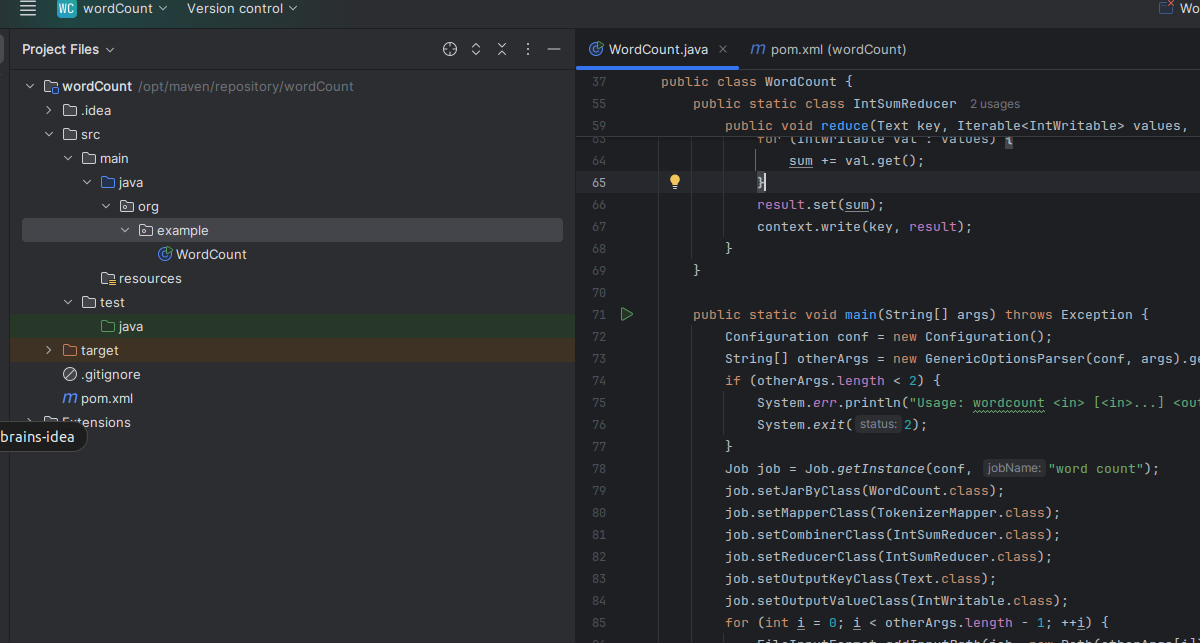
/*** Licensed to the Apache Software Foundation (ASF) under one* or more contributor license agreements. See the NOTICE file* distributed with this work for additional information* regarding copyright ownership. The ASF licenses this file* to you under the Apache License, Version 2.0 (the* "License"); you may not use this file except in compliance* with the License. You may obtain a copy of the License at** http://www.apache.org/licenses/LICENSE-2.0** Unless required by applicable law or agreed to in writing, software* distributed under the License is distributed on an "AS IS" BASIS,* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.* See the License for the specific language governing permissions and* limitations under the License.*/package org.example;import java.io.IOException;
import java.util.StringTokenizer;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;public class WordCount {public static class TokenizerMapperextends Mapper<Object, Text, Text, IntWritable>{private final static IntWritable one = new IntWritable(1);private Text word = new Text();public void map(Object key, Text value, Context context) throws IOException, InterruptedException {StringTokenizer itr = new StringTokenizer(value.toString());while (itr.hasMoreTokens()) {word.set(itr.nextToken());context.write(word, one);}}}public static class IntSumReducerextends Reducer<Text,IntWritable,Text,IntWritable> {private IntWritable result = new IntWritable();public void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {int sum = 0;for (IntWritable val : values) {sum += val.get();}result.set(sum);context.write(key, result);}}public static void main(String[] args) throws Exception {Configuration conf = new Configuration();String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();if (otherArgs.length < 2) {System.err.println("Usage: wordcount <in> [<in>...] <out>");System.exit(2);}Job job = Job.getInstance(conf, "word count");job.setJarByClass(WordCount.class);job.setMapperClass(TokenizerMapper.class);job.setCombinerClass(IntSumReducer.class);job.setReducerClass(IntSumReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);for (int i = 0; i < otherArgs.length - 1; ++i) {FileInputFormat.addInputPath(job, new Path(otherArgs[i]));}FileOutputFormat.setOutputPath(job,new Path(otherArgs[otherArgs.length - 1]));System.exit(job.waitForCompletion(true) ? 0 : 1);}
}
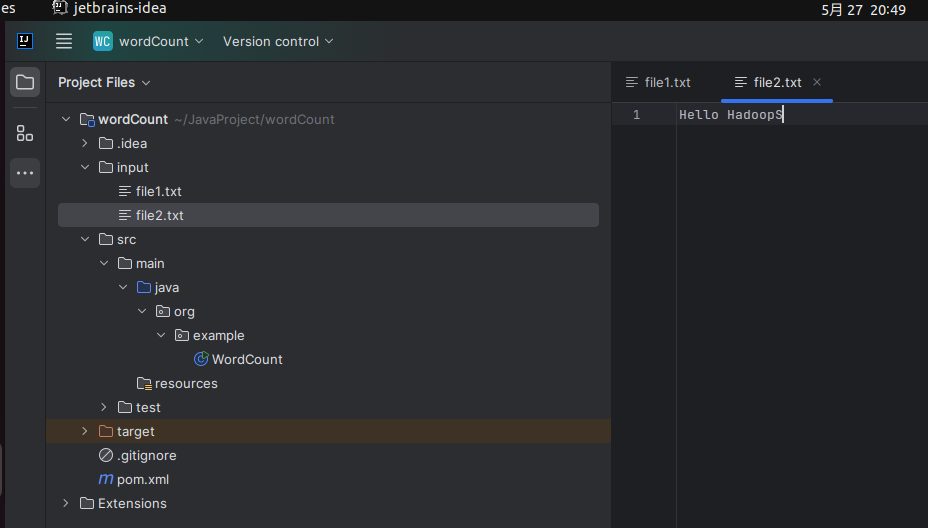
2.4:初始化文件
在工程根目录新建input文件夹,增加两个文件
input
- file1.TXT
Hello Yaoyao
- file2.txt
Hello Hadoop
2.5:运行配置

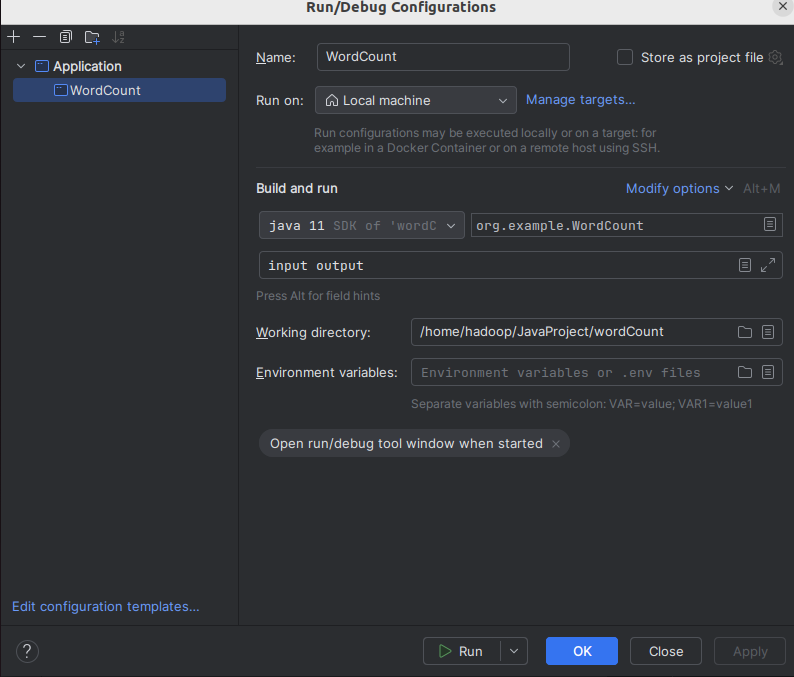
配置完成后点击apply->ok
2.6:运行
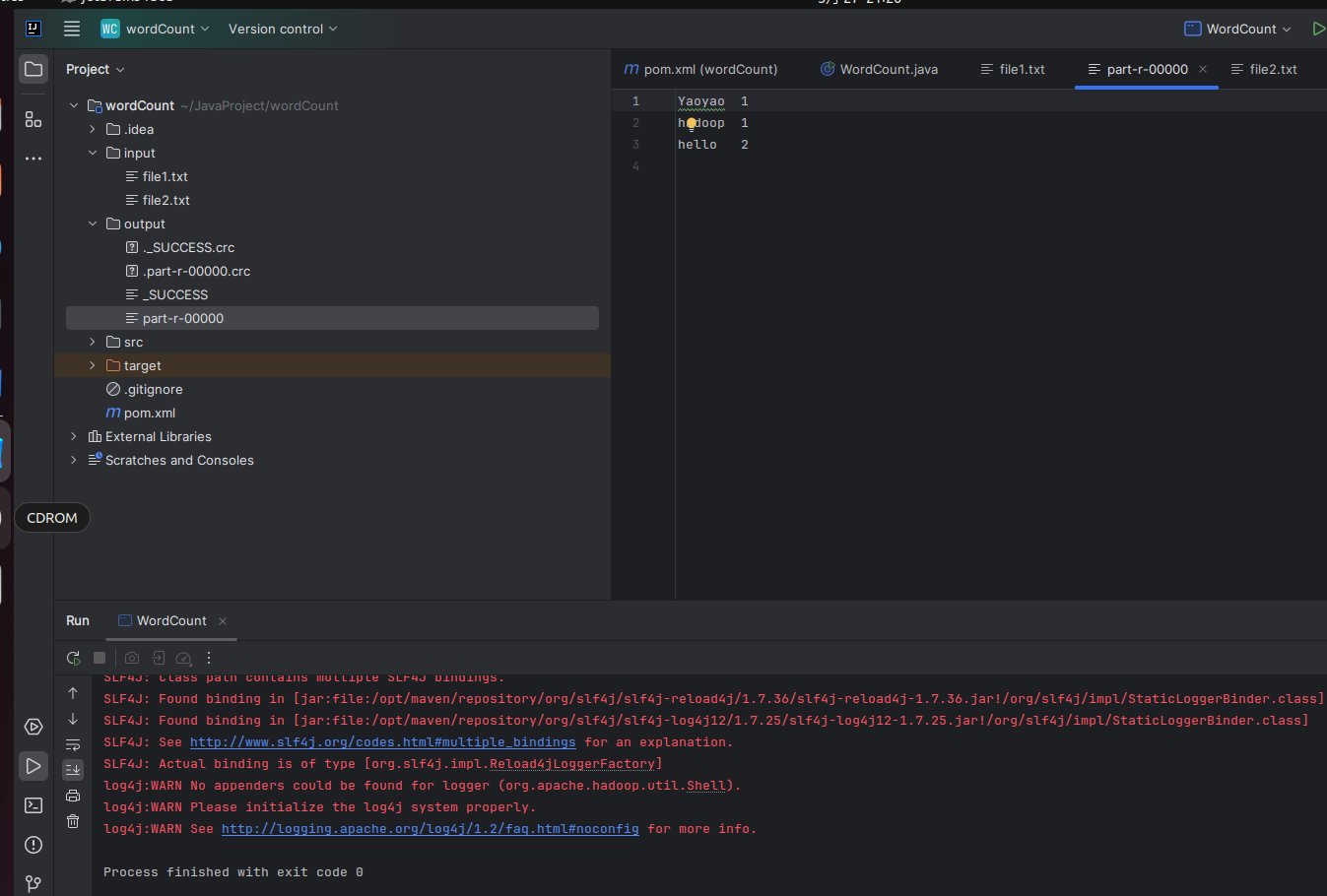
– part-r-00000文件是结果文件
– _SUCCESS文件是成功标志
– _logs目录是日志目录
hadoop_jar_199">三、打包到服务器使用hadoop jar命令执行
3.1:pom.xml增加打包插件
<build><plugins><!--指定主函数和各个依赖--><plugin><artifactId>maven-assembly-plugin</artifactId><version>3.6.0</version><configuration><archive><manifest><mainClass>org.example.WordCount</mainClass></manifest></archive><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin></plugins></build>3.2:maven打包
直接在终端执行命令:
mvn clean install
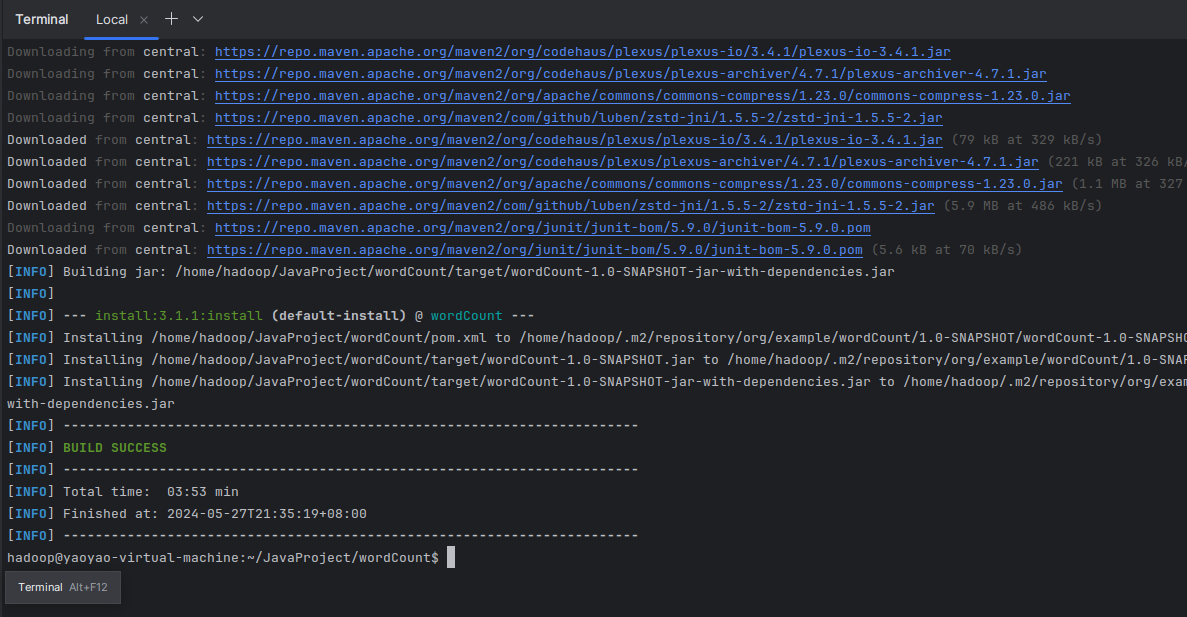
我们得到了jar包
/home/hadoop/JavaProject/wordCount/target/wordCount-1.0-SNAPSHOT-jar-with-dependencies.jar
jar包,也就是jar文件(Java Archive)。可以这么理解,它类似于zip包。但与zip文件不同的是,jar文件不仅用于压缩和发布,而且还用于部署和封装库、组件和插件程序,并可以被像编译器和 JVM 这样的工具直接使用。
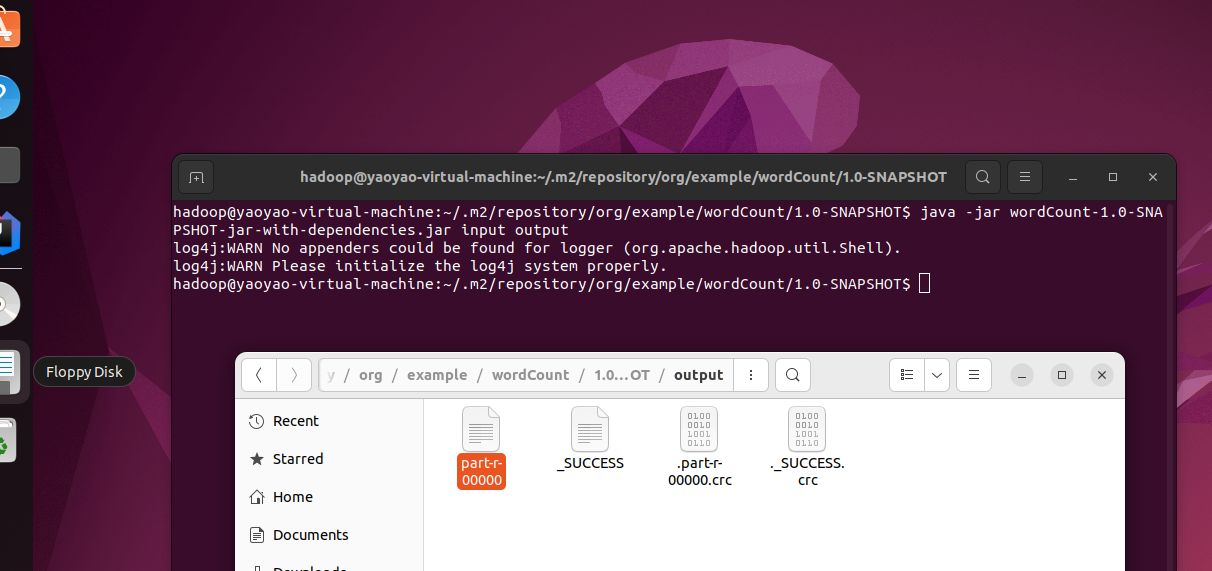
3.3:使用java -jar执行
-
在当前可执行jar目录初始化input文件夹

-
在当前目录打开命令行,执行以下命令,即可在当前目录生成output文件夹,里面就是执行结果。(注意,需要先启动hadoop)
java -jar wordCount-1.0-SNAPSHOT-jar-with-dependencies.jar input output
hadoop_258">3.4:将文件上传到hdfs,使用hadoop执行
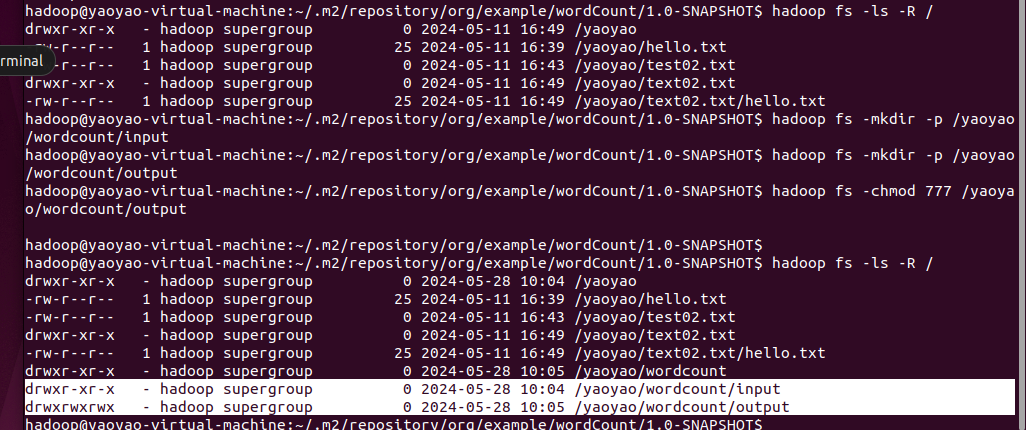
1.在hdfs上创建wordCount/input文件夹,并且把本地的file1,file2上传
hadoop fs -mkdir -p /yaoyao/wordcount/input
#hadoop fs -mkdir -p /yaoyao/wordcount/output
#hadoop fs -chmod 777 /yaoyao/wordcount/output
更改输出文件权限,任何人有写权限。因为从本地直接使用服务器的大数据集群环境,服务器集群文件没有写权限。(hadoop会自动生成输出目录,无需提前创建!!!否则报错!!!)
hadoop fs -copyFromLocal file1.txt /yaoyao/wordcount/input
hadoop fs -copyFromLocal file2.txt /yaoyao/wordcount/input
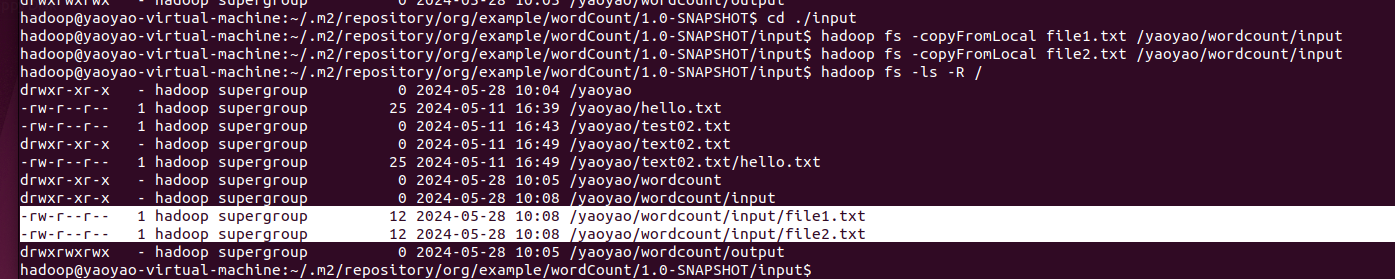
查看hdfs上传的input数据内容
hadoop fs -cat /yaoyao/wordcount/input/file1.txt
hadoop fs -cat /yaoyao/wordcount/input/file2.txt

hadoopjar_287">2.使用hadoop命令执行jar包
hadoop jar wordCount-1.0-SNAPSHOT-jar-with-dependencies.jar /yaoyao/wordcount/input /yaoyao/wordcount/output
发现报错:
Exception in thread “main” org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://localhost:9000/yaoyao/wordcount/output already exists
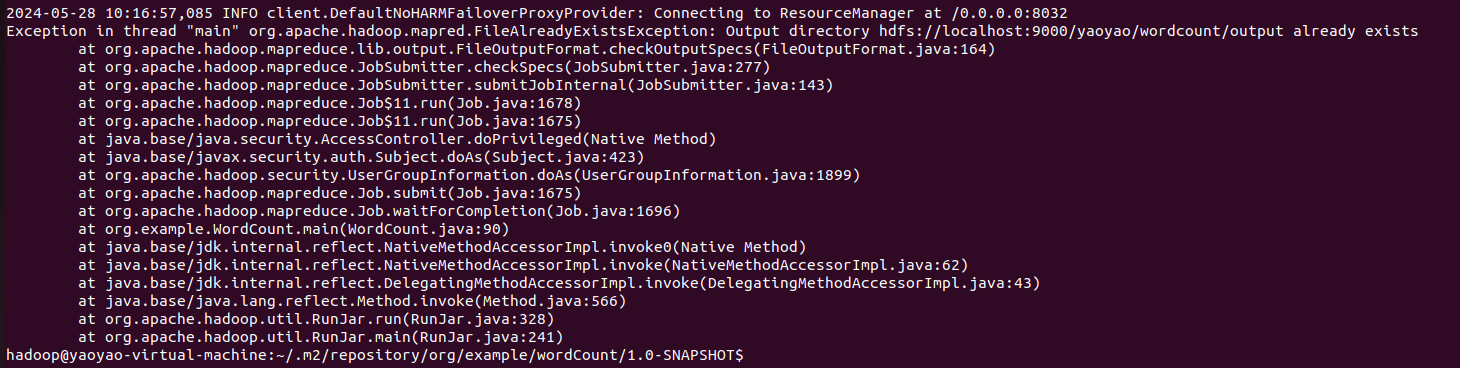
原因:Hadoop 运行程序时,输出目录不能存在
因为Hadoop会自动创建输出目录。这样做可以确保在任务执行过程中不会出现命名冲突或并发写入问题。
将输出目录删除即可:
hadoop fs -rm -r /yaoyao/wordcount/output
但是运行又发现报错:
Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster
Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.mapreduce.v2.app.MRAppMaster
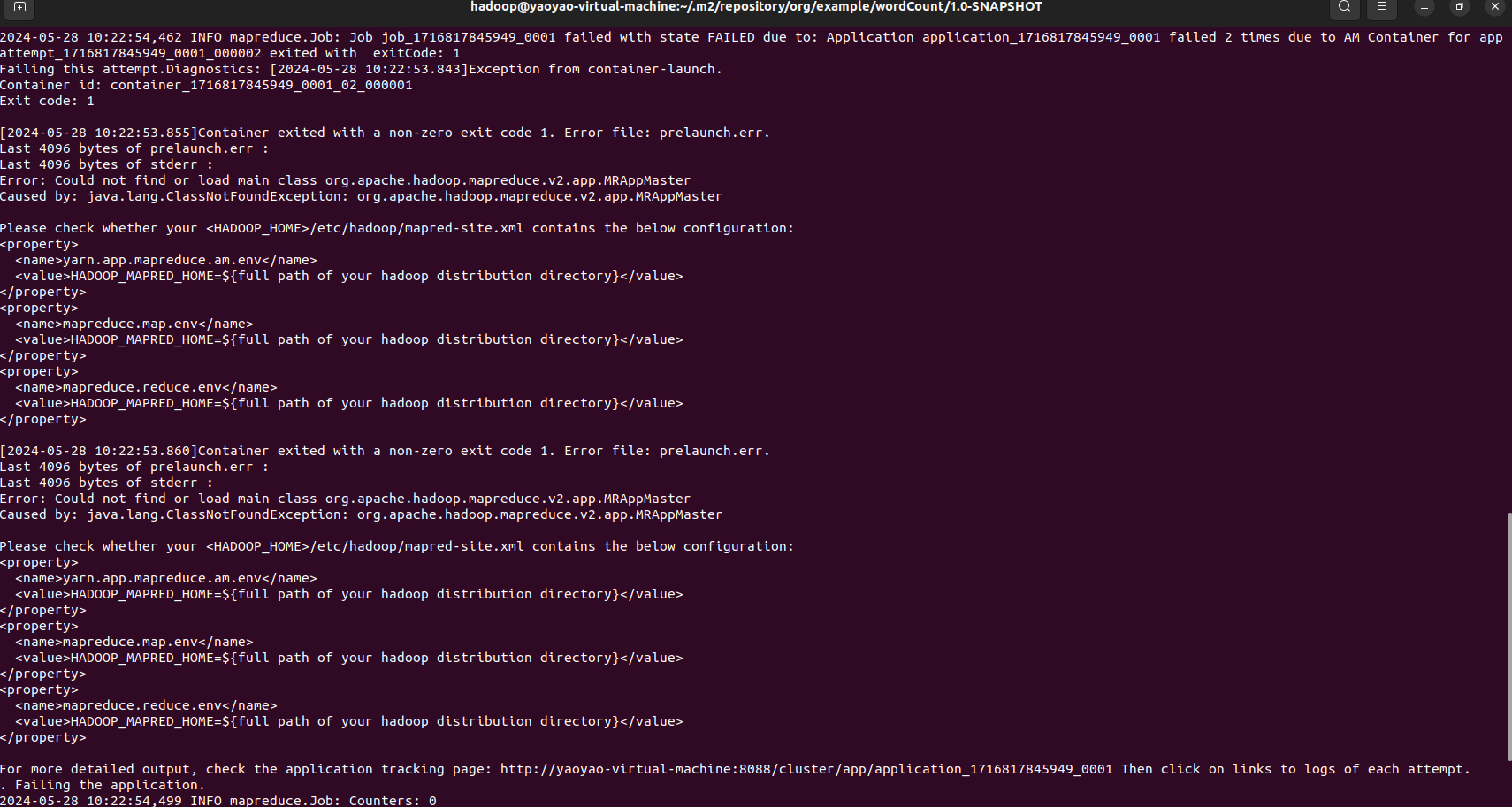
原因分析:日志中有段Please check whether your <HADOOP_HOME>/etc/hadoop/mapred-site.xml contains the below configuration很明显说明配置文件有问题,按照提示将mapred-site.xml配置补全
cd /usr/local/hadoop/etc/hadoop/
sudo gedit mapred-site.xml<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.application.classpath</name><value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value></property><property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property><property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property><property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property>
</configuration>
并重启yarn服务
# 先停止
/usr/local/hadoop/sbin/stop-yarn.sh# 在启动
/usr/local/hadoop/sbin/start-yarn.sh
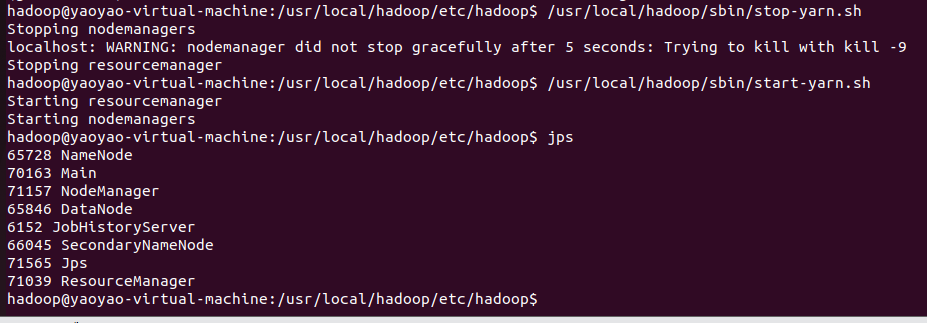
到jar所在目录,再次运行任务,就成功了

查看结果。
hadoop fs -cat /yaoyao/wordcount/output/part-r-00000
Hadoop 1
Hello 2
World 1