IO类型
缓存 I/O
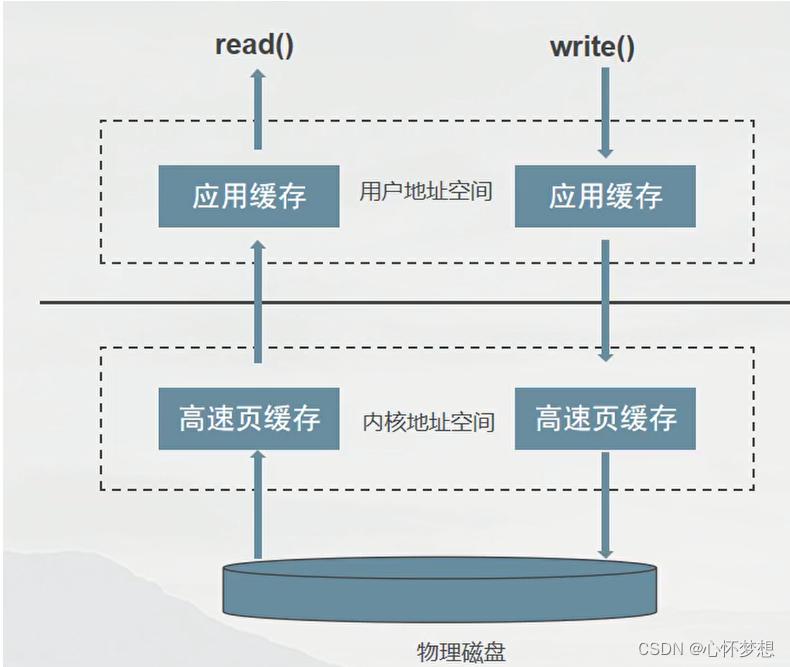
缓存 I/O 又被称作标准 I/O,大多数文件系统的默认 I/O 操作都是缓存 I/O。在 Linux 的缓存 I/O 机制中,数据先从磁盘复制到内核空间的缓冲区,然后从内核空间缓冲区复制到应用程序的地址空间(用户空间)。
读操作:操作系统检查内核空间的缓冲区有没有需要的数据,如果已经缓存了,那么就直接从缓存中返回,也就是将数据复制到应用程序的用户空间;否则从磁盘中读取数据至内核空间的缓冲区,再将内核空间缓冲区的数据返回。
写操作:将数据从用户空间复制到内核空间的缓冲区,这时对用户程序来说写操作就已经完成。至于什么时候将数据从内核空间写到磁盘中,这步由操作系统决定,除非显示地调用了 sync 同步命令。
缓存 I/O 的优点:
在一定程度上分离了内核空间和用户空间,保护系统本身的运行安全;
可以减少读盘的次数,从而提高性能。
send数据图解
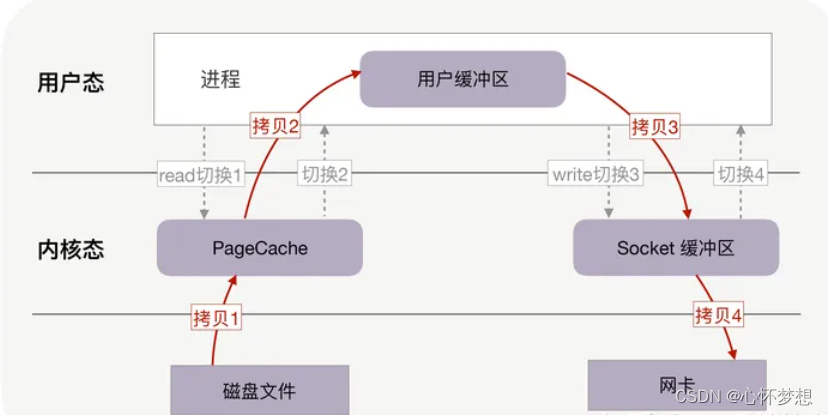
缓存 I/O 的缺点:存在四次上下文切换(用户态与内核态之间切换),四次数据拷贝(CPU参与), 这些数据拷贝操作所带来的 CPU 以及内存开销是比较大的。CPU参与四次拷贝的计算机好像已经不多见了,内核到磁盘的数据拷贝更多的是采用DMA。
如果采用DMA的IO完整流程图:
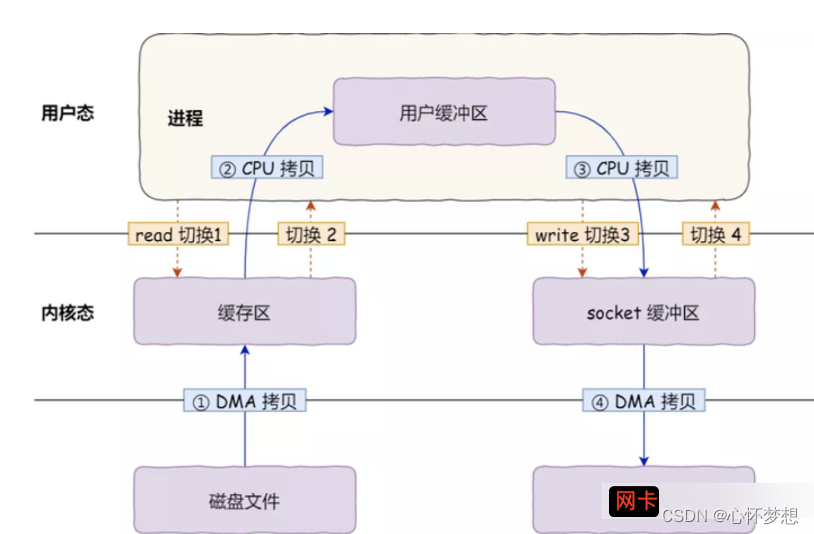
这里还是发生了 4 次用户态与内核态的上下文切换,发生了 4 次数据拷贝,但其中两次是 CPU参与的拷贝,降低了CPU压力。
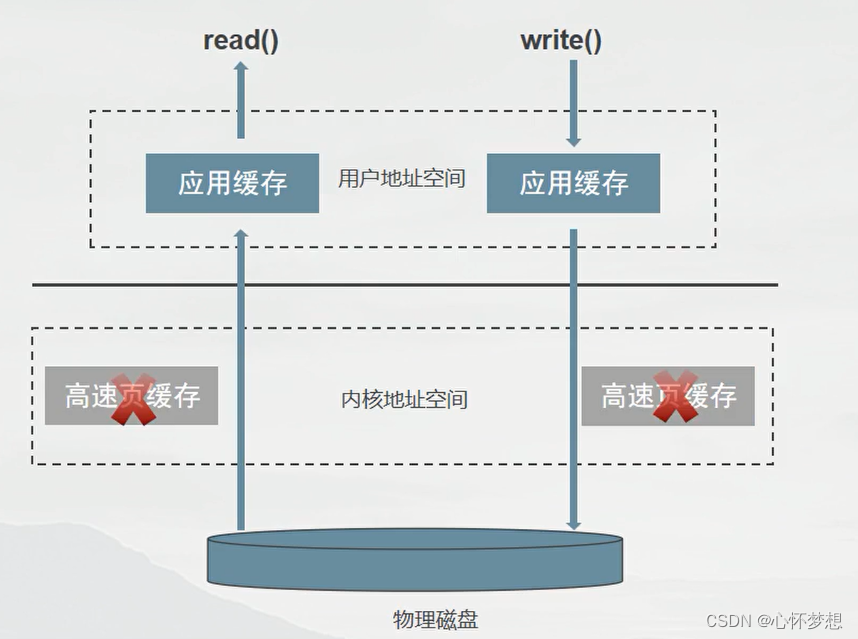
直接 I/O
Linux提供了对这种需求的支持,即在open()系统调用中增加参数选项O_DIRECT,用它打开的文件便可以绕过内核缓冲区的直接访问,这样便有效避免了CPU和内存的多余时间开销。顺便提一下,与O_DIRECT类似的一个选项是O_SYNC,后者只对写数据有效,它将写入内核缓冲区的数据立即写入磁盘,将机器故障时数据的丢失减少到最小,但是它仍然要经过内核缓冲区
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/mman.h>
#include <string.h> #define FILE_SIZE 4096 // 假设文件大小为4KB,为了示例简单
#define BLOCK_SIZE 512 // 假设块大小为512B int main() { int fd; char *buffer; off_t offset = 0; ssize_t bytes_read, bytes_written; // 打开文件,使用O_DIRECT和O_SYNC标志 fd = open("testfile", O_RDWR | O_CREAT | O_TRUNC | O_DIRECT | O_SYNC, 0644); if (fd == -1) { perror("open"); exit(1); } // 分配内存对齐的缓冲区 // 注意:直接I/O要求缓冲区是块大小的整数倍,并且内存对齐到块大小的边界 posix_memalign((void **)&buffer, BLOCK_SIZE, FILE_SIZE); if (buffer == NULL) { perror("posix_memalign"); close(fd); exit(1); } // 写入文件 memset(buffer, 'A', FILE_SIZE); // 填充数据 bytes_written = pwrite(fd, buffer, FILE_SIZE, offset); if (bytes_written != FILE_SIZE) { perror("pwrite"); free(buffer); close(fd); exit(1); } // 重置偏移量以进行读取 offset = 0; // 读取文件 bytes_read = pread(fd, buffer, FILE_SIZE, offset); if (bytes_read != FILE_SIZE) { perror("pread"); free(buffer); close(fd); exit(1); } // 打印读取的数据(可选) // ... // 清理 free(buffer); close(fd); return 0;
}
注意:对齐问题:直接I/O要求缓冲区在内存中是块大小的整数倍,并且从块大小的边界开始。在上面的示例中,我们使用posix_memalign来分配内存对齐的缓冲区。
文件大小:为了简单起见,上面的示例假设文件大小为4KB,并且块大小为512B。在实际应用中,你可能需要处理更大的文件和/或不同的块大小。
错误处理:在生产代码中,你应该更详细地处理错误情况,并为用户提供有用的错误消息。
性能考虑:虽然直接I/O可以提高性能,但它也可能增加复杂性,并可能不适用于所有用例。在决定使用它之前,请确保你了解其优点和缺点。
内核参数:在某些情况下,你可能需要调整内核参数来启用或优化直接I/O。例如,/proc/sys/vm/dirty_bytes、/proc/sys/vm/dirty_background_bytes等参数可能会影响直接I/O的性能。