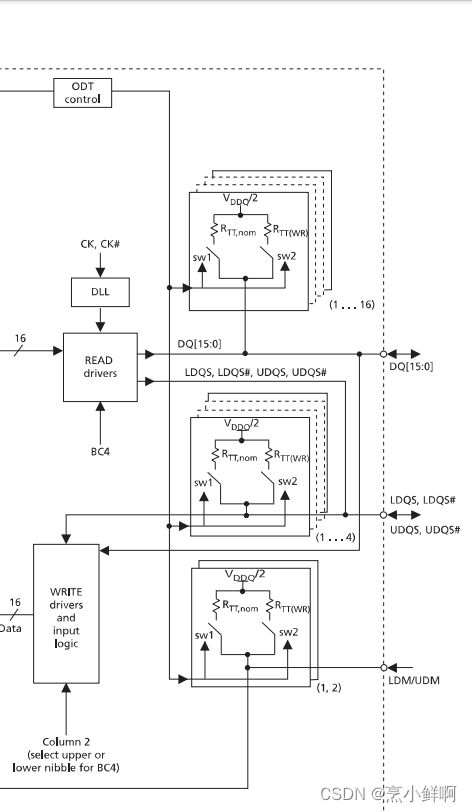
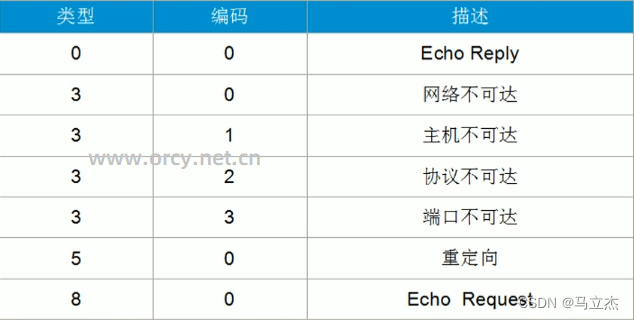
。
R语言数据分析案例框架
1. 案例背景
假设我们是一家电商公司的数据分析师,公司最近推出了一系列促销活动,我们希望通过分析销售数据来评估这些活动的效果。
2. 数据准备
- 数据来源:从公司数据库中获取销售数据。
- 数据清洗:去除重复数据、缺失值处理、异常值处理等。
- 数据整合:将不同来源的数据(如用户信息、产品信息、订单信息等)整合到一个数据集中。
3. 数据探索
- 描述性统计分析:计算销售额、订单量、用户数等基本指标的均值、中位数、众数、标准差等。
- 数据可视化:使用ggplot2等包绘制销售额随时间变化的折线图、不同产品类别的销售额柱状图等。
4. 数据预处理
- 数据转换:对销售额、订单量等数值型变量进行对数转换,以改善数据的正态性。
- 特征工程:创建新的特征,如促销活动的虚拟变量、用户购买频率等。
5. 数据分析
- 促销活动效果分析:通过对比促销前后的销售额、订单量等指标,评估促销活动的效果。
- 用户行为分析:分析不同用户群体的购买行为差异,如新用户和老用户的购买频率、购买金额等。
- 产品分析:分析不同产品类别的销售情况,找出畅销产品和滞销产品。
6. 建模预测
- 选择合适的模型:根据问题的性质和数据的特点,选择合适的预测模型,如线性回归、决策树、随机森林等。
- 模型训练与评估:使用训练集训练模型,并使用测试集评估模型的性能。
- 模型优化:通过调整模型参数、使用交叉验证等方法优化模型的性能。
7. 结果展示与报告
- 结果可视化:使用图表展示分析结果和模型预测结果。
- 撰写报告:将分析结果和结论以报告的形式呈现给管理层。
8. 案例扩展与改进
- 增加数据来源:考虑增加其他来源的数据,如社交媒体数据、竞争对手数据等,以丰富分析内容。
- 尝试新模型:尝试使用深度学习等更先进的模型进行预测分析。
- 定期更新:定期更新数据和分析结果,以反映市场变化和公司业务的发展。
示例代码片段(仅供参考)
# 加载必要的包
library(tidyverse)
library(ggplot2)
library(caret)# 读取数据
data <- read_csv("sales_data.csv")# 数据清洗和整合(这里仅展示示例)
cleaned_data <- data %>%drop_na() %>% # 去除包含NA的行mutate(sale_date = as.Date(sale_date)) %>% # 将日期列转换为日期类型# ... 其他清洗和整合操作# 数据探索(示例:绘制销售额随时间变化的折线图)
ggplot(cleaned_data, aes(x = sale_date, y = sales_amount)) +geom_line() +labs(title = "Sales Amount Over Time", x = "Date", y = "Sales Amount")# 建模预测(示例:使用线性回归模型预测销售额)
# 假设已经划分了训练集和测试集
train_set <- cleaned_data[train_indices, ]
test_set <- cleaned_data[-train_indices, ]# 构建线性回归模型
model <- lm(sales_amount ~ ., data = train_set)# 评估模型性能(示例:计算R平方值)
summary(model)$r.squared# ... 其他建模和评估操作
请注意,以上只是一个简化的案例框架和示例代码片段,你需要根据具体的数据和业务需求来扩展和完善这个案例。