目录
1 Modifiers部分
1.1 assign的使用
1.2 insert的使用
1.3 erase的使用
1.4 replace的使用
2 capacity部分
2.1 max_size的使用
2.2 capacity的使用
2.3 reserve的使用
2.4 shrink_to_fit简介
2.5 resize的使用
2.6 clear的使用
3 String operations部分
3.1 c_str的使用
3.2 copy的使用
3.3 find和rfind的使用
3.4 substr的使用
3.5 find_first_of(not)和find_last_of(not)的使用
3.6 compare的使用
4 Non-member function overloads部分
4.1 operator+的使用
4.2 relational operators
4.3 operator<< 和 operator>>的使用
4.4 getline的使用
5 补充函数
6 有关编码
1 Modifiers部分

上文已经介绍了+=,append,push_back,pop_back,这里介绍assign,insert,erase,replace。
1.1 assign的使用
assign的使用类似于赋值,会完全覆盖原来的字符串,进行赋值:
int main()
{string s1("Hello world");s1.assign("xx");cout << s1;return 0;
}
但是查看文档就发现函数重载挺冗余的,实际上常用的也就是第三个了,类比的化,第二个也可以连蒙带猜的试一下:
int main()
{string s1("Hello world");string s2("123456789");s1.assign(s2,2,5);cout << s1;return 0;
}1.2 insert的使用
insert在链表中使用过,当然是名字使用过,插入的意思,有意思的是string没有直接的支持头插,但是间接的支持了头插,可以使用insert进行实现:

int main()
{string s1("Hello world");string s3 = "123456";s3.insert(0,s1);cout << s3 << endl;return 0;
}第一个重载的使用如上,pos位置插入数据,打印出来就是Hello world123456,类似的是第三个:
int main()
{string s3 = "123456";s3.insert(0,"132");cout << s3 << endl;return 0;
}当然还有迭代器版本的,前四个函数挺类似的,不作介绍,这里介绍一下迭代器版本的:
int main()
{string s1("123456");string s2("Hello world");s1.insert(s1.end(), s2.begin(), s2.end());cout << s1 << endl;return 0;
}第一个参数是选择插入的位置,后面是区间,但是注意的是这个区间是左闭右开的。
但是离谱的是insert不支持直接插入单个字符,要插入单个字符使用第四个函数重载:
int main()
{string s1("123456");s1.insert(0, 1, 'x');cout << s1 << endl;return 0;
}有疑问了就,可以插入一个只有一个字符的字符串,但是这种情况只能这样写:
int main()
{string s1("123456");char ch = 'a';s1.insert(0, 1, ch);cout << s1 << endl;return 0;
}
但是不太推荐使用,因为它的时间复杂度是O(N),底层的实现原理是移动每个数据到相应位置,时间复杂度即一个循环,是O(N)。
1.3 erase的使用
有插入就会有删除,erase即删除:

参数问题现在已经不大了,使用如下:
int main()
{string s1("abcdefg");s1.erase();//清空字符串cout << s1 << endl;string s2("abcdefg");s2.erase(0);//清空字符串cout << s2 << endl;return 0;
}int main()
{string s3("abcdefg");s3.erase(0, 3);//abc清空cout << s3 << endl;string s4("abcdefg");s4.erase(s4.begin(), s4.begin() + 4);//abcd清空cout << s4 << endl;return 0;
}迭代器和npos的使用如上,但是仍然不推荐使用,因为和insert是一样的,时间复杂度为O(N)。
因为缺省值是npos,所以删除的长度可以离谱但是下标不能离谱:
int main()
{string s5("abcdefg");s5.erase(2,100);cout << s5 << endl;return 0;
}1.4 replace的使用
replace的英文是代替,顾名思义咯~

多吧?第一个函数重载使用如下:
int main()
{string s1("123456");s1.replace(2,2,"a");cout << s1 << endl;return 0;
}
从3开始把两个字节替换成a字符。
为什么说它坑呢?引入一道题,将一段字符串中的所有空格全部替换为x,用C语言就是:
int main()
{string s2("hello world hello Byte");for(int i = 0;i < s2.size();i++){if (s2[i] == ' '){s2[i] = 'x';}}cout << s2 << endl;return 0;
}用C++的replace就是:
int main()
{string s3("hello world hello Byte");for (int i = 0; i < s2.size(); i++){if(s3[i] == ' '){s3.replace(i,1,"x");}}cout << s3 << endl;return 0;
}看似没有差别?因为这里的空格刚好是一个字符,如果是还要涉及数据移动的问题,效率自然就低下了,所以慎用。
当然方法很多,多多选择。
2 capacity部分

上篇已经介绍了,size,length,本文介绍max_size,resize,capacity,reserve,clear,shrink_to_fit。
2.1 max_size的使用

这个函数实际上是一个冗余的设计,即一个字符串能开到多大:
int main()
{string s1("123456");cout << s1.size() << endl;cout << s1.max_size() << endl;return 0;
}max_size()的结果是看64位还是32位情况,64位是:

32位是:
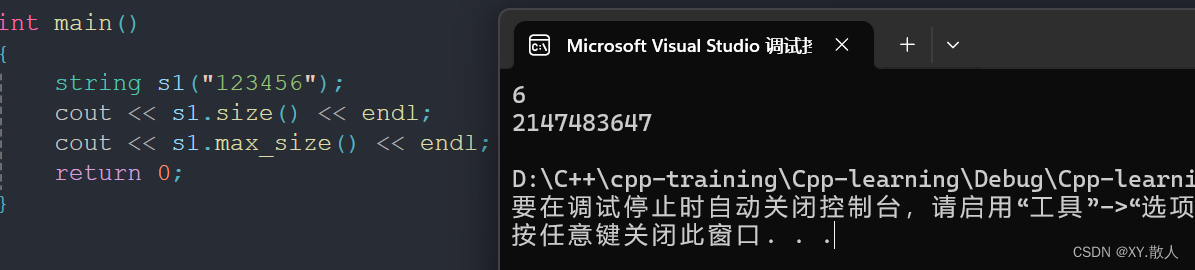
虽然结果不一样,但是大小都是挺惊人的,因为它只有这一个功能,实际上也没有哪个字符串会开这么大,就了解一下即可。
2.2 capacity的使用
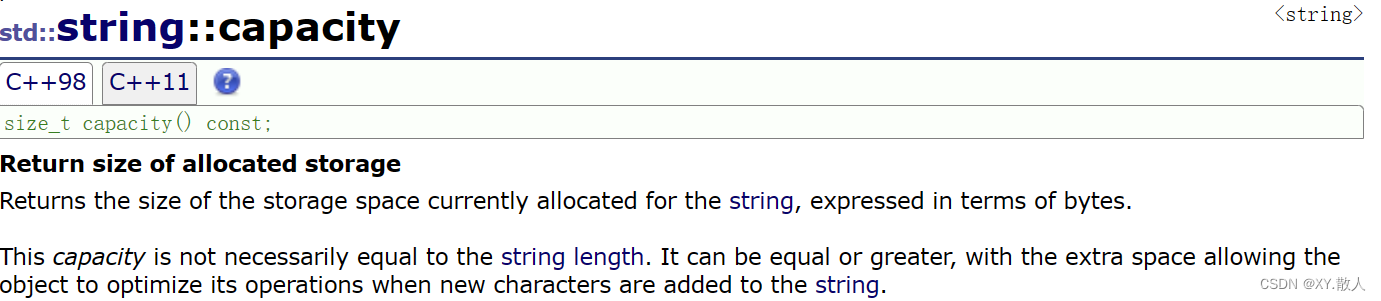
由前面的学习可以得知capacity是容量的意思,所以当我们调试一个字符串的时候总会发现:

一个串里面有size,有capacity,有其他元素,那么空间不够了,capacity就会自动扩容,我们要了解的就是它的扩容规则:
int main()
{string s1("123456");cout << "Now capacity:" << s1.capacity() << endl;for (int i = 0; i < 200; i++){s1.push_back('x');if (s1.capacity() == s1.size()){cout << "Capacity Changed:" << s1.capacity() << endl;}}return 0;
}
尾插200个数据,使其扩容: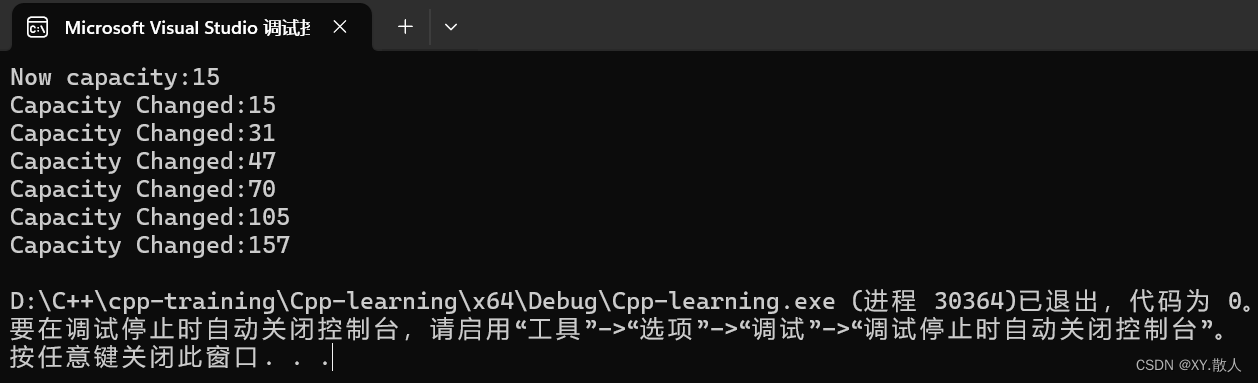
结果如下,我们可以发现扩容的方式很奇怪,一开始是约等于2倍,后面逐渐变成了1.5倍
这是Vs环境下的扩容,在Linux环境下就是标准的2倍扩容:

但是实际上呢,这里的capacity都是少了一个单位的,比如上面的应该是16,32,38,71,因为要给斜杠0预留一个空间。
可以看到不同的编译器实现扩容的时候有一定差异,Vs下的编译器的是clang,Linux环境下的编译器是g++,实现的时候都有差异,但是不管Vs还是Linux,capacity都是少了1的,因为斜杠0.
2.3 reserve的使用
reserve?reverse?傻傻分不清咯~
reverse是逆置,而reserve的中文意思是预存,保留,是用来开空间的:

它实际影响的只有capacity,不会影响size:
int main()
{string s1("123456");cout << s1.size() << " " << s1.capacity() <<endl;s1.reserve(100);cout << s1.size() << " " << s1.capacity() <<endl;return 0;
}

我们开了100个空间,但是实际上开了111个空间?
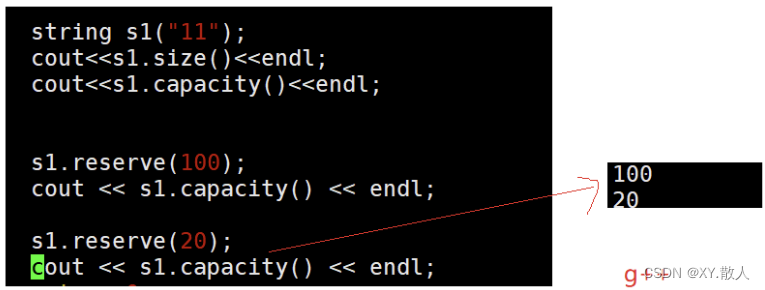
Linux环境下还是老老实实的要多少开多少。
所以reserve和capacity一样,平台直接有差异。
reserve还可以用来进行缩容,但是因为vs默认是不缩容的,所以这里呢给个结论:
如果缩容,最低只能缩容到15(实际是16),因为string有一个成员是buff数组,如果string的长度不超过16就会存到buff数组上去,就不用在堆上单独开开空间了,因为数组的大小是定的,16,所以再怎么缩容,都不会比15小。
但是也不是一无用处这个函数,比如涉及到多次开空间的题目,我们可以提前开好,省略了一下开空间的步骤,效率稍微高一点。
2.4 shrink_to_fit简介

这个函数是缩容,但是是在C++11中引进的,虽然可以实现我们想要的功能,但是实际上内存越来越发达的时代,我们更多的追求的是效率,空间不够的情况是比较少见的,而且这个函数使用代价挺大的,我们大多数人以为的缩容是这样的:

有一块空间,释放到不需要的部分,但是在动态内存管理章节我们知道,释放空间不能一段一段的释放,只能一整块的释放,所以实际的缩容是把原来的空间释放掉,重新开一块我们想要的小空间,这个代价挺大的,所以不推荐使用。
2.5 resize的使用

前文提及,capacity的扩容只会影响capacity,不会影响size,但是resize两个都会影响到:
int main()
{string s1("123456");cout << s1.size() << " " << s1.capacity() << endl;s1.resize(100);cout << s1.size() << " " << s1.capacity() << endl;s1.resize(5);cout << s1.size() << " " << s1.capacity() << endl;return 0;
}
如果我们是resize100的话,6后面的就全是斜杠0了,但是如果我们缩容,就会删除一部分数据,比如这里的6就被删除了。
int main()
{string s2("hello world");s2.resize(20, 'x');cout << s2 << endl;return 0;
}
resize插入数据会扩容,这里就是在d后面插入x知道字符串长度为20。
也可以当删除使用,size小于原来的size就可以了。
2.6 clear的使用
clear清除,使用起来还是很简单的:

int main()
{string s1("123456");cout << s1 << endl;s1.clear();cout << s1 << endl;return 0;
}清除完毕。
3 String operations部分

前文已经介绍了,,,前文没有介绍,嘿嘿,这里介绍c_str,copy,find,rfind,find_first_of,find_last_of,fin_first_not_of,find_last_not_of,substr,compare。
对于get_allocator简单掠过,它涉及到了配置器,就不多介绍了。
3.1 c_str的使用

c_str返回的是字符串的指针,c++和C语言混用的使用就可能有点坑:
int main()
{string file("Test.cpp");FILE* fout = fopen(file.c_str(), "r");char ch = fgetc(fout);while (ch != EOF){cout << ch;ch = fgetc(fout);}return 0;
}比如这里的fopen不加file. 的话,那么c_str就读取不到了,但是在C语言里面这里都是直接放的指针,没有考虑其他的,C++考虑的还要多一些。
当然函数本身的使用还是很简单的,返回指针而已。
3.2 copy的使用

copy的本质是赋值,但是不是给string类的赋值,是给字符数组赋值,并且返回值是赋值过去的字符串长度,可以理解为返回的是len
int main()
{string s1("abcdefg");char str[20] = "123456";size_t ret = s1.copy(str, 3, 2);cout << s1 << endl;cout << str << endl;cout << ret << endl;return 0;
}3.3 find和rfind的使用

find即寻找,rfind同理,倒过来寻找,也可以指定从哪里开始寻找,返回的就是找到的位置的下标,如果没有找到返回的就是npos,find可以用来找子串也可以用来寻找单个字符,这里我们试试分割后缀:
string file("string.cpp.zip");3.4 substr的使用

戛然而止,因为要分割字符串,我们还需要了解一个函数叫做substr,这个函数有利于我们分割字符串,参数两个,一个是位置,一个是长度,如果不给长度,就是默认分割到字符串结束,所以有了find返回的下标,我们这里就可以实现分割.zip:
int main()
{string file("string.cpp.zip");size_t pos = file.rfind('.');string suffix = file.substr(pos);cout << suffix << endl;return 0;
}那么为什么我们使用rfind呢?因为有两个.,我们使用find,找到的就是第一个.,所以我们应该倒过来寻找,找到之后久交给substr就可以了。
当然,我们想要分割一段区间也是可以的:
int main()
{string s1("I am the best");string s = s1.substr(5, 3);cout << s << endl;return 0;
}
给一个区间,然后分割了3个字符,the就被分割出来了。
3.5 find_first_of(not)和find_last_of(not)的使用

首先看一下函数的参数,没有什么特殊的地方,那就随便过了?不能,因为最大的误区在它的名字这里,find_first_of,一翻译就是,找最开始的什么什么,如果这样想就大错特错辣,构造和初始化有关系吗从名字上看,丝毫没有,这个也是同理的,这个的真正用法其实是:
int main()
{string str("Please, replace the vowels in this sentence by asterisks.");size_t found = str.find_first_of("aeiou");while (found != string::npos){str[found] = '*';found = str.find_first_of("aeiou", found + 1);}cout << str << endl;return 0;
}这里介绍第二个重载的使用,其他的就可以类比了,这个函数的真正用法是找任意字符,即在一个字符串里面找参数中的任意字符,找到了就会返回下标,那么就可以对下标进行一些操作,比如修改,找到了也要记得修改找的位置。

last同理,只是last是从字符串末尾开始查找的,实际使用没啥区别:
void SplitFilename(const std::string& str)
{std::cout << "Splitting: " << str << '\n';std::size_t found = str.find_last_of("/\\");std::cout << " path: " << str.substr(0, found) << '\n';std::cout << " file: " << str.substr(found + 1) << '\n';
}
int main()
{std::string str1("/usr/bin/man");std::string str2("c:\\windows\\winhelp.exe");SplitFilename(str1);SplitFilename(str2);return 0;
}只是根据不同的需求使用不同的函数罢了,比如我要分割一个网站,从末尾开始分割就可以了。

not的使用就不介绍了,有了前面两个函数的使用,这个看看也就会了。
3.6 compare的使用

compare的使用是字典序的比较,和strcmp是一样的,别看它参数多,比较我们使用第一个就可以了,其他重载要是一定要使用,看看文档也就会了:
int main()
{string s1("123456");string s2("321654");cout << s1.compare(s2) << endl;return 0;
}int main()
{string s1("123456");string s2("321654");cout << (s1 < s2) << endl;return 0;
}但是比较不仅可以用compare哦,还可以使用重载后的< >,就和cout能打印自定义类型一样。
4 Non-member function overloads部分

这部分呢就是非成员函数的部分了,重载为了全局函数,本文介绍operator+,operator>> ,operator<<,getline,relational operators。
4.1 operator+的使用

这个函数说来奇怪,重载为全局函数不是因为多特殊,只是为了支持某种形式,先看一般使用:
int main()
{string s1("123456");string s2("Hello world");cout << s1 + s2 << endl;cout << s1 + "xxx" << endl;cout << "xxx" + s1 << endl;cout << s1 + 'a' << endl;cout << 'b' + s1 << endl;return 0;
}
看起来也没什么奇怪的,那么特殊的原因是因为原来是想支持"xxx" + s1,但是发现重载为成员函数之后的第一个参数铁定是this指针,所以为了支持那种形式就重载成全局函数咯,当然不影响使用。
4.2 relational operators
compare的使用已经使用过了重载后的<,这里深入一点,我们看到相关的重载有很多个,实际上就是进行比较的,类比于日期类的多个比较,这里我们结合日期类的写法也就好理解了,当然,比较都是按照字典序进行比较的。
int main ()
{std::string foo = "alpha";std::string bar = "beta";if (foo==bar) std::cout << "foo and bar are equal\n";if (foo!=bar) std::cout << "foo and bar are not equal\n";if (foo< bar) std::cout << "foo is less than bar\n";if (foo> bar) std::cout << "foo is greater than bar\n";if (foo<=bar) std::cout << "foo is less than or equal to bar\n";if (foo>=bar) std::cout << "foo is greater than or equal to bar\n";return 0;
}4.3 operator<< 和 operator>>的使用

这个就太简单辣:
int main()
{string s1("123456");cout << s1 << endl;return 0;
}直接就过了。
4.4 getline的使用

我们先上一个实际例子:
int main()
{string s1;cin >> s1;cout << s1 << endl;return 0;
}
原本程序的意思是输入123 asd并进行打印的,但是>>重载了并不会打印完,这是因为空格,换行对于字符串的读取来说都是结束标志:
int main()
{string s1;cin >> s1;while (1){cin >> s1;cout << s1 << endl;}return 0;
}
这样就会更形象了,那么怎么结束这个程序呢?有两种方法,一种是ctrl + c,暴力杀进程,直接结束,第二种是ctrl + z。
回归正题,我们想要读取空格怎么办?
这里就需要用到getline了:
int main()
{string s2;getline(cin, s2);cout << s2 << endl;return 0;
}
这是第二个函数的重载,第一个的最后一个参数就是让你自己设置结束标志,有兴趣可以自己试试。
5 补充函数
对于string的学习不免遇到大数运算,这里提供一个函数,to_string和stoi,分别是整型转字符串,字符串转整型,但是不要用在大数运算上面,只能是说有一点点关系:
int main()
{string s2("111111");int ret1 = stoi(s2);cout << ret1 << endl;int ret2 = 112345648;string s3 = to_string(ret2);cout << s3 << endl;return 0;
}相关的文档就不上图了,有兴趣自己看看。
6 有关编码
编码是一种文字的映射,最基本的是ASCII编码,这是美国科学家研究的,最初用来存储他们的相关语言,最特殊的就是$,这个是ASCII一个标志性符号:

那么就引入了一个问题,全世界的文字那么多,不同的语言几千种甚至上万,该如何存储呢?更不用说汉字常见的就有几千个,所以汉字加起来是近9万了,如果在计算机上表达自己的语言成为了一个难题:
int main()
{string s1("计算机");string s2("123456");return 0;
}
当我们存入了这样的字符串,我们在内存能看到计算机吗?
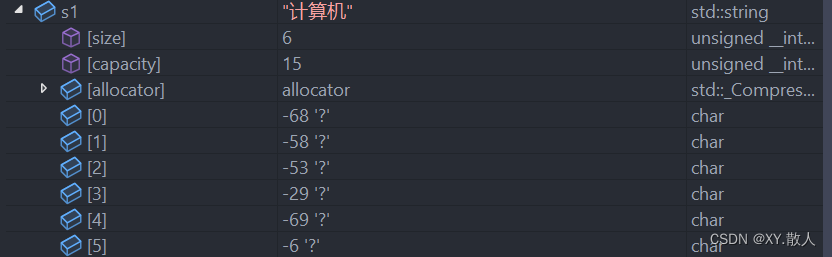
为什么会是?,编译器是如何打印计算机三个字的?这里我们不得不佩服计算机科学家们,引入了一个种新编码,叫做Unicode,称为万国码,发明出来就是为了保证计算机能打印绝大多数国家的语言的:

那么一台计算想要保证能打印不同的语言只靠一个ASCII可不够,所以引入了utf8编码,可以理解为utf8包含了Unicode和ASCIIm,与此同时还有utf16,utf32:

可以看到utf8通过一个字节的开头判断这个字属于哪个字节范围,所以计算打印的时候实际上是按照编码表去寻找最后打印的,那么16和32因为存储的成本变高了,所以不太推荐使用,目前很多机器都是使用的utf8,vs和Linux环境下使用的都是utf8。
那可能会问了,和string有什么关系?string是字符的集合:

看到这个basic了吗?我们学习的都是1个字节的字符串集合,通过编码的介绍不难猜出字符不止只有一个字节,比如:

还存在这种宽字节的字符,这就是编码的意义,存储更多的字符,使得计算机成为一门共同的语言!
感谢阅读!