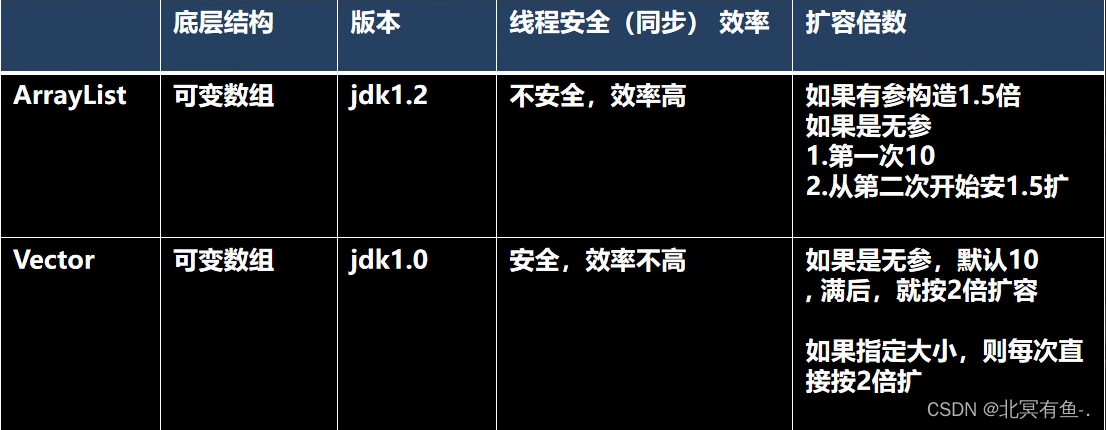
目录
准备
资源准备
实验架构
环境准备
实验步骤
(一)查看环境
1、检查防火墙是否关闭
2、检查三台虚拟机hosts文件
3、检查ssh环境
hadoop%E9%9B%86%E7%BE%A4-toc" style="margin-left:40px;">(二)部署hadoop集群
1、安装haoop
2、创建hdfs数据文件存储目录
3、修改配置文件
(三)初始化HDFS
(四)主从节点同步
hadoop%E7%9B%AE%E5%BD%95%E6%96%87%E4%BB%B6%E5%88%B0slave%E8%8A%82%E7%82%B9-toc" style="margin-left:80px;">1、同步/usr/local/hadoop目录文件到slave节点
hadoopdir%E7%9B%AE%E5%BD%95%E6%96%87%E4%BB%B6%E5%88%B0slave%E8%8A%82%E7%82%B9-toc" style="margin-left:80px;">2、同步/home/hadoopdir目录文件到slave节点
3、同步环境信息
hadoop%E9%9B%86%E7%BE%A4-toc" style="margin-left:40px;">(五)测试hadoop集群
启动集群
hadoop%E9%9B%86%E7%BE%A4-toc" style="margin-left:40px;">(六)验证hadoop集群
1、JPS查看Java进程
2、登录网页查看
今天我们基于开源软件搭建满足企业需求的Hadoop生态系统,构建基础的大数据分析平台
准备3台机器搭建Hadoop完全分布式集群,其中1台机器作为Master节点,另外两台机器作为Slave节点,主机名分别为Slave1和Slave2
准备
资源准备
| 资源名称 | 存储目录 |
| hadoop安装包 | /opt/package/software |
实验架构
在目录/usr/local/下 设置主机名,ip与机器名映射关系
| ip地址m | 机器名 | 类型 |
| 192.168.10.147 | master | NameNode ResourceManager |
| 192.168.10.148 | slave1 | DataNode NodeManger |
| 192.168.10.149 | slave2 | DataNode NodeManger |
环境准备
- Hadoop2.7.5
- VMware Workstation 15.1.0 Pro for Windows
- 虚拟机镜像
实验步骤
(一)查看环境
#关闭防火墙命令
[root@slave1 ~]# systemctl stop firewalld.service
1、检查防火墙是否关闭
[root@slave1 ~]# firewall-cmd --state
not runningh3
2、检查三台虚拟机hosts文件
[root@master ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.80.101 master
192.168.80.102 slave1
192.168.80.103 slave2
3、检查ssh环境
[root@master ~]# ssh slave1 date
Mon Nov 19 10:23:43 CST 2018
[root@master ~]# ssh slave2 date
Mon Nov 19 10:23:52 CST 2018
hadoop%E9%9B%86%E7%BE%A4" style="text-align:justify;">(二)部署hadoop集群
1、安装haoop
#解压安装包h3
[root@master ~]# tar zxvf /opt/package/software/hadoop-2.7.3.tar.gz -C /usr/local
#重命名Hadoop安装目录
[root@master ~]# mv /usr/local/hadoop-2.7.3 /usr/local/hadoop
2、创建hdfs数据文件存储目录
#删除并创建hdfs数据文件存储目录
[root@master ~]# rm -rf /home/hadoopdir
[root@master ~]# mkdir /home/hadoopdir
#创建临时文件存储目录
[root@master ~]# mkdir /home/hadoopdir/tmp
#创建namenode数据目录
[root@master ~]# mkdir -p /home/hadoopdir/dfs/name
#创建datanode数据目录
[root@master ~]# mkdir /home/hadoopdir/dfs/data
3、修改配置文件
1)配置环境变量
#检查环境变量
[root@master ~]# vi /etc/profile
export HADOOP_INSTALL=/usr/local/hadoop
export PATH=${HADOOP_INSTALL}/bin:${HADOOP_INSTALL}/sbin:${PATH}
#/etc/profile文件生效
[root@master ~]# source /etc/profile
#hadoop-env.sh配置JAVA_HOME
[root@master ~]# vi /usr/local/hadoop/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/local/jdk/jre
#验证Hadoop版本
[root@master ~]# hadoop version
Hadoop 2.7.5
2)修改core-site.xml内容参考如下
[root@master ~]# vim /usr/local/hadoop/etc/hadoop/core-site.xml
<configuration><property><name>fs.defaultFS</name><value>hdfs://master:9000</value></property><property><name>io.file.buffer.size</name><value>131072</value></property><property><name>hadoop.tmp.dir</name><value>file:/home/hadoopdir/tmp/</value><description>A base for other temporary directories.</description></property><property><name>hadoop.proxyuser.hadoop.hosts</name><value>*</value></property><property><name>hadoop.proxyuser.hadoop.groups</name><value>*</value></property></configuration>3)修改hdfs-site.xml文件
[root@master ~]# vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml
<configuration><property><name>dfs.namenode.name.dir</name><value>file:///home/hadoopdir/dfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>file:///home/hadoopdir/dfs/data</value></property><property><name>dfs.replication</name><value>2</value></property><property><name>dfs.webhdfs.enabled</name><value>true</value></property></configuration>4)修改mapred-site.xml
#复制配置文件
[root@master ~]# cp /usr/local/hadoop/etc/hadoop/mapred-site.xml.template /usr/local/hadoop/etc/hadoop/mapred-site.xml
#修改配置文件
[root@master ~]# vim /usr/local/hadoop/etc/hadoop/mapred-site.xml
<configuration> <property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.jobhistory.address</name><value>master:10020</value></property><property><name>mapreduce.jobhistory.webapp.address</name><value>master:19888</value></property><property><name>mapreduce.jobtracker.http.address</name><value>master:50030</value></property><property><name>mapred.job.tracker</name><value>master:9001</value></property></configuration>5)修改 yarn-site.xml
[root@master ~]# vim /usr/local/hadoop/etc/hadoop/yarn-site.xml
<configuration><!-- Site specific YARN configuration properties --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name><value>org.apache.hadoop.mapred.ShuffleHandler</value></property><property> <name>yarn.resourcemanager.hostname</name><value>master</value></property> <property> <name>yarn.resourcemanager.address</name><value>master:8032</value></property><property> <name>yarn.resourcemanager.scheduler.address</name><value>master:8030</value></property><property> <name>yarn.resourcemanager.resource-tracker.address</name><value>master:8031</value></property><property><name>yarn.resourcemanager.admin.address</name><value>master:8033</value></property><property><name>yarn.resourcemanager.webapp.address</name><value>master:8088</value></property></configuration>6)修改 slaves文件
[root@master ~]# vim /usr/local/hadoop/etc/hadoop/slaves
slave1
slave2
(三)初始化HDFS
[root@master ~]# hadoop namenode -format
18/11/19 11:27:07 INFO util.ExitUtil: Exiting with status 0
18/11/19 11:27:07 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at master/192.168.80.101
************************************************************/
备注:最后出现“util.ExitUtil: Exiting with status 0”,表示成功。
(四)主从节点同步
hadoop%E7%9B%AE%E5%BD%95%E6%96%87%E4%BB%B6%E5%88%B0slave%E8%8A%82%E7%82%B9" style="margin-left:0px;text-align:left;">1、同步/usr/local/hadoop目录文件到slave节点
[root@master ~]# scp -r /usr/local/hadoop slave1:/usr/local/
[root@master ~]# scp -r /usr/local/hadoop/ slave2:/usr/local/
hadoopdir%E7%9B%AE%E5%BD%95%E6%96%87%E4%BB%B6%E5%88%B0slave%E8%8A%82%E7%82%B9" style="margin-left:0px;text-align:left;">2、同步/home/hadoopdir目录文件到slave节点
#删除目录
[root@master ~]# ssh slave1 rm -rf /home/hadoopdir
[root@master ~]# ssh slave2 rm -rf /home/hadoopdir
#同步目录
[root@master ~]# scp -r /home/hadoopdir slave1:/home/
[root@master ~]# scp -r /home/hadoopdir slave2:/home/
3、同步环境信息
[root@master ~]# scp /etc/profile slave1:/etc/profile
[root@master ~]# scp /etc/profile slave2:/etc/profile
[root@slave1 ~]# source /etc/profile
[root@slave2 ~]# source /etc/profile
hadoop%E9%9B%86%E7%BE%A4" style="margin-left:0px;text-align:left;">(五)测试hadoop集群
启动集群
#启动hadoop集群
[root@master ~]# start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [master]
master: starting namenode, logging to /usr/local/hadoop/logs/hadoop-root-namenode-master.out
slave1: starting datanode, logging to /usr/local/hadoop/logs/hadoop-root-datanode-slave1.out
slave2: starting datanode, logging to /usr/local/hadoop/logs/hadoop-root-datanode-slave2.out
Starting secondary namenodes [0.0.0.0]
The authenticity of host '0.0.0.0 (0.0.0.0)' can't be established.
ECDSA key fingerprint is SHA256:lrhnnND23cf0F9Azp4qUwS+Ek6+LscJ28CRce/NofA0.
ECDSA key fingerprint is MD5:56:6b:86:5e:df:6f:4f:70:af:fc:3f:d2:81:c8:a8:e6.
Are you sure you want to continue connecting (yes/no)? yes
0.0.0.0: Warning: Permanently added '0.0.0.0' (ECDSA) to the list of known hosts.
0.0.0.0: starting secondarynamenode, logging to /usr/local/hadoop/logs/hadoop-root-secondarynamenode-master.out
starting yarn daemons
starting resourcemanager, logging to /usr/local/hadoop/logs/yarn-root-resourcemanager-master.out
slave1: starting nodemanager, logging to /usr/local/hadoop/logs/yarn-root-nodemanager-slave1.out
slave2: starting nodemanager, logging to /usr/local/hadoop/logs/yarn-root-nodemanager-slave2.out
hadoop%E9%9B%86%E7%BE%A4" style="margin-left:0px;text-align:left;">(六)验证hadoop集群
1、JPS查看Java进程
#master
[root@master ~]# jps
7779 Jps
7349 SecondaryNameNode
7499 ResourceManager
7134 NameNode
#slave1
[root@slave1 ~]# jps
3169 DataNode
3445 Jps
3277 NodeManager
#slave2
[root@slave2 ~]# jps
3270 NodeManager
3162 DataNode
3391 Jps
2、登录网页查看
打开浏览器,登录http://master:50070
![]()
正在上传…重新上传取消
打开浏览器,查看yarn环境,登录http://master:8088
![]()
正在上传…重新上传取消
采用完全分布式集群安装方式,需要提前部署JDK环境、SSH验证等过程。安装并启动后可以访问 Web 界面 http://localhost:50070 查看 NameNode 和 Datanode 信息,还可以在线查看 HDFS 中的文件。