并行收集器(此处也称为吞吐量收集器)是类似于串行收集器的分代收集器。串行和并行收集器之间的主要区别在于并行收集器具有多个线程,用于加速垃圾回收过程。
通过命令行选项-XX:+UseParallelGC 可启用并行收集器。默认情况下,使用此选项,较小和较大的垃圾回收都会并行运行,以进一步减少垃圾回收开销。
并行收集器的垃圾回收线程数量
在具有小于N个硬件线程的计算机上,其中N大于8,并行收集器使用N的固定比例作为垃圾收集器线程数。
对于较大的N值,该比例约为5/8。对于小于8的N值,使用的数量为N。在特定平台上,该比例下降到5/16。可以使用命令行选项(稍后将描述)来调整垃圾收集器线程的具体数量。在只有一个处理器的主机上,并行收集器可能性能不如串行收集器,因为并行执行需要额外开销(例如同步)。但是,在运行具有中等到大型堆大小应用程序时,在具有两个处理器的计算机上,并行收集器通常会比串行收集器获得稍微更好的性能,并且当有多余两个处理器可用时,通常表现明显优于串行收集器。
可以使用命令行选项-XX:ParallelGCThreads=<N>来控制垃圾收集器线程数。如果正在通过命令行选项调整堆大小,则使用并行收集器获得良好性能所需的堆大小与串行收集器相同。然而,启用并行收集器应该会使垃圾回收暂停时间更短。由于多个垃圾回收线程参与了一次较小的回收过程,在此过程中可能会出现一些碎片化,因为在回收过程中从年轻代晋升到老年代。每个参与较小回收过程中的垃圾回收线程都会为晋升保留一部分老年代空间,并且这些“晋升缓冲区”的可用空间划分可能导致碎片化效果。减少垃圾回收线程数量并增加老年代大小将减少这种碎片化效果。
并行收集器中的分代排列
并行收集器中的分代排列不同。
该排列显示在图6-1中:
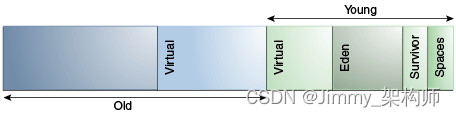
图6-1 并行收集器中的分代排列
并行收集器的自适应调整
当通过使用-XX:+UseParallelGC来选择并行收集器时,它会启用一种自动调优方法,允许您指定行为而不是指定代大小和其他底层调优细节。
指定并行收集器行为的选项
您可以指定最大的垃圾回收暂停时间、吞吐量和占用内存大小(堆大小)。
- 最大垃圾回收暂停时间:最大暂停时间目标由命令行选项-XX:MaxGCPauseMillis=<N>指定。这被解释为希望的暂停时间为<N>毫秒或更短;默认情况下,没有最大暂停时间目标。如果指定了暂停时间目标,则会调整堆大小和其他与垃圾回收相关的参数,以尝试使垃圾回收暂停时间短于指定值;但是,并不总是能达到期望的暂停时间目标。这些调整可能导致垃圾收集器降低应用程序的整体吞吐量。
- 吞吐量:吞吐量目标是以执行垃圾回收所花费的时间与未执行垃圾回收所花费的时间(即应用程序运行时间)之比来衡量的。此目标由命令行选项-XX:GCTimeRatio=<N>指定,该选项设置了垃圾回收时间与应用程序运行时间之比为1 / (1 + <N>)。
例如,-XX:GCTimeRatio=19将目标设置为1/20或5% 的总时间用于垃圾回收。默认值为99,导致将1% 的总时间用于垃圾回收。 - 占用内存大小:最大堆内存占用由选项-Xmx<N>指定。此外,该收集器还具有隐含目标,即在满足其他目标的情况下尽量减小堆大小。
并行收集器目标的优先级
这些目标依次为最大暂停时间目标、吞吐量目标和最小占用内存目标,且按照此顺序进行处理:
首先满足最大暂停时间目标。只有在达到此目标后,才会考虑吞吐量目标。同样地,只有在前两个目标达成之后,才会考虑占用内存大小的目标。
并行收集器分代大小调整
收集器在每次收集结束时会更新诸如收集器保持的平均暂停时间之类的统计数据。
然后进行用于确定是否已实现目标的测试,并根据需要调整代的大小。唯一例外的情况是显式垃圾回收,例如对System.gc()方法的调用,在统计数据和代大小调整方面被忽略。
增加和减少代大小是通过固定百分比递增来完成的,这样代就可以朝着其期望的大小逐步增加或减少。增加和减少是以不同速率进行的。默认情况下,代以20% 的增量递增,以5% 的增量递减。增长百分比由命令行选项-XX:YoungGenerationSizeIncrement=<Y>(年轻代)和-XX:TenuredGenerationSizeIncrement=<T>(老年代)控制。指定代缩小百分比由命令行标志-XX:AdaptiveSizeDecrementScaleFactor=<D>进行调整。如果增长幅度为X%,那么缩小量为X/D%。
如果收集器决定在启动时扩大某一代,则会额外添加一个百分比作为补充项。该补充项目随着收集次数而逐渐减少,并且没有长期影响。该补充项目旨在提高启动性能。对于缩小百分比没有额外添加。
如果不能达到最大暂停时间目标,则一次只会缩小一个代的大小。如果两个代的暂停时间都超过目标值,则首先会缩小暂停时间较长的那个代的大小。
如果无法实现吞吐量目标,则两个代的大小都会增加。每个都按其对总垃圾回收时间所占比例来增加。例如,如果年轻代的垃圾回收时间占总回收时间的25%,而将年轻代完全扩大20%,则年轻代将会增加5%。
并行收集器默认堆大小
除非在命令行上指定了初始堆大小和最大堆大小,否则它们将根据计算机上的内存量来计算。默认的最大堆大小为物理内存的四分之一,而初始堆大小为物理内存的64分之1。分配给年轻代的最大空间量为总堆大小的三分之一。
指定并行收集器初始和最大堆大小
您可以使用选项-Xms(最小堆大小)和 -Xmx(最大堆大小)来指定最小和最大堆大小。
如果您知道应用程序需要多少堆才能正常工作,那么可以将 -Xms 和 -Xmx 设置为相同的值。如果不确定,JVM 会从初始堆大小开始,并在堆使用和性能之间找到平衡时逐渐增加 Java 堆的大小。
其他参数和选项可能会影响这些默认值。要验证默认值,请使用-XX:+PrintFlagsFinal 选项,并查找输出中的-XX:MaxHeapSize。例如,在 Linux 上,您可以运行以下命令:
java -XX:+PrintFlagsFinal <GC options> -version | grep MaxHeapSize
过多的并行收集时间和OutOfMemoryError错误
并行收集器会在垃圾回收(GC)中花费过多时间时抛出 OutOfMemoryError。
如果总时间中有超过 98% 的时间用于垃圾回收,并且回收的堆空间不足 2%,则会抛出 OutOfMemoryError。该功能旨在防止应用程序因堆太小而无法取得实质进展而长时间运行。如有必要,可以通过在命令行中添加选项 -XX:-UseGCOverheadLimit 来禁用此特性。
并行收集器的测量指标
并行收集器的详细垃圾收集器的输出基本上与串行收集器的输出相同。



![正点原子[第二期]Linux之ARM(MX6U)裸机篇学习笔记-6.4--汇编LED驱动程序](https://img-blog.csdnimg.cn/direct/487de93cb8a744e68029b0290f7d918d.png)