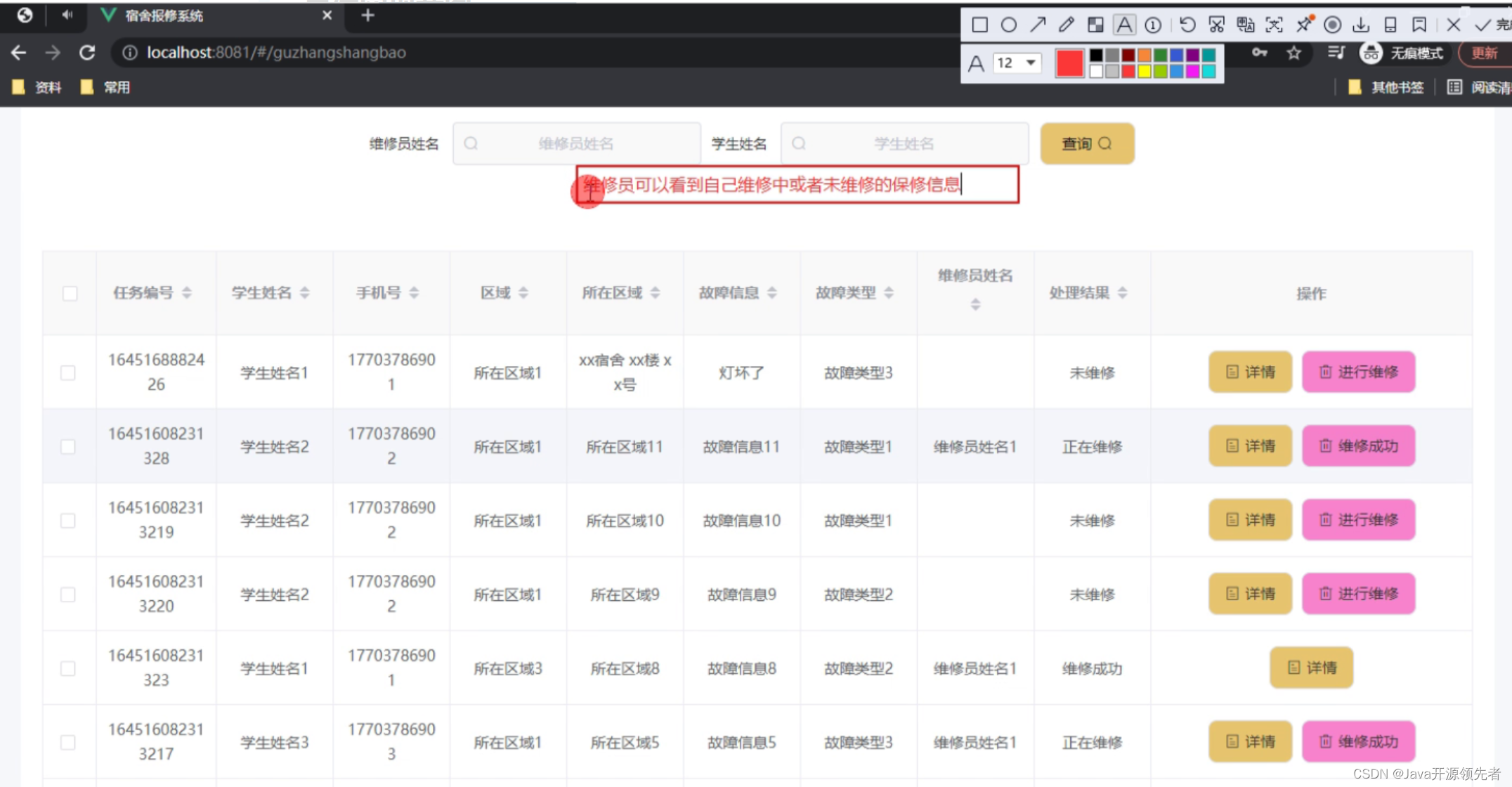
在当今数据驱动的世界里,高效的网络爬虫技术已经成为每个数据科学家和后端工程师的必备技能。本文将深入探讨一些高级的Python爬虫技术,这些技术不仅能够大幅提升你的爬虫效率,还能帮助你应对各种复杂的爬虫场景。
1. 异步爬虫:协程与异步IO
异步编程是提高爬虫效率的关键。我们将使用aiohttp和asyncio来实现一个高性能的异步爬虫。
python">import aiohttp
import asyncio
from bs4 import BeautifulSoup
import timeasync def fetch(session, url):async with session.get(url) as response:return await response.text()async def parse(html):soup = BeautifulSoup(html, 'html.parser')# 假设我们要提取所有的标题titles = soup.find_all('h2')return [title.text for title in titles]async def crawl(urls):async with aiohttp.ClientSession() as session:tasks = [fetch(session, url) for url in urls]pages = await asyncio.gather(*tasks)results = await asyncio.gather(*[parse(page) for page in pages])return resultsurls = ['http://example.com', 'http://example.org', 'http://example.net'] * 100 # 300 URLsstart_time = time.time()
results = asyncio.run(crawl(urls))
end_time = time.time()print(f"Total time: {end_time - start_time} seconds")
print(f"Total results: {sum(len(result) for result in results)}")这个例子展示了如何使用协程和异步IO来并发爬取多个网页,大大提高了爬取速度。
2. 分布式爬虫:Scrapy + Redis
对于大规模爬虫任务,单机爬虫往往力不从心。这里我们介绍如何使用Scrapy和Redis构建一个简单的分布式爬虫系统。
首先,安装必要的库:
python">pip install scrapy scrapy-redis然后,创建一个Scrapy项目并修改settings.py:
python"># settings.py
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
REDIS_URL = 'redis://localhost:6379'
SCHEDULER_PERSIST = True接下来,创建一个Redis-based Spider:
python"># myspider.py
from scrapy_redis.spiders import RedisSpiderclass MySpider(RedisSpider):name = 'myspider'def parse(self, response):# 解析逻辑pass现在,你可以在多台机器上运行这个爬虫,它们会自动从Redis中获取要爬取的URL:
python">scrapy runspider myspider.py在Redis中添加起始URL:
python">redis-cli lpush myspider:start_urls "http://example.com"这样,你就拥有了一个可以横向扩展的分布式爬虫系统。
3. 智能解析:使用机器学习识别内容
有时,网页结构可能非常复杂或经常变化,这时我们可以尝试使用机器学习来智能识别我们需要的内容。这里我们使用newspaper3k库和transformers库来实现这一功能。
python">!pip install newspaper3k transformers torchfrom newspaper import Article
from transformers import pipeline# 初始化一个用于问答的管道
nlp = pipeline("question-answering")def smart_extract(url, question):# 下载并解析文章article = Article(url)article.download()article.parse()# 使用问答模型来找到答案result = nlp(question=question, context=article.text)return result['answer']# 使用示例
url = "https://en.wikipedia.org/wiki/Python_(programming_language)"
question = "Who created Python?"answer = smart_extract(url, question)
print(f"Answer: {answer}")这个方法使用了自然语言处理技术,可以从非结构化的文本中提取特定信息,大大增强了爬虫的灵活性。
4. 绕过反爬虫:Selenium + Undetected ChromeDriver
对于一些具有强大反爬虫机制的网站,我们可能需要模拟真实的浏览器行为。这里我们使用selenium和undetected_chromedriver来实现这一点。
python">!pip install selenium undetected_chromedriverimport undetected_chromedriver as uc
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as ECdef scrape_with_real_browser(url):options = uc.ChromeOptions()options.add_argument("--headless")driver = uc.Chrome(options=options)driver.get(url)# 等待特定元素加载完成element = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR, "h1")))# 获取页面内容content = driver.page_sourcedriver.quit()return content# 使用示例
url = "https://bot.sannysoft.com/" # 这是一个测试浏览器指纹的网站
content = scrape_with_real_browser(url)
print("Successfully scraped content length:", len(content))这个方法使用了未检测的ChromeDriver,可以绕过许多基于浏览器指纹的反爬虫措施。
结语
这些高级技术为我们提供了应对各种复杂爬虫场景的工具。从异步编程到分布式系统,从智能内容提取到反反爬虫技术,掌握这些技能将使你的爬虫更加高效、灵活和强大。
记住,强大的力量伴随着巨大的责任。在使用这些技术时,请务必遵守网站的使用条款和机器人协议,保持对目标网站的尊重。祝你在数据采集的海洋中扬帆起航!